 如何使用NVIDIA Docker部署GPU服务器应用程序
如何使用NVIDIA Docker部署GPU服务器应用程序

在过去的几年里,使用容器来大规模部署数据中心应用程序的数量急剧增加。原因很简单:容器封装了应用程序的依赖项,以提供可重复和可靠的应用程序和服务执行,而无需整个虚拟机的开销。如果您曾经花了一天的时间为一个科学或 深度学习 应用程序提供一个包含大量软件包的服务器,或者已经花费数周的时间来确保您的应用程序可以在多个 linux 环境中构建和部署,那么 Docker 容器非常值得您花费时间。
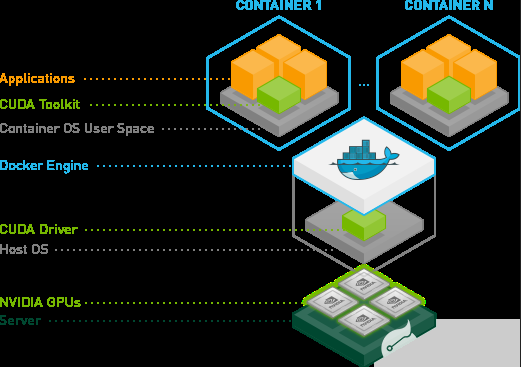
图 1 : Docker 容器封装了应用程序的依赖项,以提供可重复和可靠的执行。 NVIDIA Docker 插件支持在任何 Linux GPU 服务器上部署 GPU – 加速应用程序,并支持 NVIDIA Docker 。
在 NVIDIA ,我们以各种方式使用容器,包括开发、测试、基准测试,当然还有生产中的容器,作为通过 NVIDIA DGX-1 的云管理软件部署深度学习框架的机制。 Docker 改变了我们管理工作流程的方式。使用 Docker ,我们可以在工作站上开发和原型化 GPU 应用程序,然后在任何支持 GPU 容器的地方发布和运行这些应用程序。
在本文中,我们将介绍 Docker 容器;解释 NVIDIA Docker 插件的好处;通过构建和部署一个简单的 CUDA 应用程序的示例;最后演示如何使用 NVIDIA Docker 运行当今最流行的深度学习应用程序和框架,包括 DIGITS 、 Caffe 和 TensorFlow 。
上周在 DockerCon 2016 年 上, Felix 和 Jonathan 做了一个演讲“使用 Docker 实现 GPU – 加速应用”。这是幻灯片。
[slideshare id=63346193&doc=146387dockercon16-160622172714]
Docker 简介
Docker 容器是一种将 Linux 应用程序与其所有库、数据文件和环境变量捆绑在一起的机制,以便在运行的任何 Linux 系统上以及在同一主机上的实例之间,执行环境始终是相同的。 Docker 容器仅为用户模式,因此来自容器的所有内核调用都由主机系统内核处理。 在它的网站上 , Docker 这样描述容器:
Docker 容器将一个软件包在一个完整的文件系统中,该文件系统包含运行所需的一切:代码、运行时、系统工具、系统库——任何可以安装在服务器上的东西。这保证了软件无论其环境如何,都将始终运行相同的程序。
区分容器和基于 hypervisor 的虚拟机( vm )很重要。 vm 允许操作系统的多个副本,甚至多个不同的操作系统共享一台机器。每个虚拟机可以承载和运行多个应用程序。相比之下,容器被设计成虚拟化单个应用程序,并且部署在主机上的所有容器共享一个操作系统内核,如图 2 所示。通常,容器运行速度更快,以裸机性能运行应用程序,并且更易于管理,因为进行操作系统内核调用没有额外的开销。
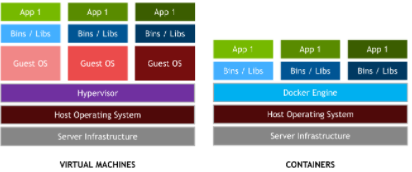
图 2 :虽然 vm 封装了整个操作系统和任何应用程序,但容器封装了单个应用程序及其依赖项,以便进行可移植部署,但在容器之间共享相同的主机操作系统。
Docker 提供了硬件和软件封装,允许多个容器同时在同一个系统上运行,每个容器都有自己的资源集( CPU 、内存等)和它们自己的专用依赖集(库版本、环境变量等)。 Docker 还提供了可移植的 Linux 部署: Docker 容器可以在任何内核为 3 。 10 或更高版本的 Linux 系统上运行。自 2014 年以来,所有主要的 Linux 发行版都支持 Docker 。封装和可移植部署对于创建和测试应用程序的开发人员以及在数据中心运行应用程序的操作人员都很有价值。
