 利用NVIDIA HGX H100加速计算数据中心平台应用
利用NVIDIA HGX H100加速计算数据中心平台应用
NVIDIA 的使命是加快我们的时代达芬奇和爱因斯坦的工作,并赋予他们解决社会的巨大挑战。随着 人工智能 ( AI )、 高性能计算 ( HPC )和数据分析的复杂性呈指数级增长,科学家需要一个先进的计算平台,能够在一个十年内实现百万次的加速,以解决这些非同寻常的挑战。
为了回答这个需求,我们介绍了NVIDIA HGX H100 ,一个由 NVIDIA Hopper 架构 供电的密钥 GPU 服务器构建块。这一最先进的平台安全地提供了低延迟的高性能,并集成了从网络到数据中心级计算(新的计算单元)的全套功能。
在这篇文章中,我将讨论NVIDIA HGX H100 是如何帮助我们加速计算数据中心平台的下一个巨大飞跃。
HGX H100 8-GPU
HGX H100 8- GPU 是新一代 Hopper GPU 服务器的关键组成部分。它拥有八个 H100 张量核 GPU 和四个第三代 NV 交换机。每个 H100 GPU 都有多个第四代 NVLink 端口,并连接到所有四个 NVLink 交换机。每个 NVSwitch 都是一个完全无阻塞的交换机,完全连接所有八个 H100 Tensor Core GPU 。
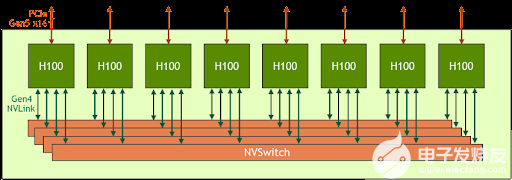
图 1 。 HGX H100 8-GPU 的高级框图
NVSwitch 的这种完全连接的拓扑结构使任何 H100 都可以同时与任何其他 H100 通话。值得注意的是,这种通信以每秒 900 千兆字节( GB / s )的 NVLink 双向速度运行,这是当前 PCIe Gen4 x16 总线带宽的 14 倍多。
第三代 NVSwitch 还为集体运营提供了新的硬件加速,多播和 NVIDIA 的网络规模大幅缩减。结合更快的 NVLink 速度,像all-reduce这样的普通人工智能集体操作的有效带宽比 HGX A100 增加了 3 倍。集体的 NVSwitch 加速也显著降低了 GPU 上的负载。
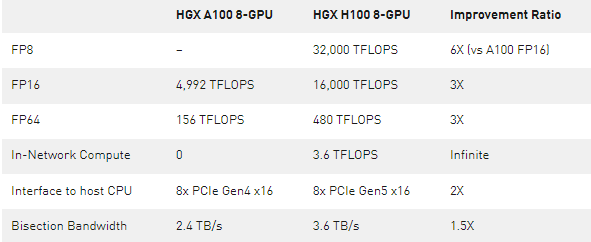
表 1 。将 HGX A100 8- GPU 与新的 HGX H100 8-GPU 进行比较
*注: FP 性能包括稀疏性
HGX H100 8- GPU 支持 NVLink 网络
新兴的 exascale HPC 和万亿参数人工智能模型(用于精确对话人工智能等任务)需要数月的训练,即使是在超级计算机上。将其压缩到业务速度并在数小时内完成培训需要服务器集群中每个 GPU 之间的高速、无缝通信。
为了解决这些大的使用案例,新的 NVLink 和 NVSwitch 旨在使 HGX H100 8- GPU 能够通过新的 NVLink 网络扩展并支持更大的 NVLink 域。 HGX H100 8- GPU 的另一个版本具有这种新的 NVLink 网络支持。
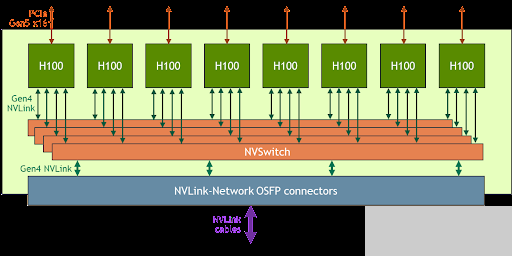
图 2 。支持 NVLink 网络的 HGX H100 8- GPU 的高级框图
使用 HGX H100 8- GPU 和 NVLink 网络支持构建的系统节点可以通过八进制小尺寸可插拔( OSFP ) LinkX 电缆和新的外部 NVLink 交换机完全连接到其他系统。此连接最多支持 256 个 GPU NVLink 域。图 3 显示了集群拓扑。
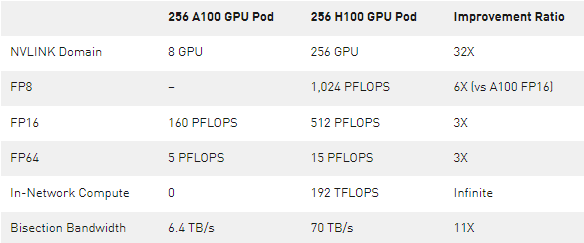
表 2 。比较 256 个 A100 GPU 吊舱和 256 个 H100 GPU 吊舱
*注: FP 性能包括稀疏性
目标用例和性能优势
随着 HGX H100 计算和网络能力的大幅增加, AI 和 HPC 应用程序的性能得到了极大的提高。
今天的主流 AI 和 HPC 模型可以完全驻留在单个节点的聚合 GPU 内存中。例如, BERT -Large 、 Mask R-CNN 和 HGX H100 是最高效的培训解决方案。
