 如何使用CUDA使warp级编程安全有效
如何使用CUDA使warp级编程安全有效
NVIDIA GPUs 以 SIMT (单指令,多线程)方式执行称为 warps 的线程组。许多 CUDA 程序通过利用 warp 执行来获得高性能。在这个博客中,我们将展示如何使用 CUDA 9 中引入的原语,使您的 warp 级编程安全有效。
扭曲级别基本体
NVIDIA GPUs 和 CUDA 编程模型采用一种称为 SIMT (单指令,多线程)的执行模型。 SIMT 扩展了计算机体系结构的 弗林分类学 ,它根据指令和数据流的数量描述了四类体系结构。作为 Flynn 的四个类之一, SIMD (单指令,多数据)通常用于描述类似 GPUs 的体系结构。但是 SIMD 和 SIMT 之间有一个微妙但重要的区别。在 SIMD 体系结构中,同一个指令中有多个并行操作。 SIMD 通常使用带有向量寄存器和执行单元的处理器来实现;标量线程发出以 SIMD 方式执行的向量指令。在 SIMT 体系结构中,多线程向任意数据发出通用指令,而不是单线程发出应用于数据向量的向量指令。
SIMT 对于可编程性的好处使得 NVIDIA 的 GPU 架构师为这种架构命名,而不是将其描述为 SIMD 。 NVIDIA GPUs 使用 SIMT 执行 32 个并行线程的 warp ,这使得每个线程能够访问自己的寄存器,从不同的地址加载和存储,并遵循不同的控制流路径。 CUDA 编译器和 GPU 一起工作,以确保 warp 的线程尽可能频繁地一起执行相同的指令序列,从而最大限度地提高性能。
虽然通过 warp 执行获得的高性能发生在场景后面,但是许多 CUDA 程序可以通过显式 warp 级编程获得更高的性能。并行程序通常使用集体通信操作,例如并行缩减和扫描。 CUDA C ++通过提供扭曲级基元和合作群集合来支持这样的集合运算。合作组 collectives ( 在上一篇文章中描述过 )是在本文关注的 warp 原语之上实现的。
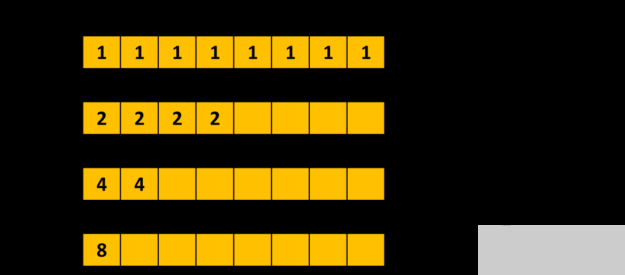
使用 shfl _ down _ sync ()进行扭曲级别并行减少的一部分。
清单 1 显示了一个使用 warp 级别原语的示例。它使用 __shfl_down_sync() 执行树缩减来计算扭曲中每个线程持有的 val 变量的总和。在第一个环的末尾, val 包含第一个线程的和。
__match_all_sync
活动掩码查询:返回一个 32 位掩码,指示扭曲中的哪些线程与当前正在执行的线程处于活动状态。
__activemask
线程同步:同步扭曲中的线程并提供内存边界。
__syncwarp
请看
同步数据交换
每个“同步数据交换”原语在一个 warp 中的一组线程之间执行一个集体操作。例如,清单 2 显示了其中的三个。调用 __shfl_sync() 或 __shfl_down_sync() 的每个线程都从同一个 warp 中的线程接收数据,而调用 __ballot_sync() 的每个线程都会接收一个位掩码,该掩码表示 warp 中为谓词参数传递真值的所有线程。
int __shfl_sync(unsigned mask, int val, int src_line, int width=warpSize);
int __shfl_down_sync(unsigned mask, int var, unsigned detla,
int width=warpSize);
int __ballot_sync(unsigned mask, int predicate);
参与调用每个原语的线程集是使用 32 位掩码指定的,这是这些原语的第一个参数。所有参与线程必须同步,集体操作才能正常工作。因此,如果线程尚未同步,这些原语将首先同步线程。
一个常见的问题是“对于mask参数,我应该使用什么?”. 可以将遮罩视为扭曲中应参与集体操作的线程集。这组线程由程序逻辑决定,通常可以通过程序流中早期的某些分支条件来计算。以清单 1 中的缩减代码为例。假设我们要计算一个数组input[],的所有元素的总和,该数组的大小NUM_ELEMENTS小于线程块中的线程数。我们可以使用清单 3 中的方法。
unsigned mask = __ballot_sync(FULL_MASK, threadIdx.x < NUM_ELEMENTS); if (threadIdx.x < NUM_ELEMENTS) { val = input[threadIdx.x]; for (int offset = 16; offset > 0; offset /= 2) val += __shfl_down_sync(mask, val, offset); … }
