 xenomai组成结构和源码
xenomai组成结构和源码
目录
xenomai初探一、xenomai 3组成结构1.1 xenomai 31.2 xenomai3 结构二、 xenomai 3源码介绍1.1 编译构建相关文件与目录1.2 官方应用示例1.3 测试工具1.4 应用库和内核源码1.5 系统工具三、xenomai实时性测试1.1 latency和jitter1.2 串口实时性测试1.3 GPIO实时性测试四、xenomai各种接口应用编译1.1 编译参数获取1.2 链接参数获取五、xenomai proc文件信息介绍1.1 实时外设中断信息ipipedovetail1.2 查看实时核信息xenomai调度cpu硬件timer与延迟信息faultsheapregistry1.3 调度与任务状态线程状态系统统计信息参考链接
xenomai初探
前两篇文章介绍了实时linux几种方案,并完成xenomai系统构建安装,下面我们更进一步认识一下xenomai,本文先介绍xenomai组成结构和源码,然后在ti am335x平台上,通过硬件外设来测试xenomai系统的实时性,最后介绍xenomai运行时proc文件系统内容,方便查看系统和实时任务运行状态信息。
一、xenomai 3组成结构
xenomai历史概况:

xenomai3于2015年正式发布,由于嵌入式设备、工业设备操作系统更新迭代比较慢,可能还有很多设备运行xenomai2操作系统,xenomai2已经过时,在此不再介绍。xenomai3由xenomai2演变而来,其原理相通,所以明白xenomai3再去看xenomai2也能很快上手。
1.1 xenomai 3
xenomai3于2015年正式发布,从xenomai3开始支持两种方式构建linux实时系统,分别是cobalt 和 mercury。
-
cobalt:添加一个实时内核核,双核结构。具有实时内核cobalt、实时驱动模型RTDM、实时应用POSIX接口库
libcobalt,然后再基于libcobalt实现的其他API skins,如Alchemy API、VxWorks emulator、pSOS emulator等(具体查看应用编程接口文档https://xenomai.org/documentation/xenomai-3/html/xeno3prm),即VxWorks、pSOS应用程序可稍微修改源码就可以在xenomai上编译运行。需要说明的是Alchemy API是xenomai除posix外的官方编程接口,提供了更接近于传统RTOS编程方式的编程接口,对于不熟悉linux应用开发的MCU开发人员也能很快上手。在xenomai2上Alchemy API是xenomai的原生编程接口,性能最好,posix API是在Alchemy API上实现的skin。在xenomai3相反,Alchemy API、VxWorks、pSOS均基于posix接口实现,也正因为这样诞生了mercury方式。
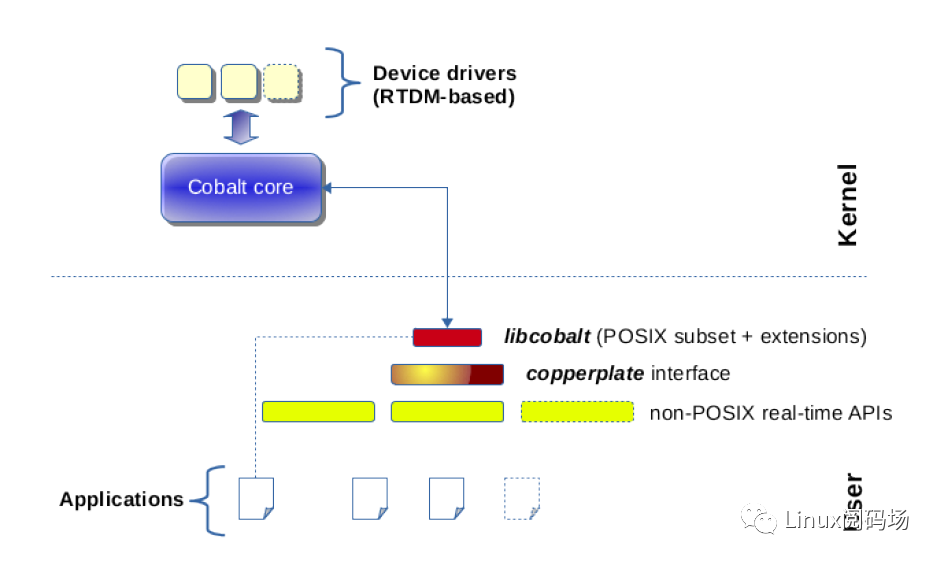
-
mercury:基于直接修改linux内核源代码的PREEMPT RT,应用空间在glibc之上,添加xenomai API库,如下图所示。可以在不支持cobalt内核时,可使用该方法运行xenomai应用;也就是说你还可以通过mercury方式在PREEMPT RT上编译运行VxWorks、pSOS等接口的应用程序。当然,也可不需要PREEMPT RT,直接使用linux,只是实时性就……
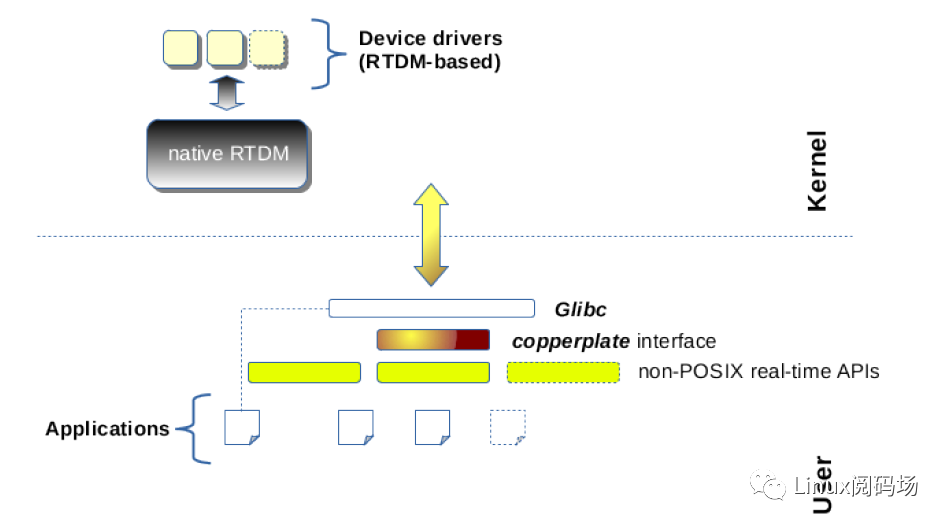
可以看出,xenomai社区开发者为保护用户煞费苦心,既方便基于VxWorks、pSOS等系统写的代码应用迁移到xenomai,也方便xenomai接口编写的程序迁移到PREEMPT RT运行。
1.2 xenomai3 结构
mercury只是在glibc上加了一层皮,不是接下来研究的对象。我们看cobalt ,从底层硬件驱动、内核空间到用户空间,保证了实时任务的实时性。其整体结构如图所示。
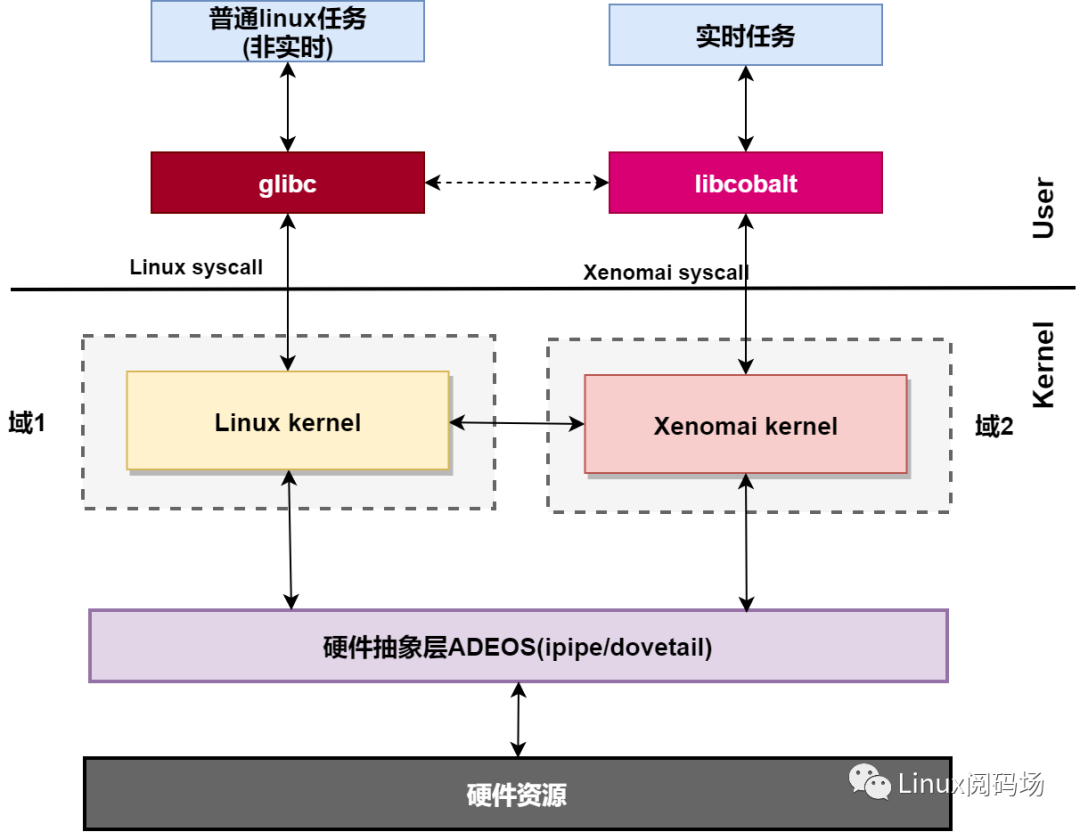
在内核空间,在标准linux基础上添加一个实时内核Cobalt,得益于基于ADEOS(Adaptive Domain Environment for Operating System),使Cobalt在内核空间与linux内核并存,并把标准的Linux内核作为实时内核中的一个idle进程在实时内核上调度。
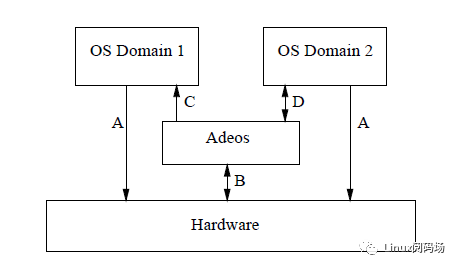
2000年,Karim发表了一篇名为《操作系统的自适应域环境》的论文(即Adeos,Adaptive Domain Environment of Operating System),该论文描述了一种简单而智能的方案,用于在同一系统上运行的多个内核之间共享公共硬件资源。他通过“pipeline”抽象来说明在x86硬件上共享中断的基本机制,根据整个系统给定的优先级,依次向每个内核传入中断。他倡导一种对硬件中断进行优先级排序的新方法,以便可以开发基于Linux内核的实时扩展,而无需使用当时已被某些专有RTOS供应商申请授予专利方法(这里的RTOS供应商和专利指的就是WindRiver和RTlinux使用的RTHAL技术)。
