 Git引出一个经典的算法问题:最近公共祖先
Git引出一个经典的算法问题:最近公共祖先
如果说笔试的时候经常遇到各种动归回溯的骚操作,那么面试会倾向于一些比较经典的问题,难度不算大,而且也比较实用。
本文就用 Git 引出一个经典的算法问题:最近公共祖先(Lowest Common Ancestor,简称 LCA)。
git pull这个命令我们经常会用,它默认是使用merge方式将远端别人的修改拉到本地;如果带上参数git pull -r,就会使用rebase的方式将远端修改拉到本地。
这二者最直观的区别就是:merge方式合并的分支会看到很多「分叉」,而rebase方式合并的分支就是一条直线。但无论哪种方式,如果存在冲突,Git 都会检测出来并让你手动解决冲突。
那么问题来了,Git 是如何合并两条分支并检测冲突的呢?
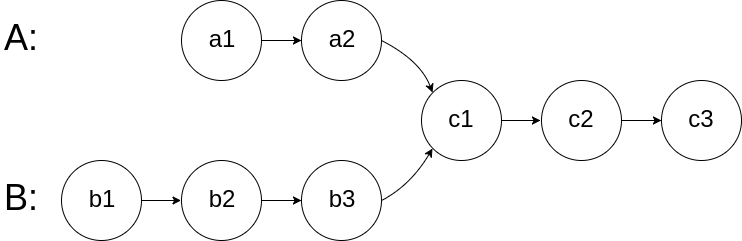
以rebase命令为例,比如下图的情况,我站在dev分支执行git rebase master,然后dev就会接到master分支之上:
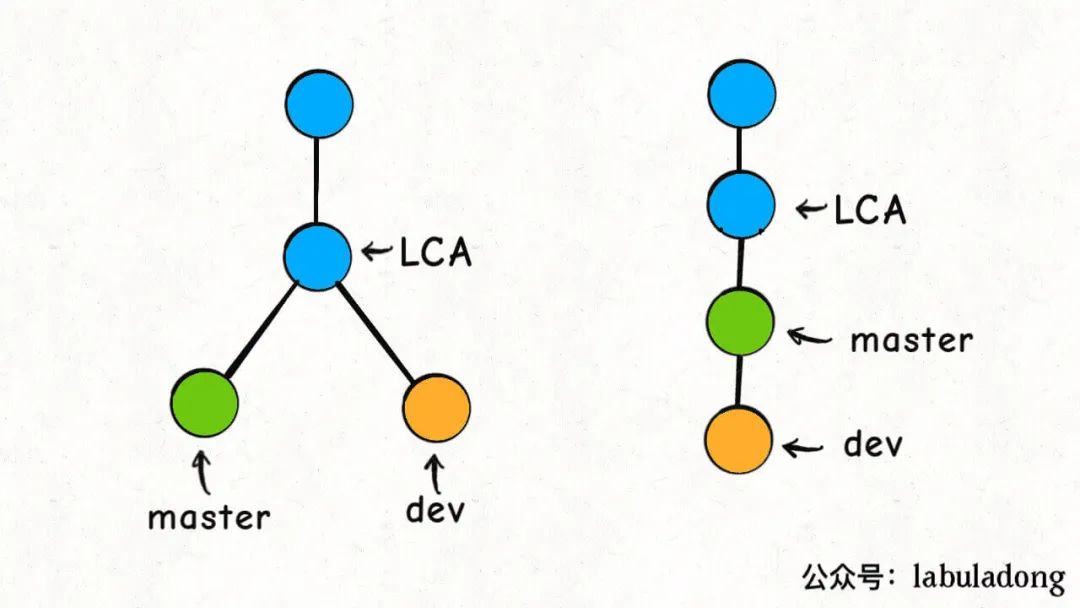
这个过程中,Git 是这么做的:
首先,找到这两条分支的最近公共祖先LCA,然后从master节点开始,重演LCA到dev的commit的修改,如果这些修改和LCA到master的commit有冲突,就会提示你手动解决冲突,最后的结果就是把dev的分支完全接到master上面。
那么,Git 是如何找到两条不同分支的最近公共祖先的呢?这就是一个经典的算法问题了,下面我来由浅入深讲一讲。
寻找一个元素
先不管最近公共祖先问题,我请你实现一个简单的算法:
给你输入一棵没有重复元素的二叉树根节点root和一个目标值val,请你写一个函数寻找树中值为val的节点。
函数签名如下:
TreeNodefind(TreeNoderoot,intval);
这个函数应该很容易实现对吧,比如我这样写代码:
//定义:在以 root 为根的二叉树中寻找值为 val 的节点
TreeNodefind(TreeNoderoot,intval){
//basecase
if(root==null){
returnnull;
}
//看看root.val是不是要找的
if(root.val==val){
returnroot;
}
//root不是目标节点,那就去左子树找
TreeNodeleft=find(root.left,val);
if(left!=null){
returnleft;
}
//左子树找不着,那就去右子树找
TreeNoderight=find(root.right,val);
if(right!=null){
returnright;
}
//实在找不到了
returnnull;
}