代码使用条件thread.idx.x < NUM_ELEMENTS来确定线程是否将参与缩减。__ballot_sync()用于计算__shfl_down_sync()操作的成员掩码。__ballot_sync()本身使用FULL_MASK(0xffffffff表示 32 个线程),因为我们假设所有线程都将执行它。
在 Volta 和更高版本的 GPU 架构中,数据交换原语可以用于线程发散的分支:在这种分支中, warp 中的一些线程采用不同于其他线程的路径。清单 4 显示了一个示例,其中一个 warp 中的所有线程都从第 0 行的线程获得val的值。偶数和奇数编号的线程采用if语句的不同分支。
if (threadIdx.x % 2) {
val += __shfl_sync(FULL_MASK, val, 0);
…
}
else {
val += __shfl_sync(FULL_MASK, val, 0);
…
}
在最新(和将来 )的 Volta 的 GPU 上,您可以运行使用 warp 同步原语的库函数,而不必担心函数是否在线程发散分支中被调用。
活动掩码查询
__activemask() 返回调用扭曲中所有当前活动线程的 32 位 unsigned int 掩码。换句话说,它显示了在其 warp 中的线程也在执行相同的 __activemask() 的调用线程。这对于我们稍后解释的:机会扭曲级编程”技术以及调试和理解程序行为非常有用。
但是,正确使用 __activemask() 很重要。清单 5 说明了一个不正确的用法。代码尝试执行与清单 4 中所示相同的总和缩减,但是它在分支内部使用了 __activemask() ,而不是在分支之前使用 __ballot_sync() 来计算掩码。这是不正确的,因为这将导致部分和而不是总和。 CUDA 执行模型并不能保证将分支连接在一起的所有线程将一起执行 __activemask() 。正如我们将要解释的那样,不能保证隐式锁步骤的执行。
// // Incorrect use of __activemask() // if (threadIdx.x < NUM_ELEMENTS) { unsigned mask = __activemask(); val = input[threadIdx.x]; for (int offset = 16; offset > 0; offset /= 2) val += __shfl_down_sync(mask, val, offset); … }
翘曲同步
当 warp 中的线程需要执行比数据交换原语提供的更复杂的通信或集体操作时,可以使用 __syncwarp() 原语来同步 warp 中的线程。它类似于 __syncthreads() 原语(同步线程块中的所有线程),但粒度更细。
void __syncwarp(unsigned mask=FULL_MASK);
__syncwarp()原语使执行线程等待,直到mask中指定的所有线程都执行了__syncwarp()(使用相同的mask),然后再继续执行。它还提供了一个记忆栅栏,允许线程在调用原语之前和之后通过内存进行通信。
清单 6 显示了一个在 warp 中的线程之间混乱矩阵元素所有权的示例。
float val = get_value(…); __shared__ float smem[4][8]; // 0 1 2 3 4 5 6 7 // 8 9 10 11 12 13 14 15 // 16 17 18 19 20 21 22 23 // 24 25 26 27 28 29 30 31 int x1 = threadIdx.x % 8; int y1 = threadIdx.x / 8; // 0 4 8 12 16 20 24 28 // 1 5 10 13 17 21 25 29 // 2 6 11 14 18 22 26 30 // 3 7 12 15 19 23 27 31 int x2= threadIdx.x / 4; int y2 = threadIdx.x % 4; smem[y1][x1] = val; __syncwarp(); val = smem[y2][x2]; use(val);
