 如何使用PyCaret + RAPIDS简化模型构建
如何使用PyCaret + RAPIDS简化模型构建
PyCaret是一个低代码 Python 机器学习库,基于流行的 R Caret 库。它自动化了从数据预处理到 i NSight 的数据科学过程,因此短代码行可以用最少的人工完成每个步骤。此外,使用简单的命令比较和调整许多模型的能力可以简化效率和生产效率,同时减少创建有用模型的时间。
PyCaret 团队在 2 . 2 版中添加了 NVIDIA GPU 支持,包括RAPIDS中所有最新和最伟大的版本。使用 GPU 加速, PyCaret 建模时间可以快 2 到 200 倍,具体取决于工作负载。
这篇文章将介绍如何在 GPU 上使用 PyCaret 以节省大量的开发和计算成本。
所有基准测试都是在一台 32 核 CPU 和四个 NVIDIA Tesla T4 的机器上运行的,代码几乎相同。为简单起见, GPU 代码编写为在单个 GPU 上运行。
PyCaret 入门
使用 PyCaret 与导入库和执行 setup 语句一样简单。setup()功能创建环境,并提供一系列预处理功能,一气呵成。
from pycaret.regression import * exp_reg = setup(data = df, target = ‘Year’, session_id = 123, normalize = True)
在一个简单的设置之后,数据科学家可以开发其管道的其余部分,包括数据预处理/准备、模型训练、集成、分析和部署。在准备好数据后,最好从比较模型开始。
与 PyCaret 的简约精神一样,我们可以通过一行代码来比较一系列标准模型,看看哪些模型最适合我们的数据。 compare _ models 命令使用默认超参数训练 PyCaret 模型库中的所有模型,并使用交叉验证评估性能指标。然后,数据科学家可以根据这些信息选择他们想要使用的模型、调整和集成。
top3 = compare_models(exclude = [‘ransac’], n_select=3)
比较模型
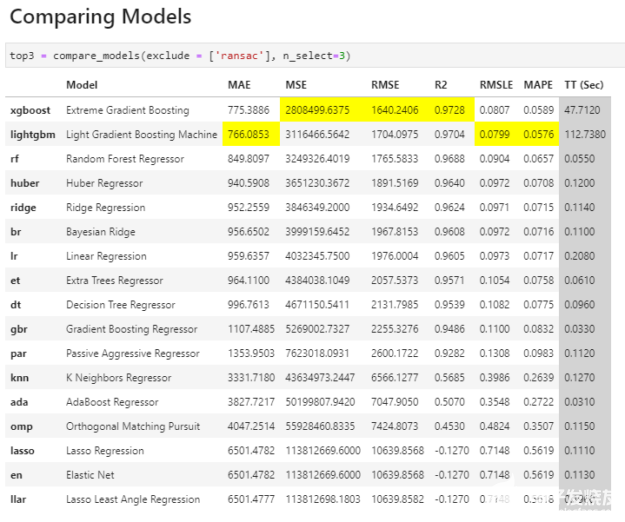
图 1 : PyCaret 中 compare _ models 命令的输出。
**模型从最佳到最差排序, PyCaret 突出显示了每个度量类别中的最佳结果,以便于使用。
用 RAPIDS cuML 加速 PyCaret
PyCaret 对于任何数据科学家来说都是一个很好的工具,因为它简化了模型构建并使运行许多模型变得简单。使用 GPU s , PyCaret 可以做得更好。由于 PyCaret 在幕后做了大量工作,因此看似简单的命令可能需要很长时间。例如,我们在一个具有大约 50 万个实例和 90 多个属性(加州大学欧文分校的年度预测 MSD 数据集)的数据集上运行了前面的命令。在 CPU 上,花费了 3 个多小时。在 GPU 上,只花了不到一半的时间。
在过去,在 GPU 上使用 PyCaret 需要许多手动编码,但谢天谢地, PyCaret 团队集成了 RAPIDS 机器学习库( cuML ),这意味着您可以使用使 PyCaret 如此有效的相同简单 API ,同时还可以使用 GPU 的计算能力。
在 GPU 上运行 PyCaret 往往要快得多,这意味着您可以充分利用 PyCaret 提供的一切,而无需平衡时间成本。使用刚才提到的同一个数据集,我们在 CPU 和 GPU 上测试了 PyCaret ML 功能,包括比较、创建、调优和集成模型。切换到 GPU 很简单;我们在设置函数中将use_gpu设置为True:
exp_reg = setup(data = df, target = ‘Year’, session_id = 123, normalize = True, use_gpu = True)
PyCaret 设置为在 GPU 上运行,它使用 cuML 来训练以下所有型号:
对数几率回归
脊分类器
随机森林
K 邻域分类器
K 邻域回归器
支持向量机
线性回归
岭回归
套索回归
群集分析
基于密度的空间聚类
仅在 GPU 上运行相同的compare_models代码的速度是 GPU 的2.5倍多。
对于流行但计算昂贵的模型,在模型基础上的影响更大。例如, K 邻域回归器在 GPU 上的速度是其 265 倍。
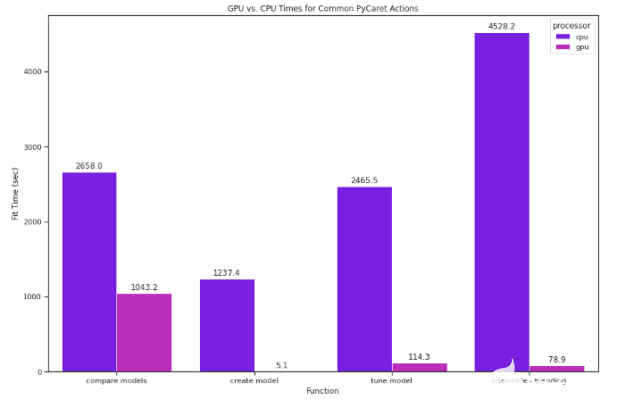
图 2 : CPU 和 GPU 上运行的常见 PyCaret 操作的比较。
影响
PyCaret API 的简单性释放了原本用于编码的时间,因此数据科学家可以做更多的实验并对实验进行微调。当与 GPU 配合使用时,这种影响甚至更大,因为充分利用 PyCaret 的评估和比较工具套件的计算成本显著降低。
结论
广泛的比较和评估模型有助于提高结果的质量,而 PyCaret 正是为了这样做。 GPU 上的 PyCaret 抵消了大量处理所带来的时间成本。