这段代码应该不用我多解释了,但我基于这段代码做一些简单的改写,请你分析一下我的改动会造成什么影响。
PS:如果你没读过前文东哥带你刷二叉树(纲领篇),强烈建议阅读一下,理解二叉树前中后序遍历的奥义。
首先,我修改一下 return 的位置:
TreeNodefind(TreeNoderoot,intval){
if(root==null){
returnnull;
}
//前序位置
if(root.val==val){
returnroot;
}
//root不是目标节点,去左右子树寻找
TreeNodeleft=find(root.left,val);
TreeNoderight=find(root.right,val);
//看看哪边找到了
returnleft!=null?left:right;
}
这段代码也可以达到目的,但是实际运行的效率会低一些,原因也很简单,如果你能够在左子树找到目标节点,还有没有必要去右子树找了?没有必要。但这段代码还是会去右子树找一圈,所以效率相对差一些。
更进一步,我把对root.val的判断从前序位置移动到后序位置:
TreeNodefind(TreeNoderoot,intval){
if(root==null){
returnnull;
}
//先去左右子树寻找
TreeNodeleft=find(root.left,val);
TreeNoderight=find(root.right,val);
//后序位置,看看root是不是目标节点
if(root.val==val){
returnroot;
}
//root不是目标节点,再去看看哪边的子树找到了
returnleft!=null?left:right;
}
这段代码相当于你先去左右子树找,然后才检查root,依然可以到达目的,但是效率会进一步下降。因为这种写法必然会遍历二叉树的每一个节点。
对于之前的解法,你在前序位置就检查root,如果输入的二叉树根节点的值恰好就是目标值val,那么函数直接结束了,其他的节点根本不用搜索。
但如果你在后序位置判断,那么就算根节点就是目标节点,你也要去左右子树遍历完所有节点才能判断出来。
最后,我再改一下题目,现在不让你找值为val的节点,而是寻找值为val1或val2的节点,函数签名如下:
TreeNodefind(TreeNoderoot,intval1,intval2);
这和我们第一次实现的find函数基本上是一样的,而且你应该知道可以有多种写法,我选择这样写代码:
//定义:在以 root 为根的二叉树中寻找值为 val1 或 val2 的节点
TreeNodefind(TreeNoderoot,intval1,intval2){
//basecase
if(root==null){
returnnull;
}
//前序位置,看看root是不是目标值
if(root.val==val1||root.val==val2){
