 协作组编程模型的特点及应用
协作组编程模型的特点及应用
C.1. Introduction
Cooperative Groups 是 CUDA 9 中引入的 CUDA 编程模型的扩展,用于组织通信线程组。协作组允许开发人员表达线程通信的粒度,帮助他们表达更丰富、更有效的并行分解。
从历史上看,CUDA 编程模型为同步协作线程提供了一个单一、简单的构造:线程块的所有线程之间的屏障,如使用__syncthreads()内部函数实现的那样。但是,程序员希望以其他粒度定义和同步线程组,以“集体”组范围功能接口的形式实现更高的性能、设计灵活性和软件重用。为了表达更广泛的并行交互模式,许多面向性能的程序员已经求助于编写自己的临时和不安全的原语来同步单个 warp 中的线程,或者跨运行在单个 GPU 上的线程块集。虽然实现的性能改进通常很有价值,但这导致了越来越多的脆弱代码集合,随着时间的推移和跨 GPU 架构的不同,这些代码的编写、调整和维护成本很高。合作组通过提供安全且面向未来的机制来启用高性能代码来解决这个问题。
C.2. What’s New in CUDA 11.0
-
使用网格范围的组不再需要单独编译,并且同步该组的速度现在提高了
30%。此外,我们在最新的 Windows 平台上启用了协作启动,并在 MPS 下运行时增加了对它们的支持。 -
grid_group现在可以转换为thread_group。 -
线程块切片和合并组的新集合:
reduce和memcpy_async。 -
线程块切片和合并组的新分区操作:
labeled_partition和binary_partition。 -
新的 API,
meta_group_rank和meta_group_size,它们提供有关导致创建该组的分区的信息。 -
线程块
tile现在可以在类型中编码其父级,这允许对发出的代码进行更好的编译时优化。 -
接口更改:
grid_group必须在声明时使用this_grid()构造。默认构造函数被删除。
注意:在此版本中,我们正朝着要求 C++11 提供新功能的方向发展。在未来的版本中,所有现有 API 都需要这样做。
C.3. Programming Model Concept
协作组编程模型描述了 CUDA 线程块内和跨线程块的同步模式。 它为应用程序提供了定义它们自己的线程组的方法,以及同步它们的接口。 它还提供了强制执行某些限制的新启动 API,因此可以保证同步正常工作。 这些原语在 CUDA 内启用了新的协作并行模式,包括生产者-消费者并行、机会并行和整个网格的全局同步。
合作组编程模型由以下元素组成:
- 表示协作线程组的数据类型;
- 获取由 CUDA 启动 API 定义的隐式组的操作(例如,线程块);
- 将现有群体划分为新群体的集体;
-
用于数据移动和操作的集体算法(例如
memcpy_async、reduce、scan); - 同步组内所有线程的操作;
- 检查组属性的操作;
- 公开低级别、特定于组且通常是硬件加速的操作的集合。
协作组中的主要概念是对象命名作为其中一部分的线程集的对象。 这种将组表示为一等程序对象的方式改进了软件组合,因为集合函数可以接收表示参与线程组的显式对象。 该对象还明确了程序员的意图,从而消除了不合理的架构假设,这些假设会导致代码脆弱、对编译器优化的不良限制以及与新一代 GPU 的更好兼容性。
为了编写高效的代码,最好使用专门的组(通用会失去很多编译时优化),并通过引用打算以某种协作方式使用这些线程的函数来传递这些组对象。
合作组需要 CUDA 9.0 或更高版本。 要使用合作组,请包含头文件:
// Primary header is compatible with pre-C++11, collective algorithm headers require C++11 #include // Optionally include for memcpy_async() collective #include // Optionally include for reduce() collective #include // Optionally include for inclusive_scan() and exclusive_scan() collectives #include
并使用合作组命名空间:
using namespace cooperative_groups; // Alternatively use an alias to avoid polluting the namespace with collective algorithms namespace cg = cooperative_groups;
可以使用 nvcc 以正常方式编译代码,但是如果您希望使用memcpy_async、reduce或scan功能并且您的主机编译器的默认不是 C++11 或更高版本,那么您必须添加--std=c++11到命令行。
C.3.1. Composition Example
为了说明组的概念,此示例尝试执行块范围的求和。 以前,编写此代码时对实现存在隐藏的约束:
__device__ int sum(int *x, int n) {
// ...
__syncthreads();
return total;
}
__global__ void parallel_kernel(float *x) {
// ...
// Entire thread block must call sum
sum(x, n);
}
线程块中的所有线程都必须到达__syncthreads()屏障,但是,对于可能想要使用sum(...)的开发人员来说,这个约束是隐藏的。 对于合作组,更好的编写方式是:
__device__ int sum(const thread_block& g, int *x, int n) {
// ...
g.sync()
return total;
}
__global__ void parallel_kernel(...) {
// ...
// Entire thread block must call sum
thread_block tb = this_thread_block();
sum(tb, x, n);
// ...
