 使用MPI来跨多个GPU缩放应用
使用MPI来跨多个GPU缩放应用
这是 标准并行编程 系列的第三篇文章,讲述在标准语言中使用并行性来加速计算的优点。
用标准语言并行性开发加速代码
多个 GPU 标准 C ++并行编程,第 1 部分
在第 1 部分中,我们解释了:
C ++并行编程的基础
格子玻尔兹曼方法( LBM )
采取了第一步来重构 PalabOS 库,以使用标准 C ++高效地运行 GPU 。
在这篇文章中,我们继续优化 ISOC ++算法的性能,然后使用 MPI 来跨多个 GPU 来缩放应用。
争取最佳性能
期望 CPU 到 GPU 端口的性能低于专用 HPC 代码的性能似乎很自然。毕竟,您受到软件体系结构、已建立的 API 的限制,以及考虑用户群期望的复杂额外功能的需要。不仅如此, C ++标准并行化的简单编程模型允许比专用语言(如 CUDA )更少的手动微调。
在现实中,通常可以将这种性能损失控制和限制到可以忽略不计的程度。关键是分析各个代码部分的性能指标,消除不能反映软件框架实际需求的性能瓶颈。
一个好的做法是为数值算法的核心组件维护一个单独的原理证明代码。这种方法的性能可以更自由地优化,并与完整、复杂的软件框架(如 Palabos 中的 STLBM library )进行比较。此外,像nvprof这样支持 GPU 的探查器可以有效地突出性能瓶颈的根源。
以下建议重点介绍了典型的性能问题及其解决方案:
不要触摸 CPU 上的数据
了解你的算法
建立绩效模型
不要触摸 CPU 上的数据
性能损失的一个常见原因是 CPU 和 GPU 内存之间的隐藏数据传输,这可能非常慢。在 CUDA 统一内存模型中,每当您从 CPU 访问 GPU 数据时,就会发生这种类型的传输。触摸单个字节的数据可能会导致灾难性的性能损失,因为整个内存页都是一次性传输的。
显而易见的解决方案是尽可能只在 GPU 上操作数据。这需要仔细搜索代码中所有对数据的访问,然后将它们包装成并行算法调用。虽然这有点健壮,但即使是最简单的操作也需要这个过程。
显而易见的地方是数据统计的后处理操作或中间评估。另一个经典的性能瓶颈出现在 MPI 通信层,因为您必须记住在 GPU 上执行数据打包和解包操作。
在 GPU 上表达算法说起来容易做起来难,因为for_each和transform_reduce的形式主义主要适用于结构均匀的内存访问。
在不规则数据结构的情况下,使用这两种算法避免竞争条件并保证合并的内存访问是痛苦的。在这种情况下,您应该继续执行下一个建议,熟悉 C ++中提供的并行算法的家族。
了解你的算法
到目前为止,并行 STL 似乎只不过是一种用奇特的函数语法表达parallel for loops的方式。实际上, STL 提供了for_each和transform_reduce之外的大量算法,这些算法对表达数值方法非常有用,包括排序和搜索算法。
exclusive_scan算法计算累积和,值得特别提及,因为它被证明通常对非结构化数据的重新索引操作非常有用。例如,考虑 MPI 通信的打包算法,其中预先由每个网格节点贡献给通信缓冲器的变量的数目是未知的。在这种情况下,需要线程之间的全局通信来确定每个网格节点写入缓冲区的索引。
下面的代码示例显示了如何使用并行算法在 GPU 上以良好的并行效率解决此类问题:
// Step 1: compute the number of variables contributed by every node.
int* numValuesPtr = allocateMemory(numberOfCells);
for_each(execution::par_unseq, numValuesPtr, numValuesPtrl + numberOfCells, [=](int& numValues)
{ int i = &numValues - numValuesPtr; // Compute number of variables contributed by current node. numValues = computeNumValues(i);
} );
// 2. Compute the buffer index for every node.