Docker 提供了许多更重要的功能。
Docker 强大的命令行工具“ Docker build ”,使用“ Dockerfile ”中提供的描述,从源代码和二进制文件创建 Docker 映像。
Docker 的组件架构允许一个容器映像用作其他容器的基础。
Docker 提供容器的自动版本控制和标签,优化了组装和部署。 Docker 映像由版本化的层组合而成,因此只需要下载服务器上缺少的层。
Docker Hub 是一项服务,它可以方便地公开或私下共享 Docker 图像。
容器可以限制在一个系统上有限的一组资源(例如一个 CPU 内核和 1GB 内存)。
Docker 提供了一个 分层文件系统 ,它可以节省磁盘空间,并构成可扩展容器的基础。
为什么是 Docker ?
Docker 容器与平台无关,但也与硬件无关。当使用特殊的硬件,如 NVIDIA GPUs 时,这就产生了一个问题,这些硬件需要内核模块和用户级库来操作。因此, Docker 本机不支持容器中的 NVIDIA GPUs 。
解决这个问题的早期解决方案之一是在容器中完全安装 NVIDIA 驱动程序,并在启动时映射到与 NVIDIA GPUs (例如 /dev/nvidia0 )对应的字符设备中。此解决方案很脆弱,因为主机驱动程序的版本必须与容器中安装的驱动程序版本完全匹配。这一要求大大降低了这些早期容器的可移植性,破坏了 Docker 更重要的特性之一。
为了使 Docker 映像能够利用 NVIDIA GPUs 实现可移植性,我们开发了 nvidia-docker ,这是一个托管在 Github 上的开源项目,它提供了基于 GPU 的可移植容器所需的两个关键组件:
与驱动程序无关的 CUDA 图像;以及
Docker 命令行包装器,在启动时将驱动程序和 GPUs (字符设备)的用户模式组件装入容器。
nvidia-docker 本质上是围绕 docker 命令的包装器,它透明地为容器提供了在 GPU 上执行代码所需的组件。只有在使用 nvidia-docker run 来执行使用 GPUs 的容器时才是绝对必要的。但为了简单起见,在本文中,我们将其用于所有 Docker 命令。
安装 Docker 和 NVIDIA Docker
在我们开始构建集装箱化的 GPU 应用程序之前,让我们先确保您已经安装了必备软件并能正常工作。您需要:
您系统的最新 NVIDIA drivers 。
码头工人。您可以按照 此处为安装说明 操作。
` NVIDIA -docker `您可以按照 此处为安装说明 操作。
为了帮助安装,我们创建了一个 执行 docker 和 NVIDIA -docker 安装的可靠角色 。 Ansible 是一个自动化机器配置管理和应用程序部署的工具。
要测试您是否准备就绪,请运行以下命令。您应该会看到与所示内容类似的输出。
要测试您是否准备就绪,请运行以下命令。您应该会看到与所示内容类似的输出。
ryan@titanx:~$ nvidia-docker run --rm hello-world Using default tag: latest latest: Pulling from library/hello-world a9d36faac0fe: Pull complete Digest: sha256:e52be8ffeeb1f374f440893189cd32f44cb166650e7ab185fa7735b7dc48d619 Status: Downloaded newer image for hello-world:latest Hello from Docker. This message shows that your installation appears to be working correctly. [... simplified output ...]
