 使用NVIDIA开源模型实现更快的训练和推理
使用NVIDIA开源模型实现更快的训练和推理
SE(3)-Transformers 是在NeurIPS 2020上推出的多功能图形神经网络。 NVIDIA 刚刚发布了一款开源优化实现,它使用的内存比基线正式实施少9倍,速度比基线正式实施快21倍。
SE(3)-Transformer 在处理几何对称性问题时非常有用,如小分子处理、蛋白质精制或点云应用。它们可以是更大的药物发现模型的一部分,如RoseTTAFold和此 AlphaFold2 的复制。它们也可以用作点云分类和分子性质预测的独立网络(图 1 )。
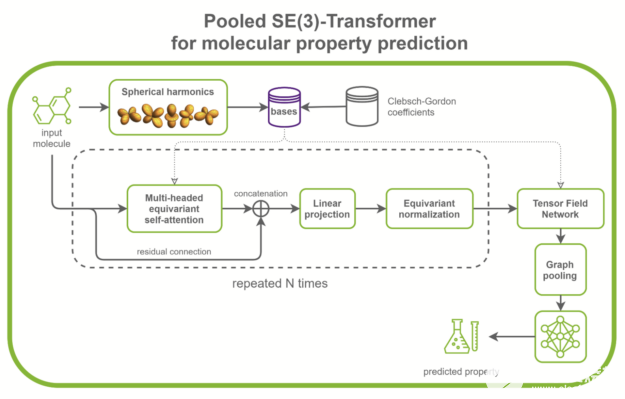
图 1 用于分子性质预测的典型 SE ( 3 ) – transformer 的结构。
在/PyTorch/DrugDiscovery/SE3Transformer存储库中, NVIDIA 提供了在QM9 数据集上为分子性质预测任务训练优化模型的方法。 QM9 数据集包含超过 10 万个有机小分子和相关的量子化学性质。
训练吞吐量提高 21 倍
与基线实施相比, NVIDIA 实现提供了更快的训练和推理。该实现对 SE(3)-Transformers 的核心组件,即张量场网络( TFN )以及图形中的自我注意机制进行了优化。
考虑到注意力层超参数的某些条件得到满足,这些优化大多采取操作融合的形式。
由于这些,与基线实施相比,训练吞吐量增加了 21 倍,利用了最近 GPU NVIDIA 上的张量核。
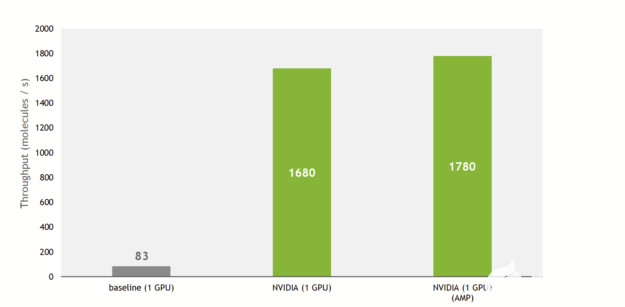
图 2 A100 GPU 上的训练吞吐量。批次大小为 100 的 QM9 数据集。
此外, NVIDIA 实现允许使用多个 GPU 以数据并行方式训练模型,充分利用 DGX A100 ( 8x A100 80GB )的计算能力。
把所有东西放在一起,在 NVIDIA DGX A100 上, SE(3)-Transformer现在可以在 QM9 数据集上在 27 分钟内进行训练。作为比较,原始论文的作者指出,培训在硬件上花费了 2 。 5 天( NVIDIA GeForce GTX 1080 Ti )。
更快的培训使您能够在搜索最佳体系结构的过程中快速迭代。随着内存使用率的降低,您现在可以训练具有更多注意层或隐藏通道的更大模型,并向模型提供更大的输入。
内存占用率降低 9 倍
SE(3)-Transformer 是已知的记忆重模型,这意味着喂养大输入,如大蛋白质或许多分批小分子是一项挑战。对于 GPU 内存有限的用户来说,这是一个瓶颈。
这一点在DeepLearningExamples上的 NVIDIA 实现中已经改变。图 3 显示,由于 NVIDIA 优化和对混合精度的支持,与基线实现相比,训练内存使用减少了 9 倍。
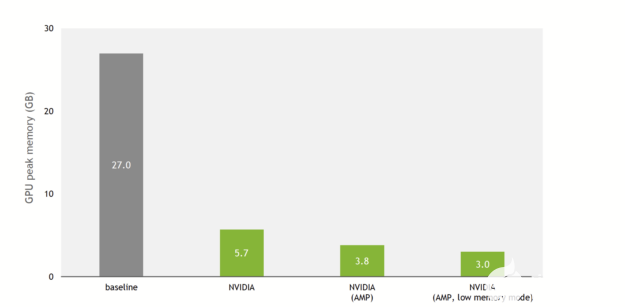
图 3 SE ( 3 ) – transformer s 的基线实现和 NVIDIA 实现之间的训练峰值内存消耗比较。在 QM9 数据集上每批使用 100 个分子。 V100 32-GB GPU 。