returnroot;
}
//去左右子树寻找
TreeNodeleft=find(root.left,val1,val2);
TreeNoderight=find(root.right,val1,val2);
//后序位置,已经知道左右子树是否存在目标值
returnleft!=null?left:right;
}
为什么要写这样一个奇怪的find函数呢?因为最近公共祖先系列问题的解法都是把这个函数作为框架的。
下面一道一道题目来看。
秒杀五道题目
先来看看力扣第 236 题「二叉树的最近公共祖先」:
给你输入一棵不含重复值的二叉树,以及存在于树中的两个节点p和q,请你计算p和q的最近公共祖先节点。
PS:后文我用
LCA(Lowest Common Ancestor)作为最近公共祖先节点的缩写。
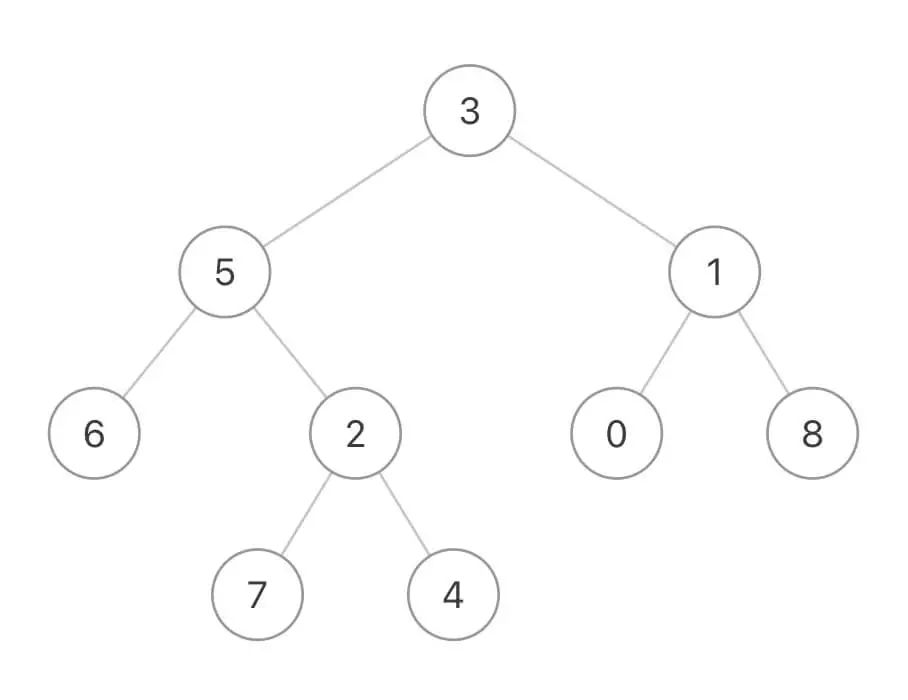
比如输入这样一棵二叉树:
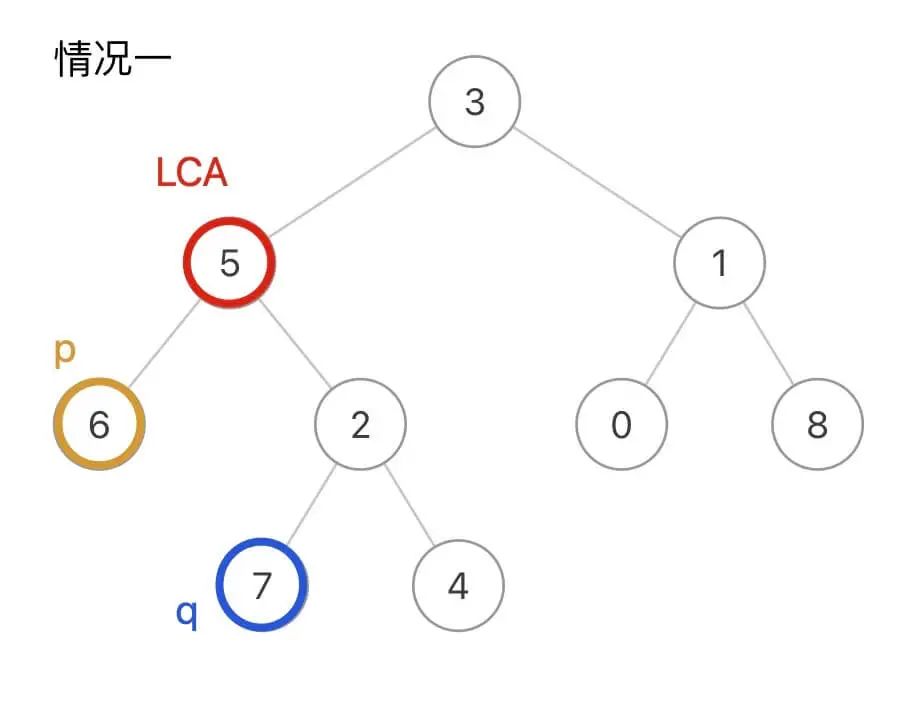
如果p是节点6,q是节点7,那么它俩的LCA就是节点5:
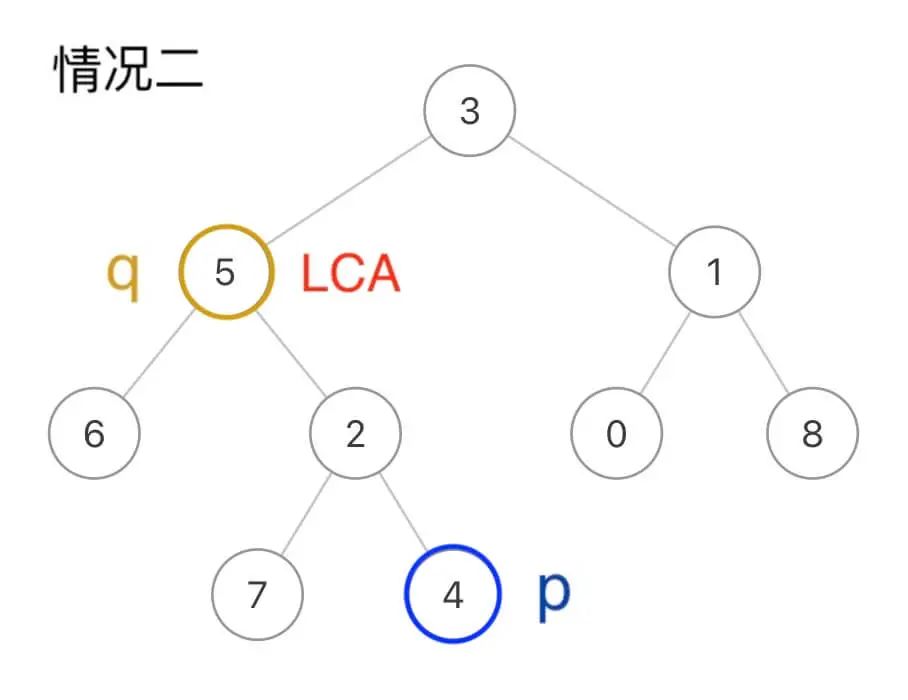
当然,p和q本身也可能是LCA,比如这种情况q本身就是LCA节点:
两个节点的最近公共祖先其实就是这两个节点向根节点的「延长线」的交汇点,那么对于任意一个节点,它怎么才能知道自己是不是p和q的最近公共祖先?
如果一个节点能够在它的左右子树中分别找到p和q,则该节点为LCA节点。
这就要用到之前实现的find函数了,只需在后序位置添加一个判断逻辑,即可改造成寻找最近公共祖先的解法代码:
TreeNodelowestCommonAncestor(TreeNoderoot,TreeNodep,TreeNodeq){
returnfind(root,p.val,q.val);
}
//在二叉树中寻找val1和val2的最近公共祖先节点
TreeNodefind(TreeNoderoot,intval1,intval2){
if(root==null){
returnnull;
}
//前序位置
if(root.val==val1||root.val==val2){
//如果遇到目标值,直接返回
returnroot;
}
TreeNodeleft=find(root.left,val1,val2);
TreeNoderight=find(root.right,val1,val2);
//后序位置,已经知道左右子树是否存在目标值
if(left!=null&&right!=null){
//当前节点是LCA节点
returnroot;
}
returnleft!=null?left:right;
}
在find函数的后序位置,如果发现left和right都非空,就说明当前节点是LCA节点,即解决了第一种情况:
