 Hybridizer编译器在GPU上实现高级C#功能
Hybridizer编译器在GPU上实现高级C#功能
Hybridizer 是一个来自 Altimesh 的编译器,它允许您从 C 代码或.NET 程序集编程 GPUs 和其他加速器。使用修饰符号来表示并行性, Hybridizer 生成针对多核 CPUs 和 GPUs 优化的源代码或二进制文件。在这篇博文中,我们展示了 CUDA 的目标。
图 1 显示了混合器编译管道。使用 Parallel.For 等并行化模式,或者像在 CUDA 中那样显式地分配并行工作,您可以从加速器的计算马力中获益,而无需了解其内部架构的所有细节。
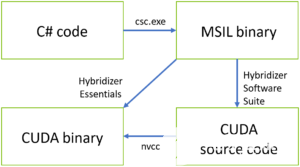
图 1 杂交剂管道。
[EntryPoint] public static void Run(double[] a, double[] b, int N) { Parallel.For(0, N, i => { a[i] += b[i]; }); }
您可以使用 NVIDIA Nsight Visual Studio Edition 在 GPU 上调试和分析这段代码。Hybridizer 实现高级 C#功能,包括虚拟功能和泛型。
哪里可以获取 Hybridizer
Hybridizer 有 两个版本 :
Hybridizer 软件套件:启用 CUDA 、 AVX 、 AVX2 、 AVX512 目标并输出源代码。可以查看此源代码,这在投资银行等一些业务中是强制性的。 Hybridizer 软件套件是根据客户 应要求 获得许可的。
杂交者基本要素 :仅启用 CUDA 目标并仅输出二进制文件。 Hybridizer Essentials 是免费的 Visual Studio 扩展 ,没有硬件限制。 您可以在 GitHub 上找到一组基本的代码示例和教育材料 。这些样本也可以用来重现我们的性能结果。
在提供自动默认行为的同时, Hybridizer 在每个阶段都提供了完全的开发人员控制,允许您重用现有的特定于设备的代码、现有的外部库或定制的手工代码片段。
调试和分析
使用调试信息编译时,可以在目标硬件上运行优化的代码时,在 Microsoft Visual Studio 中调试 Hybridizer C #/。 NET 代码。例如,用 C 编写的程序可以在 Visual Studio 中命中 C 文件中的断点,并且可以探索驻留在 GPU 上的本地变量和对象数据。
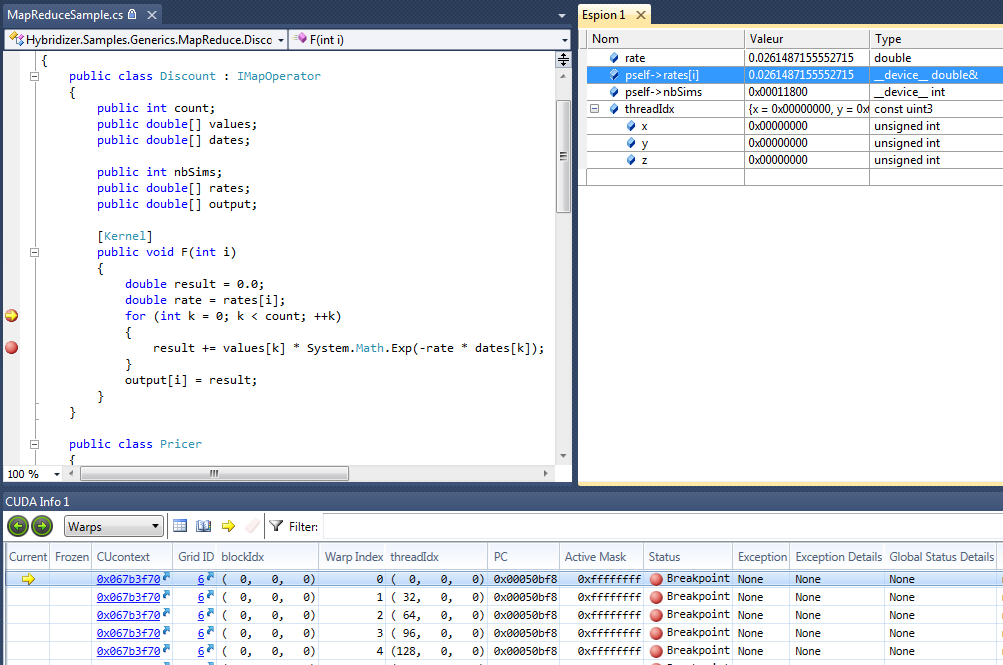
图 2 :使用 Hybridizer 和 NVIDIA Nsight VisualStudio Edition 调试运行在 GPU 上的 C 代码。
您可以在复杂的项目中集成 Hybridizer ,即使在代码不可用或混淆的库中也是如此,因为 Hybridizer 操作的是 MSIL 字节码。我们在 我们的博客帖子 中展示了这种能力,即在不修改库的情况下,用杂交子加速大型图像处理库。在 MSIL 字节码上操作还支持在。 Net 虚拟机上构建的各种语言,例如 VB 。 Net 和 F 。
