 使用NVIDIA CUDA流顺序内存分配器
使用NVIDIA CUDA流顺序内存分配器
大多数 CUDA 开发人员都熟悉 cudaMalloc 和 cudaFree API 函数来分配 GPU 可访问内存。然而,这些 API 函数长期以来一直存在一个障碍:它们不是按流排序的。在本文中,我们将介绍新的 API 函数 cudaMallocAsync 和 cudaFreeAsync ,它们使内存分配和释放成为流式有序操作。
在 本系列的第 2 部分 中,我们通过共享一些大数据基准测试结果来强调这一新功能的好处,并为修改现有应用程序提供代码 MIG 定量指南。我们还介绍了在多 GPU 访问和 IPC 使用环境中利用流顺序内存分配的高级主题。这一切都有助于提高现有应用程序的性能。
流排序效率
下面左边的代码示例效率低下,因为第一个 cudaFree 调用必须等待 kernelA 完成,所以它会在释放内存之前同步设备。为了提高运行效率,可以预先分配内存,并将其调整为两种大小中的较大值,如右图所示。
cudaMalloc(&ptrA, sizeA); kernelA<<<..., stream>>>(ptrA); cudaFree(ptrA); // Synchronizes the device before freeing memory cudaMalloc(&ptrB, sizeB); kernelB<<<..., stream>>>(ptrB); cudaFree(ptrB);
cudaMalloc(&ptr, max(sizeA, sizeB)); kernelA<<<..., stream>>>(ptr); kernelB<<<..., stream>>>(ptr); cudaFree(ptr);
这增加了应用程序中的代码复杂性,因为内存管理代码与业务逻辑分离。当涉及到其他图书馆时,问题就更加严重了。例如,考虑kernelA由库函数启动的情况,而不是:
libraryFuncA(stream);
cudaMalloc(&ptrB, sizeB);
kernelB<<<..., stream>>>(ptrB);
cudaFree(ptrB);
void libraryFuncA(cudaStream_t stream) {
cudaMalloc(&ptrA, sizeA);
kernelA<<<..., stream>>>(ptrA);
cudaFree(ptrA);
}
这对于应用程序来说要提高效率要困难得多,因为它可能无法完全查看或控制库正在执行的操作。为了避免这个问题,库必须在第一次调用该函数时分配内存,并且在库被取消初始化之前永远不会释放内存。这不仅增加了代码的复杂性,而且还会导致库占用内存的时间超过需要的时间,从而可能会阻止应用程序的另一部分使用该内存。
有些应用程序通过实现自己的自定义分配器,进一步提前分配内存。这为应用程序开发增加了大量复杂性。 CUDA 旨在提供一种低工作量、高性能的替代方案。
CUDA 11 。 2 引入了流式有序内存分配器来解决这些类型的问题,并添加了 cudaMallocAsync 和 cudaFreeAsync 。这些新的 API 函数将内存分配从同步整个设备的全局作用域操作转移到流顺序操作,从而使您能够将内存管理与 GPU 工作提交结合起来。这消除了同步未完成 GPU 工作的需要,并有助于将分配的生命周期限制为访问它的 GPU 工作。考虑下面的代码示例:
cudaMallocAsync(&ptrA, sizeA, stream); kernelA<<<..., stream>>>(ptrA); cudaFreeAsync(ptrA, stream); // No synchronization necessary cudaMallocAsync(&ptrB, sizeB, stream); // Can reuse the memory freed previously kernelB<<<..., stream>>>(ptrB); cudaFreeAsync(ptrB, stream);
现在可以在函数范围内管理内存,如下面启动kernelA的库函数示例所示。
libraryFuncA(stream);
cudaMallocAsync(&ptrB, sizeB, stream); // Can reuse the memory freed by the library call
kernelB<<<..., stream>>>(ptrB);
cudaFreeAsync(ptrB, stream);
void libraryFuncA(cudaStream_t stream) {
cudaMallocAsync(&ptrA, sizeA, stream);