在find函数的前序位置,如果找到一个值为val1或val2的节点则直接返回,恰好解决了第二种情况:
因为题目说了p和q一定存在于二叉树中(这点很重要),所以即便我们遇到q就直接返回,根本没遍历到p,也依然可以断定p在q底下,q就是LCA节点。
这样,标准的最近公共祖先问题就解决了,接下来看看这个题目有什么变体。
比如力扣第 1676 题「二叉树的最近公共祖先 IV」:
依然给你输入一棵不含重复值的二叉树,但这次不是给你输入p和q两个节点了,而是给你输入一个包含若干节点的列表nodes(这些节点都存在于二叉树中),让你算这些节点的最近公共祖先。
函数签名如下:
TreeNodelowestCommonAncestor(TreeNoderoot,TreeNode[]nodes);
比如还是这棵二叉树:
输入nodes = [7,4,6],那么函数应该返回节点5。
看起来怪吓人的,实则解法逻辑是一样的,把刚才的代码逻辑稍加改造即可解决这道题:
TreeNodelowestCommonAncestor(TreeNoderoot,TreeNode[]nodes){
//将列表转化成哈希集合,便于判断元素是否存在
HashSetvalues=newHashSet<>();
for(TreeNodenode:nodes){
values.add(node.val);
}
returnfind(root,values);
}
//在二叉树中寻找values的最近公共祖先节点
TreeNodefind(TreeNoderoot,HashSetvalues) {
if(root==null){
returnnull;
}
//前序位置
if(values.contains(root.val)){
returnroot;
}
TreeNodeleft=find(root.left,values);
TreeNoderight=find(root.right,values);
//后序位置,已经知道左右子树是否存在目标值
if(left!=null&&right!=null){
//当前节点是LCA节点
returnroot;
}
returnleft!=null?left:right;
}
有刚才的铺垫,你类比一下应该不难理解这个解法。
不过需要注意的是,这两道题的题目都明确告诉我们这些节点必定存在于二叉树中,如果没有这个前提条件,就需要修改代码了。
比如力扣第 1644 题「二叉树的最近公共祖先 II」:
给你输入一棵不含重复值的二叉树的,以及两个节点p和q,如果p或q不存在于树中,则返回空指针,否则的话返回p和q的最近公共祖先节点。
在解决标准的最近公共祖先问题时,我们在find函数的前序位置有这样一段代码:
//前序位置
if(root.val==val1||root.val==val2){