现在一切都正常了,让我们开始在容器中构建一个简单的 GPU 应用程序。
构建集装箱化 GPU 应用程序
为了突出 Docker 和我们的插件的特性,我将在容器中从 CUDA 工具箱示例构建 deviceQuery 应用程序。此三步方法可以应用于任何 CUDA 示例,也可以应用于您最喜欢的应用程序,只需稍作修改。
在容器中设置和探索开发环境。
在容器中构建应用程序。
在多个环境中部署容器。
发展环境
相当于安装 CUDA 开发库的 Docker 命令如下:
nvidia-docker pull nvidia/cuda
这个命令从 DockerHub 获取最新版本的nvidia/cuda映像, DockerHub 是一个用于容器映像的云存储服务。可以使用docker run在这个容器中执行命令。下面是在我们刚刚提取的容器中对nvcc --version的调用。
ryan@titanx:~$ nvidia-docker run --rm -ti nvidia/cuda nvcc --version nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2015 NVIDIA Corporation Built on Tue_Aug_11_14:27:32_CDT_2015 Cuda compilation tools, release 7.5, V7.5.17
如果需要 CUDA 6 .5 或 7.0 ,可以指定 图像的标记 。 Ubuntu 和 CentOS 可用的 CUDA 图像列表可以在 NVIDIA -docker 维基 上找到。下面是一个使用 CUDA 7 。 0 的类似示例。
ryan@titanx:~$ nvidia-docker run --rm -ti nvidia/cuda:7.0 nvcc --version Unable to find image 'nvidia/cuda:7.0' locally 7.0: Pulling from nvidia/cuda 6c953ac5d795: Already exists [ … simplified layers -- ubuntu base image … ] 68bad08eb200: Pull complete [ … simplified layers -- cuda 7.0 toolkit … ] Status: Downloaded newer image for nvidia/cuda:7.0 nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2015 NVIDIA Corporation Built on Mon_Feb_16_22:59:02_CST_2015 Cuda compilation tools, release 7.0, V7.0.27
由于系统上本地只有 nvidia/cuda:7.5 映像,所以上面的 docker run 命令将 pull 和 run 操作合并在一起。您会注意到, nvidia/cuda:7.0 图像的拉动比 7 。 5 图像的拉动要快。这是因为两个容器映像共享相同的基础 ubuntu14 。 04 映像,该映像已经存在于主机上。 Docker 缓存并重用图像层,因此只下载 CUDA 7 。 0 工具包所需的新层。这一点很重要: Docker 镜像是逐层构建的,可以与多个镜像共享,节省主机上的磁盘空间(以及部署时间)。 Docker 映像的这种可扩展性是一个强大的特性,我们将在本文后面讨论。(了解更多 Docker 的分层文件系统 )。
最后,您可以通过运行一个执行 bash shell 的容器来探索开发映像。
nvidia-docker run --rm -ti nvidia/cuda:7.5 bash
在这个沙盒环境中尽情玩耍吧。您可以通过 apt 安装软件包或检查 /usr/local/cuda 中的 CUDA 库,但请注意,退出( ctrl + d 或 exit 命令)时,对正在运行的容器所做的任何更改都将丢失。
这种非持久性实际上是 Docker 的一个特性。 Docker 容器的每个实例都从映像定义的相同初始状态开始。在下一节中,我们将研究一种扩展和向图像添加新内容的机制。
构建应用程序
让我们在容器中构建 deviceQuery 应用程序,方法是用应用程序的层扩展 CUDA 映像。一种用于定义层的机制是 Dockerfile 。 Dockerfile 就像一个蓝图,文件中的每一条指令都会给图像添加一个新的层。让我们看看 deviceQuery 应用程序的 Dockerfile 。
# FROM defines the base image FROM nvidia/cuda:7.5 # RUN executes a shell command # You can chain multiple commands together with && # A \ is used to split long lines to help with readability # This particular instruction installs the source files # for deviceQuery by installing the CUDA samples via apt RUN apt-get update && apt-get install -y --no-install-recommends \ cuda-samples-$CUDA_PKG_VERSION && \ rm -rf /var/lib/apt/lists/* # set the working directory WORKDIR /usr/local/cuda/samples/1_Utilities/deviceQuery RUN make # CMD defines the default command to be run in the container # CMD is overridden by supplying a command + arguments to # `docker run`, e.g. `nvcc --version` or `bash` CMD ./deviceQuery
有关可用Dockerfile指令的完整列表,请参阅码头工人。
在只有 Dockerfile 的文件夹中运行以下docker build命令,从 Dockerfile 蓝图构建应用程序的容器映像。
nvidia-docker build -t device-query .