ADEOS (Adaptive Domain Environment for Operating System),提供了一个灵活的环境,可以在多个操作系统之间或单个OS的多个实例之间共享硬件资源,从而使多个优先级域可以同时存在于同一硬件上。早期在xenomai 2上使用。
2005年6月17日,Philippe Gerum发布用于Linux内核的I-pipe,I-pipe基于ADEOS,但是I-pipe更精简,并且只处理中断,xenomai3使用I-pipe。
ADEOS ,其核心思想是Domain,也就是范围的意思,linux内核有linux内核的范围,cobalt内核有cobalt内核的范围。
-
两个内核管理各自范围内的应用、驱动、中断;
-
两个domain之间有优先级之分,cobalt内核优先级高于linux内核;
-
I-pipe优先处理高优先级域的中断,来保证高优先级域的实时性。
-
高优先级域可以通过I-pipe向低优先级域发送各类事件等。
在用户空间,添加针对实时应用优化的库--libcobalt,libcobalt提供POSIX接口给应用空间实时任务使用,应用通过libcobalt让实时内核cobalt提供服务。
驱动方面,xenomai提供实时驱动框架模型RTDM(Real-Time Driver Model),专门用于Cobalt内核,基于RTDM进行实时设备驱动开发,为实时应用提供实时驱动。RTDM将驱动分为2类:
•字符设备(open/close, read, write, ioctl),如UART,UDD,SPI……
•协议设备(socket, bind, send, recv, etc),如UDP/TCP,CAN,IPC,……
中断方面,I-Pipe(interrupt Pipeline)分发Linux和Xenomai之间的中断,并以Domain优先级顺序传递中断。I-Pipe传递中断如下图所示,对于实时内核注册的中断,中断产生后能够直接得到处理,保证实时性。对于linux的中断,先将中断记录在i-log,等实时任务让出CPU后,linux得到运行,该中断才得到处理。

实时内核cobalt与非实时内核linux相结合,既能提供工业级RTOS的硬实时性能,又能利用linux操作系统非常出色的生态、网络和图形界面服务,在产品的开发周期和成本控制方面都有巨大优势 。
二、 xenomai 3源码介绍
xenomai源码目录如下:
-
$ tree -L 1 -
. -
├── aclocal.m4 -
├── autom4te.cache -
├── configure -
├── configure.ac -
├── CONTRIBUTING.md -
├── debian -
├── demo -
├── doc -
├── include -
├── kernel -
├── lib -
├── README -
├── scripts -
├── testsuite -
├── tracing -
└── utils
1.1 编译构建相关文件与目录
debian目录将xenomai 应用库构建为debian软件包的包信息和脚本。
scripts目录和aclocal.m4、configure、configure.ac、Makefile.am xenomai库编译相关文件,在安装xenomai的文章中已使用,详见官方文档:https://source.denx.de/Xenomai/xenomai/-/wikis/InstallingXenomai3#library-install。
1.2 官方应用示例
demo目录中分别提供了 posix和 alchemy接口的应用示例:
-
posix接口应用示例:
-
cyclictest与linuxcyclictest基本一致的xenomai posix接口应用。xenomia与Preempt-RT实时性对比时,使用相同参数通过该工具进行测试对比。 -
bufp-label、bufp-readwrite、iddp-label、iddp-sendrecv:xenomai实时任务间通过本地socket 进行块数据、流数据通信示例。 -
xddp-label、xddp-echo、xddp-stream:xenomai实时应用与普通linux任务通信示例,其底层实现本博客有详细的文章分析介绍。 -
alchemy接口应用示例:
-
altency是实时性测试工具latencyalchemy API实现版本,可对比POSIX与alchemy API接口的实时性能差异。 -
cross-link: alchemy接口实现的串口实时性测试工具,将本地的两个UART 外设RX-TX交差相连,应用通过向一路UART发送本地时间数据,另一路UART接时间数据来测试串口收发数据的抖动情况,后文会对该测试详细介绍。
1.3 测试工具
其中目录 testsuite内是xenomai测试工具和 smokey单元测试用例,详细如下:
-
