 makefile都有哪些语法?
makefile都有哪些语法?
Make简介:
- 工程管理器,顾名思义,是指管理较多的文件
- Make工程管理器也就是个“自动编译管理器”,这里的“自动”是指它能够根据文件时间戳自动发现更新过的文件而减少编译的工作量,同时,它通过读入Makefile文件的内容来执行大量的编译工作
- ==Make将只编译改动的代码文件,而不用完全编译。==
会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力,makefile关系到了整个工程的编译规则。一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,因为makefile就像一个Shell脚本一样,其中也可以执行操作系统的命令。makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率
Makefile基本结构:
-
Makefile是Make读入的唯一配置文件
- 由make工具创建的目标体(target),通常是目标文件或可执行文件
- 要创建的目标体所依赖的文件(dependency_file)
- 创建每个目标体时需要运行的命令(command)
==注意:== 命令行前面必须是一个”**==TAB==** 键”,否则编译错误为:*** missing separator. Stop.
例如:
Makefile格式:
target:dependcy_files
command
target //目标 : target也就是一个目标文件,可以是Object File,也可以是执行文件。还可以是一个标签(Label)
dependcy_files //生成目标所要的目标文件: dependcy_files 就是,要生成那个target所需要的文件或是目标。
command也就是make需要执行的命令。(任意的Shell命令)
这是一个文件的依赖关系,也就是说,target这一个或多个的目标文件依赖于dependcy_files中的文件,其生成规则定义在command中。**==说白一点就是说,dependcy_files中如果有一个以上的文件比target文件要新的话,command所定义的命令就会被执行。这就是Makefile的规则。也就是Makefile中最核心的内容。==**
==【注】==:在看别人写的Makefile文件时,你可能会碰到以下三个变量:$@,$^,$<代表的意义分别是:
他们三个是十分重要的三个变量,所代表的含义分别是:
**
$@:目标文件,$^: 所有的依赖文件,$<:第一个依赖文件**。
这个变量的问题,我们在下面继续讲解。
复杂一些的例子:
sunq:kang.oyul.o
gcckang.oyul.o-osunq
kang.o:kang.ckang.h
gcc-Wall-O-g-ckang.c-okang.o
yul.o:yul.cyul.h
gcc-Wall-O-g-cyul.c-oyul.o
clean:
rm*.otest