RAPIDS 的目标是加速您的数据科学, PyCaret 是越来越多的库之一,它们与 RAPIDS 套件的兼容性有助于为您的机器学习追求带来新的效率。
PyCaret CPU vs. GPU Benchmarking
Import Libraries
import pycaret
import pandas as pd
import numpy as np
import time
from pycaret.utils import version
version()
Timing
import json
import time
class Timer:
def __enter__(self, *args, **kwargs):
self.tick = time.time()
return self
def __exit__(self, *args, **kwargs):
self.elapsed = time.time() - self.tick
benchmark_list = []
#fixing attribute labels
names = ['Year']
for x in range(1,13):
names.append('t_avg_' + str(x)) #these attributes are timbre averages
for x in range(1,79):
names.append('t_cov_' + str(x)) #these attributes are timbre covariances
dataset.columns = names
dataset.head()
Withhold a sample of 600 records from the original dataset to be used for predictions (not to be confused with train/test split).
#gpu data
df = dataset[:463716]
unseen_df = dataset[463716:515346]
unseen_df.reset_index(drop=True, inplace=True)
print('Data for Modeling: ' + str(df.shape))
print('Unseen Data For Predictions: ' + str(unseen_df.shape))
Set up Environment in PyCaret
To record CPU times, keepuse_gpu=False, and to record GPU times, set it toTrue. Be sure to update the labels in the timing module at the end of each cell to match what's being recorded.
from pycaret.regression import *
exp_reg = setup(data = df, target = 'Year', session_id = 123, normalize = True, use_gpu=False)
Compare All Models
Not all models can be run on GPU, so even whenuse_gpu=True, those that cannot be run on GPU will automatically be run on CPU. To compare the times of only those models that can be run on GPU,exclude = ['ransac', 'huber', 'par', 'ada', 'omp', 'llar'].
with Timer() as elapsed:
best_models = compare_models(exclude = ['ransac'], n_select = 3)
benchmark_payload = {}
benchmark_payload["function"] = "compare models"
benchmark_payload["model"] = "all"
benchmark_payload["processor"] = "cpu"
benchmark_payload["fit_time"] = elapsed.elapsed
benchmark_list.append(benchmark_payload)
Create Models
Here we can time the fitting of an individual model. Linear regression is used for example.