}
C.4. Group Types
C.4.1. Implicit Groups
隐式组代表内核的启动配置。不管你的内核是如何编写的,它总是有一定数量的线程、块和块尺寸、单个网格和网格尺寸。另外,如果使用多设备协同启动API,它可以有多个网格(每个设备一个网格)。这些组为分解为更细粒度的组提供了起点,这些组通常是硬件加速的,并且更专门针对开发人员正在解决的问题。
尽管您可以在代码中的任何位置创建隐式组,但这样做很危险。为隐式组创建句柄是一项集体操作——组中的所有线程都必须参与。如果组是在并非所有线程都到达的条件分支中创建的,则可能导致死锁或数据损坏。出于这个原因,建议您预先为隐式组创建一个句柄(尽可能早,在任何分支发生之前)并在整个内核中使用该句柄。出于同样的原因,必须在声明时初始化组句柄(没有默认构造函数),并且不鼓励复制构造它们。
C.4.1.1. Thread Block Group
任何 CUDA 程序员都已经熟悉某一组线程:线程块。 Cooperative Groups 扩展引入了一个新的数据类型thread_block,以在内核中明确表示这个概念。
class thread_block;
thread_block g = this_thread_block();
公开成员函数:

示例:
/// Loading an integer from global into shared memory __global__ void kernel(int *globalInput) { __shared__ int x; thread_block g = this_thread_block(); // Choose a leader in the thread block if (g.thread_rank() == 0) { // load from global into shared for all threads to work with x = (*globalInput); } // After loading data into shared memory, you want to synchronize // if all threads in your thread block need to see it g.sync(); // equivalent to __syncthreads(); }
注意:组中的所有线程都必须参与集体操作,否则行为未定义。
相关:thread_block数据类型派生自更通用的thread_group数据类型,可用于表示更广泛的组类。
C.4.1.2. Grid Group
该组对象表示在单个网格中启动的所有线程。 除了sync()之外的 API 始终可用,但要能够跨网格同步,您需要使用协作启动 API。
class grid_group; grid_group g = this_grid();
公开成员函数:

C.4.1.3. Multi Grid Group
该组对象表示跨设备协作组启动的所有设备启动的所有线程。 与grid.group不同,所有 API 都要求您使用适当的启动 API。
class multi_grid_group;
通过一下方式构建:
// Kernel must be launched with the cooperative multi-device API multi_grid_group g = this_multi_grid();
公开成员函数:

C.4.2. Explicit Groups
C.4.2.1. Thread Block Tile
tile组的模板版本,其中模板参数用于指定tile的大小 – 在编译时已知这一点,有可能实现更优化的执行。
template class thread_block_tile;
通过以下构建:
template _CG_QUALIFIER thread_block_tile tiled_partition(const ParentT& g),>
Size必须是 2 的幂且小于或等于 32。
ParentT是从其中划分该组的父类型。 它是自动推断的,但是 void 的值会将此信息存储在组句柄中而不是类型中。
公开成员函数:

注意:
shfl、shfl_up、shfl_down 和 shfl_xor函数在使用 C++11 或更高版本编译时接受任何类型的对象。 这意味着只要满足以下约束,就可以对非整数类型进行shuffle :
-
符合普通可复制的条件,即
is_trivially_copyable::value == true -
sizeof(T) <= 32
示例:
/// The following code will create two sets of tiled groups, of size 32 and 4 respectively: /// The latter has the provenance encoded in the type, while the first stores it in the handle thread_block block = this_thread_block(); thread_block_tile<32> tile32 = tiled_partition<32>(block); thread_block_tile<4, thread_block> tile4 = tiled_partition<4>(block);
注意:这里使用的是 thread_block_tile 模板化数据结构,并且组的大小作为模板参数而不是参数传递给 tiled_partition 调用。
C.4.2.1.1. Warp-Synchronous Code Pattern
开发人员可能拥有他们之前对 warp 大小做出隐含假设并围绕该数字进行编码的 warp 同步代码。 现在这需要明确指定。
__global__ void cooperative_kernel(...) {
// obtain default "current thread block" group
thread_block my_block = this_thread_block();
// subdivide into 32-thread, tiled subgroups
// Tiled subgroups evenly partition a parent group into
// adjacent sets of threads - in this case each one warp in size
auto my_tile = tiled_partition<32>(my_block);
// This operation will be performed by only the
// first 32-thread tile of each block
if (my_tile.meta_group_rank() == 0) {
// ...
