 NVIDIA深度学习加速数据科学教材套满足教学需求
NVIDIA深度学习加速数据科学教材套满足教学需求
NVIDIA 深度学习培训中心( DLI )发布了加速数据科学教材套,该研究所与佐治亚理工学院的 Polo Chau 教授和 Prairie View A & M 大学的董锡双教授共同开发。
综合教材涵盖数据收集和预处理、加速数据科学 RAPIDS、可扩展和分布式计算 GPU – 加速机器学习、数据可视化和图形分析等基础和高级主题,并满足了高等教育和研究机构对学生教授数据科学技能的日益增长的需求。
加速数据科学教学包包括以下重点模块:
数据科学与技术导论 RAPIDS
数据收集和预处理( ETL )
数据集中的数据伦理和偏见
数据集成和分析
数据可视化
使用 Hadoop 、 Hive 、 Spark 、 HBase 和 RAPIDS 的可扩展计算
基于 Dask 和 UCX 的可扩展计算
机器学习:分类
机器学习:聚类和降维
图形分析
流数据
基因组学
文本分析
CPU vs GPU – 加速数据科学
数据科学团队、代码备份和版本控制
团队项目(假新闻检测)
该工具包还涵盖了公平性和数据偏见等文化敏感话题,以及来自代表性不足群体的挑战和重要人物。
讲座幻灯片和讲稿、动手实验室、 Jupyter 笔记本、解决方案(以私人回购形式持有)、样本数据集、测验/考试问题/答案、 GPU 通过免费 AWS 云学分提供的计算资源,以及免费 DLI 在线课程/证书都包括在内。讲座视频计划在下一版本中发布。
RAPIDS 数据科学框架是 GPU 加速的库集合,用于在 GPU 上完全执行端到端数据科学管道。使用 RAPIDS 的主要目标是加速典型数据科学工作流的各个部分,从而加速数据准备和机器学习中完整的端到端工作流。
第一个基于 Jupyter 笔记本电脑的实验室之一让学生使用 pandas 和 cuDF 直接进入 RAPIDS 。 pandas 是一个建立在 Python 编程语言之上的数据分析和操作工具,用于执行各种任务(例如:加载、加入、聚合、, cuDF 是一个基于 RAPIDS 的 GPU 数据帧库,有助于通过 GPU 加速执行类似功能。
学生们首先要理解如何在 cuDF 中创建数据帧对象,为这些对象分配值,然后调用方法并对值应用用户定义的函数。一旦学生掌握了如何使用 cuDF 数据帧,他们的任务就是从 Kaggle 的Netflix 电影数据集中创建一个数据帧。
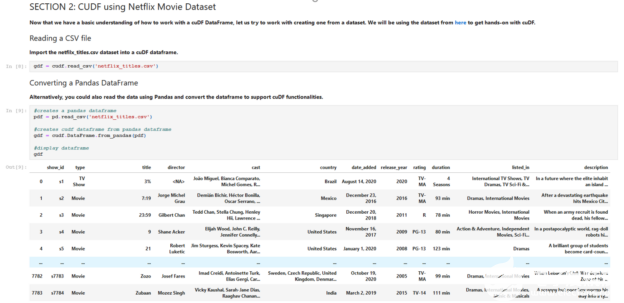
图 1 。教学包模块 1 的快照: RAPIDS 实验室简介。
从那里,学生们学习如何操作和查询数据,从删除缺失的列和值、查询和查找唯一值,到对数据进行排序、计数和分组。学生将感受到使用 RAPIDS 和 GPU 与教学包中也包含的传统方法相比是多么快速和简单。作为实验室的一项额外任务,最后要求学生使用 cuDF 一个热编码将数据集的电影和电视节目标题转换为 0 和 1 的向量,以提高分析数据的准确性。
周教授说:“数据科学揭示了数据在解决社会挑战和大规模复杂问题方面的巨大潜力,几乎涵盖了商业、技术、科学、工程、医疗保健、政府等各个领域。”随着数据在数量、速度和复杂性方面的不断增长,对数据科学人才和技能的需求不断增加,以帮助设计最佳解决方案。”
关于作者
Joe Bungo 是 NVIDIA 的深度学习培训中心( DLI )项目经理,在那里他能够在大学中使用深度学习和 GPU 加速计算技术,包括课程和教材开发、 DLI 大学大使/讲师认证、促进学术生态系统和实践研讨会。此前,他在 ARM 公司管理大学项目,并担任应用工程师。乔获得了得克萨斯大学奥斯汀分校计算机科学学位。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
4952浏览量
102861 -
gpu
+关注
关注
28文章
4709浏览量
128781 -
深度学习
+关注
关注
73文章
5495浏览量
121042
发布评论请先 登录
相关推荐
NPU在深度学习中的应用

《AI for Science:人工智能驱动科学创新》第一章人工智能驱动的科学创新学习心得
FPGA做深度学习能走多远?
NVIDIA推出全新深度学习框架fVDB
NVIDIA提供一套服务、模型以及计算平台 加速人形机器人发展
深度学习与nlp的区别在哪
助力科学发展,NVIDIA AI加速HPC研究

NVIDIA在加速识因智能AI大模型落地应用方面的重要作用介绍
使用NVIDIA Triton推理服务器来加速AI预测
NVIDIA首席科学家Bill Dally:深度学习硬件趋势






 工商网监
工商网监
评论