注释:—Wall : 表示允许发出gcc所有有用的报警信息。—c : 只是编译不连接,生成目标文件" .o "—o file : 表示把输出文件输出到file里
我们可以把这个内容保存在文件为“Makefile”或“makefile”的文件中,然后在该目录下直接输入命令“make”就可以生成执行文件sunq。如果要删除执行文件和所有的中间目标文件,那么,只要简单地执行一下“make clean”就可以了。在这个makefile中,==目标文件(target)包含:执行文件sunq和中间目标文件(*.o),依赖文件(prerequisites)就是冒号后面的那些 .c 文件和 .h文件。每一个 .o 文件都有一组依赖文件,而这些 .o 文件又是执行文件 sunq的依赖文件。依赖关系的实质上就是说明了目标文件是由哪些文件生成的==,换言之,目标文件是哪些文件更新的。
在定义好依赖关系后,后续的那一行定义了如何生成目标文件的操作系统命令,**==一定要以一个Tab键作为开头==**。记住,make并不管命令是怎么工作的,他只管执行所定义的命令。make会比较targets文件和dependcy_files文件的修改日期,如果dependcy_files文件的日期要比targets文件的日期要新,或者target不存在的话,那么,make就会执行后续定义的命令。
1. make是如何工作的
大多数的make都支持“makefile”和“Makefile”这两种默认文件名,你可以使用别的文件名来书写Makefile,比如:“Make.Linux”,“Make.Solaris”,“Make.AIX”等,如果要指定特定的Makefile,你可以使用make的“-f”和“--file”参数,如:**make -f Make.Linux或make --file Make.AIX**。
在默认的方式下,也就是我们只输入make命令。那么,
- make会在当前目录下找名字叫“Makefile”或“makefile”的文件。
- 如果找到,它会找文件中的第一个目标文件(target),在上面的例子中,他会找到“sunq”这个文件,并把这个文件作为最终的目标文件。
- 如果sunq文件不存在,或是sunq所依赖的后面的 .o文件的文件修改时间要比sunq这个文件新,那么,他就会执行后面所定义的命令来生成sunq这个文件。
- 如果sunq所依赖的.o文件不存在,那么make会在当前文件中找目标为.o文件的依赖性,如果找到则再根据那一个规则生成.o文件。(这有点像一个堆栈的过程)
- 当然,你的C文件和H文件是存在的啦,于是make会生成 .o 文件,然后再用 .o文件声明make的终极任务,也就是执行文件sunq了。
这就是整个make的依赖性,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错,而对于所定义的命令的错误,或是编译不成功,make根本不理。make只管文件的依赖性,即,如果在我找了依赖关系之后,冒号后面的文件还是不在,那么对不起,我就不工作啦。