my_tile.sync();
}
}
C.4.2.1.2. Single thread group
可以从 this_thread 函数中获取代表当前线程的组:
thread_block_tile<1> this_thread();
以下memcpy_asyncAPI 使用thread_group将int元素从源复制到目标:
#include #include cooperative_groups::memcpy_async(cooperative_groups::this_thread(), dest, src, sizeof(int));
可以在使用 cuda::pipeline的单阶段异步数据拷贝和使用 cuda::pipeline的多阶段异步数据拷贝部分中找到使用this_thread执行异步复制的更详细示例。
C.4.2.1.3. Thread Block Tile of size larger than 32
使用cooperative_groups::experimental命名空间中的新API 可以获得大小为64、128、256 或512的thread_block_tile。 要使用它,_CG_ABI_EXPERIMENTAL必须在源代码中定义。 在分区之前,必须为thread_block_tile保留少量内存。 这可以使用必须驻留在共享或全局内存中的cooperative_groups::experimental::block_tile_memory结构模板来完成。
template struct block_tile_memory;
TileCommunicationSize确定为集体操作保留多少内存。 如果对大于指定通信大小的大小类型执行此类操作,则集合可能涉及多次传输并需要更长的时间才能完成。
MaxBlockSize指定当前线程块中的最大线程数。 此参数可用于最小化仅以较小线程数启动的内核中block_tile_memory的共享内存使用量。
然后这个block_tile_memory需要被传递到cooperative_groups::experimental::this_thread_block,允许将生成的thread_block划分为大小大于32的tile。this_thread_block接受block_tile_memory参数的重载是一个集体操作,必须与所有线程一起调用 线程块。 返回的线程块可以使用experimental::tiled_partition函数模板进行分区,该模板接受与常规tiled_partition相同的参数。
#define _CG_ABI_EXPERIMENTAL // enable experimental API
__global__ void cooperative_kernel(...) {
// reserve shared memory for thread_block_tile usage.
__shared__ experimental::block_tile_memory<4, 256> shared;
thread_block thb = experimental::this_thread_block(shared);
auto tile = experimental::tiled_partition<128>(thb);
// ...
}
公开成员函数:

C.4.2.2. Coalesced Groups
在 CUDA 的 SIMT 架构中,在硬件级别,多处理器以 32 个一组的线程执行线程,称为 warp。 如果应用程序代码中存在依赖于数据的条件分支,使得 warp 中的线程发散,那么 warp 会串行执行每个分支,禁用不在该路径上的线程。 在路径上保持活动的线程称为合并。 协作组具有发现和创建包含所有合并线程的组的功能。
通过coalesced_threads()构造组句柄是伺机的(opportunistic)。 它在那个时间点返回一组活动线程,并且不保证返回哪些线程(只要它们是活动的)或者它们在整个执行过程中保持合并(它们将被重新组合在一起以执行一个集合,但之后可以再次发散)。
class coalesced_group;
通过以下重构:
coalesced_group active = coalesced_threads();
公开成员函数:


注意:shfl、shfl_up 和 shfl_down函数在使用 C++11 或更高版本编译时接受任何类型的对象。 这意味着只要满足以下约束,就可以对非整数类型进行洗牌:
-
符合普通可复制的条件,即
is_trivially_copyable::value == true -
sizeof(T) <= 32
示例:
/// Consider a situation whereby there is a branch in the
/// code in which only the 2nd, 4th and 8th threads in each warp are
/// active. The coalesced_threads() call, placed in that branch, will create (for each
/// warp) a group, active, that has three threads (with
/// ranks 0-2 inclusive).
__global__ void kernel(int *globalInput) {
// Lets say globalInput says that threads 2, 4, 8 should handle the data
if (threadIdx.x == *globalInput) {
coalesced_group active = coalesced_threads();
// active contains 0-2 inclusive
active.sync();
}
}
C.4.2.2.1. Discovery Pattern
通常,开发人员需要使用当前活动的线程集。 不对存在的线程做任何假设,而是开发人员使用碰巧存在的线程。 这可以在以下“在warp中跨线程聚合原子增量”示例中看到(使用正确的 CUDA 9.0 内在函数集编写):
{
unsigned int writemask = __activemask();
unsigned int total = __popc(writemask);
unsigned int prefix = __popc(writemask & __lanemask_lt());
// Find the lowest-numbered active lane
int elected_lane = __ffs(writemask) - 1;
int base_offset = 0;
if (prefix == 0) {
base_offset = atomicAdd(p, total);
}
base_offset = __shfl_sync(writemask, base_offset, elected_lane);
int thread_offset = prefix + base_offset;
return thread_offset;
}
这可以用Cooperative Groups重写如下:
{
cg::coalesced_group g = cg::coalesced_threads();
int prev;
if (g.thread_rank() == 0) {
prev = atomicAdd(p, g.num_threads());
}
prev = g.thread_rank() + g.shfl(prev, 0);
return prev;
}
C.5. Group Partitioning
C.5.1. tiled_partition
template thread_block_tile tiled_partition(const ParentT& g); thread_group tiled_partition(const thread_group& parent, unsigned int tilesz);,>
tiled_partition方法是一种集体操作,它将父组划分为一维、行主序的子组平铺。 总共将创建((size(parent)/tilesz)子组,因此父组大小必须能被Size整除。允许的父组是thread_block或thread_block_tile。
该实现可能导致调用线程在恢复执行之前等待,直到父组的所有成员都调用了该操作。功能仅限于本地硬件大小,1/2/4/8/16/32和cg::size(parent)必须大于size参数。cooperative_groups::experimental命名空间的实验版本支持64/128/256/512大小。
Codegen 要求:计算能力 3.5 最低,C++11 用于大于 32 的size
示例:
/// The following code will create a 32-thread tile thread_block block = this_thread_block(); thread_block_tile<32> tile32 = tiled_partition<32>(block);
我们可以将这些组中的每一个分成更小的组,每个组的大小为 4 个线程:
auto tile4 = tiled_partition<4>(tile32); // or using a general group // thread_group tile4 = tiled_partition(tile32, 4);