clocktest:cobalt内核与linux核之间时钟漂移测试工具。由于xenomai内核与linux共存,两个内核各自有时间子系统对时间进行度量,两个系统对时间的度量可能存在不一致的情况(漂移),该工具用于测试该漂移,后面会专门有一篇文章介绍。 -
latency:实时性测试工具,通过它结合stress等压力工具,能测试xenomai在各种工况下的实时性能,该工具类似于linux下的实时性能测试工具cyclitest,下一节内容通过该工具进行实时性能测试; -
spitest:SPI通讯延迟测试; -
switchtest:上下文切换测试。创建各种类型的线程,并尝试在这些线程之间切换上下文,打印每秒切换上下文的计数。 -
xeno-test:运行Xenomai的基本测试/基准测试,先运行一些单元测试,然后在“load-command”生成的负载下运行latency测试; -
gpiobench:通过gpio测试实时性,两种方式: -
两个gpio硬件相连,从一个 gpio 输出引脚发送高电平脉冲,并从另一个 gpio 引脚接收中断,测量两个事件之间的时间,后文会对该测试详细介绍。
-
一个gpio 引脚接收中断后,从另一个gpio 输出确认信号,测量两个信号之间的延迟(可通过外部示波器等设备测量两个事件之间经过的时间)。
1.4 应用库和内核源码
kernel和 lib分别存放了实时内核和应用库的源代码。
-
cobalt
-
kernel -
├── cobalt -
└── drivers -
于 kernel部分源码结构与linux内核结构一致,其中 cobalt就是xenomai的实时内核cobalt源码,包含了调度、rtdm实时驱动框架等。
-
drivers
一般嵌入式应用中,需要操作外设,或从外设获取数据,需要为操作系统编写硬件设备驱动。同样,xenomai需要要实时驱动配合才能发挥xenomai的实时性能。drivers中是官方提供的一些实时驱动和实时TCP/IP协议栈(rtnet)源码,其中包含了上面说到个一些测试工具的内核部分。
-
. -
├── analogy #实时模拟数据处框架 -
├── autotune #延迟校准驱动,应用autotune使用 -
├── can #实时can协议栈、部分CAN控制器实时驱动 -
├── gpio #实时gpio驱动 -
├── gpiopwm #gpiopwm 驱动框架 -
├── ipc #实时应用间本地socket通讯机制 -
├── Kconfig -
├── Makefile -
├── net #实时以太网协议栈、部分实时网卡驱动 -
├── serial #实时串口驱动框架、部分实时串口驱动 -
├── spi #实时SPI驱动框架、部分master驱动 -
├── testing #用户态测试程序需要的内核态部分 -
└── udd #用户态实时IO驱动框架
我们可以看到xenomai官方驱动源码里支持的外设比较少,对于X86平台,得益于X86平台的兼容性,xenomai支持比较好,X86平台应用场合一般很少用到如SPI等低速设备,大部分用到的网卡驱动均具备。
但对于ARM,由于ARM IP核授权方式,各个芯片厂商不同芯片外设各式各样,如果需要使用xenomai,这就需要开发者投入资源,按照RTDM来开发使用到实时外设驱动。大家都习惯了linux主线或芯片厂商提供Linux SDK开箱即用的方便快速,这就劝退了大部分人。
主要原因是 RTOS应用于特定领域,芯片厂商未对其做支持,xenomai社区开发人员太少(意味着机会)无法代替芯片厂商支持这么多平台。另外xenomai开发有一定门槛,导致没有更多的开发者参与贡献,这就造成了恶性循环。
据了解,随着国产化替代推进,目前国内部分芯片厂商为了让自家的芯片能应用到这些特殊领域,开始关注和适配xenomai,比如龙芯。部分国产操作系统厂商也开始研究和引用xenomai技术,比如openEuler+xenomai的二进制镜像发布等。
1.5 系统工具
针对实时内核,xenomai提供了多种系统工具,其源码位于 utils目录下,默认编译安装到 /usr/xenomai/sbin/目录,其中:
-
autotune是xenomai延迟调整工具,可调整中断延迟、内核调度延迟、用户调度延迟,内核中称为gravity,为什么需要调整延迟?如下图,一个实时任务定时10us,但操作硬件timer、中断响应、其他内核代码的执行等都需要时间,为了让用户态任务准时唤醒,设置硬件timer下一个中断唤醒时间时,需要将这些时间减去,才是应用程序真正的唤醒时间,这也是后文中latency测试时存在负值的原因,autotune就是用来调整这些时间的。

-
corectl为实时内核控制工具,通过该工具可控制实时内核的启动和停止。 -
rtps名字可以看出等同于linux的ps,用于查看实时任务的状态, 其输出结果是通过解析/proc/xenomai/sched/下的文件得到。 -
xenomai提供了实时TCP/IP 协议栈,其中一些工具如下:
-
rtcfg、rtnet:rtnet 配置工具 -
rtifconfig、rtping、rtroute、与linuxifocnfig、ping、route等等效.