这个命令生成一个名为 device-query 的 docker 容器映像,它继承了 CUDA 7 。 5 开发映像的所有层。
运行集装箱化 CUDA 应用程序
我们现在准备在 GPU 上执行 device-query 容器。默认情况下, nvidia-docker 将主机上的所有 GPUs 映射到容器中。
ryan@titanx:~$ nvidia-docker run --rm -ti device-query ./deviceQuery Starting... CUDA Device Query (Runtime API) version (CUDART static linking) Detected 2 CUDA Capable device(s) Device 0: "GeForce GTX TITAN X" CUDA Driver Version / Runtime Version 8.0 / 7.5 CUDA Capability Major/Minor version number: 5.2 Total amount of global memory: 12287 MBytes (12883345408 bytes) (24) Multiprocessors, (128) CUDA Cores/MP: 3072 CUDA Cores [... simplified output …] Device 1: "GeForce GTX TITAN X" CUDA Driver Version / Runtime Version 8.0 / 7.5 CUDA Capability Major/Minor version number: 5.2 Total amount of global memory: 12288 MBytes (12884705280 bytes) (24) Multiprocessors, (128) CUDA Cores/MP: 3072 CUDA Cores [... simplified output …] > Peer access from GeForce GTX TITAN X (GPU0) -> GeForce GTX TITAN X (GPU1) : Yes > Peer access from GeForce GTX TITAN X (GPU1) -> GeForce GTX TITAN X (GPU0) : Yes deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8.0, CUDA Runtime Version = 7.5, NumDevs = 2, Device0 = GeForce GTX TITAN X, Device1 = GeForce GTX TITAN X Result = PASS
nvidia-docker还通过NV_GPU环境变量提供资源隔离功能。下面的示例在 GPU 1 上运行device-query容器。
ryan@titanx:~$ NV_GPU=1 nvidia-docker run --rm -ti device-query ./deviceQuery Starting... CUDA Device Query (Runtime API) version (CUDART static linking) Detected 1 CUDA Capable device(s) Device 0: "GeForce GTX TITAN X" CUDA Driver Version / Runtime Version 8.0 / 7.5 CUDA Capability Major/Minor version number: 5.2 Total amount of global memory: 12288 MBytes (12884705280 bytes) (24) Multiprocessors, (128) CUDA Cores/MP: 3072 CUDA Cores [... simplified output …] deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8.0, CUDA Runtime Version = 7.5, NumDevs = 1, Device0 = GeForce GTX TITAN X Result = PASS
因为我们只将 GPU 1 映射到容器中, deviceQuery 应用程序只能看到并报告一个 GPU 。资源隔离允许您指定允许您的容器化应用程序使用哪个 GPUs 。为获得最佳性能,请确保在选择 GPUs 的子集时考虑到 PCI 树的拓扑结构。
集装箱 GPU
在我们目前的例子中,我们在一个有两个 GPUs NVIDIA X Titan 的工作站上构建并运行 device-query 。现在,让我们在 DGX-1 服务器上部署该容器。部署容器是将容器映像从构建位置移动到运行位置的过程。部署容器的多种方法之一是 码头枢纽 ,这是一种云服务,用于承载容器映像,类似于 Github 托管 git 存储库的方式。我们用来构建 device-query 的 nvidia/cuda 映像由 Docker Hub 托管。