例如,如果我们要包含以下代码行:
if (tile4.thread_rank()==0) printf(“Hello from tile4 rank 0\n”);
那么该语句将由块中的每四个线程打印:每个 tile4 组中排名为 0 的线程,它们对应于块组中排名为 0、4、8、12.. 的那些线程。
C.5.2. labeled_partition
coalesced_group labeled_partition(const coalesced_group& g, int label); template coalesced_group labeled_partition(const thread_block_tile& g, int label);
labeled_partition方法是一种集体操作,它将父组划分为一维子组,线程在这些子组中合并。 该实现将评估条件标签并将具有相同标签值的线程分配到同一组中。
该实现可能会导致调用线程在恢复执行之前等待直到父组的所有成员都调用了该操作。
注意:此功能仍在评估中,将来可能会略有变化。
Codegen 要求:计算能力 7.0 最低,C++11
C.5.3. binary_partition
coalesced_group binary_partition(const coalesced_group& g, bool pred); template coalesced_group binary_partition(const thread_block_tile& g, bool pred);
binary_partition()方法是一种集体操作,它将父组划分为一维子组,线程在其中合并。 该实现将评估predicate并将具有相同值的线程分配到同一组中。 这是labeled_partition()的一种特殊形式,其中label只能是0 或1。
该实现可能会导致调用线程在恢复执行之前等待直到父组的所有成员都调用了该操作。
注意:此功能仍在评估中,将来可能会略有变化。
Codegen 要求:计算能力 7.0 最低,C++11
示例:
/// This example divides a 32-sized tile into a group with odd
/// numbers and a group with even numbers
_global__ void oddEven(int *inputArr) {
cg::thread_block cta = cg::this_thread_block();
cg::thread_block_tile<32> tile32 = cg::tiled_partition<32>(cta);
// inputArr contains random integers
int elem = inputArr[cta.thread_rank()];
// after this, tile32 is split into 2 groups,
// a subtile where elem&1 is true and one where its false
auto subtile = cg::binary_partition(tile32, (elem & 1));
}
C.6. Group Collectives
C.6.1. Synchronization
C.6.1.1. sync
cooperative_groups::sync(T& group);
sync同步组中指定的线程。T可以是任何现有的组类型,因为它们都支持同步。 如果组是grid_group或multi_grid_group,则内核必须已使用适当的协作启动 API 启动。
C.6.2. Data Transfer
C.6.2.1. memcpy_async
memcpy_async是一个组范围的集体memcpy,它利用硬件加速支持从全局到共享内存的非阻塞内存事务。给定组中命名的一组线程,memcpy_async将通过单个管道阶段传输指定数量的字节或输入类型的元素。此外,为了在使用memcpy_asyncAPI 时获得最佳性能,共享内存和全局内存都需要 16 字节对齐。需要注意的是,虽然在一般情况下这是一个memcpy,但只有当源(source)是全局内存而目标是共享内存并且两者都可以通过 16、8 或 4 字节对齐来寻址时,它才是异步的。异步复制的数据只能在调用wait或wait_prior之后读取,这表明相应阶段已完成将数据移动到共享内存。
必须等待所有未完成的请求可能会失去一些灵活性(但会变得简单)。为了有效地重叠数据传输和执行,重要的是能够在等待和操作请求N时启动N+1 memcpy_async请求。为此,请使用memcpy_async并使用基于集体阶段的wait_priorAPI 等待它.有关详细信息,请参阅wait 和 wait_prior。
用法1:
template void memcpy_async( const TyGroup &group, TyElem *__restrict__ _dst, const TyElem *__restrict__ _src, const TyShape &shape );
执行shape字节的拷贝
用法2:
template void memcpy_async( const TyGroup &group, TyElem *__restrict__ dst, const TyDstLayout &dstLayout, const TyElem *__restrict__ src, const TySrcLayout &srcLayout );
执行min(dstLayout, srcLayout)元素的拷贝。 如果布局的类型为cuda::aligned_size_t,则两者必须指定相同的对齐方式。
勘误表
CUDA 11.1 中引入的具有 src 和 dst 输入布局的memcpy_asyncAPI 期望布局以元素而不是字节形式提供。 元素类型是从TyElem推断出来的,大小为sizeof(TyElem)。 如果使用cuda::aligned_size_t类型作为布局,指定的元素个数乘以sizeof(TyElem)必须是 N 的倍数,建议使用std::byte或char作为元素类型。
如果副本的指定形状或布局是cuda::aligned_size_t类型,则将保证至少为min(16, N)。 在这种情况下,dst 和 src 指针都需要与 N 个字节对齐,并且复制的字节数需要是 N 的倍数。
Codegen 要求:最低计算能力 3.5,异步计算能力 8.0,C++11
需要包含collaborative_groups/memcpy_async.h头文件。
示例:
/// This example streams elementsPerThreadBlock worth of data from global memory /// into a limited sized shared memory (elementsInShared) block to operate on. #include #include namespace cg = cooperative_groups; __global__ void kernel(int* global_data) { cg::thread_block tb = cg::this_thread_block(); const size_t elementsPerThreadBlock = 16 * 1024; const size_t elementsInShared = 128; __shared__ int local_smem[elementsInShared]; size_t copy_count; size_t index = 0; while (index < elementsPerThreadBlock) { cg::memcpy_async(tb, local_smem, elementsInShared, global_data + index, elementsPerThreadBlock - index); copy_count = min(elementsInShared, elementsPerThreadBlock - index); cg::wait(tb); // Work with local_smem index += copy_count; } }
C.6.2.2. wait and wait_prior
template void wait(TyGroup & group); template void wair_prior(TyGroup & group);
wait和wait_prior集合同步指定的线程和线程块,直到所有未完成的memcpy_async请求(在等待的情况下)或第一个NumStages(在 wait_prior 的情况下)完成。
Codegen 要求:最低计算能力 3.5,异步计算能力 8.0,C++11
需要包含collaborative_groups/memcpy_async.h 头文件。
示例:
/// This example streams elementsPerThreadBlock worth of data from global memory
/// into a limited sized shared memory (elementsInShared) block to operate on in
/// multiple (two) stages. As stage N is kicked off, we can wait on and operate on stage N-1.
