 使用FIL加速基于树模型的推理与预测
使用FIL加速基于树模型的推理与预测

介绍
RAPIDS森林推理库,亲切地称为 FIL ,极大地加速了基于树的模型的推理(预测),包括梯度增强的决策树模型(如 XGBoost 和 LightGBM 的模型)和随机森林 ( 要深入了解整个库,请查看 最初的 FIL 博客 。原始 FIL 中的模型存储为密集的二叉树。也就是说,树的存储假定所有叶节点都出现在同一深度。这就为浅树提供了一个简单、运行时高效的布局。但对于深树,它也需要 lot 的 GPU 内存2d+1-1深度树的节点 d 。为了支持最深的森林, FIL 支持
稀疏树存储。如果稀疏树的分支早于最大深度 d 结束,则不会为该分支的潜在子级分配存储。这可以节省大量内存。虽然深度为 30 的 稠密的 树总是需要超过 20 亿个节点,但是深度为 30 的最瘦的 稀疏 树只需要 61 个节点。
在 FIL中使用稀疏森林
在 FIL 使用稀疏森林并不比使用茂密森林困难。创建的林的类型由新的 storage_type 参数控制到 ForestInference.load() 。其可能值为:
DENSE 为了营造一片茂密的森林,
SPARSE 要创建稀疏的森林,
AUTO (默认)让 FIL 决定,当前总是创建一个密林。
无需更改输入文件、输入数据或预测输出的格式。初始模型可以由 scikit learn 、 cuML 、 XGBoost 或 LightGBM 进行训练。下面是一个将 FIL 用于稀疏森林的示例。
from cuml import ForestInference import sklearn.datasets # Load the classifier previously saved with xgboost model_save() model_path = 'xgb.model' fm = ForestInference.load(model_path, output_class=True, storage_type='SPARSE') # Generate random sample data X_test, y_test = sklearn.datasets.make_classification() # Generate predictions (as a gpu array) fil_preds_gpu = fm.predict(X_test.astype('float32'))
实施
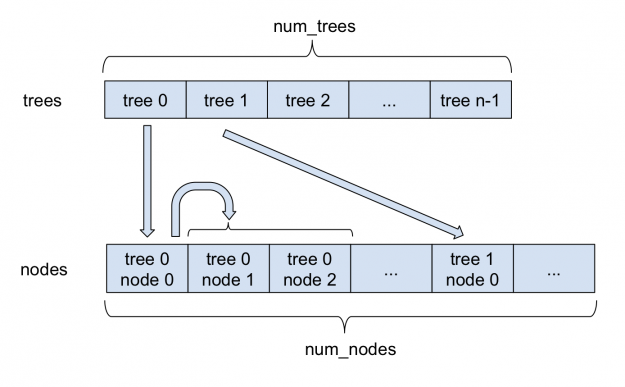
图 1 :在 FIL 中存储稀疏森林。
图 1 描述了稀疏森林是如何存储在 FIL 中的。所有节点都存储在单个大型 nodes 阵列中。对于每个树,其根在节点数组中的索引存储在 trees 数组中。每个稀疏节点除了存储在密集节点中的信息外,还存储其左子节点的索引。由于每个节点总是有两个子节点,所以左右节点相邻存储。因此,右子级的索引总是可以通过将左子级的索引加 1 来获得。在内部, FIL 继续支持密集节点和稀疏节点,这两种方法都来自一个基林类。
与内部更改相比,对 pythonapi 的更改保持在最低限度。新的 storage_type 参数指定是创建密集林还是稀疏林。此外,一个新的值 ‘AUTO’ 已经成为推断算法参数的新默认值;它允许 FIL 自己选择推理算法。对于稀疏林,它当前使用的是 ‘NAIVE’ 算法,这是唯一受支持的算法。对于密林,它使用 ‘BATCH_TREE_REORG’ 算法。
基准