//如果遇到目标值,直接返回
returnroot;
}
我也进行了解释,因为p和q都存在于树中,所以这段代码恰好可以解决最近公共祖先的第二种情况:
但对于这道题来说,p和q不一定存在于树中,所以你不能遇到一个目标值就直接返回,而应该对二叉树进行完全搜索(遍历每一个节点),如果发现p或q不存在于树中,那么是不存在LCA的。
回想我在文章开头分析的几种find函数的写法,哪种写法能够对二叉树进行完全搜索来着?
这种:
TreeNodefind(TreeNoderoot,intval){
if(root==null){
returnnull;
}
//先去左右子树寻找
TreeNodeleft=find(root.left,val);
TreeNoderight=find(root.right,val);
//后序位置,判断root是不是目标节点
if(root.val==val){
returnroot;
}
//root不是目标节点,再去看看哪边的子树找到了
returnleft!=null?left:right;
}
那么解决这道题也是类似的,我们只需要把前序位置的判断逻辑放到后序位置即可:
//用于记录p和q是否存在于二叉树中
booleanfoundP=false,foundQ=false;
TreeNodelowestCommonAncestor(TreeNoderoot,TreeNodep,TreeNodeq){
TreeNoderes=find(root,p.val,q.val);
if(!foundP||!foundQ){
returnnull;
}
//p和q都存在二叉树中,才有公共祖先
returnres;
}
//在二叉树中寻找val1和val2的最近公共祖先节点
TreeNodefind(TreeNoderoot,intval1,intval2){
if(root==null){
returnnull;
}
TreeNodeleft=find(root.left,val1,val2);
TreeNoderight=find(root.right,val1,val2);
//后序位置,判断当前节点是不是LCA节点
if(left!=null&&right!=null){
returnroot;
}
//后序位置,判断当前节点是不是目标值
if(root.val==val1||root.val==val2){
//找到了,记录一下
if(root.val==val1)foundP=true;
if(root.val==val2)foundQ=true;
returnroot;
}
returnleft!=null?left:right;
}
这样改造,对二叉树进行完全搜索,同时记录p和q是否同时存在树中,从而满足题目的要求。
接下来,我们再变一变,如果让你在二叉搜索树中寻找p和q的最近公共祖先,应该如何做呢?
