 机器翻译中细粒度领域自适应的数据集和基准实验
机器翻译中细粒度领域自适应的数据集和基准实验
01
—
研究动机
近年来,神经机器翻译(Neural Machine Translation, NMT)研究取得了重大的进展。从大规模平行数据中学习具有大规模参数的通用神经机器翻译模型已经比较成熟。当需要处理特定场景中的翻译任务时,人们广泛采用领域自适应技术将一个通用领域的神经机器翻译模型迁移到目标领域。
然而现有领域自适应研究考虑的领域仍比较粗糙,例如法律、医疗、科技、字幕等领域。事实上,在这些领域下还存在着非常多的细粒度领域。例如,科技领域下还包含着自动驾驶(Autonomous Vehicles, AV)、AI教育(AI Education, AIE)、实时网络通信(Real-Time Networks, RTN)、智能手机(Smart Phone, SP)等等细粒度领域。即使这些领域都属于科技领域,但是在这些领域中却存在着不同的翻译现象。在词级别,以中文“卡”字为例,它在不同的细粒度科技领域中其实对应着不同的英文翻译(表格1)。在句子级别,在科技领域(FGraDA)和通用领域(CWMT)的分布存在着较大的差异的同时(图1的左图),科技领域内部的细粒度领域的分布仍然存在着一定的差异(图1的右图)。
表格1中文“卡”在几个科技细粒度领域对应的翻译

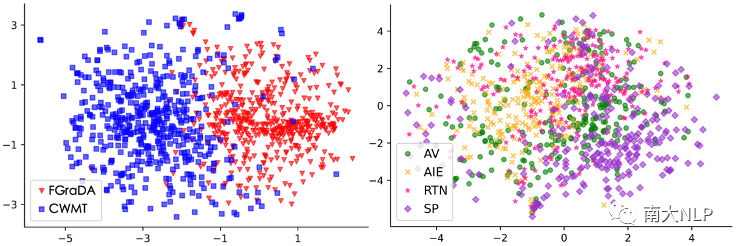
图1数据分布差异可视化分析
细粒度领域自适应问题是一个重要的实际应用问题。当研发人员需要为某个特定主题提供翻译服务(比如为某个主题的会议提供翻译)时,往往需要在特定的细粒度领域上取得更好的翻译性能。在这些场景中,细粒度领域的专业性、研发部署的预算要求使得人们难以获取大规模的细粒度领域平行数据,这进一步加大了建模细粒度领域的难度。当细粒度领域建模不准确时,NMT模型很容易出现翻译错误,包括专有名词错误、一词多义错误、漏译错误等(表格2)。为了精确建模细粒度领域、解决细粒度领域自适应问题,需要思考如何从多样的非平行数据中挖掘有效的目标领域信息。
表格2三种典型翻译错误及样例

02
—
贡献
本文构建了一份细粒度领域自适应的中英机器翻译数据集(FGraDA)。该数据集并不是为特定领域的翻译提供数据支持,而是展示了一个包含多个细粒度领域的实际场景,制作了评估领域翻译效果的验证集和测试集数据,并提供了实际应用中可能面临的多种类型的数据资源。希望该数据集可以支持在细粒度领域自适应方向的研究。
在FGraDA数据集上,我们比较了现有的部分自适应方法,可以作为后续研究工作的实验基准;也分析了现有方法在进行细粒度领域自适应时存在的一些缺陷,希望能为后续研究工作提供参考。
03
—
数据集构建
为了模拟真实场景,我们以四个有代表性的会议(CCF-GAIR, GIIS, RTC, Apple-Events)为基础构建FGraDA数据集。这四个会议对应的领域分别是:自动驾驶、AI教育、实时网络通信、智能手机,这些领域都属于科技领域下的细分领域。我们为每个领域配备了词典资源、wiki资源、验证集、测试集(数据规模如表格3所示)。词典资源和wiki资源作为获取成本较低的非平行资源,包含着丰富的领域信息,用于细粒度领域建模及自适应。验证集和测试集则用于评估自适应效果。下面将具体介绍这些资源的构建过程。
表格3FGraDA数据集各领域数据规模报告

词典相比于平行句对是一种获取成本更低的资源。与此同时,词典资源可以提供领域词语的翻译信息,这对于处理细粒度领域翻译任务是非常有帮助的。因此,我们为每个领域人工标注了一定规模的双语词典资源。表格4中展示了一些我们标注的词典条目示例。标注完成后,我们请语言专家确认了词典的准确性和可靠性。
表格4词典条目示例