所有这些灵活性并不是以性能损失为代价的。正如我们的 benchmark 所说明的,杂交器生成的代码可以执行与手写代码一样好的性能。您可以使用性能分析器,如 NVIDIA Nsight 和 NVIDIA 可视化探查器来测量生成的二进制文件的性能,性能指标引用原始源代码(例如 C )。
一个简单的例子:曼德尔布洛特
作为第一个示例,我们演示了在 NVIDIA GeForce GTX 1080 Ti GPU ( Pascal 体系结构;计算能力 6 。 1 )上运行的 Mandelbrot 分形的渲染。
Mandelbrot C 代码
下面的代码片段显示了纯 C #。它在 CPU 上平稳运行,没有任何性能损失,因为大多数代码修改都是在运行时没有影响的属性(例如 Run 方法上的 EntryPoint 属性)。
[EntryPoint]
public static void Run(float[,] result)
{
int size = result.GetLength(0);
Parallel2D.For(0, size, 0, size, (i, j) => {
float x = fromX + i * h;
float y = fromY + j * h;
result[i, j] = IterCount(x, y);
});
}
public static float IterCount(float cx, float cy)
{
float result = 0.0F;
float x = 0.0f, y = 0.0f, xx = 0.0f, yy = 0.0f;
while (xx + yy <= 4.0f && result < maxiter) {
xx = x * x;
yy = y * y;
float xtmp = xx - yy + cx;
y = 2.0f * x * y + cy;
x = xtmp;
result++;
}
return result;
}
EntryPoint属性告诉杂交器生成一个 CUDA 内核。多维数组映射到内部类型,而Parallel2D.For映射到 2D 执行网格。给出几行样板代码,我们在 GPU 上透明地运行这段代码。
float[,] result = new float[N,N];
HybRunner runner = HybRunner.Cuda("Mandelbrot_CUDA.dll").SetDistrib(32, 32, 16, 16, 1, 0);
dynamic wrapper = runner.Wrap(new Program());
wrapper.Run(result);
描绘
我们使用 Nvidia Nsight Visual Studio Edition 探查器分析了这段代码。 C 代码在 CUDA 源代码视图中链接到 PTX ,如图 3 所示。
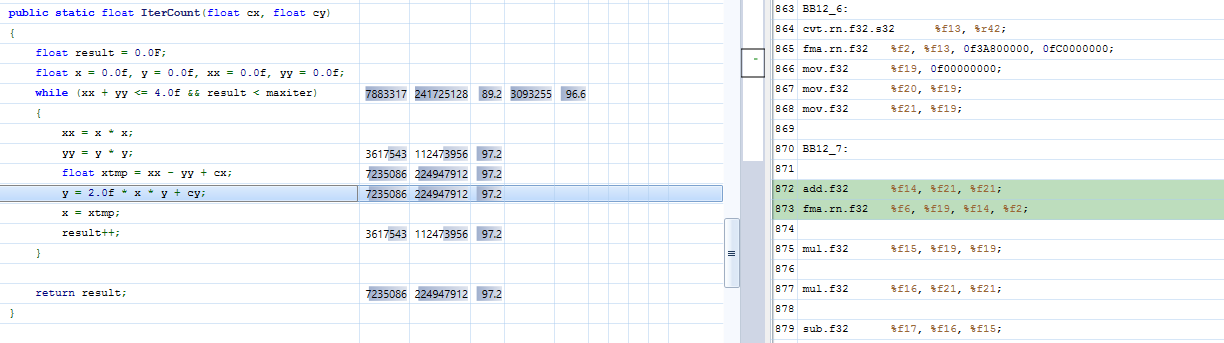