int* indexPtr = allocateMemory(numberOfCells);
exclusive_scan(execution::par_unseq, numValuesPtr, numValuesPtr + numberOfCells, indexPtr, 0);
// 3. Pack the data into the buffer.
for_each(execution::par_unseq, indexPtr, indexPtr + numberOfCells, [=](int& index)
{ int i = &index - indexPtr; packCellData(i, index);
} );
这个例子让你享受到基于算法的 GPU 编程方法的表达能力:代码不需要同步指令或任何其他低级构造。
建立绩效模型
性能模型通过瓶颈分析为算法的性能建立上限。这通常将峰值处理器性能(以触发器为单位)和峰值内存带宽视为限制硬件特性的主要因素。
正如在上一篇文章的示例:Lattice Boltzmann 软件 Palabos 部分中所讨论的,LBM 代码的计算与内存访问的比率较低,并且在现代 GPU 上完全受内存限制。也就是说,至少如果您使用单精度算术或为双精度算术优化的 GPU。
峰值性能简单地表示为 GPU 的内存带宽与代码中执行的内存访问次数之间的比率。直接的结果是,将 LBM 代码从双精度算术转换为单精度算术将使性能加倍。
图 1 显示了在 NVIDIA A100 ( 40 GB ) GPU 上获得的 Palabos GPU 端口在单精度和双精度浮点上的性能。

图 1 。 3D 盖驱动腔体的 Palabos 性能( 6003网格节点)在 A100 ( 40 GB ) GPU 上以单精度和双精度运行。型号: TRT , D3Q19
执行的测试用例是湍流状态下盖驱动腔中的流动,具有简单的立方几何结构。然而,这种情况包括边界条件,并表现出复杂的流动模式。性能以每秒百万次晶格节点更新( MLUPS ,越多越好)来衡量,并与假设 GPU 内存在峰值容量下被利用的理论峰值进行比较。
该代码在双精度下达到 73% 的峰值性能,在单精度下达到 74% 。这种性能指标在 LB 模型的最新实现中很常见,与所使用的语言或库无关。
尽管一些实现可能会增加几个百分点,并达到接近 80% 的值,但很明显,我们正在接近性能模型隐含的硬限制。从大的角度来看,代码的单 – GPU 性能是最好的。
重用现有的 MPI 后端以获得多 GPU 代码
当 C ++并行算法无缝地集成到现有的软件项目中以加速关键代码部分时,没有什么能阻止您重用项目的通信后端以达到多 GPU 性能。但是,您需要密切关注通信缓冲区,确保它不会绕过 CPU 内存,这将导致代价高昂的页面错误。
我们首次尝试在多个 GPU 上运行带有 GPU 端口的 Palabos 版本,虽然产生了技术上正确的结果,但没有表现出可接受的性能。不是加速,而是从 1 切换到 2 GPU 将速度降低了一个数量级。这个问题可以追溯到通信数据的打包和解包。在最初的后端,这是在 CPU 上执行的,并且是在 CPU 内存中的其他不必要数据访问实例上执行的,例如调整通信缓冲区的大小。
这些问题可以在探查器的帮助下发现。分析器会突出显示统一内存中出现的所有页面错误,并通过将相应的代码部分移动到并行算法来修复。“了解你的算法”部分解释了如果数据遵循不规则模式,如何打包和解包通信缓冲区。
在这一点上,使用标准的 C ++,除了 MPI 以外没有任何扩展,您可以获得一个混合 CPU / GPU 软件项目,具有最先进的性能,在单 G GPU 和多 GPU 上的并行性能。
不幸的是,由于语言规范和相应的 GPU 实现的当前限制,多 GPU 性能仍然低于预期。在未来的 C ++技术标准并行化技术的改进中,我们将基于 C ++标准之外的技术提供一些解决方案。
