 如何优化数据实现机器学习高数据吞吐量
如何优化数据实现机器学习高数据吞吐量

译者 | 李睿
作者:Bin Fan, InfoWorld
机器学习工作负载需要高效的基础设施来快速产生结果,而模型训练非常依赖大型数据集。在所有机器学习工作流程中,第一步是将这些数据从存储集中到训练集群,而这也会对模型训练效率产生显著影响。
长期以来,数据和人工智能平台工程师一直在考虑以下问题来管理数据:
数据可访问性:当数据跨越多个来源并且数据被远程存储时,如何使训练数据可访问?
数据管道:如何将数据作为一条管道进行管理,无需等待即可将数据持续输入到训练工作流程中?
性能和GPU利用率:如何同时实现低元数据延迟和高数据吞吐量以保持GPU不会空闲?
本文将讨论一种新的解决方案,它将用来协调端到端机器学习管道中的数据以解决上述问题。本文将概述常见的挑战和陷阱,并推出编排数据这种新技术,以优化机器学习的数据管道。
模型训练中常见数据挑战
端到端机器学习管道是从数据预处理、清理、模型训练再到推理的一系列步骤,其中模型训练是整个工作流程中最关键和最耗费资源的部分。
下图是一个典型的机器学习管道。它从数据收集开始,然后是数据准备,最后是模型训练。在数据收集阶段,数据平台工程师通常需要花费大量时间让数据工程师可以访问数据,数据工程师则需要为数据科学家准备数据以构建和迭代模型。

训练阶段需要处理大量数据,以确保将数据持续提供给生成模型的GPU。你必须对数据予以管理,以支持机器学习及其可执行架构的复杂性。在数据管道中,每个步骤都会面临相应的技术挑战。
(1)数据收集挑战——数据无处不在
机器学习训练需要采用大型数据集,因此从所有相关来源收集数据至关重要。当数据驻留在数据湖、数据仓库和对象存储中时,(无论是在内部部署、在云中还是分布在多个地理位置)将所有数据组合到一个单一的源中不再可行。对于数据孤岛,通过网络进行远程访问不可避免地会导致延迟。因此如何在保持所需性能的同时使数据可访问是一项重大挑战。
(2)数据准备挑战——序列化数据准备
数据准备从采集阶段的数据开始,包括清理、ETL和转换,然后交付数据以训练模型。如果没有对这个阶段全面考虑,那么数据管道是序列化的,且在等待为训练集群准备的数据时会浪费额外的时间。因此,平台工程师必须弄清楚如何创建并行化的数据管道,并实现高效的数据共享和中间结果的高效存储。
(3)模型训练挑战——I/O与GPU未充分利用
模型训练需要处理数百TB的数据,这些数据通常是大量的小文件,例如图像和音频文件等等。训练涉及需要多次epoch的迭代,从而频繁访问数据。通过不断地向GPU提供数据来保持其忙碌是有必要的,同时优化I/O并保持GPU所需的吞吐量也非易事。
传统方法和常见陷阱
在讨论不同的解决方案之前,先设定一个简化的场景,如下图所示。这里使用一个GPU集群在云中训练,该集群具有多个运行TensorFlow作为机器学习框架的节点。预处理数据存储在Amazon S3中。通常,有两种方法可以将此数据传输到训练集群,下文将予以讨论。

方法一:在本地存储中复制数据
在第一种方法中,整个数据集从远程存储复制到每个服务器的本地存储进行训练,如下图所示。因此,数据局部性得到保证,训练作业从本地读取输入,而不是从远程存储中检索。
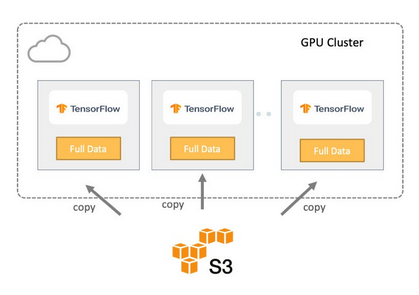
从数据管道和I/O的角度来看,这种方法提供了最高的I/O吞吐量,因为所有数据都是本地的。除了开始阶段,GPU将保持忙碌,因为训练必须等待数据从对象存储完全复制到训练集群。