图 3 。在 CUDA 源代码视图中分析 Mandelbrot C #代码。
剖析器允许使用与 CUDA C ++代码相同的调查级别。
至于性能,这个例子达到了峰值计算 FLOP / s 的 72 。 5% ,这是用 CUDA C++ 手写的相同代码的 83% 。
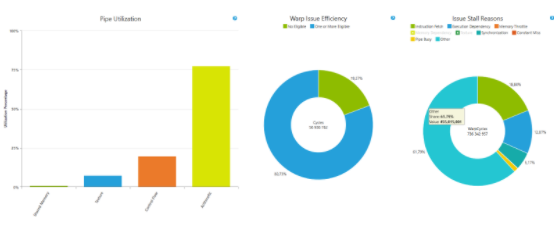
图 4 : Profiler 输出显示了 GPU 上 Mandelbrot 代码的利用率和执行效率。它达到了与手写 CUDA C ++代码差不多的良好效率。
使用杂交器提供的扩展控制,可以从 C 代码中获得更好的性能。正如下面的代码所示,语法与 CUDA C ++非常类似。
[EntryPoint]
public static void Run(float[] result)
{
for (int i = threadIdx.y + blockIdx.y * blockDim.y; i < N; i += blockDim.y * gridDim.y)
{
for (int j = threadIdx.x + blockIdx.x * blockDim.x; j < N; j += blockDim.x * gridDim.x)
{
float x = fromX + i * h;
float y = fromY + j * h;
result[i * N + j] = IterCount(x, y);
}
}
}
在这种情况下,生成的代码和手写的 CUDA C ++代码执行一致,达到峰值触发器的 87% ,如图 5 所示。
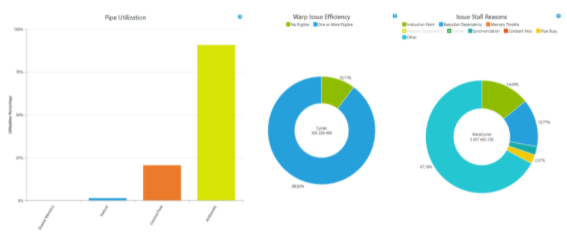
图 5 :分析手动优化的 Mandelbrot C 代码。
泛型与虚函数
Hybridizer 在设备功能上支持 泛型和虚函数调用 。现代编程语言的这些基本概念促进了代码模块化并提高了表达能力。然而, C 型的类型解析是在运行时完成的,这引入了一些性能上的惩罚。席。 NET- 泛型可以在保持灵活性的同时实现更高的性能: FixZER 将泛型映射到 C ++模板,这些模板在编译时被解决,允许函数内联和过程间优化。另一方面,虚拟函数中的方法被映射到另一个虚拟函数中。
模板实例化提示由两个属性 HybridTemplateConcept 和 HybridRegisterTemplate 提供给混合器(在设备代码中触发实际的模板实例化),另一个使用模板映射。基准依赖于一个公开下标运算符的公共接口 IMyArray :
[HybridTemplateConcept]
public interface IMyArray {
double this[int index] { get; set; }
}
这些操作员必须与设备功能“混合”。为此,我们将Kernel属性放在实现类中。
public class MyArray : IMyArray {
double[] _data;
public MyArray(double[] data) {
