 基于NVIDIA GPU加速机器学习模型推理
基于NVIDIA GPU加速机器学习模型推理
谷歌云与 NVIDIA 合作,宣布 Dataflow 将 GPU 带入大数据处理领域,开启新的可能性。使用数据流 GPU ,用户现在可以在机器学习推理工作流中利用 NVIDIA GPU 的强大功能。下面我们将向您展示如何使用 BERT 获得这些性能优势。
Google Cloud 的 Dataflow 是一个托管服务,用于执行各种各样的数据处理模式,包括流式处理和批处理分析。它最近添加了 GPU 支持 现在可以加速机器学习推理工作流,这些工作流运行在数据流管道上。
请查看 谷歌云发布 了解更多令人兴奋的新功能。在这篇文章中,我们将展示 NVIDIA GPU 加速的性能优势和 TCO 改进,方法是部署一个来自 Transformers ( BERT )模型的双向编码器表示,该模型对数据流上的“问答”任务进行了微调。我们将用 CPU 演示数据流中的 TensorFlow 推理,如何在 GPU 上运行相同的代码,并显著提高性能,展示通过 NVIDIA TensorRT 转换模型后的最佳性能,以及通过 TensorRT 的 python API 和数据流进行部署。查看 NVIDIA 示例代码 立即尝试。
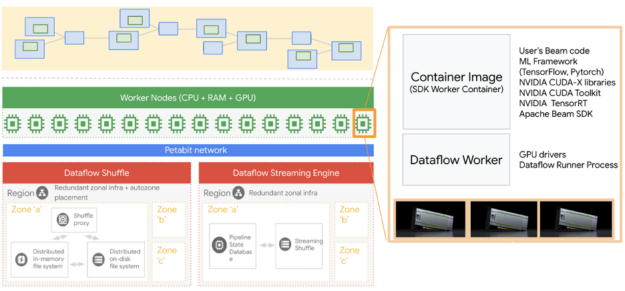
图 1 .数据流架构和 GPU 运行时。
有几个步骤,我们将在这个职位上触及。我们首先在本地机器上创建一个环境来运行所有这些数据流作业。
创造环境
建议为 Python 创建一个虚拟环境,我们在这里使用 virtualenv :
virtualenv -p
使用 Dataflow 时,需要将开发环境中的 Python 版本与 Dataflow 运行时 Python 版本对齐。更具体地说,在运行数据流管道时,应该使用相同的 Python 版本和阿帕奇光束SDK 版本,以避免意外错误。
现在,我们激活虚拟环境。
在激活虚拟环境之前需要注意的最重要的一点是确保您没有在另一个虚拟环境中操作,因为这通常会导致问题。
激活虚拟环境后,我们就可以安装所需的软件包了。即使我们的作业在 Dataflow 上运行,我们仍然需要一些本地包,这样当我们在本地运行代码时 Python 就不会抱怨了。
pip install apache-beam[gcp]
pip install TensorFlow==2.3.1
您可以尝试使用 TensorFlow 的不同版本,但这里的关键是将这里的版本与您将在数据流环境中使用的版本保持一致。 apachebeam 及其 Google 云组件也是必需的。
获得微调的 BERT 模型
NVIDIA NGC 有大量的资源,从 GPU – 优化的 containers 到微调的 models 。我们探索了几个 NGC 资源。
我们将使用的第一个资源是 BERT 大型模型,它针对 SquadV2 问答任务进行了微调,包含 3 。 4 亿个参数。以下命令将下载 BERT model 。
wget --content-disposition
https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_savedmodel_large_qa_squad2_amp_384/versions/19.03.0/zip -O bert_tf_savedmodel_large_qa_squad2_amp_384_19.03.0.zip
对于我们刚刚下载的 BERT 模型,在训练过程中使用了自动混合精度( AMP ),序列长度为 384 。
我们还需要一个词汇表文件,我们可以从 BERT 检查点获得它,该检查点可以通过以下命令从 NGC 获得:
wget --content-disposition
https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_ckpt_large_qa_squad2_amp_128/versions/19.03.1/zip -O bert_tf_ckpt_large_qa_squad2_amp_128_19.03.1.zip