三、xenomai实时性测试
硬件环境:TI AM335x Cortex-A8 600MHZ DDR2 128MB spiNorflash 16MB
软件环境:5.4.106 + xenomai 3.1
压力条件:stress-c10--vm4--vm-bytes16M
以下数据基于该环境测试得出。
1.1 latency和jitter
事件预期发生与实际发生的时间之间的时间称为延迟(latency),实际发生的最大时间与最小时间之间的差值称为抖动(Jitter),两者均可表示实时性。根据实时性的定义,延迟必须是确定的,不能超过deadline,否则将会产生严重的后果。
在否决定使用一个实时系统时,需要结合具体应用场景来评估该实时系统是否符合,若不符合则需要考虑对现有系统优化优化或者更换方案。
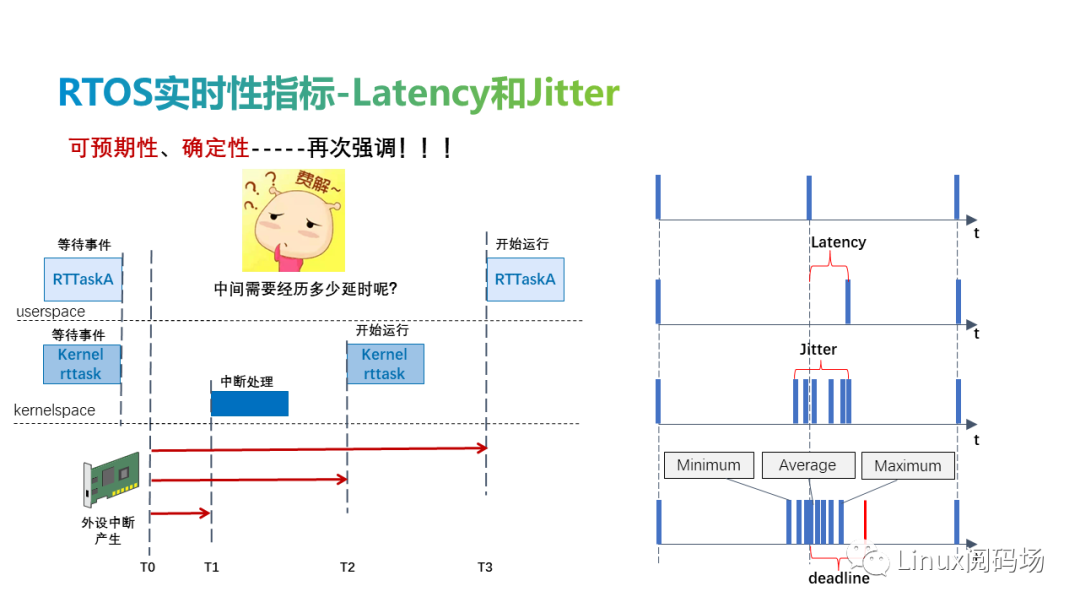
-
中断延迟——中断触发和中断服务开始处理之间的时间。
-
唤醒延迟——从最高优先级任务被唤醒到它实际开始运行的时间。这也可以称为调度延迟。
-
优先级反转——高优先级线程必须等待低优先级线程拥有的资源的时间。
cyclitest仅提供用户态实时任务的抖动测试,xenomai官方测试程序 latency分别提供了用户态、内核态实时任务和 内核态软件 timer的测试,其中内核态timer近似的模拟中断的响应时间,因为一个软件timer的处理,底层是由硬件timer时间到期来触发中断处理的,其中用户态抖动测试原理如下图所示。
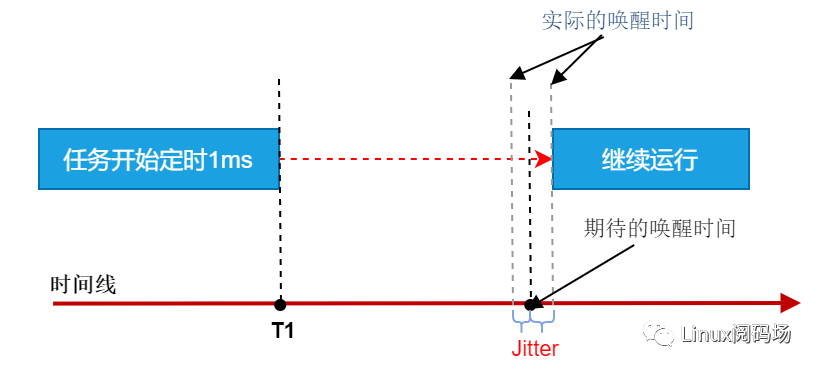
| nostress | user-task ltaency(us) | kernel-task ltaency(us) | kernel-Timer(us) |
|---|---|---|---|
| 最小值 | -1.200 | -3.360 | -1.200 |
| 平均值 | 2.037 | -0.606 | 1.693 |
| 最大值 | 27.120 | 13.880 | 14.600 |
| 抖动 | 28.32 | 17.24 | 15.8 |
| stress | user-task ltaency(us) | kernel-task ltaency(us) | kernel-Timer(us) |
|---|---|---|---|
| 最小值 | 3.629 | -3.720 | -1.360 |
| 平均值 | 9.346 | -0.682 | 1.543 |
| 最大值 | 29.289 | 15.880 | 13.920 |
| jitter | 25.66 | 19.6 | 15.28 |
这里laten为负值,表示内核中默认中断gravity、内核调度gravity、用户调度gravity比实际值偏大,如果你的应用场景不允许任务提前唤醒,如何调整?在真实生产环境可通过运行autotune得出准确值后:
重新配置编译安装内核
-
-> Xenomai/cobalt (XENOMAI [=y]) -
-> Latency settings -
(0) User scheduling latency (ns) -
(0) Intra-kernel scheduling latency (ns) -
(0) Interrupt latency (ns)
-
通过写
/proc/xenomai/latency或/proc/xenomai/clock/coreclk动态修改,见后文。
1.2 串口实时性测试
源码简介中说到 cross-link,cross-link是串口实时性测试工具,能反应系统整体实时性能,cross-link要求的硬件连接图如下:
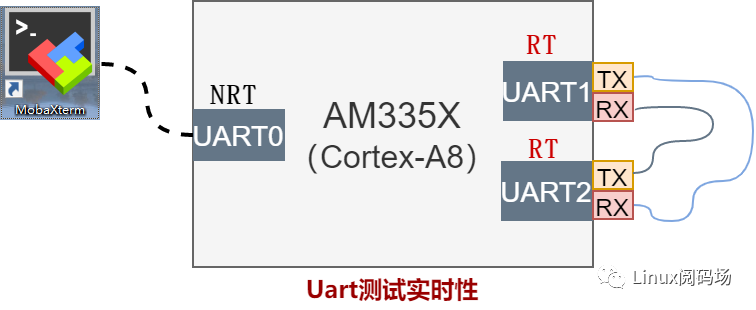
UART1和UART2是xenomai RTDM驱动管理的两个设备,RX-TX交差相连,UART0是普通linux驱动管理的设备,这里作为终端使用。cross-link应用程序逻辑如下:

测试原理为,两个RT 线程 Task1和 Task2,各打开一路串口, Task1读取时间T1通过UART发送,Task2阻塞接收数据T1,接收后读取此时系统时间T2,计算T1与T_2之间的差值就是,整个串口通讯的耗时。如果是操作系统是实时的,传输速率不变,那么这个差值T是一个确定的范围的值,在us级范围内波动,这个波动就能反映操作系统的实时性能。
linux stress-c10-m2----vm-bytes16MB压力下, 波特率3.68Mbps,进行10W次收发测试,结果如下:
-
... -
Nr| write->irq | irq->read | write->read | -
----------------------------------------------------------- -
1000| 666440|18446744073708932056| 46880 -
2000| 666120|18446744073708932216| 46720 -
3000| 666480|18446744073708932616| 47480 -
4000| 666480|18446744073708932656| 47520 -
5000| 667680|18446744073708934496| 50560 -
6000| 666280|18446744073708932376| 47040 -
7000| 666440|18446744073708932296| 47120 -
8000| 666160|18446744073708932616| 47160 -
9000| 666120|18446744073708932296| 46800 -
....... -
90000| 666080|18446744073708932136| 46600 -
91000| 666880|18446744073708933136| 48400 -
92000| 667200|18446744073708933736| 49320 -
93000| 666320|18446744073708932576| 47280 -
94000| 666200|18446744073708932096| 46680 -
95000| 666160|18446744073708931776| 46320 -