但这种方法并不适用于所有情况。
首先,数据集必须适合聚合本地存储。随着输入数据集大小的增长,数据复制过程变得更长且更容易出错,从而浪费更多时间和GPU资源。
其次,将大量数据复制到每台训练机上会对存储系统和网络造成巨大压力。在输入数据经常变化的情况下,数据同步可能非常复杂。
最后,因为要使云存储上的数据与训练数据保持同步,人工复制数据既费时又容易出错。
方法二:直接访问云存储
另一种常见的方法是将训练与远程存储上的目标数据集直接连接起来,如下图所示。这种方法与之前的解决方案一样,数据集的大小不是问题,但也面临着一些新的挑战。

首先,从I/O和管道的角度来看,数据是串行处理的。所有的数据访问操作都必须经过对象存储和训练集群之间的网络,使得I/O成为瓶颈。因此,由于I/O吞吐量受到网络限制,GPU会等待并会浪费时间。
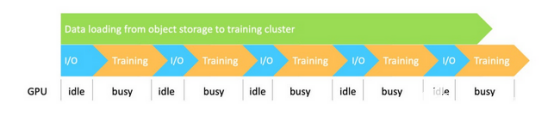
其次,当训练规模较大时,所有训练节点同时从同一个远程存储访问同一个数据集,给存储系统增加了巨大的压力。由于高并发访问,存储可能会变得拥挤,从而导致GPU利用率低。
第三,如果数据集包含大量的小文件,元数据访问请求将占数据请求的很大一部分。因此,直接从对象存储中获取大量文件或目录的元数据成为性能瓶颈,并增加了元数据的操作成本。
推荐的方法——编排数据
为了应对这些挑战和陷阱,在处理机器学习管道中的I/O时,需要重新考虑数据平台架构。在这里推荐一种加速端到端机器学习管道的新方法:数据编排。数据编排技术将跨存储系统的数据访问抽象化,同时将所有数据虚拟化,并通过标准化API和全局命名空间将数据呈现给数据驱动的应用程序。
(1)使用抽象统一数据孤岛
与其复制和移动数据,留在原处也不失为上策,无论是在本地还是在云中。数据编排可以帮助抽象数据以创建统一的视图。这将显著降低数据收集阶段的复杂性。
由于数据编排已经可以与存储系统集成,机器学习框架只需要与单个数据编排平台交互即可访问来自任何连接存储的数据。因此,来自任何来源的数据都可以用来训练,从而提高模型质量。同时,无需人工数据移动到中央源。包括Spark、Presto、PyTorch和TensorFlow在内的所有计算框架都可以访问数据,而无需担心数据的位置。
(2)在数据本地性方面使用分布式缓存
建议不要将整个数据集复制到每台机器上,而是实施分布式缓存,其中数据可以均匀分布在集群中。当训练数据集远大于单个节点的存储容量时,分布式缓存尤其有利。当数据是来自远程时,因为数据是在本地缓存的,它也可以提供助益。因为在访问数据时没有网络I/O,机器学习训练会变得更快且更具成本效益。
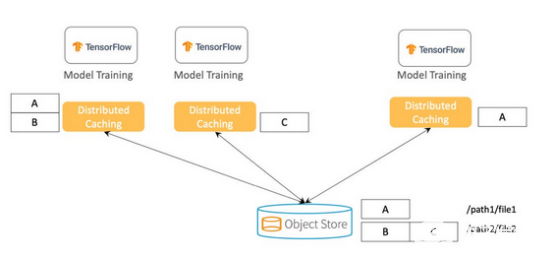
上图显示了存储所有训练数据的对象存储,以及表示数据集的两个文件(/path1/file1和/path2/file2)。与其将所有文件块存储在每台训练机器上,不如将块分布在多台机器上。为了防止数据丢失和提高读取并发性,每个块可以同时存储在多个服务器上。
(3)优化跨管道的数据共享
在机器学习(ML)训练作业中,作业内部和作业之间执行的数据读取和写入之间存在高度重叠。数据共享可以确保所有计算框架都可以访问先前缓存的数据,用于下一步的读写工作负载。例如,如果在数据准备步骤中使用Spark 进行ETL,数据共享可以确保输出数据被缓存并可供下一阶段使用。通过数据共享,整个数据管道获得了更好的端到端性能。
(4)通过并行化数据预加载、缓存和训练来编排数据管道
可以通过执行预加载和按需缓存来编排数据管道。如下图显示,使用数据缓存从源加载数据可以与实际训练任务并行完成。因此,在访问数据时,训练受益于高数据吞吐量,而无需在训练前等待缓存完整数据。
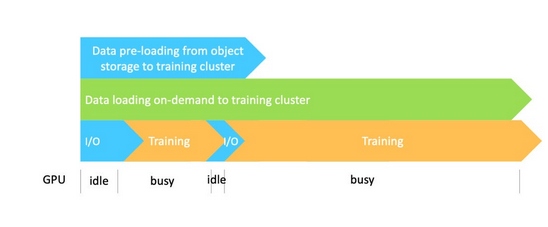
虽然一开始会有一些I/O延迟,但因为数据已经加载到缓存中,等待时间会有所减少。这种方法可以减少重复步骤,从对象存储到训练集群的数据加载、缓存、训练要求的数据加载以及训练都可以并行完成,从而大大加快整个过程。
通过跨机器学习管道的步骤编排数据,可消除数据从一个阶段流向下一个阶段时串行执行和相关的低效问题,同时也将具有较高的GPU利用率。下表将对这种新方法与两种传统方法进行比较:

如何为机器学习工作负载编排数据
这里以Alluxio为例,展示如何使用数据编排。同样,我们还将使用上面提到的简化场景。为了安排TensorFlow作业,可使用Kubernetes或公共云服务。

使用Alluxio编排机器学习和深度学习训练通常包括三个步骤:
(1)在训练集群上部署Alluxio。
(2)挂载Alluxio作为本地文件夹来训练作业。
(3)使用训练脚本从本地文件夹(由Alluxio支持)加载数据。
不同存储系统中的数据可以在挂载后通过Alluxio立即访问,并且可以通过基准脚本透明访问,无需修改TensorFlow。这显著简化了应用程序开发过程,不然就需要集成每个特定的存储系统以及凭证的配置。
可参照这里的方法使用Alluxio和TensorFlow运行图像识别。
数据编排优秀实践
因为没有一劳永逸的方法,所以数据编排最好在以下场景中使用:
需要分布式训练。
有大量的训练数据(10TB或更多),尤其是在训练数据中有很多小文件和图像的情况下。
GPU资源没有被网络I/O充分占用。
管道使用许多数据源和多个训练/计算框架。
当处理额外的训练请求时,底层存储需要稳定。
多个训练节点或任务使用相同的数据集。
随着机器学习技术的不断发展,框架执行更复杂的任务,管理数据管道的方法也将不断改进。通过将数据编排扩展到数据管道,端到端训练管道的效率和资源利用率都可以得到提高。
-
人工智能
+关注
关注
1821文章
50471浏览量
267610 -
机器学习
+关注
关注
67文章
8570浏览量
137381
发布评论请先 登录
RDMA设计64:数据吞吐量性能测试分析
RDMA设计65:如何根据包吞吐量性能权衡设计?
网卡吞吐量测试解决方案
优化FPGA利用率和自动测试设备数据吞吐量参考设计
浅析敏捷高吞吐量卫星通讯载荷
FF H1基于RDA的吞吐量优化算法
DM6467的吞吐量性能信息和系统芯片(SoC)架构的详细概述




评论