在获得这些资源之后,我们只需要解压缩它们并将它们定位到我们的工作文件夹中。我们将使用自定义 docker 容器,这些模型将包含在我们的图像中。
自定义 Dockerfile
我们将使用从 GPU 优化的 NGC TensorFlow 容器派生的自定义 Dockerfile 。 NGC TensorFlow ( TF )容器是使用 NVIDIA GPU 加速 TF 模型的最佳选择。
然后我们再添加几个步骤来复制这些模型和我们拥有的文件。您可以此处找到 Dockerfile ,下面是 Dockerfile 的快照。
FROM nvcr.io/nvidia/tensorflow:20.11-tf2-py3
RUN pip install --no-cache-dir apache-beam[gcp]==2.26.0 ipython pytest pandas && \
mkdir -p /workspace/tf_beam
COPY --from=apache/beam_python3.6_sdk:2.26.0 /opt/apache/beam /opt/apache/beam
ADD. /workspace/tf_beam
WORKDIR /workspace/tf_beam
ENTRYPOINT [ "/opt/apache/beam/boot"]
接下来的步骤是构建 docker 文件并将其推送到 Google 容器注册中心( GCR )。您可以使用以下命令执行此操作。或者,您可以在此处使用我们创建的脚本。如果您使用的是我们回购的脚本,那么只需执行bash build_and_push.sh
project_id=""
docker build . -t "gcr.io/${project_id}/tf-dataflow-${USER}:latest"
docker push "gcr.io/${project_id}/tf-dataflow-${USER}:latest"
正在运行作业
如果您已经验证了您的 Google 帐户,只需调用 run_gpu.sh 和 run_gpu.sh 脚本即可运行我们提供的 Python 文件 here 。
数据流中的 CPU TensorFlow 引用( TF- CPU )
repo 中的 bert_squad2_qa_cpu.py 文件用于根据描述文本文档回答问题。批量大小是 16 ,这意味着我们将在每个推理电话回答 16 个问题,有 16000 个问题( 1000 批问题)。请注意, BERT 可以针对给定特定用例的其他任务进行微调。
在 Dataflow 上运行作业时,默认情况下,它会根据实时 CPU 使用情况自动缩放。如果要禁用此功能,需要将 autoscaling_algorithm 设置为 NONE 。这将允许您选择在整个工作周期中使用多少工人。或者,可以通过设置 max_num_workers parameter ,让 Dataflow 自动缩放作业并限制要使用的最大工作线程数。
我们建议设置作业名称,而不是使用自动生成的名称,以便通过设置 job_name 参数更好地跟踪作业。此作业名称将是运行作业的计算实例的前缀。
用 GPU 加速( TF- GPU )
要在 GPU 支持下执行相同的数据流 TensorFlow 推断作业,我们需要设置以下参数。有关更多信息,请参阅数据流 GPU 文档。
--experiment "worker_accelerator=type:nvidia-tesla-t4;count:1;install-nvidia-driver"
前面的参数使我们能够将一个 CUDAT4 张量核连接到 Dataflow worker VM ,它也可以作为运行作业的 Compute VM 实例看到。数据流将自动安装所需的支持 NVIDIA 11 的 NVIDIA 驱动程序。
bert_squad2_qa_gpu.py文件与bert_squad2_qa_cpu.py文件几乎相同。这意味着只需很少甚至不做任何更改,就可以使用 NVIDIA GPU s 运行作业。在我们的示例中,我们有几个额外的 GPU 设置,比如用下面的代码设置内存增长。