96000| 665960|18446744073708932096| 46440 -
97000| 666280|18446744073708932096| 46760 -
98000| 666440|18446744073708932376| 47200 -
99000| 666240|18446744073708932176| 46800 -
----------------------------------------------------------- -
mini | 665680|18446744073708931296| 45360 -
max | 674700|18446744073708946766| 69850 -
Transfer size:8Byte period:10000000 ns -
main : delete write_task -
main : delete read_task
需要说明的
write->irq和irq->read值为什么比较大?该测试程序xenomai2中就存在,write->irq表示$$Task1$$写数据时间$$T1$$到$$Uart2$$产生接收中断$$T{irq}$$之间的时间差,由于$$T1$$是用户态调用alchemy接口读取的时间,而$$T_{irq}$$是内核态中断处理函数读取的时间,在xenomai3上用户态和内核态的读取的时间值存在一个固定的差值,xenomai2中没有该问题,irq->read同理,所以这两个数据差距比较大,这里看总时间write->read即可。
从测试数据可以看出,最小时间为45.360us,最大时间69.850us ,即 Task1写数据到内核态---RTDM驱动将数据写入Uart1控制器发送---线路传输---Uart2中断接收处理---唤醒 Task2---上下文切换Task2--数据拷贝到Task2用户态继续运行,整个流程时间抖动在24.49us内,与上面latency测试程序基本相符。
1.3 GPIO实时性测试
gpiobench:提供了两种通过实时gpio测试系统实时性的方式:
-
方式1
类似串口的方式,两个gpio口相连,从一个 gpio 输出引脚发送高电平脉冲,并从另一个 gpio 引脚接收中断,测量两个事件之间的时间;

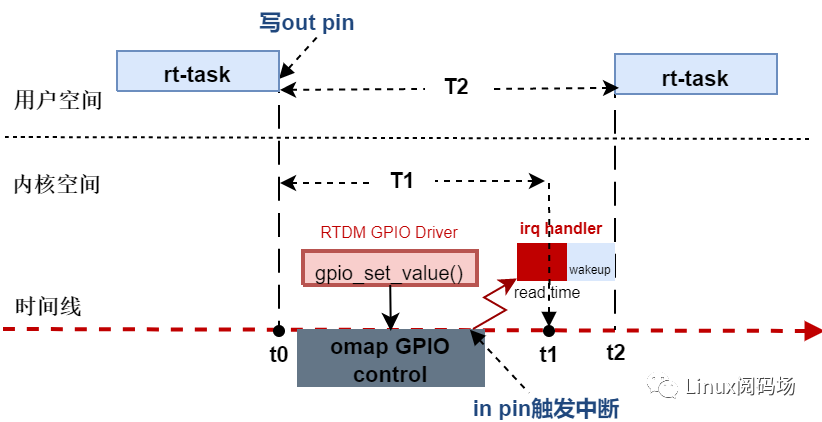
gpiobench会记录两个时间T1和T2并在测试完成时打印, stress-c10-m2--vm-bytes16M条件下,测试100W次,其中T1如下(单位us):
-
root@xxxxx/app/bin# ./gpiobench -o 19 -i 20 -l 100000 -q -
----rt task, gpio loop, test run---- -
-
# Inner Loop Histogram -
# Inner Loop latency is the latency in kernel space -
# between gpio_set_value and irq handler -
000000000000 -
... -
000009128840 -
000010047625 -
000011014770 -
000012004761 -
000013002243 -
000014001115 -
000015000464 -
000016000141 -
000017000031 -
000018000012 -
000019000001 -
.... -
000099000000 -
# Total: 000099999 -
# Min Latencies: 00009 -
# Avg Latencies: 9.551216 -
# Max Latencies: 00019
其中T2如下:
-
# Outer Loop Histogram -
# Outer Loop latency is the latency in user space -
# between write and read -
# Technically, outer loop latency is inner loop latercy -
# plus overhead of event wakeup -
000000000000 -
... -
000017000001 -
000018124952 -
000019029179 -
000020019092 -
000021012050 -
000022004978 -
000023003129 -
000024002173 -
000025001434 -
000026001025 -
000027000749 -
000028000492 -
000029000337 -
000030000185 -
000031000108 -
000032000054 -
000033000031 -
000034000016 -
000035000011 -
000036000005 -
000037000001 -
000038000000 -
000039000001 -
... -
000099000000 -
# Total: 000099999 -
# Min Latencies: 00017 -
# Avg Latencies: 18.956690 -
# Max Latencies: 00039
-
方式2
一个gpio 引脚接收中断后,从另一个gpio 输出确认信号,测量两个信号之间的延迟(可通过外部示波器等设备测量两个事件之间的时间),在此就不再测试。

四、xenomai各种接口应用编译
1.1 编译参数获取
xenomai 3组成结构小节说到,xenomai库libcobalt提供了多种编程接口,这些接口编写的实时应用程序如何编译呢?xenomai提供了一个脚本工具 xeno-config来生成各个接口的GCC编译链接参数:
-
$ /usr/bin/xeno-config --help -
xeno-config --verbose -
--core=cobalt -
--version="3.2.1" -
--cc="gcc" -
--ccld="/usr/bin/wrap-link.sh gcc" -
--arch="x86" -
--prefix="/usr" -