kernelA<<<..., stream>>>(ptrA);
cudaFreeAsync(ptrA, stream); // No synchronization necessary
}
流有序分配语义
所有常用的流排序规则都适用于 cudaMallocAsync 和 cudaFreeAsync 。从 cudaMallocAsync 返回的内存可以被任何内核或 memcpy 操作访问,只要内核或 memcpy 被命令在分配操作之后和解除分配操作之前以流顺序执行。解除分配可以在任何流中执行,只要命令在分配操作之后以及在 GPU 上对该内存的所有流进行所有访问之后执行。
实际上,流顺序分配的行为就像分配和自由是内核一样。如果 kernelA 在流上生成有效缓冲区,并且 kernelB 在同一流上使其无效,则应用程序可以按照适当的流顺序在 kernelA 之后和 kernelB 之前自由访问缓冲区。
下面的示例显示了各种有效用法。
auto err = cudaMallocAsync(&ptr, size, streamA); // If cudaMallocAsync completes successfully, ptr is guaranteed to be // a valid pointer to memory that can be accessed in stream order assert(err == cudaSuccess); // Work launched in the same stream can access the memory because // operations within a stream are serialized by definition kernel<<<..., streamA>>>(ptr); // Work launched in another stream can access the memory as long as // the appropriate dependencies are added cudaEventRecord(event, streamA); cudaStreamWaitEvent(streamB, event, 0); kernel<<<..., streamB>>>(ptr); // Synchronizing the stream at a point beyond the allocation operation // also enables any stream to access the memory cudaEventSynchronize(event); kernel<<<..., streamC>>>(ptr); // Deallocation requires joining all the accessing streams. Here, // streamD will be deallocating. // Adding an event dependency on streamB ensures that all accesses in // streamB will be done before the deallocation cudaEventRecord(event, streamB); cudaStreamWaitEvent(streamD, event, 0); // Synchronizing streamC also ensures that all its accesses are done before // the deallocation cudaStreamSynchronize(streamC); cudaFreeAsync(ptr, streamD);
图 1 显示了在前面的代码示例中指定的各种依赖关系。如您所见,所有内核都被命令在分配操作之后执行,并在释放操作之前完成。
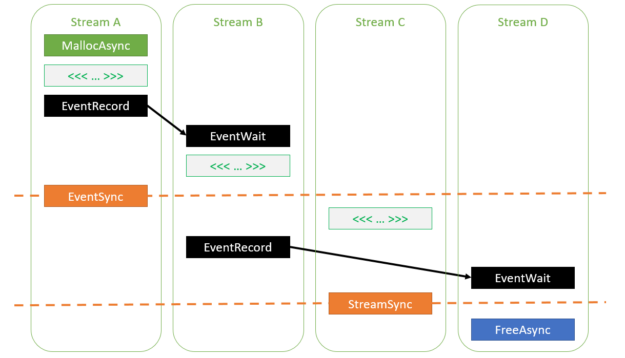
图 1 在流之间插入依赖关系的各种方法,以确保访问使用 cudaMallocAsync.
内存分配和释放不能异步失败。由于调用 cudaMallocAsync 或 cudaFreeAsync (例如,内存不足)而发生的内存错误会通过调用返回的错误代码立即报告。如果 cudaMallocAsync 成功完成,则返回的指针将保证是指向内存的有效指针,可以按照适当的流顺序安全访问。
err = cudaMallocAsync(&ptr, size, stream);
if (err != cudaSuccess) {
return err;
}