除了对单精度和混合精度进行改进外,还提供了低内存模式。启用此标志后,模型在 TF32 ( NVIDIA 安培体系结构)或 FP16 ( NVIDIA 安培体系结构、 NVIDIA 图灵体系结构和 NVIDIA 伏特体系结构)精度上运行,模型将切换到以吞吐量换取额外内存节省的模式。
实际上,在具有 V100 32-GB GPU 的 QM9 数据集上,基线实现可以在内存耗尽之前扩展到 100 的批大小。 NVIDIA 实现每批最多可容纳 1000 个分子(混合精度,低内存模式)。
对于处理以氨基酸残基为节点的蛋白质的研究人员来说,这意味着你可以输入更长的序列并增加每个残基的感受野。
SE(3)-Transformers 优化
与基线相比, NVIDIA 实现提供了一些优化。
融合键与值计算
在“自我注意”层中,将计算关键帧、查询和值张量。查询是图形节点特征,是输入特征的线性投影。另一方面,键和值是图形边缘特征。它们是使用 TFN 层计算的。这是 SE(3)-Transformer 中大多数计算发生的地方,也是大多数参数存在的地方。
基线实现使用两个独立的 TFN 层来计算键和值。在 NVIDIA 实现中,这些被融合在一个 TFN 中,通道数量增加了一倍。这将启动的小型 CUDA 内核数量减少一半,并更好地利用 GPU 并行性。径向轮廓是 TFN 内部完全连接的网络,也与此优化融合。概览如图 4 所示。
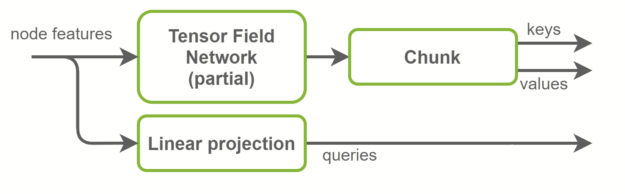
图 4 NVIDIA 实现中的键、查询和值计算。键和值一起计算,然后沿通道维度分块。
TFN 合并
SE(3)-Transformer 内部的功能除了其通道数量外,还有一个degreed,它是一个正整数。程度特征d有维度2d+1. TFN 接受不同程度的特征,使用张量积组合它们,并输出不同程度的特征。
对于输入为 4 度、输出为 4 度的图层,将考虑所有度的组合:理论上,必须计算 4 × 4 = 16 个子图层。
这些子层称为成对 TFN 卷积。图 5 显示了所涉及的子层的概述,以及每个子层的输入和输出维度。对给定输出度(列)的贡献相加,以获得最终特征。
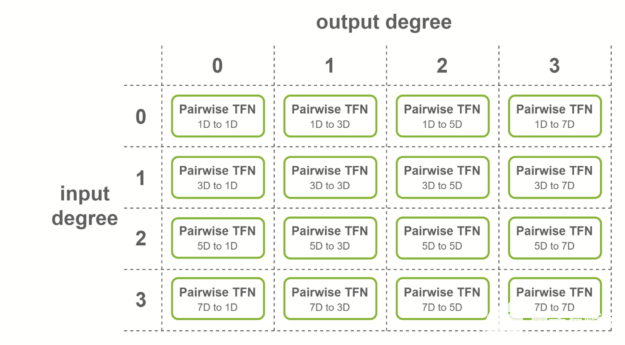
图 5 TFN 层中涉及的成对卷积,输入为 4 度,输出为 4 度。
NVIDIA 在满足 TFN 层上的某些条件时,提供多级融合以加速这些卷积。通过创建尺寸为 16 倍的形状,熔合层可以更有效地使用张量核。以下是应用熔合卷积的三种情况:
输出功能具有相同数量的通道
输入功能具有相同数量的通道
这两种情况都是正确的
第一种情况是,所有输出特征具有相同数量的通道,并且输出度数的范围从 0 到最大度数。在这种情况下,使用输出融合特征的融合卷积。该融合层用于 SE(3)-Transformers 的第一个 TFN 层。
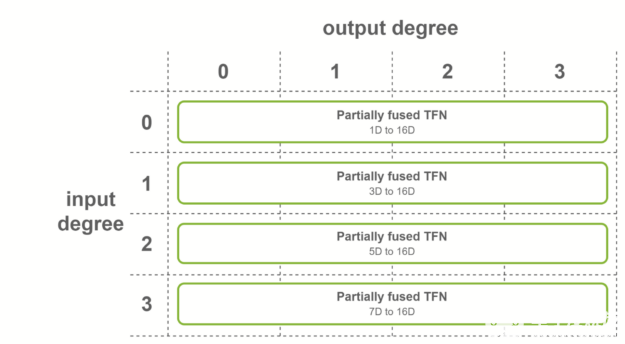
图 6 每个输出度的部分熔融 TFN 。