--library-dir="/usr/lib" -
Usage xeno-config OPTIONS -
Options: -
--help -
--v,--verbose -
--version -
--cc -
--ccld -
--arch -
--prefix -
--[skin=]posix|vxworks|psos|alchemy|rtdm|smokey|cobalt -
--auto-init|auto-init-solib|no-auto-init -
--mode-check|no-mode-check -
--cflags -
--ldflags -
--lib*-dir|libdir|user-libdir -
--core -
--info -
--compat
其中 --[skin=]参数指定我们编译的应用程序是什么接口类型,例如编译一个POSIX接口的实时应用,指定接口(skin) --posix,同时使用参数 --cflags来获取POSIX接口实时应用的编译参数:
$ /usr/bin/xeno-config --posix --cflags-I/usr/include/xenomai/cobalt-I/usr/include/xenomai-D_GNU_SOURCE-D_REENTRANT-fasynchronous-unwind-tables-D__COBALT__-D__COBALT_WRAP__
1.2 链接参数获取
获取链接参数, --ldflags得到链接参数:
$ /usr/bin/xeno-config --ldflags --posix-Wl,--no-as-needed -Wl,@/usr/lib/cobalt.wrappers -Wl,@/usr/lib/modechk.wrappers /usr/lib/xenomai/bootstrap.o -Wl,--wrap=main -Wl,--dynamic-list=/usr/lib/dynlist.ld -L/usr/lib -lcobalt -lmodechk -lpthread -lrt
同样通过指定 --[skin=]为vxworks、psos来编译VxWorks、psos实时应用程序到xenomai上运行。
五、xenomai proc文件信息介绍
1.1 实时外设中断信息
ipipe
ipipe为了xenomai与linux之间更好地结合,引入了虚拟中断。虚拟中断和常规softirq本质上不同,softirq只存在linux中,ipipe虚拟中断更近似于硬件中断,但不是硬件触发,由内核之间需要处理紧急任务时向另一个内核发送,ipipe处理虚拟中断与处理硬件中断流程一致,这些中断信息分为Llinux和xenomai,分别对应文件 /proc/ipipe/Linux和 /proc/ipipe/Xenomai。
双核下ipipe层linux中断信息:
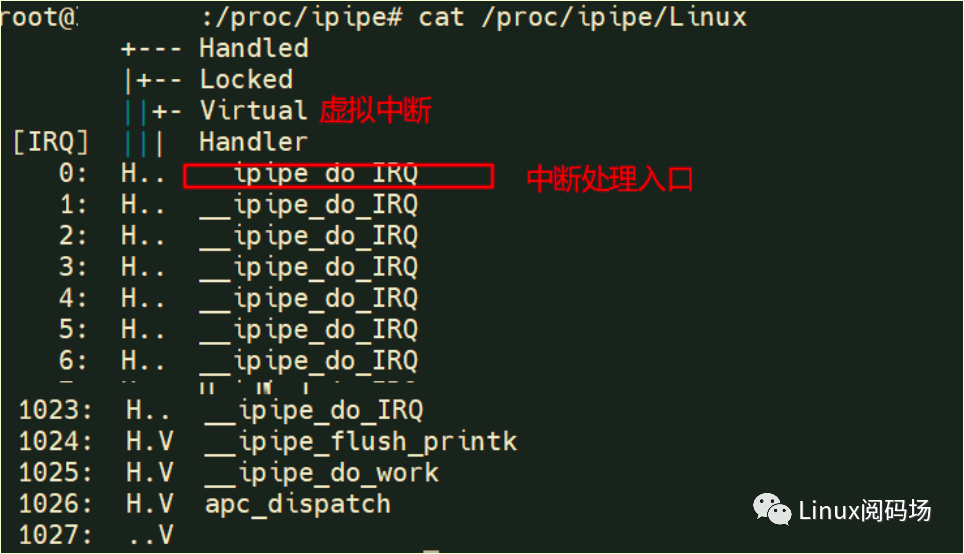
__ipipe_do_IRQ为linux非实时中断处理入口,为了保证cobalt内核的实时性,这些irq对于的中断必须延迟处理。
__ipipe_flush_printk虚拟中断,为了避免cobalt内核的打印输出影响实时性,打印时通过向linux内核发送虚拟中断来进行打印输出。
__ipipe_do_work虚拟中断,是为cobalt内核实时上下文需要linux非实时上下文处理一些任务时提供的通知机制,一些应用如下:
-
实时上下文运行的任务需要调linux的非实时服务时,用于将该任务从cobalt kernel切换到linux kernel;
-
实时应用close实时设备时,需要linux清理task文件描述符fd;
-
实时网卡驱动中 watchdog_timer中断需要linux处理等等。
apc_dispatch与 __ipipe_do_work类似,比如实时与非实时通讯时,从实时上下文唤醒等待的linux任务等;
以上是ipipe层的中断信息,linux具体的外设中断信息还是通过 /proc/interrupts文件查看,没有变化。
下图为ipipe层xenomai实时中断信息:
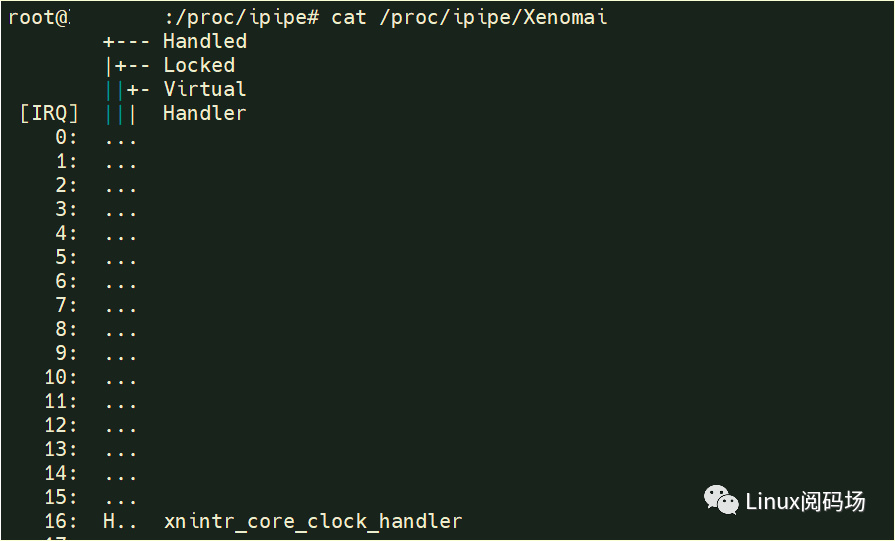
更具体有哪些实时驱动设备注册了中断,通过 /proc/xenomai/irq来查看:

dovetail
dovetail区别与ipipe,它是在已有linux中断管理代码上进行扩展,为实时核提供与ipipe相同的功能。所以 /proc/interrupts就包含了ipipe层和xenomai实时中断信息。
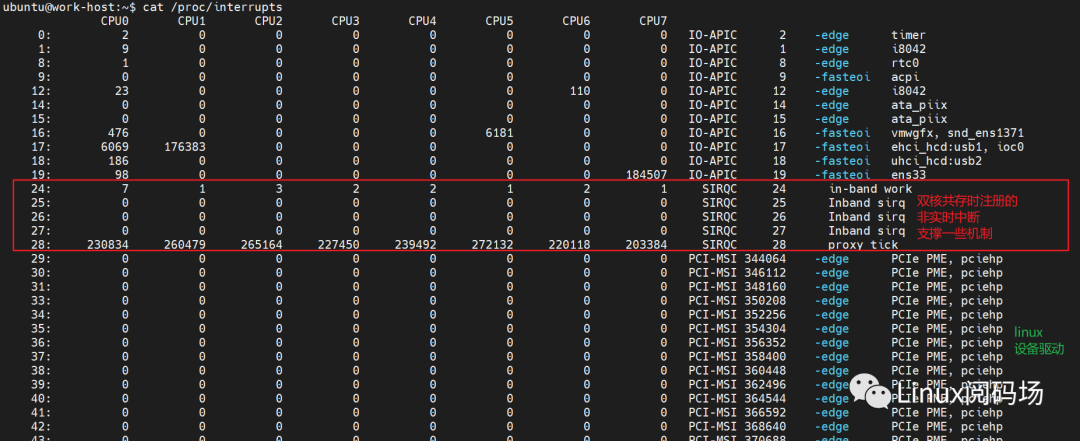

其中 inband表示非实时域中断, oob表示实时域中断。与ipipe一样,需要注意的是,这里的一些中断不是硬件触发的,是dovetail模拟的中断,只有触发源头不同,软件处理流程与硬件中断处理流程一致。
1.2 查看实时核信息
xenomai内核相关信息均为位于 /proc/xenomai/目录下:

xenomai调度cpu
-
ubuntu@work-host:/proc/xenomai$ cat /proc/xenomai/affinity -
000000ff
/proc/xenomai/affinity中是一组掩码,每一个bit表示系统中的一个CPU,该源码表示cobalt内核管理的CPU集,若实时应用程序中没有设置affinity,那么该实时会调度在该掩码下的任意一个CPU上。当我们需要将指定cpu给cobalt调度的时候,可以通过添加内核参数 xenomai.supported_cpus=0x06来修改,这通常结合linux参数 isolcpus来优化实时性能。
硬件timer与延迟信息
/proc/xenomai/clock/coreclk包含了系统的硬件timer和gravity信息。
root@xxxxx:/proc/xenomai# cat clock/coreclkgravity: irq=1880 kernel=6880 user=6880devices: timer=timer2, clock=ipipe_tscwatchdog: offsetup: 1880ticks:230615579053(0035b1c279ad)
-
gravity在前文autotune工具部分已经解释,它的值可通过