with Timer() as elapsed:
lr = create_model('lr', fold = 5)
benchmark_payload = {}
benchmark_payload["function"] = "create model"
benchmark_payload["model"] = "lr"
benchmark_payload["processor"] = "cpu"
benchmark_payload["fit_time"] = elapsed.elapsed
benchmark_list.append(benchmark_payload)
Tune Models
Here we can time the tuning of a model we've created.
with Timer() as elasped:
tuned_lr = tune_model(lr)
benchmark_payload = {}
benchmark_payload["function"] = "tune model"
benchmark_payload["model"] = "lr"
benchmark_payload["processor"] = "cpu"
benchmark_payload["fit_time"] = elapsed.elapsed
benchmark_list.append(benchmark_payload)
Ensemble a Model
Blending
with Timer() as elapsed:
#train individual models to blend
xgboost = create_model('xgboost', verbose = False)
lr = create_model('lr', verbose = False)
knn = create_model('knn', verbose = False)
#blend individual models
blender = blend_models(estimator_list = [xgboost, lr, knn])
benchmark_payload = {}
benchmark_payload["function"] = "ensemble - blending"
benchmark_payload["model"] = "xgboost, lr, knn"
benchmark_payload["processor"] = "cpu"
benchmark_payload["fit_time"] = elapsed.elapsed
benchmark_list.append(benchmark_payload)
Stacking
with Timer() as elapsed:
stacker = stack_models(best_models)
benchmark_payload = {}
benchmark_payload["function"] = "ensemble - stacking"
benchmark_payload["model"] = "best_models cpu"
benchmark_payload["processor"] = "cpu"
benchmark_payload["fit_time"] = elapsed.elapsed
benchmark_list.append(benchmark_payload)
Plot Error
plot_model(blender, plot = 'error')
plot_model(stacker, plot = 'error')
Predict on Hold-Out Sample
with Timer() as elapsed:
predict_model(stacker);
benchmark_payload = {}
benchmark_payload["function"] = "predict model"
benchmark_payload["model"] = "stacker"
benchmark_payload["processor"] = "cpu"
benchmark_payload["fit_time"] = elapsed.elapsed
benchmark_list.append(benchmark_payload)
Finalize Model
with Timer() as elapsed:
final_stacker = finalize_model(stacker)
benchmark_payload = {}
benchmark_payload["function"] = "finalize model"
benchmark_payload["model"] = "stacker"
benchmark_payload["processor"] = "cpu"
benchmark_payload["fit_time"] = elapsed.elapsed
benchmark_list.append(benchmark_payload)
with Timer() as elapsed:
predict_model(final_stacker);
benchmark_payload = {}
benchmark_payload["function"] = "predict model"
benchmark_payload["model"] = "final stacker"
benchmark_payload["processor"] = "cpu"
benchmark_payload["fit_time"] = elapsed.elapsed
benchmark_list.append(benchmark_payload)
Predict on Unseen Data
with Timer() as elapsed:
unseen_predictions = predict_model(final_stacker, data=data_unseen)
unseen_predictions.head()
benchmark_payload = {}
benchmark_payload["function"] = "predict on unseen"
benchmark_payload["model"] = "final stacker"
benchmark_payload["processor"] = "cpu"
benchmark_payload["fit_time"] = elapsed.elapsed
benchmark_list.append(benchmark_payload)
Write Times to File
outpath = "pycaret_benchmarksCPU.json"
with open(outpath, "a") as fh:
fh.write(json.dumps(benchmark_list))
fh.write("\n")
关于作者
Sofia Sayyah 是 NVIDIA 的数据工程实习生。
审核编辑:郭婷
-
gpu
+关注
关注
28文章
4754浏览量
129080 -
机器学习
+关注
关注
66文章
8428浏览量
132779
发布评论请先 登录
相关推荐
小白学大模型:构建LLM的关键步骤

RAPIDS cuDF将pandas提速近150倍

如何使用Python构建LSTM神经网络模型
数据中心应用中适用于Intel Xeon Sapphire Rapids可扩展处理器的负载点解决方案







 工商网监
工商网监
评论