 RAPIDS cuML中的输入输出可配置性
RAPIDS cuML中的输入输出可配置性
APIDS 机器学习库 cuML 支持多种类型的输入数据格式,同时尝试以最适合用户工作流的输出格式返回结果。 RAPIDS 团队为 cuML 添加了支持不同类型用户的功能:

图 1 :一个优化的 cuML 工作流示例。
最大化兼容性
使用现有 NumPy 、 Scikit-learn 和传统的基于 PyData 库的工作流的用户: cuML 的默认行为,允许尽可能多的格式,以及其基于 Scikit-learn 的 API 设计,允许以最小的工作量和无中断的方式移植这些工作流的一部分。因此,例如,您可以使用 NumPy 数组作为输入,然后返回 NumPy 数组作为输出,正如您所期望的那样,只是速度要快得多。
最大化性能
希望通过将所有内容都保存在 GPU 内存中来获得最终性能的用户: cuML 使用的开源标准和行为的可配置性允许用户以较低的努力实现最高性能。本文将详细介绍用户如何利用这项工作从 cuML 和 GPU s 中获得最大的好处。
兼容的输入格式: CUDA 数组接口的奇迹
很大程度上要感谢 cuda_array_interface ,即所谓的 CAI , cuML 接受多种数据格式:
cuDF 对象(数据帧和序列)
pandas 对象(数据帧和序列)
NumPy 阵列
CuPy 和 Numba 设备阵列
任何与 CAI 兼容的对象,如 PyTorch 和 CuPy 数组。这组被称为 CAI 数组。
这个列表根据用户需求不断扩展。例如, cuML 团队正在为 dlpack 阵列标准开发 直接支持 ,与 TensorFlow 的新支持正好吻合。也可以通过 cuDF 还是丘比 或 dlpack 支持来实现。如果您有当前不支持的特定数据格式,请提交问题或请求 在 GitHub 上 。
默认行为: cuML 如何开箱即用?
cuML 的默认行为被设计成尽可能多地镜像输入。因此,例如,如果您在 cuDF 中执行 ETL ,这对于 RAPIDS 用户非常典型,您将看到如下内容:
import cuml
import cudf
df = cudf.DataFrame()
df[1] = [1.0, 2.0, 5.0]
df[2] = [4.0, 2.0. 1.0]
df[3] = [4.0, 2.0. 1.0]
kmeans = cuml.KMeans(n_clusters=2)
kmeans.fit(df)
print(type(kmeans.labels_))
# 《class ‘cudf.core.series.Series’》
镜像 cuML 行为的默认输入格式类型。
使用 cuDF 数据帧时, cuML 会返回 cuDF 对象(在本例中是一个序列)。但是,如前所述, cuML 还允许您在不更改 cuML 调用的情况下使用 NumPy 数组:
import cuml
import numpy as np
ary = np.array([[1.0, 4.0, 4.0], [2.0, 2.0, 2.0], [5.0, 1.0, 1.0]])
kmeans = cuml.KMeans(n_clusters=2)
kmeans.fit(ary)
print(type(kmeans.labels_))
# 《class ‘numpy.ndarray’》
原始视图默认输入格式类型镜像 cuML 镜像 NumPy 数组的行为。
在本例中,现在 cuML 以 NumPy 数组的形式返回结果。镜像输入数据类型格式是 cuML 的默认行为,通常情况下,该行为是:
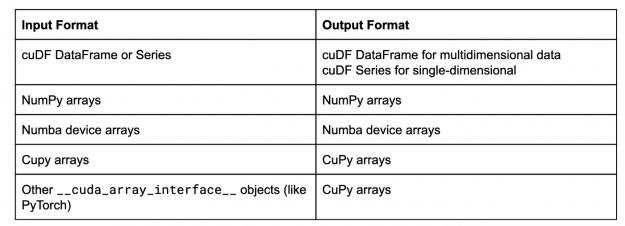
表 1 :可接受的输入格式和默认输出行为列表。
这个列表在不断增长,所以希望很快能在该表中看到类似 dlpack 兼容库的内容。
可配置性:如何让 cuML 按自己的方式工作?
cuML 允许用户全局配置输出类型。例如,如果您的 ETL 和机器学习工作流基于 GPU ,但依赖于基于 NumPy 的可视化框架,请尝试以下操作:
import cupy as cp
import numpy as np
import cuml
cuml.set_global_output_type(‘numpy’)
ary = cp.array([[1.0, 4.0, 4.0], [2.0, 2.0, 2.0], [5.0, 1.0, 1.0]])
kmeans = cuml.KMeans(n_clusters=2)
kmeans.fit(ary)
print(type(kmeans.labels_))
# 《class ‘numpy.ndarray’》
使用 cuML 的“ set \ u global \ u output \ u type ”`
使用 set_global_output_type 指令会影响对 cuML 的所有后续调用。如果用户需要更细粒度的控制(例如,您的模型由 GPU 库处理,但只有一个模型需要是 NumPy 数组才能进行专门的可视化),则可以使用以下机制:
cuML 的上下文管理器 using_output_type :
import cuml
import cupy as cp
ary = [[1.0, 4.0, 4.0], [2.0, 2.0, 2.0], [5.0, 1.0, 1.0]]
ary = cp.asarray(ary)
with cuml.using_output_type(‘cudf’):
dbscan = cuml.DBSCAN(eps=1.0, min_samples=1)
dbscan.fit(ary)
print(type(dbscan_float.labels_))
# 《class ‘cudf.core.Series’》
kmeans = cuml.KMeans(n_clusters=2)
kmeans.fit(ary)
print(type(kmeans.labels_))
# 《class ‘cupy.core.core.ndarray’》
使用 cuML 的上下文管理器` using \ u output \ u type `
设置单个模型的输出类型:
import cupy as cp
import cuml
ary = cp.array([[1.0, 4.0, 4.0], [2.0, 2.0, 2.0], [5.0, 1.0, 1.0]])
kmeams = cuml.KMeans(n_clusters=2, output_type=‘numpy’)
kmeans.fit(ary)
print(type(kmeans.labels_))
# 《class ‘numpy.ndarray’》
这种新功能可以自动将数据转换为方便的格式,而无需手动从多种类型转换数据。以下是模型为了解返回内容而遵循的规则:
如果在构建模型时指定了输出类型,例如 cuml.KMeans(n_clusters=2, output_type=’numpy’) ,那么它将给出该类型的结果。
如果模型是使用 cuml.using_output_type 在上下文管理器 with 中构建的,那么模型将使用该上下文的输出类型。
如果 output_type 是使用 set_global_output_type 设置的,那么它将返回该类型的结果。
如果没有指定上述任何一项,则模型将镜像用于输入的对象的类型,如“默认行为”部分中所述。
效率:我应该使用什么格式?
既然您知道了如何使用 cuML 的输入和输出可配置性,那么问题是,最好使用什么格式?这将取决于你的需要和优先级,因为所有的格式都有权衡。让我们考虑一个简单的工作流程:

图 2 :使用 ML 的简单数据科学工作流。
使用基于 NumPy 的对象
在下面的图 3 中,传输(粉色框)限制了 cuML 可以给您的加速量,因为通信使用较慢的系统内存,您必须通过 PCI-Express 总线。每次使用 NumPy 数组作为模型的输入或要求模型返回 NumPy 数组时,主系统内存和 GPU 之间至少有一次内存传输。
乍一看,有人认为这影响不大。然而,将尽可能多的数据保存在 GPU 中,即使不是最大的原因,也是 RAPIDS 实现闪电般速度的原因之一。

图 3 :说明使用 NumPy 数组进行输入或输出时发生什么的工作流。
使用 cuDF 对象
使用 GPU 对象而不是 NumPy 数组具有重要意义。例如,使用 cuDF 对象如下图 4 所示。橙色框表示完全在 fast GPU 内存上发生的转换。不幸的是,这意味着在 cuML 算法处理过程中会有一个额外的数据副本,这会限制在特定 GPU 中可以处理的数据集的大小。

图 4 :说明 GPU 内存中发生的转换的工作流。
DataFrames (和 Series )是非常强大的对象,允许用户以平易近人和熟悉的方式进行 ETL 。但要提供这一点,它们是具有大量复杂性的复杂结构,以实现此功能。
其中有几个例子:
除了数据之外,每一列都可以有一个位掩码数组(基本上是一个由 0 和 1 组成的附加数组),允许用户在数据中有丢失的条目。
由于数据帧在添加/删除行和列时需要提供灵活性,因此每一列 MIG 在内存中应该彼此远离。
当然,还有一些附加的结构,比如索引和列名。
但是,这些限制为某些分析工作流带来了一些困难:
首先,许多算法在所有数据都是连续的情况下工作得更好,例如,所有字节都分组在同一个内存区域中,因为高效地访问内存是快速处理数据的一个重要组成部分(特别是对于 GPU s !)。
内存是一种有限的资源(一般来说,但对于 GPU 和加速器来说更是如此),因此额外的开销会产生非常显著的影响。
使用设备阵列
下面的图 5 说明了用于输入或输出的 CAI 数组如何在 cuML 中处理数据时具有最低的开销。通过使用 CAI ,不会发生内存传输或转换。 cuML 直接使用 CAI 的属性访问数据,然后返回 CAI 数组。这些格式几乎没有开销。设备阵列,例如来自 CuPy 或 Numba 的设备阵列,比数据帧/系列等效物的结构要简单得多。与 NumPy 类似,它们被设计成由元数据描述的连续内存块。这个设计决定就是为什么 NumPy 对于最初的 Python 生态系统是革命性的。考虑到所有这些,设备阵列是使用 cuML 最有效的方法也就不足为奇了!
如前所述,从 cuML 的角度来看,所有 CAI 数组本质上是相同的,因此您的工作流可以组合 Numba 、 CuPy 、 cuML 等功能,而无需执行昂贵的内存复制操作。