假设使用了一维线程块(即 threadIdx . y 始终为 0 )。在代码的开头,一个 warp 中的每个线程都拥有一个 4 × 8 矩阵的元素,该矩阵具有行主索引。换句话说,第 0 车道拥有[0][0]车道,第 1 车道拥有[0][1]。每个线程将其值存储到共享内存中 4 × 8 数组的相应位置。然后使用__syncwarp()来确保在每个线程从数组中的一个转置位置读取数据之前,所有线程都完成了存储。最后, warp 中的每一个线程都拥有一个矩阵元素,列主索引为: lane0 拥有[0][0], lane1 拥有[1][0]。
确保__syncwarp()将共享内存读写分开,以避免争用情况。清单 7 演示了共享内存中树和缩减的错误用法。在每两个__syncwarp()调用之间有一个共享内存读取,然后是共享内存写入。 CUDA 编程模型不能保证所有的读操作都会在所有的写操作之前执行,因此存在竞争条件。
unsigned tid = threadIdx.x; // Incorrect use of __syncwarp() shmem[tid] += shmem[tid+16]; __syncwarp(); shmem[tid] += shmem[tid+8]; __syncwarp(); shmem[tid] += shmem[tid+4]; __syncwarp(); shmem[tid] += shmem[tid+2]; __syncwarp(); shmem[tid] += shmem[tid+1]; __syncwarp();
清单 8 通过插入额外的__syncwarp()调用修复了竞争条件。 CUDA 编译器可以在最终生成的代码中省略一些同步指令,这取决于目标体系结构(例如,在预伏打体系结构上)。
unsigned tid = threadIdx.x; int v = 0; v += shmem[tid+16]; __syncwarp(); shmem[tid] = v; __syncwarp(); v += shmem[tid+8]; __syncwarp(); shmem[tid] = v; __syncwarp(); v += shmem[tid+4]; __syncwarp(); shmem[tid] = v; __syncwarp(); v += shmem[tid+2]; __syncwarp(); shmem[tid] = v; __syncwarp(); v += shmem[tid+1]; __syncwarp(); shmem[tid] = v;
在最新的 Volta (和 future ) GPUs 上,也可以在线程发散分支中使用 __syncwarp() 来同步两个分支的线程,但是一旦它们从原语返回,线程就会再次发散。请参见清单 13 中的示例。
机会主义翘曲水平编程
正如我们在同步数据交换一节中所示,在同步数据交换原语中使用的成员关系 mask 通常是在程序流中的分支条件之前计算的。在许多情况下,程序需要沿着程序流传递掩码;例如,在函数内部使用扭曲级原语时,作为函数参数。如果要在库函数内使用 warp 级编程,但不能更改函数接口,则这可能很困难。
有些计算可以使用碰巧一起执行的任何线程。我们可以使用一种称为机会主义翘曲级别编程的技术,如下例所示。
// increment the value at ptr by 1 and return the old value
__device__ int atomicAggInc(int *ptr) {
int mask = __match_any_sync(__activemask(), (unsigned long long)ptr);
int leader = __ffs(mask) – 1; // select a leader
int res;
if(lane_id() == leader) // leader does the update
res = atomicAdd(ptr, __popc(mask));
res = __shfl_sync(mask, res, leader); // get leader’s old value
return res + __popc(mask & ((1 << lane_id()) – 1)); //compute old value
}