在将 device-query 推送到 DockerHub 之前,我们需要用 DockerHub 用户名/帐户对其进行标记。
ryan@titanx:~$ nvidia-docker tag device-query ryanolson/device-query
现在将标记的图像推送到 Docker Hub 很简单。
ryan@titanx:~/docker/blog-post$ nvidia-docker push ryanolson/device-query The push refers to a repository [docker.io/ryanolson/device-query] 35f4e4c58e9f: Pushed 170db279f3a6: Pushed 3f6d94182a7e: Mounted from nvidia/cuda [ … simplifed multiple ‘from nvidia/cuda’ layers … ]
对于使用 Docker Hub 或其他容器托管存储库的替代方法,请查看 docker save 和 docker load 命令。
我们推送到 Docker Hub 的 device-query 映像现在可供世界上任何支持 Docker 的服务器使用。为了在我实验室的 DGX-1 上部署 device-query ,我只需拉取并运行映像。这个例子使用了 CUDA 8 。 0 候选版本,现在您可以通过加入 NVIDIA 加速计算开发人员计划 来访问它。
lab@dgx-1-07:~$ nvidia-docker run --rm -ti ryanolson/device-query Using default tag: latest latest: Pulling from ryanolson/device-query 6c953ac5d795: Already exists [ … simplified multiple ‘already exists’ layers … ] 1cc994928295: Pull complete a9e6b6393938: Pull complete Digest: sha256:0b42703a0785cf5243151b8cba7cc181a6c20a3c945a718ce712476541fe4d70 Status: Downloaded newer image for ryanolson/device-query:latest ./deviceQuery Starting... CUDA Device Query (Runtime API) version (CUDART static linking) Detected 8 CUDA Capable device(s) Device 0: "Tesla P100-SXM2-16GB" CUDA Driver Version / Runtime Version 8.0 / 7.5 CUDA Capability Major/Minor version number: 6.0 Total amount of global memory: 16281 MBytes (17071669248 bytes) (56) Multiprocessors, (64) CUDA Cores/MP: 3584 CUDA Cores [... simplified output … ] Device 7: "Tesla P100-SXM2-16GB" CUDA Driver Version / Runtime Version 8.0 / 7.5 CUDA Capability Major/Minor version number: 6.0 Total amount of global memory: 16281 MBytes (17071669248 bytes) (56) Multiprocessors, (64) CUDA Cores/MP: 3584 CUDA Cores [ … simplified output … ] deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8.0, CUDA Runtime Version = 7.5, NumDevs = 8, Device0 = Tesla P100-SXM2-16GB, Device1 = Tesla P100-SXM2-16GB, Device2 = Tesla P100-SXM2-16GB, Device3 = Tesla P100-SXM2-16GB, Device4 = Tesla P100-SXM2-16GB, Device5 = Tesla P100-SXM2-16GB, Device6 = Tesla P100-SXM2-16GB, Device7 = Tesla P100-SXM2-16GB Result = PASS
Docker for Deep Learning 和 HPC
既然您已经了解了构建和运行一个简单的 CUDA 应用程序是多么容易,那么运行更复杂的应用程序(如 DIGITS 或 Caffe )有多困难?如果我告诉你这就像一个命令那么简单呢?