_data = data;
}
[Kernel]
public double this[int index] {
get { return _data[index]; }
set { _data[index] = value; }
}
}
虚函数调用
在第一个版本中,我们使用接口编写一个流算法,而不向编译器提供进一步的提示。
public class MyAlgorithmDispatch {
IMyArray a, b;
public MyAlgorithmDispatch(IMyArray a, IMyArray b) {
this.a = a;
this.b = b;
}
[Kernel]
public void Add(int n) {
IMyArray a = this.a;
IMyArray b = this.b;
for (int k = threadIdx.x + blockDim.x * blockIdx.x;
k < n;
k += blockDim.x * gridDim.x) {
a[k] += b[k];
}
}
}
因为我们在a和b上调用下标运算符,所以在 MSIL 中有一个callvirt。
IL_002a: ldloc.3 IL_002b: ldloc.s 4 IL_002d: callvirt instance float64 Mandelbrot.IMyArray::get_Item(int32) IL_0032: ldloc.1 IL_0033: ldloc.2 IL_0034: callvirt instance float64 Mandelbrot.IMyArray::get_Item(int32) IL_0039: add IL_003a: callvirt instance void Mandelbrot.IMyArray::set_Item(int32, float64)
检查生成的二进制文件显示, Hybridizer 在虚拟函数表中生成了一个查找,如图 6 所示。
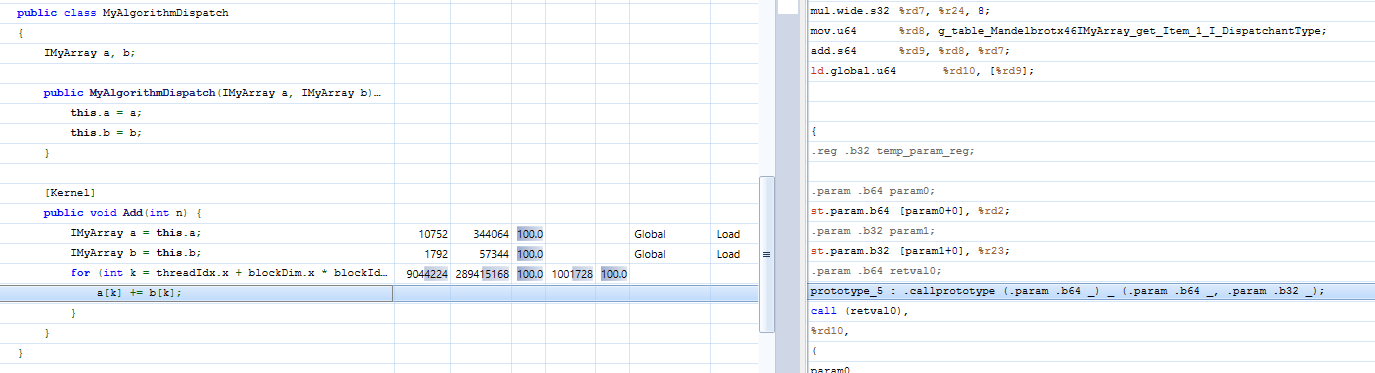
图 6 PTX 中的虚函数调用。
这个版本的算法消耗 32 个寄存器,达到 271 GB / s 的带宽,如图 7 所示。在相同的硬件上, CUDA 工具箱中的 bandwidthTest 示例达到 352Gb / s 。
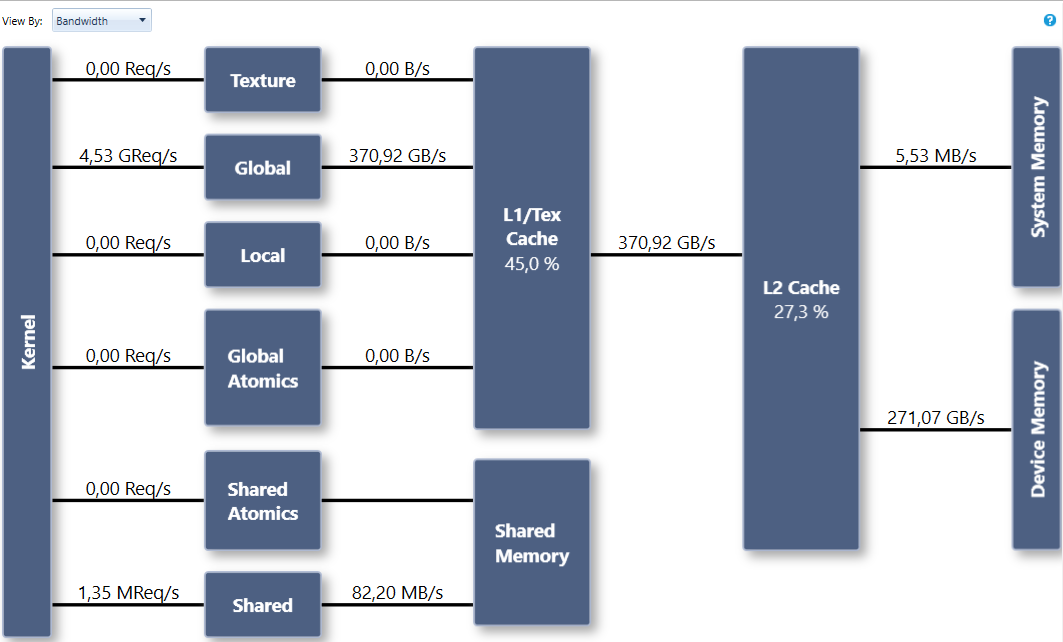
图 7 由于虚拟函数调用,实现的带宽较低。
虚函数表导致更大的寄存器压力,并阻止内联。
一般呼叫
我们用泛型编写了第二个版本,要求杂交子生成模板代码。
[HybridRegisterTemplate(Specialize = typeof(MyAlgorithm))]
public class MyAlgorithm where T : IMyArray
{
T a, b;
[Kernel]
public void Add(int n)
{
T a = this.a;