make工作时的执行步骤入下:(想来其它的make也是类似)
读入所有的Makefile。
读入被include的其它Makefile。
始化文件中的变量。
推导隐晦规则,并分析所有规则。
为所有的目标文件创建依赖关系链。
根据依赖关系,决定哪些目标要重新生成。
执行生成命令。
1-5步为第一个阶段,6-7为第二个阶段。第一个阶段中,如果定义的变量被使用了,那么,make会把其展开在使用的位置。但make并不会完全马上展开,make使用的是拖延战术,如果变量出现在依赖关系的规则中,那么仅当这条依赖被决定要使用了,变量才会在其内部展开。
2.makefile文件中的依赖关系理解
假设当前工程目录为object/,该目录下有6个文件,分别是:main.c、abc.c、xyz.c、abc.h、xyz.h和Makefile。其中main.c包含头文件abc.h和xyz.h,abc.c包含头文件abc.h,xyz.c包含头文件xyz.h,而abc.h又包含了xyz.h。它们的依赖关系如图。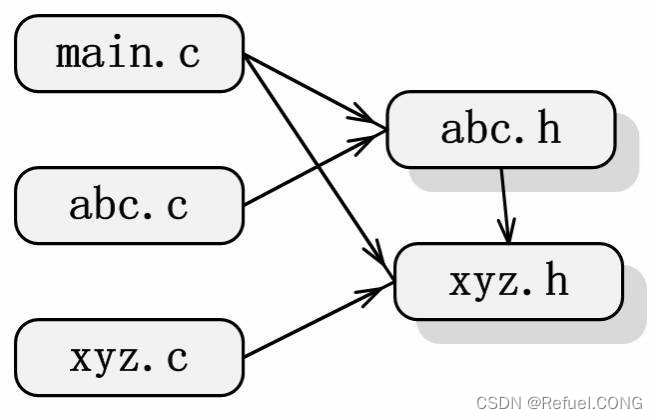 Makefile应该写成这个样子(假设生成目标main):
Makefile应该写成这个样子(假设生成目标main):
main:main.oabc.oxyz.o
gccmain.oabc.oxyz.o-omain
main.o:main.cabc.hxyz.h
gcc-cmain.c–omain.o-g
abc.o:abc.cabc.hxyz.h
gcc-cabc.c–oabc.o-g
xyz.o:xyz.cxyz.h
gcc-cxyz.c-oxyz.o-g
.PHONY:clean
clean:
rmmainmain.oabc.oxyz.o-f
3. Makefile书写规则
规则包含两个部分,一个是==依赖关系==,一个是==生成目标的方法==。
在Makefile中,规则的顺序是很重要的,因为,**==Makefile中只应该有一个最终目标==,其它的目标都是被这个目标所连带出来的,所以 ==一定要让make知道你的最终目标是什么== 。一般来说,定义在Makefile中的目标可能会有很多,但是第一条规则中的目标将被确立为最终的目标。==如果第一条规则中的目标有很多个,那么,第一个目标会成为最终的目标==。make所完成的也就是这个目标。**
3.1 规则举例
foo.o:foo.cdefs.h#foo模块
cc-c-gfoo.c
看到这个例子,各位应该不是很陌生了,前面也已说过,foo.o是我们的目标,foo.c和defs.h是目标所依赖的源文件,而只有一个命令“cc -c -g foo.c”(以Tab键开头)。这个规则告诉我们两件事:
-
文件的依赖关系,foo.o依赖于foo.c和defs.h的文件,如果foo.c和defs.h的文件日期要比foo.o文件日期要新,或是foo.o不存在,那么依赖关系发生。
-
如果生成(或更新)foo.o文件。也就是那个cc命令,其说明了,如何生成foo.o这个文件。(当然foo.c文件include了defs.h文件)