nvidia-docker run --name digits --rm -ti -p 8000:34448 nvidia/digits
这个命令启动 nvidia/digits 容器,并将运行 DIGITS web 服务的容器中的 34448 端口映射到主机上的端口 8000 。
如果您在阅读本文的同一台机器上运行该命令,那么现在尝试打开 http://localhost:8000 。如果在远程计算机上执行 nvidia-docker 命令,则需要访问该计算机上的端口 8000 。如果可以直接访问远程服务器,只需将 localhost 替换为远程服务器的主机名或 IP 地址。
只需一个命令,就可以启动并运行 NVIDIA 的数字平台,并且可以从浏览器访问,如图 3 所示。
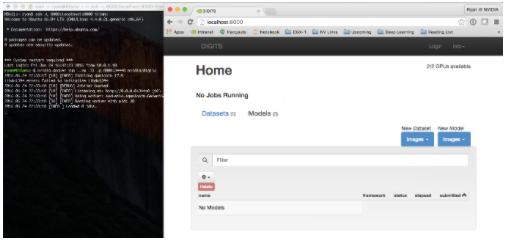
图 3 这个屏幕截图显示了一个本地 web 浏览器连接到远程主机上的容器中运行的数字,使用 ssh 隧道进行转发本地主机: 8000 到运行容器的远程主机上的端口 8000 。(点击查看更大的屏幕截图。)
这就是为什么我们喜欢 NVIDIA 的 Docker 。作为 DIGITS 等开源软件的开发人员,我们希望像您这样的用户能够以最小的努力使用我们最新的软件。
而且我们并不是唯一的一家:谷歌和微软分别使用我们的 CUDA 图片作为 TensorFlow 和 CNTK 的基础图片。 Google 提供 TensorFlow 的预构建 Docker 映像 通过他们的公共容器存储库,而微软 为 CNTK 提供 Dockerfile 则可以自己构建。
让我们看看启动一个更复杂的应用程序有多容易,比如 TensorFlow ,它需要 NumPy 、 Bazel 和无数其他依赖项。是的,只是一条线!您甚至不需要下载和构建 TensorFlow ,您可以直接使用 Docker Hub 上提供的图像。
nvidia-docker run --rm -ti tensorflow/tensorflow:r0.9-devel-gpu
运行此命令后,您可以通过运行其包含的 MNIST 训练脚本来测试 TensorFlow :
nvidia-docker run --rm -ti tensorflow/tensorflow:r0.9-devel-gpu root@ab5f46ba17d2:~# python -m tensorflow.models.image.mnist.convolutional [tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcublas.so locally [tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcudnn.so locally [tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcufft.so locally [tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcuda.so locally [tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcurand.so locally Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes. Successfully downloaded train-labels-idx1-ubyte.gz 28881 bytes. Successfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes. Successfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes. [...]
今天就开始使用 NVIDIA Docker
在这篇文章中,我们通过扩展 nvidia/cuda 映像并在多个不同的平台上部署我们的新容器,介绍了在容器中构建 GPU 应用程序的基本知识。当您将您的 GPU 应用程序容器化时,请使用下面的注释与我们联系,以便我们可以将您的项目添加到 使用 nvidia-docker 的项目列表 。
关于作者
Ryan Olson 是 NVIDIA 全球现场组织的解决方案架构师。他的主要职责包括支持深度学习和高性能计算应用程序。
Jonathan Calmels 是 NVIDIA 的系统软件工程师。他的工作主要集中在 GPU 数据中心软件和用于深度学习的超大规模解决方案。乔纳森拥有计算机科学与工程硕士学位。
Felix Abecasis 是 NVIDIA 的系统软件工程师,致力于使 GPU 应用程序更易于在数据中心部署和管理。 GPU 专注于机器学习支持框架。他拥有法国学校 EPITA 的计算机科学硕士学位。
Phil Rogers 是 NVIDIA 计算服务器产品的首席软件架构师。 Phil 现在主要关注的是 DGX-1 的系统软件,以及 GPU ——加速容器,用于将应用程序传送到该服务器。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5694浏览量
110119 -
gpu
+关注
关注
28文章
5272浏览量
136073
发布评论请先 登录
NVIDIA Omniverse基于Container的部署推流方案

捷智算GPU维修中心服务器电源维修成功率高达90%!

Jtti分析可以选择日本服务器进行国际应用部署吗?
如何在NVIDIA Jetson AGX Thor上通过Docker高效部署vLLM推理服务

香港服务器支持Docker和Kubernetes吗?
Jtti云服务器上怎么部署网站吗
Lambda采用Supermicro NVIDIA Blackwell GPU服务器集群构建人工智能工厂
什么是服务器虚拟化?一文读懂原理、优势与实战部署
华纳云服务器角色服务器失败的原因和解决办法
硅谷GPU云服务器是什么意思?使用指南详解
如何使用Docker部署大模型
云电竞服务器 工作原理




评论