协调多 CPU 和多 GPU 代码的执行
虽然这篇文章主要关注混合 CPU 和 GPU 编程,但我们无法避免在 CPU 部分讨论混合并行性( MPI 或多线程)问题。
例如, Palabos 的原始版本是非混合的,它使用 MPI 通信层在 CPU 的核心之间以及整个网络中分配工作。移植到 GPU 后,生成的多 CPU 和多 GPU 代码会自动将单个 CPU 内核与每个 MPI 任务中的完整 GPU 进行分组,使 CPU 的动力相对不足。
每当需要或方便将计算密集型任务保留在 CPU 上时,这会导致性能瓶颈。在流体动力学中,在预处理阶段(如几何体处理或网格生成)通常会出现这种情况。
显而易见的解决方案是使用多线程从 MPI 任务中访问多个 CPU 内核。这些线程的共享内存空间可以通过 CUDA 统一内存形式直接与 GPU 共享。
然而, C ++并行算法不能被重用以服务于 GPU 和多核 CPU 执行的两个目的。这是因为 C ++不允许从语言内选择并行算法的目标平台。
虽然 C ++线程确实提供了一种解决这个问题的方法,但我们发现 OpenMP 提供了最方便和最不受干扰的解决方案。在这种情况下,for loop的 OpenMP 注释足以将分配给当前 MPI 任务的网格部分分布到多个线程上。
通过固定内存进行通信
在当前版本的 HPC SDK 中, CUDA 统一内存模型与 MPI 相结合,表现出另一个性能问题。
由于 MPI 通信层希望数据具有固定的硬件地址(所谓的pinned memory),因此托管内存区域中的任何缓冲区都会首先隐式复制到主机 CPU 上的固定内存缓冲区中。由于 GPU 和 CPU 之间的传输,此操作最终可能会非常昂贵。
因此,通信缓冲区应明确固定到 GPU 内存地址。对于nvc++ compiler,这是通过使用cudaMalloc分配通信缓冲区来实现的:
// Allocate the communication buffer
// vector《double》 buffer(N);
// double* buffer = buffer.data();
double* buffer; cudaMalloc((void**)&buffer, N * sizeof(double));
for_each(buffer, buffer + N, … // Proceed with data packing
另一种解决方案是用推力库中的thrust::device_vector替换 STL 向量,默认情况下,推力库使用固定 GPU 内存。
在不久的将来, HPC SDK 将为用户更高效、更自动地处理这些情况。这样他们就不必伸手去拿cudaMalloc或thrust::device_vector。所以,请继续关注!
在本文列出的各种改进之后, Palabos 库在一个带有四个 GPU 的 DGX A100 ( 40-GB )工作站上进行了测试,再次用于盖驱动型腔的基准情况。获得的性能如图 2 所示,并与 48 核 Xeon Gold 6240R CPU 上获得的性能进行了比较:
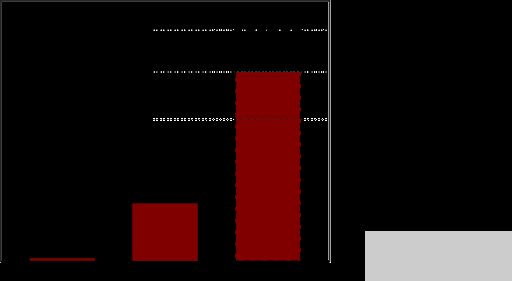
图 2 。 3D 盖驱动腔体的 Palabos 性能( 6003网格节点)在 48 核 Xeon Gold 6240R CPU 和 DGX A100 ( 40 GB )工作站上,一次使用一个 GPU ,一次使用四个 GPU 。型号: TRT , D3Q19 ,单精度
对于 Xeon Gold , Palabos 的原始实现被证明更高效,并用于 48 个 MPI 任务,而单 GPU 和四 GPU 执行使用并行算法后端,并使用nvc++编译。