4. Makefile 基础的使用
接下来我们做个实例来学习下怎么写 Makefile
写两个c程序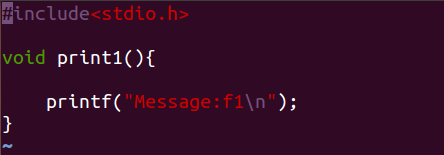
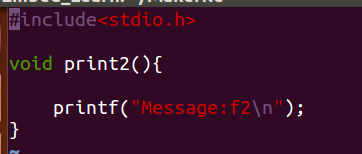 写一个head.h 头文件,用来声明上面的函数
写一个head.h 头文件,用来声明上面的函数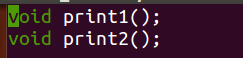
写一个main程序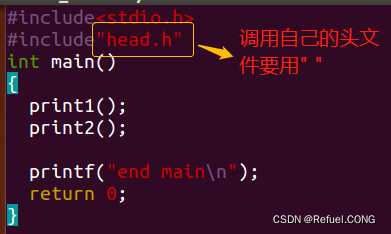
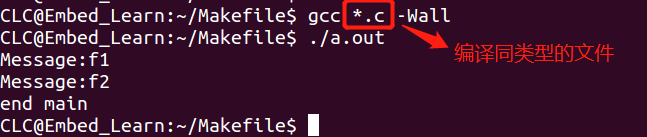
如果这样的方式写,要是改动其中文件的时候,若文件过多,会很麻烦。
所以Makefile的使用会带来很大的惊喜。
Makefile
test:fun1.ofun2.omain.o
gccfun1.ofun2.omain.o-otest
fun2.o:fun2.c
gcc-c-Wallfun2.c-ofun2.o
fun1.o:fun1.c
gcc-c-Wallfun1.c-ofun1.o
main.o:main.c
gcc-c-Wallmain.c-omain.o
Makefile内部流程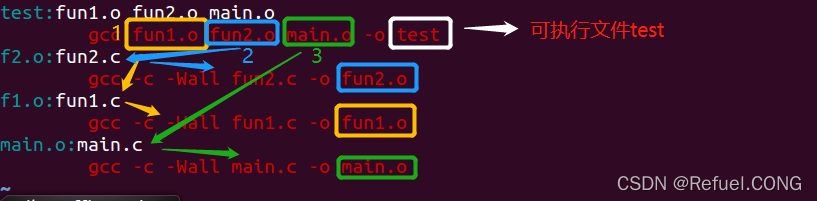
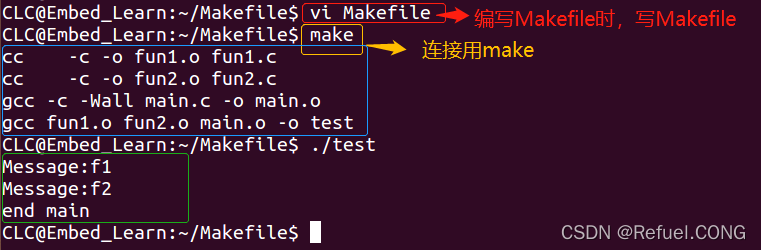 若我要改动其中的c文件 改动fun2.c
若我要改动其中的c文件 改动fun2.c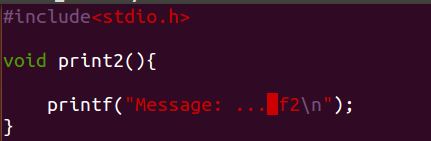 改动好后,再make 发现只有fun2.c被重新生成fun2.o ,因为fun2.o是新生成的,也要新生成 test。
改动好后,再make 发现只有fun2.c被重新生成fun2.o ,因为fun2.o是新生成的,也要新生成 test。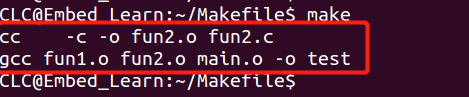 结果
结果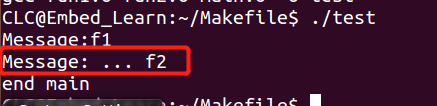 Makefile后文件夹内会生成很多中间文件
Makefile后文件夹内会生成很多中间文件
 我们需要清理时呢,我们 ==往往通过make相关命令来清理== ,而不是rm一个一个删除。
我们需要清理时呢,我们 ==往往通过make相关命令来清理== ,而不是rm一个一个删除。
clean:
rm*.otest
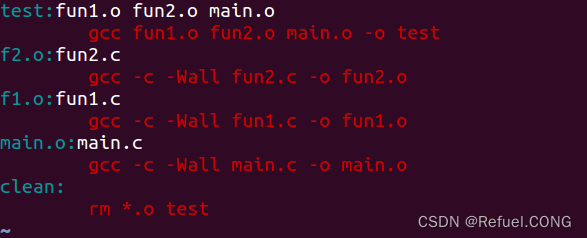 make + 目标名
make + 目标名 这样中间文件都被清理了
这样中间文件都被清理了 伪目标:肯定会被执行的文件,重名了
伪目标:肯定会被执行的文件,重名了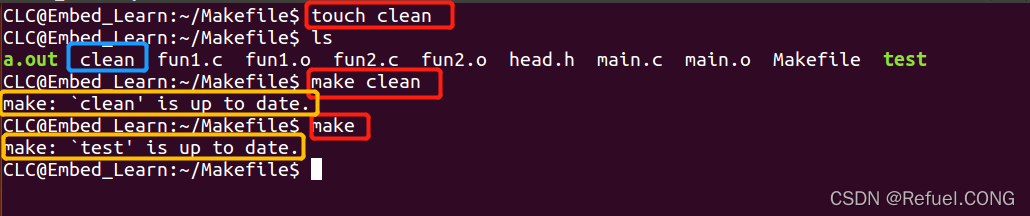 重名后,发现clean不工作了,默认为它没被改动,所以它不工作。如何避免这个问题呢?
重名后,发现clean不工作了,默认为它没被改动,所以它不工作。如何避免这个问题呢?
