 使用CUDA流顺序内存分配器助于提高现有应用程序的性能
使用CUDA流顺序内存分配器助于提高现有应用程序的性能
在 本系列的第 1 部分 中,我们引入了新的 API 函数 cudaMallocAsync 和 cudaFreeAsync ,它们使内存分配和释放成为流顺序操作。在这篇文章中,我们通过分享一些大数据基准测试结果来强调这一新功能的好处,并为修改现有应用程序提供代码 MIG 定量指南。我们还介绍了在多 GPU 访问和 IPC 使用环境中利用流顺序内存分配的高级主题。这一切都有助于提高现有应用程序的性能。
GPU 大数据基准
为了衡量新的流式有序分配器在实际应用程序中的性能影响,以下是来自 RAPIDS GPU 大数据基准 ( GPU -bdb]的结果。 GPU -bdb 是 30 个查询的基准,这些查询以各种比例因子表示现实世界的数据科学和机器学习工作流: SF1000 是 1 TB 的数据, SF10000 是 10 TB 的数据。事实上,每个查询都是一个模型工作流,可以包括 SQL 、用户定义函数、仔细的子集和聚合以及机器学习。
图 1 显示了在 SF1000 上在 NVIDIA DGX-2 上跨 16 个 V100 GPU 执行的 gpu-bdb 查询子集的 cudaMallocAsync 与 cudaMalloc 的性能比较。如您所见,由于内存重用和消除无关同步,使用 cudaMallocAsync 时端到端性能提高了 2-5 倍。
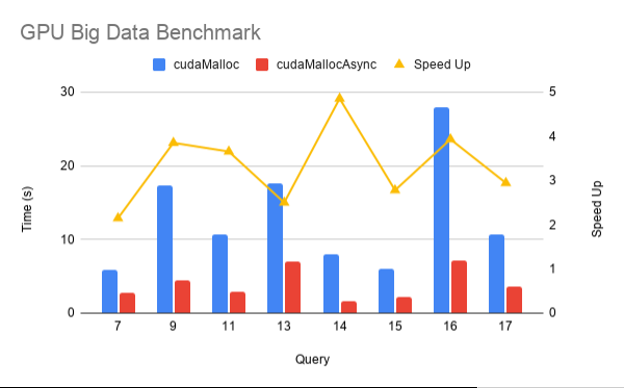
图 1 加速 cudaMallocAsync 结束 cudaMalloc 对于 RAPIDS GPU 大数据基准的各种查询 。
与 CUDA Malloc 和 CUDA Free 的互操作性
应用程序可以使用 cudaFreeAsync 释放 cudaMalloc 分配的指针。在下一次同步传递到 cudaFreeAsync 的流之前,不会释放基础内存。
cudaMalloc(&ptr, size); kernel<<<..., stream>>>(ptr); cudaFreeAsync(ptr, stream); cudaStreamSynchronize(stream); // The memory for ptr is freed at this point
类似地,应用程序可以使用 cudaFree 释放使用 cudaMallocAsync 分配的内存。但是,在这种情况下, cudaFree 不会隐式同步,因此应用程序必须插入适当的同步,以确保对要释放的内存的所有访问都已完成。任何有意或无意依赖 cudaFree 的隐式同步行为的应用程序代码都必须更新。
cudaMallocAsync(&ptr, size, stream); kernel<<<..., stream>>>(ptr); cudaStreamSynchronize(stream); // Must synchronize first cudaFree(ptr);
多 – GPU 访问
默认情况下,可以从与指定流关联的设备访问使用 cudaMallocAsync 分配的内存。从任何其他设备访问内存需要启用从该其他设备访问整个池。正如 cudaDeviceCanAccessPeer 所报告的,它还要求这两个设备具有对等功能。与 cudaMalloc 分配不同, cudaDeviceEnablePeerAccess 和 cudaDeviceDisablePeerAccess 对从内存池分配的内存没有影响。
例如,考虑启用设备 4Access 到设备 3 的内存池:
cudaMemPool_t mempool; cudaDeviceGetDefaultMemPool(&mempool, 3); cudaMemAccessDesc desc = {}; desc.location.type = cudaMemLocationTypeDevice; desc.location.id = 4; desc.flags = cudaMemAccessFlagsProtReadWrite; cudaMemPoolSetAccess(mempool, &desc, 1 /* numDescs */);
调用 cudaMemPoolSetAccess 时,可以使用 cudaMemAccessFlagsProtNone 撤销对内存池所在设备以外的设备的访问。无法撤消对内存池自身设备的访问。
进程间通信支持
使用与设备关联的默认内存池分配的内存不能与其他进程共享。应用程序必须显式创建自己的内存池,以便与其他进程共享使用 cudaMallocAsync 分配的内存。以下代码示例显示如何创建具有进程间通信( IPC )功能的显式内存池:
cudaMemPool_t exportPool;
cudaMemPoolProps poolProps = {};
poolProps.allocType = cudaMemAllocationTypePinned;