atomicAggInc() 以原子方式将 ptr 指向的值递增 1 并返回旧值。它使用 atomicAdd() 函数,这可能会引发争用。为了减少争用, atomicAggInc 用 per-warp atomicAdd() 替换了 per-thread atomicAdd() 操作。第 4 行中的 __activemask() 在 warp 中查找将要执行原子操作的线程集。[zx7]的传入线程具有相同的值,这些线程的[zx7]与[ez3]的值相同。每个组选择一个引导线程(第 5 行),该线程为整个组执行 atomicAdd() (第 8 行)。每个线程从 atomicAdd() 返回的前导(第 9 行)获取旧值。第 10 行计算并返回当前线程调用函数而不是 atomicAggInc 时从 atomicInc() 获得的旧值。
隐式 Warp 同步编程是不安全的
CUDA 版本 9 。 0 之前的工具箱提供了一个(现在是遗留的) warp 级别基本体版本。与 CUDA 9 原语相比,传统原语不接受 mask 参数。例如, int __any(int predicate) 是 int __any_sync(unsigned mask, int predicate) 的旧版本。
如前所述, mask 参数指定扭曲中必须参与原语的线程集。如果掩码指定的线程在执行过程中尚未同步,则新基元将执行扭曲线程级内同步。
传统的 warp 级别原语不允许程序员指定所需的线程,也不执行同步。因此,必须参与翘曲级别操作的线程不是由 CUDA 程序显式表示的。这样一个程序的正确性取决于隐式 warp 同步行为,这种行为可能从一个硬件体系结构改变到另一个,从一个 CUDA 工具包版本到另一个(例如,由于编译器优化的变化),甚至从一个运行时执行到另一个。这种隐式 warp 同步编程是不安全的,可能无法正常工作。
例如,在下面的代码中,假设 warp 中的所有 32 个线程一起执行第 2 行。第 4 行的 if 语句导致线程发散,奇数线程在第 5 行调用 foo() ,偶数线程在第 8 行调用 bar() 。
// Assuming all 32 threads in a warp execute line 1 together. assert(__ballot(1) == FULL_MASK); int result; if (thread_id % 2) { result = foo(); } else { result = bar(); } unsigned ballot_result = __ballot(result);
CUDA 编译器和硬件将尝试在第 10 行重新聚合线程,以获得更好的性能。但这一重新收敛是不保证的。因此,ballot_result可能不包含来自所有 32 个线程的投票结果。
在__ballot()之前的第 10 行调用新的__syncwarp()原语,如清单 11 所示,也不能解决这个问题。这又是隐式翘曲同步编程。它假设同一个扭曲中的线程一旦同步,将保持同步,直到下一个线程发散分支为止。尽管这通常是真的,但在 CUDA 编程模型中并不能保证它。
__syncwarp(); unsigned ballot_result = __ballot(result);
正确的修复方法是使用清单 12 中的__ballot_sync()。
unsigned ballot_result = __ballot_sync(FULL_MASK, result);
一个常见的错误是假设在旧的 warp 级别原语之前和/或之后调用__syncwarp()在功能上等同于调用原语的sync版本。例如,__syncwarp(); v = __shfl(0); __syncwarp();与__shfl_sync(FULL_MASK, 0)相同吗?答案是否定的,有两个原因。首先,如果在线程发散分支中使用序列,那么__shfl(0)不会由所有线程一起执行。清单 13 显示了一个示例。第 3 行和第 7 行的__syncwarp()将确保在执行第 4 行或第 8 行之前, warp 中的所有线程都会调用foo()。一旦线程离开__syncwarp(),奇数线程和偶数线程将再次发散。因此,第 4 行的__shfl(0)将得到一个未定义的值,因为当第 4 行执行时,第 0 行将不活动。__shfl_sync(FULL_MASK, 0)可以在线程发散的分支中使用,没有这个问题。
v = foo();
if (threadIdx.x % 2) {
__syncwarp();
v = __shfl(0); // L3 will get undefined result because lane 0
__syncwarp(); // is not active when L3 is executed. L3 and L6
} else { // will execute divergently.