T b = this.b;
for (int k = threadIdx.x + blockDim.x * blockIdx.x;
k < n;
k += blockDim.x * gridDim.x)
a[k] += b[k];
}
}
public MyAlgorithm(T a, T b)
{
this.a = a;
this.b = b;
}
}
使用 RegisterTemplate 属性, Hybridizer 生成适当的模板实例。然后优化器内联函数调用,如图 8 所示。
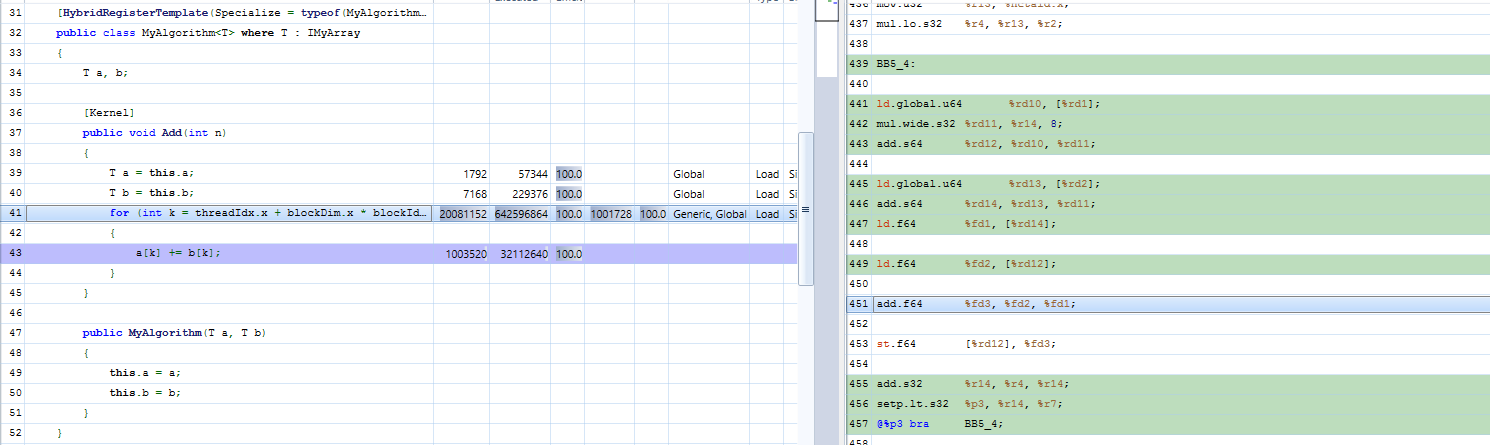
图 8 使用泛型参数生成内联函数调用,而不是虚拟函数表查找。
泛型参数的性能要好得多,达到 339gb / s ,性能提高了 25% (图 9 ),比 bandwidthTest 提高了 96% 。
图 9 由于函数内联,泛型实现了更高的带宽。
开始使用杂交剂
Hybridizer 支持多种 C 特性,允许代码分解和表达能力。 Visual Studio 与 Nsight (调试器和探查器)的集成为您提供了一个安全高效的开发环境。 Hybridizer 即使在非常复杂、高度定制的代码上也能获得出色的 GPU 性能。
关于作者
Florent Duguet 是 Altimesh 的创始人, Altimesh 是一家法国软件工程公司,专门从事自动代码转换和多核和多核代码优化。他学习数学、物理和计算机科学,并于 2005 年获得计算机图形学博士学位。作为 GPU 计算领域的早期采用者, Florent 自 2007 年初开始在各种环境中实施 CUDA 解决方案,如定量金融、石油和天然气以及图像处理,同时致力于 Hybridizer 以实现代码转换的自动化。
R é gis 是 Altimesh 的研究工程师。他于 2010 年毕业于 Ecole Polytechnique ,学习纯数学和应用数学,如拓扑学和计算流体力学。瑞吉斯在加入 Altimesh 之前曾在微软做过三年的工程师。 Regis 专注于使 LLVM-IR 成为杂交剂和杂交剂要素开发的输入。
审核编辑:郭婷
-
cpu
+关注
关注
68文章
10873浏览量
212096 -
gpu
+关注
关注
28文章
4744浏览量
129019 -
虚拟机
+关注
关注
1文章
918浏览量
28257
发布评论请先 登录
相关推荐
Triton编译器与GPU编程的结合应用
Triton编译器如何提升编程效率
Triton编译器在高性能计算中的应用
Triton编译器的优化技巧
Triton编译器的优势与劣势分析
Triton编译器在机器学习中的应用
Triton编译器支持的编程语言
Triton编译器与其他编译器的比较
Triton编译器功能介绍 Triton编译器使用教程
HighTec C/C++编译器支持Andes晶心科技RISC-V IP

人工智能编译器与传统编译器的区别
SEGGER编译器优化和安全技术介绍 支持最新C和C++语言






 工商网监
工商网监
评论