图 5 :说明用于输入或输出的 CAI 数组如何在 cuML 中处理数据时具有最低开销的工作流。
选择数据类型的提示
那么您应该使用什么数据类型呢?如前所述,这取决于场景,但这里有一些建议:
如果您有一个现有的 PyData 工作流,那么可以利用 cuML 的 NumPy 功能逐个尝试不同的模型。从加速工作流程中最慢的部分开始。 DBSCAN 和 UMAP 是 cuML 中 modInels 的很好例子,即使它们自己使用,没有完全的 RAPIDS 加速,也能提供巨大的加速和改进。
潜在陷阱:这可能会在主系统内存和 GPU 内存之间造成通信瓶颈。
如果您的工作流程非常依赖 ETL ,需要大量的 cuDF 工作,而大部分处理和开发时间都在数据加载或转换中,请将其作为 cuDF 对象,并让 cuML 管理转换。
潜在的陷阱:这个 MIG ht 限制了 GPU 中单个模型可以容纳的数据量。
如果训练或推理的最终速度是关键,那么调整您的工作流以尽可能多地使用 CUDA rray 接口库。
使用所有这些技巧,您可以配置 cuML 来优化您的需求,并更好地估计工作流的影响和瓶颈。您的新工作流现在可能如下所示:

图 6 :用户在 cuML 中优化的工作流。
下一步是什么?
以下是我们很高兴在接下来的帖子中分享的一些活跃领域:
多节点多 – GPU ( MNMG ) cuML :还有很多额外的工作要做。 RAPIDS cuML 团队中的许多工程师目前正在构建领先算法的多节点多 – GPU ( MNMG )实现,以实现大规模的分布式机器学习。分布式数据本身就是一个完整的主题,很快就会有更多的帖子发布。但是从版本 0 。 13 开始, mnmgcuml 接受 Dask-cuDF 对象(使用 Dask 的 cuDF 的分布式等价物)和 CuPy 支持的 Dask 阵列 。 cuML 在 MNMG 算法中生成反映您使用的输入的结果,类似于 cuML 对单个 GPU 的默认行为。我们正在努力为 MNMG-cuML 算法添加更多的可配置性。我们将讨论您的数据是如何分布的,以及您使用的格式对 cuML 的影响。
有关数据及其含义的较低级别详细信息: 许多细节,如数据类型或内存中数据的顺序,都会影响 cuML 。我们将讨论这些细节如何影响 cuML ,以及它与传统 PyData 库的比较和区别。
抽象与设计 :最近在 RAPIDS 软件堆栈中引入的抽象和机制,如 CumlArray ,允许 cuML 提供此功能,同时降低代码复杂性和保证结果所需的测试数量。我们将讨论这个,连同 CAI ,如何让用户能够使用多个库,比如 CuPy , cuDF , cuML ,而不费吹灰之力。
Conclusion
这篇文章讨论了 cuML 的输入和输出可配置能力,支持的不同数据格式,以及 cuML 中每种格式的优缺点。这篇文章展示了在现有工作流中采用 cuML 是多么容易。 cuML 的 sciketlearnapi 和格式输出镜像允许您使用它作为现有库的替代品。为了获得最大的性能,用户应该尽量使用 GPU 特定的格式,以及 CuPy 或 Numba 等 CAI 数组。 RAPIDS 团队正在努力改进 cuML 的功能和支持的数据格式。
关于作者
Dante Gama Dessavre 是 NVIDIA 的 RAPIDS 团队的高级数据科学家和工具开发人员。
审核编辑:郭婷
-
API
+关注
关注
2文章
1502浏览量
62117 -
机器学习
+关注
关注
66文章
8422浏览量
132736
发布评论请先 登录
相关推荐
误差放大器的输入输出关系
隔离变压器输入输出可以随便接吗
寄存器的输入输出方式
PLC运动控制中的输入输出设备
引入负反馈对输入输出电阻的影响
PLC输入输出信号异常的原因分析
为什么可以将一个GPIO引脚同时配置为输入输出模式呢?

输入输出复用电路的定义 复用器的输出由什么控制
锁相环的输入输出相位一致吗?
s71200有几路脉冲输出 s71200输入输出接线图





 工商网监
工商网监
评论