Wiki资源是机器翻译研究中的一种重要的可利用资源。鉴于领域词典中包含大量的领域词语,我们利用这些英文领域词语抽取细粒度领域相关的wiki页面。具体来说,我们首先抽取标题中包含领域词语的wiki页面作为种子页面(seed page)。这些种子页面中的内容是与细粒度领域高度相关的,并且这些页面中的部分内容还会链接到其他相关页面(如图2所示)。因此我们利用这种天然存在的链接关系,收集种子页面所链接到的一跳页面(one-hop-link page),进一步扩充wiki资源。最终,抽取出的种子页面和一跳页面共同构成了细粒度领域相关的wiki资源(数据规模如表格5所示)。该资源不仅包含了大量的单语文本,还包含了诸如链接关系的结构知识,具有非常大的利用价值。
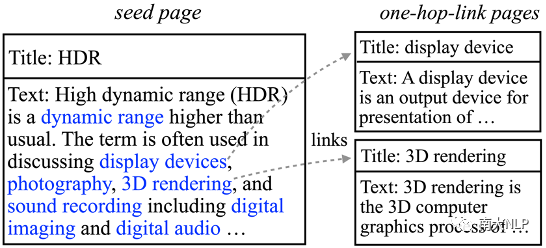
图2Wiki资源示例
表格5Wiki资源数据规模报告
最后,为了评估细粒度领域自适应效果,我们为各个细粒度领域标注了平行数据作为验证集和测试集。我们从上面提到的四个会议上收集了70个小时的录音,然后使用内部工具将其转录为文本。随后我们进行了数据清洗和数据脱敏,去除了文本语料中领域无关的句子和涉及隐私的人名、公司名。最终,经过语言专家标注,一共在四个领域上得到了4767条中英平行句对。我们把每个领域的平行数据分为两部分:200条作为验证集,剩下的作为测试集。我们可以看到,仅仅是收集少量平行数据用于评估就需要花费大量的人力、物力代价。在这种情况下,期望收集更多的平行数据用于自适应学习是不现实的,因此本数据集也没有提供这种资源。
04
—
基线结果
我们在FGraDA数据集上比较了部分现有自适应方法(实验结果如表格6所示)。实验结果表明现有方法能够利用数据集中提供的资源取得一定的提升,并且综合使用词典资源和wiki资源取得的提升最多。但是,这些方法在部分领域上的翻译性能仍然较弱。为了进一步对自适应效果进行分析,我们统计了表现最好的基线方法在测试集上的句子级别BLEU的分布情况(如图3所示)。分布情况显示自适应模型在大部分句子上的翻译状况还不理想(BLEU分数低于20),这也表明细粒度领域的翻译效果仍然有待提升。
表格6基线方法在细粒度领域上的翻译性能(BLEU)
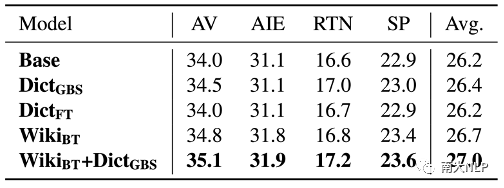
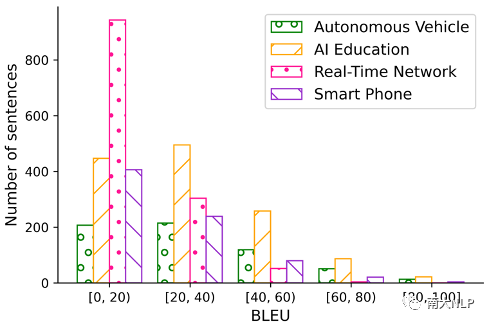
图3句子级别BLEU分布情况
05
—
有待解决的挑战
在词典资源方面,我们发现现有的领域自适应方法还无法充分利用这些词语翻译知识。我们在测试集上统计了领域词典条目的翻译准确率(实验结果如表格7所示)。实验结果表明,即使采用词约束解码算法Grid Beam Search(GBS),自适应模型也无法100%正确翻译出领域词典中的领域词语。为了进一步分析在细粒度领域自适应中使用词典资源的挑战,我们尝试了调节GBS算法中的权重超参数(实验结果如图4所示)。实验结果表明尽管我们可以调节GBS算法中的权重超参数强制模型翻译出更多领域词语,但是翻译结果的BLEU分数会大幅下降。这说明,简单地通过词约束解码的方式并不能翻译好领域词语,如何更好地利用领域词典仍然有待探索。
表格7领域词典条目翻译准确率(%)
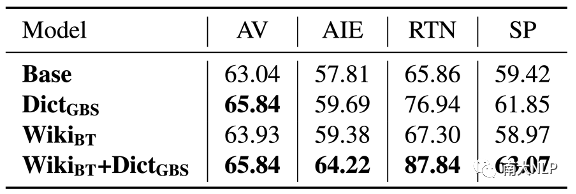
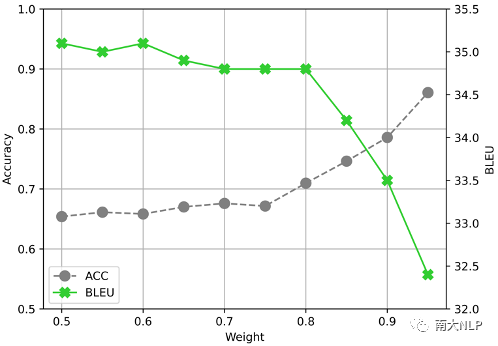