// Now you’re guaranteed that ‘ptr’ is valid when the kernel executes on stream
kernel<<<..., stream>>>(ptr);
cudaFreeAsync(ptr, stream);
CUDA 驱动程序使用内存池实现立即返回指针的行为。
内存池
流顺序内存分配器将 存储池 的概念引入 CUDA 。内存池是以前分配的内存的集合,可以重新用于将来的分配。在 CUDA 中,池由 cudaMemPool_t 句柄表示。每个设备都有一个默认池的概念,可以使用 cudaDeviceGetDefaultMemPool 查询其句柄。
您还可以显式创建自己的池,直接使用它们,或者将它们设置为设备的当前池,并间接使用它们。创建显式池的原因包括自定义配置,如本文后面所述。当没有显式创建的池被设置为设备的当前池时,默认池将充当当前池。
在没有显式池参数的情况下调用 cudaMallocAsync 时,每次调用都会从指定的流推断设备,并尝试从该设备的当前池分配内存。如果池内存不足, CUDA 驱动程序将调用操作系统以分配更多内存。对 cudaFreeAsync 的每次调用都会将内存返回到池中,然后可在后续 cudaMallocAsync 请求中重新使用该内存。池由 CUDA 驱动程序管理,这意味着应用程序可以在多个库之间实现池共享,而无需这些库相互协调。
如果使用 cudaMallocAsync 发出的内存分配请求由于相应内存池的碎片而无法提供服务, CUDA 驱动程序通过将池中未使用的内存重新映射到 GPU 虚拟地址空间的连续部分来对池进行碎片整理。重新映射现有池内存而不是从操作系统分配新内存也有助于降低应用程序的内存占用。
默认情况下,在事件、流或设备上的下一次同步操作期间,池中累积的未使用内存将返回到操作系统,如下面的代码示例所示。
cudaMallocAsync(ptr1, size1, stream); // Allocates new memory into the pool kernel<<<..., stream>>>(ptr); cudaFreeAsync(ptr1, stream); // Frees memory back to the pool cudaMallocAsync(ptr2, size2, stream); // Allocates existing memory from the pool kernel<<<..., stream>>>(ptr2); cudaFreeAsync(ptr2, stream); // Frees memory back to the pool cudaDeviceSynchronize(); // Frees unused memory accumulated in the pool back to the OS // Note: cudaStreamSynchronize(stream) achieves the same effect here
在池中保留内存
在某些情况下,将内存从池返回到系统可能会影响性能。考虑下面的代码示例:
for (int i = 0; i < 100; i++) {
cudaMallocAsync(&ptr, size, stream);
kernel<<<..., stream>>>(ptr);
cudaFreeAsync(ptr, stream);
cudaStreamSynchronize(stream);
}
默认情况下,流同步会导致与该流的设备关联的任何池将所有未使用的内存释放回系统。在本例中,这将在每次迭代结束时发生。因此,没有内存可供下次 cudaMallocAsync 调用重用,而必须通过昂贵的系统调用来分配内存。
为了避免这种昂贵的重新分配,应用程序可以配置一个释放阈值,以使未使用的内存在同步操作之后保持不变。释放阈值指定池缓存的最大内存量。在同步操作期间,它会将所有多余的内存释放回操作系统。
默认情况下,池的释放阈值为零。这意味着池中使用的内存在每次同步操作期间都会释放回操作系统。下面的代码示例演示如何更改释放阈值。
cudaMemPool_t mempool;
cudaDeviceGetDefaultMemPool(&mempool, device);
uint64_t threshold = UINT64_MAX;
cudaMemPoolSetAttribute(mempool, cudaMemPoolAttrReleaseThreshold, &threshold);
for (int i = 0; i < 100; i++) {
cudaMallocAsync(&ptr, size, stream);