poolProps.handleTypes = cudaMemHandleTypePosixFileDescriptor;
poolProps.location.type = cudaMemLocationTypeDevice;
poolProps.location.id = deviceId;
cudaMemPoolCreate(&exportPool, &poolProps);
位置类型设备和位置 ID deviceId 指示必须在特定 GPU 上分配池内存。分配类型 pinted 表示内存应该是 non-migratable ,也称为不可分页。句柄类型 PosixFileDescriptor 表示用户打算查询池的文件描述符,以便与其他进程共享。
通过 IPC 共享此池中的内存的第一步是查询表示该池的文件描述符:
int fd; cudaMemAllocationHandleType handleType = cudaMemHandleTypePosixFileDescriptor; cudaMemPoolExportToShareableHandle(&fd, exportPool, handleType, 0);
然后,应用程序可以与另一个进程共享文件描述符,例如通过 UNIX 域套接字。然后,另一个进程可以导入文件描述符并获得进程本地池句柄:
cudaMemPool_t importPool; cudaMemAllocationHandleType handleType = cudaMemHandleTypePosixFileDescriptor; cudaMemPoolImportFromShareableHandle(&importPool, &fd, handleType, 0);
下一步是导出过程从池中分配内存:
cudaMallocFromPoolAsync(&ptr, size, exportPool, stream);
cudaMallocAsync还有一个重载版本,它采用与cudaMallocFromPoolAsync相同的参数:
cudaMallocAsync(&ptr, size, exportPool, stream);
通过这两个 API 中的任何一个从该池分配内存后,指针就可以与导入进程共享。首先,导出过程获得一个表示内存分配的不透明句柄:
cudaMemPoolPtrExportData data; cudaMemPoolExportPointer(&data, ptr);
然后,可以通过任何标准 IPC 机制(例如通过共享内存、管道等)与导入进程共享此不透明数据。导入进程然后将不透明数据转换为进程本地指针:
cudaMemPoolImportPointer(&ptr, importPool, &data);
现在,两个进程共享对相同内存分配的访问。在导出过程中释放内存之前,必须先在导入过程中释放内存。这是为了确保在导出过程中,当导入过程仍在访问以前的共享内存分配时,内存不会重新用于另一个 cudaMallocAsync 请求,从而可能导致未定义的行为。
现有函数 cudaIpcGetMemHandle 仅适用于通过 cudaMalloc 分配的内存,不能用于通过 cudaMallocAsync 分配的任何内存,无论该内存是否从显式池分配。
更改设备池
如果应用程序期望大部分时间使用显式内存池,则可以考虑通过 cudaDeviceSetMemPool 将其设置为设备的当前池。这使应用程序可以避免每次必须从池中分配内存时都必须指定池参数。
cudaDeviceSetMemPool(device, pool); cudaMallocAsync(&ptr, size, stream); // This now allocates from the earlier pool set instead of the device’s default pool.
这样做的好处是,使用 cudaMallocAsync 分配的任何其他函数现在都会自动使用新池作为默认池。可以使用 cudaDeviceGetMemPool 查询与设备关联的当前池。
库可组合性
通常,库不应该更改设备的池,因为这样做会影响整个顶级应用程序。如果库必须分配具有不同于默认设备池属性的内存,它可以创建自己的池,然后使用 cudaMallocFromPoolAsync 从该池进行分配。该库还可以使用 cudaMallocAsync 的重载版本,该版本将池作为参数。
为了使应用程序的互操作更容易,库应该考虑为顶级应用程序提供 API 以协调所使用的池。例如,库可以提供 set 或 get API ,使应用程序能够以更明确的方式控制池。库还可以将池作为单个 API 的参数。
代码迁移指南
当将使用 cudaMalloc 或 cudaFree 的现有应用程序移植到新的 cudaMallocAsync 或 cudaFreeAsync API 时,考虑以下准则。
确定适当人才库的指南:
初始默认池适用于许多应用程序。
今天,显式构造的池只需要在与 CUDA IPC 的进程之间共享池内存。这可能会随着将来的功能而改变。