图4不同权重下词典词语翻译准确率和BLEU分数的变化情况
在wiki资源方面,现有的领域自适应方法主要将wiki页面中包含的文本作为单语数据使用,忽视了wiki页面中包含的各种结构化知识。这些知识对于理解领域词语语义可能会起到非常重要的作用。我们在这里列举出两种重要的结构化知识:(1)wiki页面正文的第一句话通常是标题的定义。以图2中的页面标题“HDR”为例,正文的第一句话“High dynamic range (HDR) is a dynamic range higher than usual”,这是“HDR”的定义,可以帮助理解HDR的含义。(2)当前wiki页面中链接到其他wiki页面的词语往往和当前wiki页面的标题是高度相关的。同样以图2中的页面标题“HDR”为例,该页面中包含的“dynamic range”,“display devices”,“photography”等词语都是和“HDR”高度相关的,也可以帮助理解“HDR”的含义。
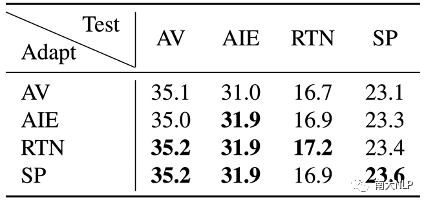
在领域层级方面,现有的领域自适应方法只考虑使用目标领域对应的领域资源进行领域自适应,忽略了利用相近细粒度领域中的资源。为了量化细粒度领域之间的近似关系,我们评估了适应到各个领域的模型在另外三个领域的翻译性能(实验结果如表格8所示)。从翻译性能的差异可以看出细粒度领域之间有的差距较大,有的差距较小。如何利用相近细粒度领域中的资源辅助当前目标细粒度领域建模,以及如何利用粗细粒度领域间的层级关系仍然是值得探究的问题。
表格8迁移到不同细粒度领域上的模型翻译性能对比(BLEU)
06
—
总结
本文从实际问题出发,构建了细粒度领域自适应机器翻译数据集FGraDA。我们在FGraDA 数据集对比了现有的部分领域自适应方法,发现细粒度领域的翻译效果仍然有待提升。进一步的分析显示FGraDA数据集中提供的多样非平行资源中仍然存在着非常多有待挖掘的、对自适应有益的信息。如何从各种不同资源中挖掘、利用这些信息建模细粒度领域,实现细粒度领域自适应是一个有待研究的重要课题。
审核编辑 :李倩
-
机器翻译
+关注
关注
0文章
139浏览量
14881 -
数据集
+关注
关注
4文章
1208浏览量
24698
原文标题:LREC'22 | 机器翻译中细粒度领域自适应的数据集和基准实验
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【「具身智能机器人系统」阅读体验】+数据在具身人工智能中的价值
空间光调制器自适应激光光束整形
Perforce Helix Core通过ISO 26262认证!为汽车软件开发团队提供无限可扩展性、细粒度安全性、文件快速访问等

如何设定机器人语义地图的细粒度级别
步进电机如何自适应控制?步进电机如何细分驱动控制?

如何在自己的固件中增加wifi自适应性相关功能,以通过wifi自适应认证测试?
杭州中天微系统:自适应时钟频率控制领域创新技术获硕果
什么是自适应光学?自适应光学原理与方法的发展
TCP协议技术之自适应重传
语音数据集:智能驾驶中车内语音识别技术的基石
ICLR 2024 清华/新国大/澳门大学提出一模通吃的多粒度图文组合检索MUG:通过不确定性建模,两行代码完成部署

Spring Boot和飞腾派融合构建的农业物联网系统-改进自适应加权融合算法
创想焊缝跟踪系统在尔必地机器人自适应焊接中的应用案例






 工商网监
工商网监
评论