#include
#include
namespace cg = cooperative_groups;
__global__ void kernel(int* global_data) {
cg::thread_block tb = cg::this_thread_block();
const size_t elementsPerThreadBlock = 16 * 1024 + 64;
const size_t elementsInShared = 128;
__align__(16) __shared__ int local_smem[2][elementsInShared];
int stage = 0;
// First kick off an extra request
size_t copy_count = elementsInShared;
size_t index = copy_count;
cg::memcpy_async(tb, local_smem[stage], elementsInShared, global_data, elementsPerThreadBlock - index);
while (index < elementsPerThreadBlock) {
// Now we kick off the next request...
cg::memcpy_async(tb, local_smem[stage ^ 1], elementsInShared, global_data + index, elementsPerThreadBlock - index);
// ... but we wait on the one before it
cg::wait_prior<1>(tb);
// Its now available and we can work with local_smem[stage] here
// (...)
//
// Calculate the amount fo data that was actually copied, for the next iteration.
copy_count = min(elementsInShared, elementsPerThreadBlock - index);
index += copy_count;
// A cg::sync(tb) might be needed here depending on whether
// the work done with local_smem[stage] can release threads to race ahead or not
// Wrap to the next stage
stage ^= 1;
}
cg::wait(tb);
// The last local_smem[stage] can be handled here
C.6.3. Data manipulation
C.6.3.1. reduce
template auto reduce(const TyGroup& group, TyArg&& val, TyOp&& op) -> decltype(op(val, val));
reduce对传入的组中指定的每个线程提供的数据执行归约操作。这利用硬件加速(在计算 80 及更高的设备上)进行算术加法、最小或最大操作以及逻辑 AND、OR、或 XOR,以及在老一代硬件上提供软件替代支持(fallback)。只有 4B 类型由硬件加速。
group:有效的组类型是coalesced_group和thread_block_tile。
val:满足以下要求的任何类型:
-
符合普通可复制的条件,即
is_trivially_copyable::value == true -
sizeof(TyArg) <= 32 - 对给定的函数对象具有合适的算术或比较运算符。
op:将提供具有整数类型的硬件加速的有效函数对象是plus()、less()、greater()、bit_and()、bit_xor()、bit_or()。这些必须构造,因此需要TyVal模板参数,即plus()。Reduce还支持可以使用operator()调用的lambda和其他函数对象
Codegen 要求:计算能力 3.5 最低,计算能力 8.0 用于硬件加速,C++11。
需要包含collaborative_groups/reduce.h 头文件。
示例:
#include
#include
namespace cg=cooperative_groups;
/// The following example accepts input in *A and outputs a result into *sum
/// It spreads the data within the block, one element per thread
#define blocksz 256
__global__ void block_reduce(const int *A, int *sum) {
__shared__ int reduction_s[blocksz];
cg::thread_block cta = cg::this_thread_block();
cg::thread_block_tile<32> tile = cg::tiled_partition<32>(cta);
const int tid = cta.thread_rank();
int beta = A[tid];
// reduce across the tile
// cg::plus allows cg::reduce() to know it can use hardware acceleration for addition
reduction_s[tid] = cg::reduce(tile, beta, cg::plus());
// synchronize the block so all data is ready
cg::sync(cta);
// single leader accumulates the result
if (cta.thread_rank() == 0) {
beta = 0;
for (int i = 0; i < blocksz; i += tile.num_threads()) {
beta += reduction_s[i];
}
sum[blockIdx.x] = beta;
}
C.6.3.2. Reduce Operators
下面是一些可以用reduce完成的基本操作的函数对象的原型
namespace cooperative_groups {
template
struct cg::plus;
template
struct cg::less;
template
struct cg::greater;
template
struct cg::bit_and;
template
struct cg::bit_xor;
template
struct cg::bit_or;
}
Reduce仅限于在编译时可用于实现的信息。 因此,为了利用 CC 8.0 中引入的内在函数,cg::命名空间公开了几个镜像硬件的功能对象。 这些对象看起来与 C++ STL 中呈现的对象相似,除了less/greater。 与 STL 有任何差异的原因在于,这些函数对象旨在实际反映硬件内联函数的操作。
功能说明:
-
cg::plus:接受两个值并使用operator +返回两者之和。 -
cg::less: 接受两个值并使用operator <返回较小的值。 这不同之处在于返回较低的值而不是布尔值。 -
cg::greater:接受两个值并使用operator <返回较大的值。 这不同之处在于返回更大的值而不是布尔值。 -
cg::bit_and:接受两个值并返回operator &的结果。 -
cg::bit_xor:接受两个值并返回operator ^的结果。 -
cg::bit_or:接受两个值并返回operator |的结果。
示例:
{
// cg::plus is specialized within cg::reduce and calls __reduce_add_sync(...) on CC 8.0+
cg::reduce(tile, (int)val, cg::plus());
// cg::plus fails to match with an accelerator and instead performs a standard shuffle based reduction
cg::reduce(tile, (float)val, cg::plus());
// While individual components of a vector are supported, reduce will not use hardware intrinsics for the following
// It will also be necessary to define a corresponding operator for vector and any custom types that may be used
int4 vec = {...};
cg::reduce(tile, vec, cg::plus())
// Finally lambdas and other function objects cannot be inspected for dispatch
// and will instead perform shuffle based reductions using the provided function object.