PS:二叉搜索树相关的题目详解见东哥带你刷二叉搜索树。
看力扣第 235 题「二叉搜索树的最近公共祖先」:
给你输入一棵不含重复值的二叉搜索树,以及存在于树中的两个节点p和q,请你计算p和q的最近公共祖先节点。
把之前的解法代码复制过来肯定也可以解决这道题,但没有用到 BST「左小右大」的性质,显然效率不是最高的。
在标准的最近公共祖先问题中,我们要在后序位置通过左右子树的搜索结果来判断当前节点是不是LCA:
TreeNodeleft=find(root.left,val1,val2);
TreeNoderight=find(root.right,val1,val2);
//后序位置,判断当前节点是不是LCA节点
if(left!=null&&right!=null){
returnroot;
}
但对于 BST 来说,根本不需要老老实实去遍历子树,由于 BST 左小右大的性质,将当前节点的值与val1和val2作对比即可判断当前节点是不是LCA:
假设val1 < val2,那么val1 <= root.val <= val2则说明当前节点就是LCA;若root.val比val1还小,则需要去值更大的右子树寻找LCA;若root.val比val2还大,则需要去值更小的左子树寻找LCA。
依据这个思路就可以写出解法代码:
TreeNodelowestCommonAncestor(TreeNoderoot,TreeNodep,TreeNodeq){
//保证val1较小,val2较大
intval1=Math.min(p.val,q.val);
intval2=Math.max(p.val,q.val);
returnfind(root,val1,val2);
}
//在BST中寻找val1和val2的最近公共祖先节点
TreeNodefind(TreeNoderoot,intval1,intval2){
if(root==null){
returnnull;
}
if(root.val>val2){
//当前节点太大,去左子树找
returnfind(root.left,val1,val2);
}
if(root.val< val1) {
//当前节点太小,去右子树找
returnfind(root.right,val1,val2);
}
//val1<= root.val <= val2
//则当前节点就是最近公共祖先
returnroot;
}
再看最后一道最近公共祖先的题目吧,力扣第 1650 题「二叉树的最近公共祖先 III」,这次输入的二叉树节点比较特殊,包含指向父节点的指针:
classNode{
intval;
Nodeleft;
Noderight;
Nodeparent;
};
给你输入一棵存在于二叉树中的两个节点p和q,请你返回它们的最近公共祖先,函数签名如下:
NodelowestCommonAncestor(Nodep,Nodeq);
由于节点中包含父节点的指针,所以二叉树的根节点就没必要输入了。
这道题其实不是公共祖先的问题,而是单链表相交的问题,你把parent指针想象成单链表的next指针,题目就变成了:
给你输入两个单链表的头结点p和q,这两个单链表必然会相交,请你返回相交点。
我在前文单链表的六大解题套路中详细讲解过求链表交点的问题,具体思路在本文就不展开了,直接给出本题的解法代码:
NodelowestCommonAncestor(Nodep,Nodeq){
//施展链表双指针技巧
Nodea=p,b=q;
while(a!=b){
//a走一步,如果走到根节点,转到q节点
if(a==null)a=q;
elsea=a.parent;
//b走一步,如果走到根节点,转到p节点
if(b==null)b=p;
elseb=b.parent;
}
returna;
}
至此,5 道最近公共祖先的题目就全部讲完了,前 3 道题目从一个基本的find函数衍生出解法,后 2 道比较特殊,分别利用了 BST 和单链表相关的技巧,希望本文对你有启发。
审核编辑 :李倩
-
算法
+关注
关注
23文章
4629浏览量
93260 -
检测
+关注
关注
5文章
4511浏览量
91707 -
Git
+关注
关注
0文章
201浏览量
15810
原文标题:一文秒杀 5 道最近公共祖先问题
文章出处:【微信号:TheAlgorithm,微信公众号:算法与数据结构】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
飞凌嵌入式ElfBoard ELF 1板卡-移植前准备之git管理内核源码
飞凌嵌入式ElfBoard ELF 1板卡-git管理源码之git安装和使用
TimSort:一个在标准函数库中广泛使用的排序算法
华为云 Flexus X 实例部署安装 HivisionIDPhoto 一个轻量级的 AI 证件照制作算法
热电偶需要10个而AD7124-8最多只支持8个,能不能用3个AIN实现2个热电偶输入,其中一个AIN作为公共的负输入端?
Pure path studio内能否自己创建一个component,来实现特定的算法,例如LMS算法?
基于ArkTS语言的OpenHarmony APP应用开发:公共事件的订阅和发布
光伏组件引出端机械负载下的强度测试







 工商网监
工商网监
评论