对于更先进、更大的 AI 和 HPC 模型,该模型需要多个聚合 GPU 内存节点才能适应。例如,具有 TB 级嵌入式表的深度学习推荐模型( DLRM )、大量混合专家( MoE )自然语言处理模型,以及具有 NVLink 网络的 HGX H100 加速了关键通信瓶颈,是此类工作负载的最佳解决方案。
图 4 来自 NVIDIA H100 GPU 体系结构 白皮书显示了 NVLink 网络带来的额外性能提升。
所有性能数据都是基于当前预期的初步数据,可能会随着运输产品的变化而变化。 A100 集群: HDR IB 网络。 H100 集群: NDR IB 网络和 NVLink 网络,如图所示。
# GPU :气候建模 1K , LQCD 1K ,基因组学 8 , 3D-FFT 256 , MT-NLG 32 (批次大小: A100 为 4 , 1 秒 H100 为 60 , A100 为 8 , 1.5 和 2 秒 H100 为 64 ), MRCNN 8 (批次 32 ), GPT-3 16B 512 (批次 256 ), DLRM 128 (批次 64K ), GPT-3 16K (批次 512 ), MoE 8K (批次 512 ,每个 GPU 一名专家)
HGX H100 4-GPU
除了 8- GPU 版本外, HGX 系列还具有一个 4-GPU 版本,该版本直接与第四代 NVLink 连接。
H100 对 H100 点对点对等 NVLink 带宽为 300 GB / s 双向,比今天的 PCIe Gen4 x16 总线快约 5 倍。
HGX H100 4- GPU 外形经过优化,可用于密集 HPC 部署:
多个 HGX H100 4- GPU 可以装在 1U 高液体冷却系统中,以最大化每个机架的 GPU 密度。
带有 HGX H100 4- GPU 的完全无 PCIe 交换机架构直接连接到 CPU ,降低了系统材料清单并节省了电源。
对于 CPU 更密集的工作负载, HGX H100 4- GPU 可以与两个 CPU 插槽配对,以提高 CPU 与 GPU 的比率,从而实现更平衡的系统配置。
人工智能和高性能计算的加速服务器平台
NVIDIA 正与我们的生态系统密切合作,在今年晚些时候将基于 HGX H100 的服务器平台推向市场。我们期待着把这个强大的计算工具交给你们,使你们能够以人类历史上最快的速度创新和完成你们一生的工作。
关于作者
William Tsu NVIDIA HGX 数据中心产品线的产品管理。他与客户和合作伙伴合作,将世界上性能最高的人工智能、深度学习和 HPC 服务器平台推向市场。威廉最初加入NVIDIA 是作为一名图形处理器芯片设计师。他是最初的 PCI Express 行业标准规范的共同作者,也是 12 项专利的共同发明人。威廉获得了他的学士学位,硕士学位在计算机科学和 MBA 从加利福尼亚大学,伯克利。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5104浏览量
104392 -
数据中心
+关注
关注
16文章
4951浏览量
72645 -
人工智能
+关注
关注
1800文章
48062浏览量
242021 -
H100
+关注
关注
0文章
32浏览量
334
发布评论请先 登录
相关推荐
英伟达A100和H100比较

利用NVIDIA DPF引领DPU加速云计算的未来
NIDA发布《智算数据中心网络建设技术要求》
Supermicro推出直接液冷优化的NVIDIA Blackwell解决方案

华为致力于打造安全可靠的智算数据中心
NVIDIA向开放计算项目捐赠Blackwell平台设计
华迅光通AI计算加速800G光模块部署
英伟达H100芯片市场降温
云计算与数据中心的关系
利用NVIDIA RAPIDS加速DolphinDB Shark平台提升计算性能
SK电讯将与Lambda合作打造AI数据中心
Supermicro推出适配NVIDIA Blackwell和NVIDIA HGX H100/H200的机柜级即插即用液冷AI SuperCluster

首批1024块H100 GPU,正崴集团将建中国台湾最大AI计算中心
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
NVIDIA 通过 CUDA-Q 平台为全球各地的量子计算中心提供加速






 工商网监
工商网监
评论