kernel<<<..., stream>>>(ptr);
cudaFreeAsync(ptr, stream);
cudaStreamSynchronize(stream); // Only releases memory down to “threshold” bytes
}
使用非零释放阈值可以从一个迭代到下一个迭代重用内存。这只需要简单的簿记,并使 cudaMallocAsync 的性能独立于分配的大小,从而显著提高了内存分配性能(图 2 )。
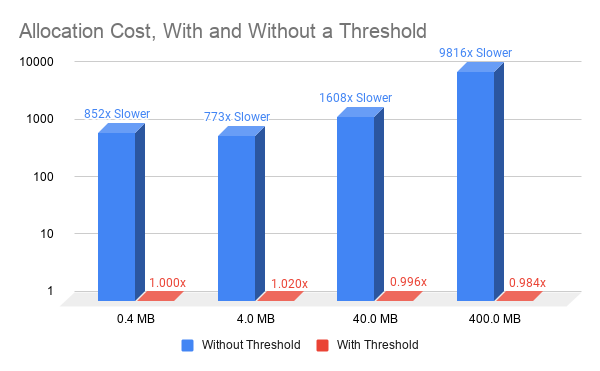
图 2 使用 cudaMallocAsync 设置和不设置释放阈值(与 0 。 4MB 性能相关的所有值,阈值分配) 。
池阈值只是一个提示。在相同的内存池中[0]可以隐式释放内存分配,以使内存分配成功。例如,对 cudaMalloc 或 cuMemCreate 的调用可能会导致 CUDA 从与同一进程中的设备关联的任何内存池中释放未使用的内存来为请求提供服务
这在应用程序使用多个库的情况下尤其有用,其中一些库使用 cudaMallocAsync ,而另一些库不使用 cudaMallocAsync 。通过自动释放未使用的池内存,这些库不必相互协调以使各自的分配请求成功。
CUDA 驱动程序自动将内存从池重新分配给不相关的分配请求时存在限制。例如,应用程序可能使用不同的接口(如 Vulkan 或 DirectX )来访问 GPU ,或者可能有多个进程同时使用 GPU 。这些上下文中的内存分配请求不会自动释放未使用的池内存。在这种情况下,应用程序可能必须通过调用 cudaMemPoolTrimTo 显式释放池中未使用的内存。
size_t bytesToKeep = 0; cudaMemPoolTrimTo(mempool, bytesToKeep);
bytesToKeep 参数告诉 CUDA 驱动程序它可以在池中保留多少字节。任何超过该大小的未使用内存都会释放回操作系统。
通过内存重用提高性能
cudaMallocAsync 和 cudaFreeAsync 的 stream 参数有助于 CUDA 高效地重用内存,避免对操作系统进行昂贵的调用。考虑下面的琐碎代码示例。
cudaMallocAsync(&ptr1, size1, stream); kernelA<<<..., stream>>>(ptr1); cudaFreeAsync(ptr1, stream); cudaMallocAsync(&ptr2, size2, stream); kernelB<<<..., stream>>>(ptr2);
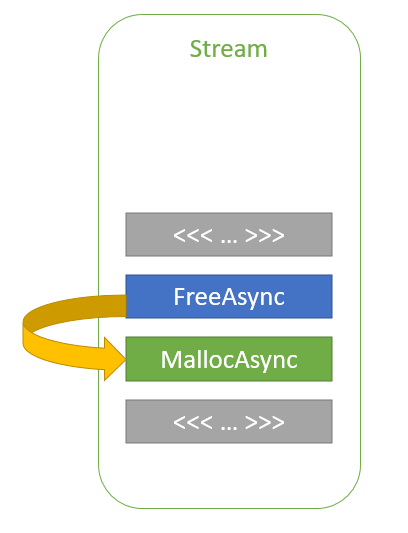
图 3 同一流中的内存重用 。
在这个代码示例中, ptr2 是在 ptr1 被释放后按流顺序分配的。 ptr2 分配可以重用用于 ptr1 的部分或全部内存,而无需任何同步,因为 kernelA 和 kernelB 在同一个流中启动。因此,流排序语义保证 kernelB 在 kernelA 完成之前不能开始执行和访问内存。通过这种方式, CUDA 驱动程序可以帮助降低应用程序的内存占用,同时提高分配性能。
CUDA 驱动程序还可以跟踪通过 CUDA 事件插入的流之间的依赖关系,如以下代码示例所示:
cudaMallocAsync(&ptr1, size1, streamA); kernelA<<<..., streamA>>>(ptr1); cudaFreeAsync(ptr1, streamA); cudaEventRecord(event, streamA); cudaStreamWaitEvent(streamB, event, 0); cudaMallocAsync(&ptr2, size2, streamB); kernelB<<<..., streamB>>>(ptr2);
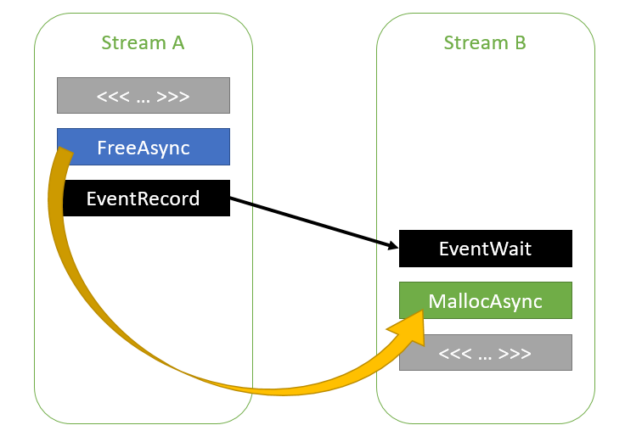
图 4 跨流的内存重用,它们之间有事件依赖关系 。
由于 CUDA 驱动程序知道流 A 和 B 之间的依赖关系,因此它可以重用 ptr1 为 ptr2 使用的内存。流 A 和 B 之间的依赖关系链可以包含任意数量的流,如下面的代码示例所示。
cudaMallocAsync(&ptr1, size1, streamA);
kernelA<<<..., streamA>>>(ptr1);
cudaFreeAsync(ptr1, streamA);
cudaEventRecord(event, streamA);
for (int i = 0; i < 100; i++) {