__syncwarp();
v = __shfl(0);
__syncwarp();
}
第二,即使所有线程一起调用序列, CUDA 执行模型也不能保证线程在离开__syncwarp()后保持收敛,如清单 14 所示。不能保证隐式锁步骤的执行。请记住,线程收敛只在显式同步的扭曲级别原语中得到保证。
assert(__activemask() == FULL_MASK); // assume this is true __syncwarp(); assert(__activemask() == FULL_MASK); // this may fail
因为使用它们可能会导致不安全的程序,所以从 CUDA 9 。 0 开始就不推荐使用旧的 warp 级别原语。
更新旧版曲速级编程
如果您的程序使用旧的 warp 级原语或任何形式的隐式 warp 同步编程(例如在没有同步的 warp 线程之间通信),您应该更新代码以使用原语的 sync 版本。您可能还需要重新构造代码以使用 Cooperative Groups ,这提供了更高级别的抽象以及诸如多块同步等新功能。
使用翘曲级别原语最棘手的部分是找出要使用的成员掩码。我们希望以上几节能给你一个好主意,从哪里开始,注意什么。以下是建议列表:
不要只使用 FULL_MASK (即对于 32 个线程使用 0xffffffff )作为 mask 值。如果不是所有的线程都能根据程序逻辑到达原语,那么使用 FULL_MASK 可能会导致程序挂起。
不要只使用 __activemask() 作为掩码值。 __activemask() 告诉您调用函数时哪些线程会收敛,这可能与您希望在集合操作中的情况不同。
分析程序逻辑并理解成员资格要求。根据程序逻辑提前计算掩码。
如果您的程序执行机会主义 warp 同步编程,请使用“ detective ”函数,如 __activemask() 和 __match_all_sync() 来找到正确的掩码。
使用 __syncwarp() 来分离与内部扭曲相关的操作。不要假设执行锁步。
最后一个诀窍。如果您现有的 CUDA 程序在 Volta architecture GPUs 上给出了不同的结果,并且您怀疑差异是由 Volta 新的独立线程调度 引起的,它可能会改变翘曲同步行为,您可能需要使用 nvcc 选项 -arch=compute_60 -code=sm_70 重新编译程序。这样的编译程序选择使用 Pascal 的线程调度。当有选择地使用时,它可以帮助更快地确定罪魁祸首模块,允许您更新代码以避免隐式 warp 同步编程。
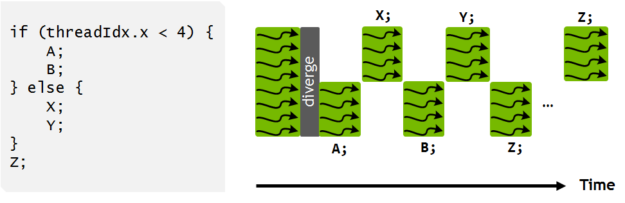
Volta 独立的线程调度允许交叉执行来自不同分支的语句。这使得执行细粒度并行算法成为可能,其中 warp 中的线程可以同步和通信。
关于作者
Yuan Lin 是 NVIDIA 编译团队的首席工程师。他对所有使程序更高效、编程更高效的技术感兴趣。在加入 NVIDIA 之前,他是 Sun Microsystems 的一名高级职员工程师。
Vinod Grover 是 CUDA C ++编译器团队 NVIDIA 的主管。在此之前,他曾在微软和太阳微系统公司担任各种研究、工程和管理职务。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
4981浏览量
102997 -
gpu
+关注
关注
28文章
4729浏览量
128898 -
CUDA
+关注
关注
0文章
121浏览量
13620
发布评论请先 登录
相关推荐
加密算法的选择对于加密安全有多重要?
晶圆的TTV,BOW,WARP,TIR是什么?
如何安全有效的删代码?
室内外一体化人行导航技术如何安全有效的使用
怎么在TMDSEVM6678: 6678自带的FFT接口和CUDA提供CUFFT函数库选择?

车厂如何安全有效做自动驾驶路测?

打破英伟达CUDA壁垒?AMD显卡现在也能无缝适配CUDA了
英国公司实现英伟达CUDA软件在AMD GPU上的无缝运行
软件生态上超越CUDA,究竟有多难?
Keil使用AC6编译提示CUDA版本过高怎么解决?
深入浅出理解PagedAttention CUDA实现

基于cutlass GTC2020的slides

什么是CUDA?谁能打破CUDA的护城河?






 工商网监
工商网监
评论