physical_devices = tf.config.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(physical_devices[0], True)
NVIDIA 优化库的推理
NVIDIA TensorRT 优化了推理的深度学习模型,并提供了低延迟和高吞吐量(对于更多的 information )。在这里,我们使用 NVIDIA TensorRT 优化到 BERT 模型,并用它来回答 GPU 在光速下的数据流管道上的问题。用户可以按照 TensorRT 演示 BERT github 存储库 进行操作。
我们还使用了 Polygraphy, ,它是 TensorRT 的高级 python API 来加载 TensorRT 引擎文件并运行推断。在数据流代码中, TensorRT 模型被封装为一个共享实用程序类,允许来自数据流工作进程的所有线程使用它。
比较 CPU 和 GPU 运行
在表 10 中,我们提供了用于示例运行的总运行时间和资源。数据流作业的最终成本是总 v CPU 时间、总内存时间和总硬盘使用量的线性组合。对于 GPU 情况,还有一个 GPU 组件。
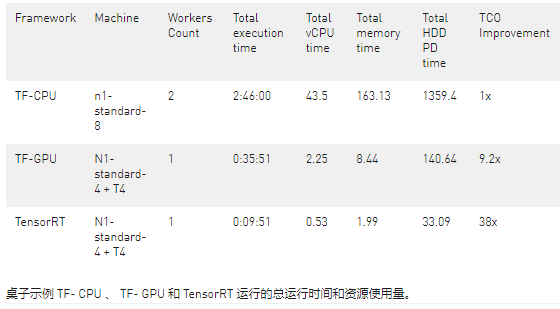
请注意,上表是基于一次运行编译的,确切的数字或许略有波动,但根据我们的实验,比率变化不大。
当使用 NVIDIA GPU( TF- GPU )加速我们的模型时,与使用 CPU ( TF- CPU )相比,包括成本和运行时在内的总节省是 10 倍以上。这意味着,当我们使用 NVIDIA GPU 来推断此任务时,与仅使用 CPU 运行模型相比,我们可以获得更快的运行时间和更低的成本。
使用 NVIDIA 优化的推理库(如 TensorRT ),用户可以在数据流中的 GPU 上运行更复杂和更大的模型。 TensorRT 进一步加速同一作业,比使用 TF- GPU 运行快 3 。 6 倍,从而节省 4 。 2 倍的成本。与 TensorRT 和 TF- CPU 相比,我们的执行时间减少了 17 倍,提供的账单减少了 38 倍。
概括
在本文中,我们比较了 TF- CPU 、 TF- GPU 和 TensorRT 在 Google 云数据流上运行的问答任务的推理性能。数据流用户可以通过利用 GPU 工人和 NVIDIA 优化库获得巨大的好处。
用 NVIDIA GPU s 和 NVIDIA 软件加速深度学习模型推理非常简单。通过添加或更改两行,我们可以使用 TF- GPU 或 TensorRT 运行模型。我们在这里和这里提供了脚本和源文件供参考。
关于作者
Ethem Can NVIDIA 的数据科学家。他在解决客户问题的机器学习应用程序方面拥有超过 12 年的研发经验。在 NVIDIA 之前,他是主要的机器学习开发人员。埃森完成了他的博士学位。在麻州大学计算机科学系, Amherst
Dong Meng 是 NVIDIA 的解决方案架构工程师。董先生在大数据平台和加速器性能优化方面经验丰富。他与公共云服务提供商合作,为机器学习培训/推理和数据分析部署基于云的 GPU 加速解决方案。
Rajan Arora 是 NVIDIA 的解决方案架构师经理,专门从事面向消费互联网行业的机器学习和数据科学应用。 Rajan 在 NVIDIA 工作了 4 年多,致力于开发系统基础设施和广泛的深度学习应用程序。他有博士学位。亚特兰大乔治亚理工学院电子和计算机工程专业。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5087浏览量
103928 -
gpu
+关注
关注
28文章
4795浏览量
129508
发布评论请先 登录
相关推荐
基于NVIDIA GPU的加速服务 为AI、机器学习和AI工作负载提速
《CST Studio Suite 2024 GPU加速计算指南》
Nvidia GPU风扇和电源显示ERR怎么解决
在Ubuntu上使用Nvidia GPU训练模型
压缩模型会加速推理吗?
NVIDIA GPU加速AI推理洞察,推动跨行业创新
Microsoft使用NVIDIA Triton加速AI Transformer模型应用
用NVIDIA TSPP和Triton推理服务器加速模型推理





 工商网监
工商网监
评论