cudaStreamWaitEvent(streams[i], event, 0); // streams[] is a previously created array of streams
cudaEventRecord(event, streams[i]);
}
cudaStreamWaitEvent(streamB, event, 0);
cudaMallocAsync(&ptr2, size2, streamB);
kernelB<<<..., streamB>>>(ptr2);
如有必要,应用程序可以基于每个池禁用此功能:
int enable = 0; cudaMemPoolSetAttribute(mempool, cudaMemPoolReuseFollowEventDependencies, &enable);
CUDA 驱动程序还可以在没有应用程序指定的显式依赖项的情况下,有机会重用内存。虽然这种启发式方法可能有助于提高性能或避免内存分配失败,但它们会给应用程序增加不确定性,因此可以在每个池的基础上禁用。考虑下面的代码示例:
cudaMallocAsync(&ptr1, size1, streamA); kernelA<<<..., streamA>>>(ptr1); cudaFreeAsync(ptr1); cudaMallocAsync(&ptr2, size2, streamB); kernelB<<<..., streamB>>>(ptr2); cudaFreeAsync(ptr2);
在此场景中, streamA 和 streamB 之间没有明确的依赖关系。但是, CUDA 驱动程序知道每个流执行了多远。如果在第二次调用 streamB 中的 cudaMallocAsync 时, CUDA 驱动程序确定 kernelA 已在 GPU 上完成执行,则它可以重用 ptr1 用于 ptr2 的部分或全部内存。
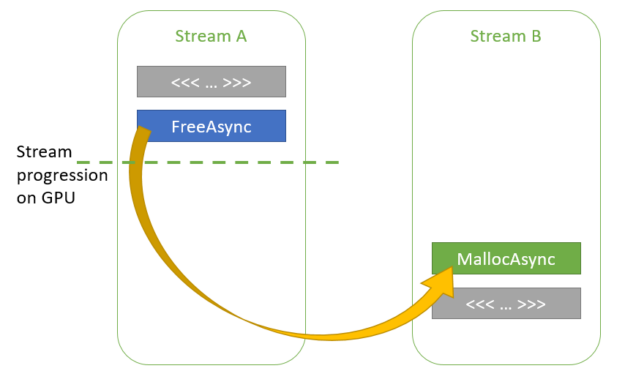
图 5 跨流的机会主义内存重用。
如果 kernelA 尚未完成执行, CUDA 驱动程序可以在两个流之间添加隐式依赖项,以便 kernelB 在 kernelA 完成之前不会开始执行。
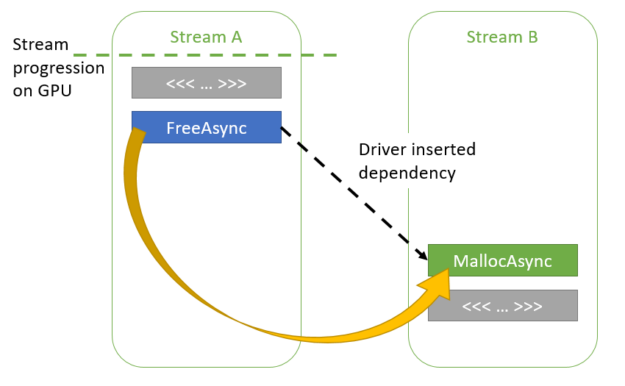
图 6 通过内部依赖关系重用内存 。
应用程序可以按如下方式禁用这些启发式:
int enable = 0; cudaMemPoolSetAttribute(mempool, cudaMemPoolReuseAllowOpportunistic, &enable); cudaMemPoolSetAttribute(mempool, cudaMemPoolReuseAllowInternalDependencies, &enable);
概括
在本系列的第 1 部分中,我们介绍了新的 API 函数 cudaMallocAsync 和 cudaFreeAsync ,这两个函数使内存分配和释放成为流顺序操作。使用它们可以避免通过 CUDA 驱动程序维护的内存池对操作系统进行昂贵的调用。
在 本系列的第 2 部分 中,我们分享了一些基准测试结果,以展示流顺序内存分配的好处。我们还提供了一个逐步修改现有应用程序的方法,以充分利用此高级 CUDA 功能。
关于作者
Vivek Kini 是 NVIDIA 的高级系统软件工程师。他致力于 CUDA 驱动程序,特别关注内存管理功能。他旨在简化 CUDA 应用程序的内存管理,而不牺牲它们所需的性能。
Jake Hemstad 是一个高级开发工程师 NVIDIA ,他在开发高性能 CUDA C ++软件加速数据分析。他同样关心开发高质量的软件,正如他实现最佳的 GPU 性能一样,也是现代 C ++设计的倡导者。在 NVIDIA 之前,他参加了明尼苏达大学的研究生院,在那里他与桑迪亚国家实验室在任务并行 HPC 运行时间和稀疏线性求解器上工作。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
4862浏览量
102742 -
CUDA
+关注
关注
0文章
121浏览量
13587
发布评论请先 登录
相关推荐
CDCL1810A 1.8V、10 输出高性能时钟分配器数据表

CDCL1810 1.8V 10路输出高性能时钟分配器数据表
液压分配器起什么作用的
液压分配器工作原理是什么
液压分配器压力调整方法有哪些
单线分配器与双线分配器的区别是什么
四路数据分配器的基本概念、工作原理、应用场景及设计方法
八路数据分配器的基本概念及工作原理
DS90LV110AT 1至10 LVDS数据/时钟分配器数据表
Linux内核内存管理之slab分配器





 工商网监
工商网监
评论