cg::reduce(tile, (int)val, [](int l, int r) -> int {return l + r;});
}
C.6.3.3. inclusive_scan and exclusive_scan
template auto inclusive_scan(const TyGroup& group, TyVal&& val, TyFn&& op) -> decltype(op(val, val)); template TyVal inclusive_scan(const TyGroup& group, TyVal&& val); template auto exclusive_scan(const TyGroup& group, TyVal&& val, TyFn&& op) -> decltype(op(val, val)); template TyVal exclusive_scan(const TyGroup& group, TyVal&& val);
inclusive_scan和exclusive_scan对传入组中指定的每个线程提供的数据执行扫描操作。在exclusive_scan的情况下,每个线程的结果是减少thread_rank低于该线程的线程的数据。inclusive_scan的结果还包括调用线程中的归约数据。
group:有效的组类型是coalesced_group和thread_block_tile。
val:满足以下要求的任何类型:
-
符合普通可复制的条件,即
is_trivially_copyable::value == true -
sizeof(TyArg) <= 32 - 对给定的函数对象具有合适的算术或比较运算符。
op:为了方便而定义的函数对象有reduce Operators中描述的plus()、less()、greater()、bit_and()、bit_xor()、bit_or()。这些必须构造,因此需要TyVal模板参数,即plus()。inclusive_scan和exclusive_scan还支持可以使用operator()调用的lambdas和其他函数对象
Codegen 要求:计算能力 3.5 最低,C++11。
需要包含collaborative_groups/scan.h 头文件。
示例:
#include
#include
#include
namespace cg = cooperative_groups;
__global__ void kernel() {
auto thread_block = cg::this_thread_block();
auto tile = cg::tiled_partition<8>(thread_block);
unsigned int val = cg::inclusive_scan(tile, tile.thread_rank());
printf("%u: %u\n", tile.thread_rank(), val);
}
/* prints for each group:
0: 0
1: 1
2: 3
3: 6
4: 10
5: 15
6: 21
7: 28
*/
使用 Exclusive_scan 进行动态缓冲区空间分配的示例:
#include
#include
namespace cg = cooperative_groups;
// Buffer partitioning is static to make the example easier to follow,
// but any arbitrary dynamic allocation scheme can be implemented by replacing this function.