第二种情况是,所有输入特征具有相同数量的通道,并且输入度数的范围从 0 到最大度数。在这种情况下,使用对融合输入特征进行操作的融合卷积。该融合层用于 SE(3)-Transformers 的最后一层 TFN 。
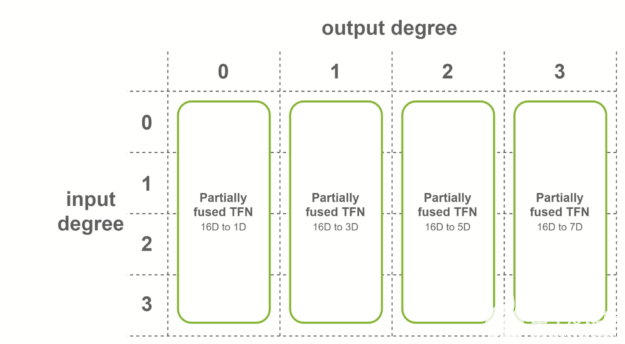
图 7 每个输入度的部分熔融 TFN 。
在最后一种情况下,当两个条件都满足时,使用完全融合的卷积。这些卷积作为输入融合特征,输出融合特征。这意味着每个 TFN 层只需要一个子层。内部 TFN 层使用此融合级别。
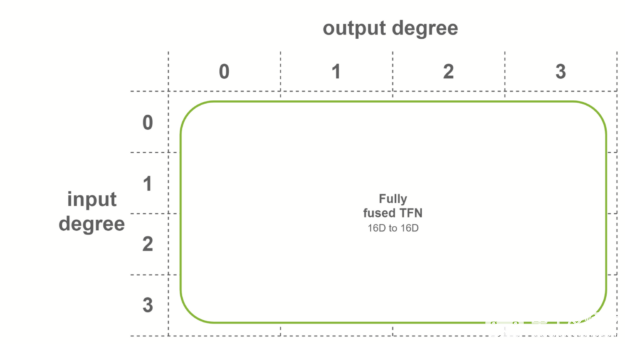
图 8 全熔合 TFN
基预计算
除了输入节点特性外, TFN 还需要基矩阵作为输入。每个图边都有一组矩阵,这些矩阵取决于目标节点和源节点之间的相对位置。
在基线实现中,这些矩阵在前向传递开始时计算,并在所有 TFN 层中共享。它们依赖于球形 h ARM ,计算起来可能很昂贵。由于输入图不会随着 QM9 数据集而改变(没有数据扩充,没有迭代位置细化),这就引入了跨时代的冗余计算。
NVIDIA 实现提供了在培训开始时预计算这些基础的选项。整个数据集迭代一次,基缓存在 RAM 中。前向传递开始时的计算基数过程被更快的 CPU 到 GPU 内存拷贝所取代。
关于作者
Alexandre Milesi 是 NVIDIA 的深度学习算法工程师。他拥有法国 UTC 的机器学习硕士学位,以及法国索邦大学的机器人和多智能体系统硕士学位。在加入 NVIDIA 之前, Alexandre 是伯克利实验室的附属研究员,使用深度强化学习解决电子 CTR ical 网格问题。在 NVIDIA ,他的工作集中于药物发现和计算机视觉的 DL 算法,包括等变图神经网络。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5103浏览量
104343 -
机器学习
+关注
关注
66文章
8459浏览量
133372 -
深度学习
+关注
关注
73文章
5527浏览量
121833
发布评论请先 登录
相关推荐
壁仞科技支持DeepSeek-V3满血版训练推理
Qwen大模型助力开发低成本AI推理方案
阿里云开源推理大模型QwQ
NVIDIA助力丽蟾科技打造AI训练与推理加速解决方案

NVIDIA助力提供多样、灵活的模型选择
NVIDIA Nemotron-4 340B模型帮助开发者生成合成训练数据

魔搭社区借助NVIDIA TensorRT-LLM提升LLM推理效率
英伟达推出全新NVIDIA AI Foundry服务和NVIDIA NIM推理微服务
英伟达推出AI模型推理服务NVIDIA NIM
摩尔线程和滴普科技完成大模型训练与推理适配
NVIDIA与Google DeepMind合作推动大语言模型创新
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
NVIDIA加速微软最新的Phi-3 Mini开源语言模型
李彦宏:开源模型将逐渐滞后,文心大模型提升训练与推理效率
基于NVIDIA Megatron Core的MOE LLM实现和训练优化






 工商网监
工商网监
评论