为了方便起见,考虑将显式创建池设置为设备的当前池,以确保进程内的所有 cudaMallocAsync 调用都使用该池。这必须由顶级应用程序而不是库来完成,以避免与顶级应用程序的目标冲突。
为所有内存池设置释放阈值的准则:
设备的共享和释放方式取决于:
对单个进程是独占的 :使用最大释放阈值。
在合作进程之间共享 :通过 IPC 协调使用相同的池,或将每个进程池设置为适当的值,以避免任何一个进程独占所有设备内存。
在未知进程之间共享: 如果已知,请将阈值设置为应用程序的工作集大小。否则,在使用非零值之前,请将其保留为零,并使用探查器确定分配性能是否是瓶颈。
用 cudaMallocAsync 替换 cudaMalloc 的指南:
确保所有内存访问都是在流顺序分配之后排序的。
如果需要对等访问,请使用 cudaMemPoolSetAccess ,因为 cudaEnablePeerAccess 和 cudaDisablePeerAccesss 对池内存没有影响。
与 cudaMalloc 分配不同, cudaDeviceReset 不会隐式释放池内存,因此必须显式释放。
如果使用 cudaFree 释放,请确保在释放之前通过适当的同步完成所有访问,因为在这种情况下没有隐式同步。依赖隐式同步的任何后续代码也可能需要更新。
如果内存通过 IPC 与另一个进程共享,请从显式创建的支持 IPC 的池中进行分配,并删除该指针对 cudaIpcGetMemHandle 、 cudaIpcOpenMemHandle 和 cudaIpcCloseMemHandle 的所有引用。
如果该内存必须与 GPU 直接 RDMA 一起使用,请暂时继续使用 cudaMalloc ,因为通过 cudaMallocAsync 分配的内存目前不支持它。 CUDA 打算在将来支持它。
与使用 cudaMalloc 分配的内存不同,使用 cudaMallocAsync 分配的内存与 CUDA 上下文不关联。这有以下影响:
使用属性 CU_POINTER_ATTRIBUTE_CONTEXT 调用 cuPointerGetAttribute 会为上下文返回 null 。
当使用至少一个使用 cudaMallocAsync 分配的源或目标指针调用 cudaMemcpy 时,必须可以从调用线程的当前上下文/设备访问该内存。如果无法从该上下文或设备访问,请改用 cudaMemcpyPeer 。
将 cudaFree 替换为 cudaFree 的指南
确保所有内存访问都是在按流排序的释放之前排序的。
在下一次同步操作之前,可能无法将内存释放回系统。如果释放阈值设置为非零值,则在显式修剪相应的池之前,可能无法将内存释放回系统。
与 cudaFree 不同, cudaFreeAsync 不会隐式同步设备。任何依赖此隐式同步的代码都必须更新为显式同步。
结论
CUDA 11 。 2 中添加的流式有序分配器以及 cudaMallocAsync 和 cudaFreeAsync API 函数通过将内存分配和释放作为流式有序操作引入 CUDA 流编程模型,扩展了 CUDA 流编程模型。这使得分配的范围能够限定到内核,内核使用它们,同时避免了传统 cudaMalloc/cudaFree 可能发生的昂贵的设备范围同步。
此外,这些 API 函数在 CUDA 中添加了内存池的概念,从而实现了内存的重用,从而避免了代价高昂的系统调用并提高了性能。使用指南 MIG 评估您现有的代码,并查看您的应用程序性能有多大改进!
关于作者
Vivek Kini 是 NVIDIA 的高级系统软件工程师。他致力于 CUDA 驱动程序,特别关注内存管理功能。他旨在简化 CUDA 应用程序的内存管理,而不牺牲它们所需的性能。
Jake Hemstad 是一个高级开发工程师 NVIDIA ,他在开发高性能 CUDA C ++软件加速数据分析。他同样关心开发高质量的软件,正如他实现最佳的 GPU 性能一样,也是现代 C ++设计的倡导者。在 NVIDIA 之前,他参加了明尼苏达大学的研究生院,在那里他与桑迪亚国家实验室在任务并行 HPC 运行时间和稀疏线性求解器上工作。
审核编辑:郭婷
-
gpu
+关注
关注
28文章
4795浏览量
129506 -
API
+关注
关注
2文章
1522浏览量
62507 -
CUDA
+关注
关注
0文章
121浏览量
13706
发布评论请先 登录
相关推荐
PS2-185/NF带状线2路电源分配器
英迈质谱流路分配器:精准控制,引领质谱分析新高度
CDCL1810A 1.8V、10 输出高性能时钟分配器数据表

CDCL1810 1.8V 10路输出高性能时钟分配器数据表
液压分配器起什么作用的
液压分配器工作原理是什么
液压分配器压力调整方法有哪些
单线分配器与双线分配器的区别是什么
四路数据分配器的基本概念、工作原理、应用场景及设计方法
八路数据分配器的基本概念及工作原理
Linux内核内存管理之slab分配器





 工商网监
工商网监
评论