__device__ int calculate_buffer_space_needed(cg::thread_block_tile<32>& tile) {
return tile.thread_rank() % 2 + 1;
}
__device__ int my_thread_data(int i) {
return i;
}
__global__ void kernel() {
__shared__ int buffer_used;
extern __shared__ int buffer[];
auto thread_block = cg::this_thread_block();
auto tile = cg::tiled_partition<32>(thread_block);
buffer_used = 0;
thread_block.sync();
// each thread calculates buffer size it needs and its offset within the allocation
int buf_needed = calculate_buffer_space_needed(tile);
int buf_offset = cg::exclusive_scan(tile, buf_needed);
// last thread in the tile allocates buffer space with an atomic operation
int alloc_offset = 0;
if (tile.thread_rank() == tile.num_threads() - 1) {
alloc_offset = atomicAdd(&buffer_used, buf_offset + buf_needed);
}
// that thread shares the allocation start with other threads in the tile
alloc_offset = tile.shfl(alloc_offset, tile.num_threads() - 1);
buf_offset += alloc_offset;
// each thread fill its part of the buffer with thread specific data
for (int i = 0 ; i < buf_needed ; ++i) {
buffer[buf_offset + i] = my_thread_data(i);
}
// buffer is {0, 0, 1, 0, 0, 1 ...};
}
C.7. Grid Synchronization
在引入协作组(Cooperative Groups)之前,CUDA 编程模型只允许在内核完成边界的线程块之间进行同步。内核边界带有隐含的状态失效,以及潜在的性能影响。
例如,在某些用例中,应用程序具有大量小内核,每个内核代表处理pipeline中的一个阶段。当前的 CUDA 编程模型需要这些内核的存在,以确保在一个pipeline阶段上运行的线程块在下一个pipeline阶段上运行的线程块准备好使用数据之前产生数据。在这种情况下,提供全局线程间块同步的能力将允许将应用程序重组为具有持久线程块,当给定阶段完成时,这些线程块能够在设备上同步。
要从内核中跨网格同步,您只需使用grid.sync()功能:
grid_group grid = this_grid(); grid.sync();
并且在启动内核时,有必要使用cudaLaunchCooperativeKernelCUDA 运行时启动 API 或 CUDA 驱动程序等价物,而不是 <<<…>>> 执行配置语法。
例子:
为了保证线程块在 GPU 上的共同驻留,需要仔细考虑启动的块数。 例如,可以按如下方式启动与 SM 一样多的块:
int device = 0; cudaDeviceProp deviceProp; cudaGetDeviceProperties(&deviceProp, dev); // initialize, then launch cudaLaunchCooperativeKernel((void*)my_kernel, deviceProp.multiProcessorCount, numThreads, args);
或者,您可以通过使用占用计算器(occupancy calculator)计算每个 SM 可以同时容纳多少块来最大化暴露的并行度,如下所示:
/// This will launch a grid that can maximally fill the GPU, on the default stream with kernel arguments int numBlocksPerSm = 0; // Number of threads my_kernel will be launched with int numThreads = 128; cudaDeviceProp deviceProp; cudaGetDeviceProperties(&deviceProp, dev); cudaOccupancyMaxActiveBlocksPerMultiprocessor(&numBlocksPerSm, my_kernel, numThreads, 0); // launch void *kernelArgs[] = { /* add kernel args */ }; dim3 dimBlock(numThreads, 1, 1); dim3 dimGrid(deviceProp.multiProcessorCount*numBlocksPerSm, 1, 1); cudaLaunchCooperativeKernel((void*)my_kernel, dimGrid, dimBlock, kernelArgs);
最好先通过查询设备属性cudaDevAttrCooperativeLaunch来确保设备支持协作启动:
int dev = 0; int supportsCoopLaunch = 0; cudaDeviceGetAttribute(&supportsCoopLaunch, cudaDevAttrCooperativeLaunch, dev);
如果设备 0 支持该属性,则将supportsCoopLaunch设置为 1。仅支持计算能力为 6.0 及更高版本的设备。 此外,您需要在以下任何一个上运行:
- 没有 MPS 的 Linux 平台
- 具有 MPS 和计算能力 7.0 或更高版本的设备上的 Linux 平台
- 最新的 Windows 平台
C.8. Multi-Device Synchronization
为了通过协作组启用跨多个设备的同步,需要使用cudaLaunchCooperativeKernelMultiDeviceCUDA API。这与现有的 CUDA API 有很大不同,它将允许单个主机线程跨多个设备启动内核。除了cudaLaunchCooperativeKernel做出的约束和保证之外,这个 API 还具有额外的语义:
- 此 API 将确保启动是原子的,即如果 API 调用成功,则提供的线程块数将在所有指定设备上启动。
- 通过此 API 启动的功能必须相同。驱动程序在这方面没有进行明确的检查,因为这在很大程度上是不可行的。由应用程序来确保这一点。
-
提供的
cudaLaunchParams中没有两个条目可以映射到同一设备。 - 本次发布所针对的所有设备都必须具有相同的计算能力——主要版本和次要版本。
- 每个网格的块大小、网格大小和共享内存量在所有设备上必须相同。请注意,这意味着每个设备可以启动的最大块数将受到 SM 数量最少的设备的限制。
- 拥有正在启动的 CUfunction 的模块中存在的任何用户定义的device、constant或managed设备全局变量都在每个设备上独立实例化。用户负责适当地初始化此类设备全局变量。
弃用通知:cudaLaunchCooperativeKernelMultiDevice 已在 CUDA 11.3 中针对所有设备弃用。在多设备共轭梯度样本中可以找到替代方法的示例。
多设备同步的最佳性能是通过cuCtxEnablePeerAccess或cudaDeviceEnablePeerAccess为所有参与设备启用对等访问来实现的。
启动参数应使用结构数组(每个设备一个)定义,并使用cudaLaunchCooperativeKernelMultiDevice启动
Example:
cudaDeviceProp deviceProp;
cudaGetDeviceCount(&numGpus);
// Per device launch parameters
cudaLaunchParams *launchParams = (cudaLaunchParams*)malloc(sizeof(cudaLaunchParams) * numGpus);
cudaStream_t *streams = (cudaStream_t*)malloc(sizeof(cudaStream_t) * numGpus);
// The kernel arguments are copied over during launch
// Its also possible to have individual copies of kernel arguments per device, but
// the signature and name of the function/kernel must be the same.