autotune命令来重新测量调整:
root@xxxxx:/proc/xenomai# autotune== auto-tuning started, period=1000000 ns (may take a while)irq gravity... 2880 nskernel gravity... 4320 nsuser gravity... 7200 ns== auto-tuning completed after 38sroot@xxxxx:/proc/xenomai# cat clock/coreclkgravity: irq=2880 kernel=4320 user=7200devices: timer=timer2, clock=ipipe_tscwatchdog: offsetup: 1880ticks:25641430824(0005f8592f28)
-
如果latency测试后只修user gravity,
echo xxxx>/proc/xenomai/latency即可: -
root@xxxxx:/proc/xenomai# echo 6680 > latencyroot@xxxxx:/proc/xenomai# cat clock/coreclkgravity: irq=2880 kernel=4320 user=6680devices: timer=timer2, clock=ipipe_tscwatchdog: offsetup: 1880ticks:28659743127(0006ac40f997)
-
若三者都需要修改,可通过
echo irq=xxxx kernel=xxxx user=xxxx>/proc/xenomai/clock/coreclk修改: -
root@xxxxx:/proc/xenomai# echo irq=0 kernel=0 user=0 > clock/coreclkroot@xxxxx:/proc/xenomai# cat clock/coreclkgravity: irq=0 kernel=0 user=0devices: timer=timer2, clock=ipipe_tscwatchdog: offsetup: 1880ticks:32430637968(00078d044390)
faults
文件 /proc/xenomai/faults提供了cobalt内核实时上下文产生的fault统计信息,为什么需要关注CPU fault?回到实时性,如果我们的实时任务真正进行关键的行为,此时产生了异常,异常必须解决才能继续运行,这就导致了结果输出的不确定性,即影响实时性。这也是为什么我们在xenomai应用编程时不能通过glibc库进行动态内存分配的原因,因为linux内存的惰性内存分配机制,只有在应用访问分配的虚拟内存地址时才产生缺页异常(Page fault)进行物理内存分配,同时linux在内存水位过低时也会进行内存回收,需要考虑。这也是为什么VxWorks等RTOS很少使用MMU的原因。
该文件只统计cobalt内核管理的CPU且在实时调度上下产生的异常,因此,若你运行的实时任务抖动比较大,建议查看一下文件,是否是受到异常的影响。
X86下各类异常如下:
:/proc/xenomai$ cat faultsTRAP CPU0 CPU10: 0 0 (Divide error)1: 0 0 (Debug)3: 0 0 (Int3)4: 0 0 (Overflow)5: 0 0 (Bounds)6: 0 0 (Invalid opcode)7: 0 0 (FPU not available)8: 0 0 (Double fault)9: 0 0 (FPU segment overrun)10: 0 0 (Invalid TSS)11: 0 0 (Segment not present)12: 0 0 (Stack segment)13: 0 0 (General protection)14: 0 0 (Page fault)15: 0 0 (Spurious interrupt)16: 0 0 (FPU error)17: 0 0 (Alignment check)18: 0 0 (Machine check):00(SIMDerror)
heap
-
ubuntu@work-host:/proc/xenomai$ cat heap -
TOTAL FREE NAME -
41943044192256 system heap -
262144262016 shared heap
该文件显示了xenomai heap的信息。前面说到,为避免实时性受到影响,实时应用运行过程中不能使用linux的惰性内存分配接口,在内核里也是一样,一是linux内核内存分配算法的不确定性,二是linux内核惰性分配原则。所以xenomai的解决机制是,xenomai内核初始化时预先分配一大片内存,并一一读写访问来建立虚拟内存与物理内存的映射,再通过自己的内存分配算法进行管理,该分配算法时间是确定的,xenomai自己管理的内存称为 xnheap,xenomai运行过程中的动态内存分配均从 xnheap中分配,为避免多个子系统同时访问一个 xnheap,xenomai内核内有多个heap,这些heap的大小可通过内核参数 xenomai.sysheap_size=配置,或内核编译时配置:
-
[*] Xenomai/cobalt ---> -
Sizes and static limits ---> -
(512) Number of registry slots -
(4096) Size of system heap (Kb) -
(512) Size of private heap (Kb) -
(512) Size of shared heap (Kb)
关于 xnheap内存分配管理算法,有单独的文章介绍。
registry
什么是registry?与内存资源类似,在操作系统管理应用程序或为应用程序提供服务的实时,需要管理很多对象。
举个例子,有两个xenoami实时任务, 它们使用semaphore做同步互斥,任务1创建一个名为 /test-sem的semaphore,任务2打开这个semaphore并使用该semaphore,思考下面两个问题:
-
问题1:任务1创建的这个semaphore是如何管理的?