为了对稀疏树进行基准测试,我们使用 sciket learn 训练了一个随机林,具体来说就是 sklearn.ensemble.RandomForestClassifier 。然后,我们将得到的模型转化为一个 FIL 林,并对推理的性能进行了测试。数据是使用 sklearn.datasets.make_classification() 生成的,包含 200 万行,在训练和验证数据集之间平分, 32 列。对于基准测试,在一百万行上执行推断。
我们使用两组参数进行基准测试。
深度限制设置为 10 或 20 ;在这种情况下,密集或稀疏的 FIL 林都可以放入 GPU 内存中。
无深度限制;在这种情况下, SKLearn 训练的模型包含非常深的树。在我们的基准测试运行中,树的深度通常在 30 到 50 之间。试图创建一个稠密的 FIL-forest 会耗尽内存,但是可以顺利创建一个稀疏的 forest 。
在这两种情况下,林本身的大小仍然相对较小,因为树中的叶节点数限制为 2048 个,并且林由 100 棵树组成。我们测量了 CPU 推理和 GPU 推理的时间。 GPU 推理是在 V100 上进行的, CPU 推理是在一个有两个插槽的系统上进行的,每个插槽有 16 个内核,带有双向超线程。基准测试结果如图 2 所示。
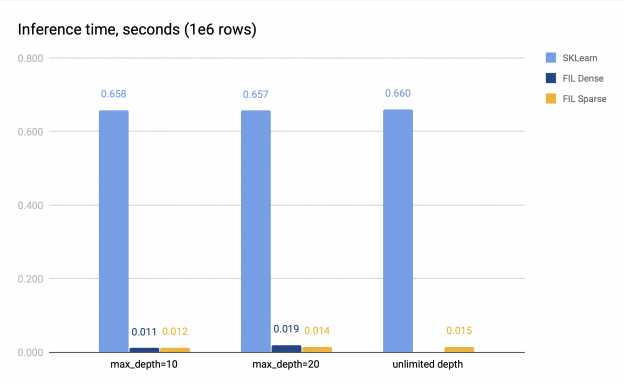
图 2 : FIL (密集稀疏树)和 SKLearn 的基准测试结果 。
稀疏和密集 FIL 预测器(如果后者可用)都比 SKLearn CPU 预测器快 34-60 倍。对于浅层森林,稀疏 FIL 预报器比稠密 FIL 预报器慢,但是对于较深的森林,稀疏 FIL 预报器可以更快;具体的性能差异各不相同。例如,在图 2 中, max \ u depth = 10 时,密集预测器比稀疏预测器快 1 。 14 倍,但 max \ u depth = 20 时,速度较慢,仅达到稀疏预测器的 0 。 75 倍。因此,对于浅层森林应采用稠密 FIL 预报。
然而,对于深林,稠密预测器的内存不足,因为它的空间需求随着森林深度呈指数增长。稀疏预测器没有这个问题,即使对于非常深的树,它也能在 GPU 上提供快速的推断。
结论
在稀疏森林的支持下, FIL 适用于更广泛的问题。无论您是使用 XGBoost 构建梯度增强的决策树,还是使用 cuML 或 sciket learn 构建随机林, FIL 都应该是一个方便的选择,可以加速您的推理。
关于作者
Andy Adinets 自2005年以来一直从事GPU编程工作,自2017年7月底以来一直在Nvidia担任AI开发人员技术工程师近4年。他目前正在从事多个项目,包括Forest Inference Library(FIL) )和GPU排序。 当机会出现时,他还喜欢优化各种GPU算法。
审核编辑:郭婷
-
cpu
+关注
关注
68文章
11327浏览量
225888 -
gpu
+关注
关注
28文章
5271浏览量
136069
发布评论请先 登录
大模型推理服务的弹性部署与GPU调度方案
使用NORDIC AI的好处
LLM推理模型是如何推理的?

华为数据存储与「DaoCloud 道客」发布AI推理加速联合解决方案
在Ubuntu20.04系统中训练神经网络模型的一些经验
什么是AI模型的推理能力
NVIDIA Nemotron Nano 2推理模型发布

NVIDIA从云到边缘加速OpenAI gpt-oss模型部署,实现150万TPS推理




评论