void *kernelArgs[] = { /* Add kernel arguments */ };
for (int i = 0; i < numGpus; i++) {
cudaSetDevice(i);
// Per device stream, but its also possible to use the default NULL stream of each device
cudaStreamCreate(&streams[i]);
// Loop over other devices and cudaDeviceEnablePeerAccess to get a faster barrier implementation
}
// Since all devices must be of the same compute capability and have the same launch configuration
// it is sufficient to query device 0 here
cudaGetDeviceProperties(&deviceProp[i], 0);
dim3 dimBlock(numThreads, 1, 1);
dim3 dimGrid(deviceProp.multiProcessorCount, 1, 1);
for (int i = 0; i < numGpus; i++) {
launchParamsList[i].func = (void*)my_kernel;
launchParamsList[i].gridDim = dimGrid;
launchParamsList[i].blockDim = dimBlock;
launchParamsList[i].sharedMem = 0;
launchParamsList[i].stream = streams[i];
launchParamsList[i].args = kernelArgs;
}
cudaLaunchCooperativeKernelMultiDevice(launchParams, numGpus);
此外,与网格范围的同步一样,生成的设备代码看起来非常相似:
multi_grid_group multi_grid = this_multi_grid(); multi_grid.sync();
但是,需要通过将-rdc=true传递给 nvcc 来单独编译代码。
最好先通过查询设备属性cudaDevAttrCooperativeMultiDeviceLaunch来确保设备支持多设备协作启动:
int dev = 0; int supportsMdCoopLaunch = 0; cudaDeviceGetAttribute(&supportsMdCoopLaunch, cudaDevAttrCooperativeMultiDeviceLaunch, dev);
如果设备 0 支持该属性,则将 supportsMdCoopLaunch 设置为 1。仅支持计算能力为 6.0 及更高版本的设备。 此外,您需要在 Linux 平台(无 MPS)或当前版本的 Windows 上运行,并且设备处于 TCC 模式。
关于作者
Ken He 是 NVIDIA 企业级开发者社区经理 & 高级讲师,拥有多年的 GPU 和人工智能开发经验。自 2017 年加入 NVIDIA 开发者社区以来,完成过上百场培训,帮助上万个开发者了解人工智能和 GPU 编程开发。在计算机视觉,高性能计算领域完成过多个独立项目。并且,在机器人和无人机领域,有过丰富的研发经验。对于图像识别,目标的检测与跟踪完成过多种解决方案。曾经参与 GPU 版气象模式GRAPES,是其主要研发者。
审核编辑:郭婷
-
gpu
+关注
关注
28文章
4812浏览量
129619 -
API
+关注
关注
2文章
1527浏览量
62587 -
CUDA
+关注
关注
0文章
122浏览量
13742
发布评论请先 登录
相关推荐
并行编程模型有什么优势
“协作机器人”如何快速处理传感器数据
深度融合模型的特点
协作对等组的接入控制和联合授权机制
基于Agent技术的决策模型协作问题研究
计算机辅助审计的多Agent协作模型研究
多移动agent协作规划模型
如何使用云雾协作模型进行任务分配详细方法说明
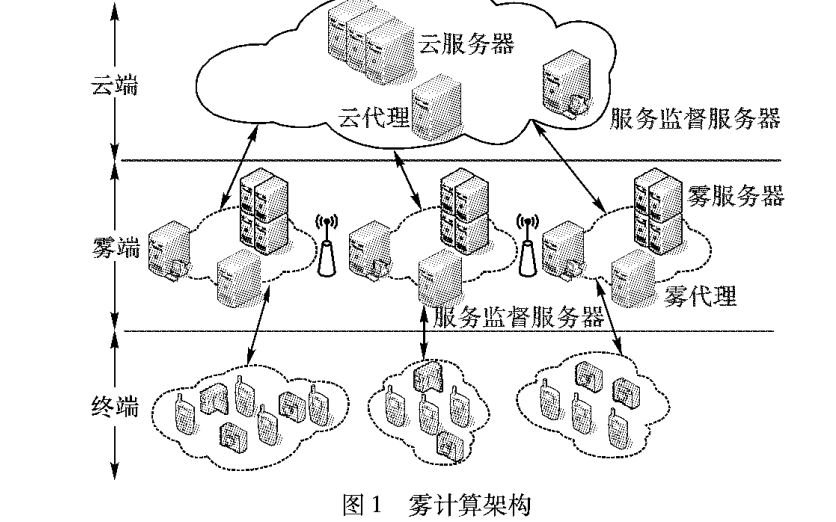
如何使用云雾协作模型实现任务分配的方法说明
CUDA简介: CUDA编程模型概述
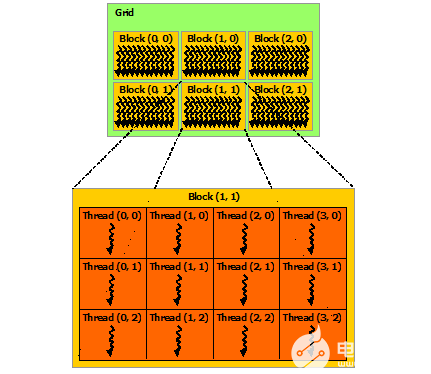
介绍CUDA编程模型及CUDA线程体系
SCP线程模型特点





 工商网监
工商网监
评论