性能数据显示,与单次执行 GPU 相比, 4- GPU 执行的速度提高了 3.27 倍。这相当于一个非常令人满意的并行效率 82% ,在一个强大的扩展机制,在两个执行相同的总域大小。在弱扩展情况下,使用 4 倍于 4- GPU 执行的问题大小,加速比增加到 3.72 (效率 93% )。
图 2 还显示,当使用未固定的通信缓冲区时,例如当 MPI 通信缓冲区未分配cudaMalloc时,并行效率从 82% 下降到 61% 。
最终,四 GPU DGX 工作站的运行速度比 Xeon Gold CPU 快 55 倍。虽然由于两台机器的范围不同,直接比较可能不公平,但它提供了通过将代码移植到 GPU 获得的加速度感。 DGX 是一个连接到公共电源插头的台式工作站,但它提供的性能在 CPU 群集上只能通过数千个 CPU 内核获得。
结论
您已经看到 C ++标准语言并行性可以用来把像 PalabOS 这样的库移植到 GPU ,代码性能惊人地提高。
对于 Palabos 库的最终用户来说,这种性能提升是通过一行更改来实现的,即从 CPU 后端切换到 GPU 后端。
对于 Palabos 库开发人员来说,开发相应的 GPU 后端需要做一些工作。
然而,这项工作不需要学习新的领域特定语言,也不依赖于 GPU 体系结构的详细知识。
关于作者
Jonas Latt 是瑞士日内瓦大学计算机科学系的副教授。他从事高性能计算和计算流体力学的研究,并在包括地球物理、生物医学和航空航天领域在内的跨学科领域进行应用。他是 lattice Boltzmann 复杂流动模拟开源软件 Palabos 的最初开发者和当前共同维护者。他以前在日内瓦大学获得物理学和计算机科学博士学位,并通过塔夫斯大学(波士顿,美国)和综合理工学校 F.E.EdRaelde 洛桑 EPFL (瑞士)的研究,并作为 CFD 公司 FuluKIT 的联合创始人,对流体力学感兴趣。
Christophe Guy Coreixas 是一名航空工程师, 2014 年毕业于 ISAE-SUPAERO (法国图卢兹)。 2018 年,他在 CERFACS 从事面向行业应用的可压缩晶格玻尔兹曼方法研究时获得了博士学位(流体动力学)。作为日内瓦大学计算机科学系的博士后,克里斯多夫现在开发格子玻尔兹曼模型来模拟航空、多物理和生物医学流程。
Gonzalo Brito 是 NVIDIA 计算性能与 HPC 团队的高级开发技术工程师,工作于硬件和软件的交叉点。他热衷于让加速计算变得更容易实现。在加入NVIDIA 之前,冈萨洛在 RWTH 亚琛大学空气动力学研究所开发了多物理方法,用于颗粒流。
Jeff Larkin 是 NVIDIA HPC 软件团队的首席 HPC 应用程序架构师。他热衷于高性能计算并行编程模型的发展和采用。他曾是 NVIDIA 开发人员技术小组的成员,专门从事高性能计算应用程序的性能分析和优化。 Jeff 还是 OpenACC 技术委员会主席,曾在 OpenACC 和 OpenMP 标准机构工作。在加入NVIDIA 之前,杰夫在位于橡树岭国家实验室的克雷超级计算卓越中心工作。
审核编辑:郭婷
-
cpu
+关注
关注
68文章
10850浏览量
211523 -
NVIDIA
+关注
关注
14文章
4973浏览量
102964 -
gpu
+关注
关注
28文章
4723浏览量
128873
发布评论请先 登录
相关推荐
《CST Studio Suite 2024 GPU加速计算指南》
GPU服务器AI网络架构设计

【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--了解算力芯片GPU
如何选择适合的GPU
GPU加速计算平台是什么

干货分享:宏集物联网HMI通过S7 MPI协议采集西门子400PLC数据
跨网段IP耦合器是什么?跨网段IP耦合器的功能作用
跨阻结构的优点是怎么的来的?
为什么GPU比CPU更快?






 工商网监
工商网监
评论