-
问题2:任务2又是如何通过name找到它的?
这里例子中的semaphore在操作系统内核中可以一种内核对象,registry提供了一个机制,用于保存xenomai全局内核对象。这些对象分为两种,一种有name,常用于两个及以上进程间,可以通过name来找到同一对象。另一种没有name,常用于同一进程空间。
registry的大小和heap一样预先分配,xenomai运行过程中直接获取,一是全局方便查找降低实现复杂度,二避免内存分配导致系统heap竞争。默认大小为512个条目。
-
ubuntu@work-host:/proc/xenomai$ cat registry/usage -
10/512
若你运行在xenomai上的软件比较庞大和复杂,512个不够使用,可重新配置编译内核:
-
-> Xenomai/cobalt (XENOMAI [=y]) -
-> Sizes and static limits -
(512) Number of registry slots
关于 registry内核对象的管理机制,会有单独的文章介绍。
1.3 调度与任务状态
下面看最重要的部分,xenomai内核和实时任务运行状态信息在 /proc/xenomai/sched下:

其中 /proc/xenomai/sched/rt/threads与 /proc/xenomai/sched/threads,前者仅包括优先级大于0的xenomai任务信息,后者包括所有xenomai调度的任务信息,比如我们在运行latency时,只有 sampling线程是有优先级的,主线程和 display线程优先级均为0。
线程状态
root@xxxxx:/proc/xenomai/sched# cat threadsCPU PID CLASS TYPE PRI TIMEOUT STAT NAME0 0 idle core -1 - R [ROOT]0 265 rt core 98 - W [rtnet-stack]0 266 rt core 0 - W [rtnet-rtpc]0 281 rt core 0 - W [rtnetproxy]0 380 rt cobalt 0 - X latency0 382 rt cobalt 0 - W display-3800 383 rt cobalt 99 - Wt sampling-380root@xxxxx:/proc/xenomai/sched# cat rt/threadsCPU PID PRI PERIOD NAME0 265 98 - rtnet-stack0 383 99 - sampling-380
-
CPU 表示该实时任务在哪个CPU的调度队列上。
-
CLASS 表示该任务的调度类
-
TYPE 中core表示该任务是内核态任务,cobalt用户态任务
-
PRI 表示任务优先级
-
STAT 表示任务所处状态
系统统计信息
下面看cobalt内核统计信息 /proc/xenomai/sched/stat,这对我们查找实时问题时有帮助,以latency运行为例,输出如下:
:/proc/xenomai/sched# cat statCPU PID MSW CSW XSC PF STAT %CPU NAME0 0 0 40051 0 0 00018000 99.1 [ROOT]0 265 0 2 0 0 00000042 0.0 [rtnet-stack]0 266 0 2 0 0 00020042 0.0 [rtnet-rtpc]0 282 0 2 0 0 00020042 0.0 [rtnetproxy]0 329 1 1 5 0 000600c0 0.0 latency0 331 40 80 44 0 00060042 0.0 display-3290 332 2 40003 40046 0 0004c042 0.6 sampling-3290 0 0 44791 0 0 00000000 0.3 [IRQ16: [timer]]0 0 0 0 0 0 00000000 0.0 [IRQ46: 4a100000.ethernet]:4a100000.ethernet]
它统计了cobalt内核线程、用户态线程、中断的信息,这些信息包括:
-
CPU 运行的CPU和PID
-
MSW域上下文切换。xenomai是双内核结构,xenomai应用可以无缝使用linux提供的服务,但这是有风险的,因为使用linux服务需要切换到linux非实时调度上下文,无法保证任务的实时性。MSW表示的就是实时域与非实时域之间的切换次数。
latency是主线程,它创建完高优先级线程sampling-329和负责结果打印的低优先级线程display-329后,等待SIGTERM等结束信号。间隔执行
cat stat发现display-329的MSW会不断增大,是因为打印输出需要使用linux提供的服务进行终端打印;而高优先级sampling-329的MSW没有变化,因为该线程创建后,没有调用任何linux服务全程在实时内核上下文运行。为什么sampling-329 MSW为2?因为xenomai实时线程的创建是通过linux来完成 的。
因此,如果你的实时任务会出现大的抖动,那么请通过该文件观察,是否因为不经意调用了linux的服务,切换到linux域引起的。
-
CSW xenomai内核上下文切换次数。
-
XSW 切换到linux域后,由linux内核调度的上下文切换次数。
-
PF 为Page fault产生次数。
-
STAT 运行状态掩码
-
%CPU CPU使用率,需要额外说明的是,[ROOT]表示的是cobalt内核调度下的linux,双核下linux已经退化为cobalt内核调度的一个任务。
解析系统调用是了解内核架构最有力的一把钥匙,后续文章会以xenomai POSIX接口(libcobalt )为入口,解析xenomai内核的内部机制。
审核编辑 :李倩
-
Linux
+关注
关注
87文章
11301浏览量
209409 -
源码
+关注
关注
8文章
640浏览量
29193 -
Xenomai
+关注
关注
0文章
10浏览量
7986
原文标题:xenomai内核解析之xenomai初探
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
原子结构模型及特点 原子的组成及结构解析
基于无操作系统的STM32单片机开发附源码
揭秘电子连接器:组成结构与防水原理

迅为瑞芯微RK3568开发板/核心板《iTOP-3568开发板实时系统使用手册》
迅为RK3568开发板/核心板助力实时系统!
锁存器的结构组成及工作原理
FMS柔性制造系统的结构组成
伺服系统的结构组成及应用场景
数控机床的基本结构组成和工作原理
伺服控制系统的结构组成和工作原理
什么是源码?源码有什么作用?源码组件是什么?源码可二次开发吗?






 工商网监
工商网监
评论