在Makefile中加.PHONY:command
==.PHONY:隐含说明==“.PHONY”表示,clean是个伪目标文件。
.PHONY:clean
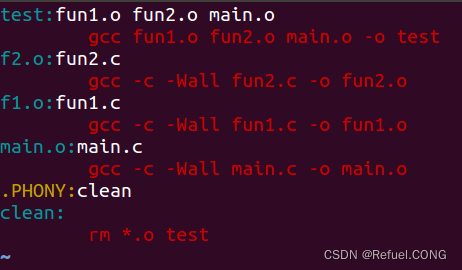 这样就不会被重名耽误运行了
这样就不会被重名耽误运行了 清空目标文件的规则每个Makefile中都应该写一个清空目标文件(.o和执行文件)的规则,这不仅便于重编译,也很利于保持文件的清洁。一般的风格都是:
清空目标文件的规则每个Makefile中都应该写一个清空目标文件(.o和执行文件)的规则,这不仅便于重编译,也很利于保持文件的清洁。一般的风格都是:
clean:
rmedit$(objects)
更为稳健的做法是:
.PHONY:clean
clean:
-rmedit$(objects)
前面说过,.PHONY意思表示clean是一个“伪目标”,。而在rm命令前面加了一个小减号的意思就是,也许某些文件出现问题,但不要管,继续做后面的事。 当然,clean的规则不要放在文件的开头,不然,这就会变成make的默认目标,相信谁也不愿意这样。不成文的规矩是——“clean从来都是放在文件的最后”。
3.makefile文件中的依赖关系理解
假设当前工程目录为object/,该目录下有6个文件,分别是:main.c、abc.c、xyz.c、abc.h、xyz.h和Makefile。其中main.c包含头文件abc.h和xyz.h,abc.c包含头文件abc.h,xyz.c包含头文件xyz.h,而abc.h又包含了xyz.h。它们的依赖关系如图。Makefile应该写成这个样子(假设生成目标main):
main:main.oabc.oxyz.o
gccmain.oabc.oxyz.o-omain
main.o:main.cabc.hxyz.h
gcc-cmain.c–omain.o-g
abc.o:abc.cabc.hxyz.h
gcc-cabc.c–oabc.o-g
xyz.o:xyz.cxyz.h
gcc-cxyz.c-oxyz.o-g
.PHONY:clean
clean:
rmmainmain.oabc.oxyz.o-f
4. 创建和使用变量
为了makefile的易维护,在makefile中我们可以使用变量。makefile的变量也就是一个字符串,理解成C语言中的宏可能会更好。
上面makefile例子:
test:fun1.ofun2.omain.o
gccfun1.ofun2.omain.o-otest
fun2.o:fun2.c
gcc-c-Wallfun2.c-ofun2.o
fun1.o:fun1.c
gcc-c-Wallfun1.c-ofun1.o
main.o:main.c
gcc-c-Wallmain.c-omain.o
.PHONY:clean
clean
rm*.otest
比如,我们声明一个变量,叫objects,能够表示obj文件就行了。我们在makefile一开始就这样定义:
objects=fun1.ofun2.omain.o
于是,我们就可以很方便地在我们的makefile中以“**$(objects)**”的方式来使用这个变量了,于是我们的改良版makefile就变成下面这个样子:
objects=fun1.ofun2.omain.o
test:$(objects)
gccfun1.ofun2.omain.o-otest
fun2.o:fun2.c
gcc-c-Wallfun2.c-ofun2.o
fun1.o:fun1.c
gcc-c-Wallfun1.c-ofun1.o
main.o:main.c
gcc-c-Wallmain.c-omain.
.PHONY:clean
clean
rm*.otest
于是如果有新的 .o 文件加入,我们只需简单地修改一下 objects 变量就可以了
我们简单的总结一下:
2.1 创建变量的目的:
用来代替一个文本字符串:
- 系列文件的名字
- 传递给编译器的参数
- 需要运行的程序
- 需要查找源代码的目录
- 你需要输出信息的目录
- 你想做的其它事情。
2.2 如何定义变量:
变量定义的两种方式
- 递归展开方式
VAR=var- 简单方式
VAR:=var- 变量使用
$(VAR)=========================- 用 ” $ ” 来表示
- 类似于编程语言中的宏
我们再来举一个例子:
sunq:kang.oyul.o
gcckang.oyul.o-osunq
kang.o:kang.ckang.h
gcc-Wall-O-g-ckang.c-okang.o
yul.o:yul.cyul.h
gcc-Wall-O-g-cyul.c-oyul.o
.PHONY:clean
clean
rm*.otest
用变量来替换:
OBJS=kang.oyul.o
CC=gcc
CFLAGS=-Wall-O-g
sunq:$(OBJS)
$(CC)$(OBJS)-osunq
kang.o:kang.ckang.h
$(CC)$(CFLAGS)-ckang.c-okang.o
yul.o:yul.cyul.h
$(CC)$(CFLAGS)-cyul.c-oyul.o
.PHONY:clean
clean
rm*.otest
-
递归展开方式
VAR=var例子:
foo=$(bar)
bar=$(ugh)
ugh=Huh?
(foo)来进行查看
优点: 它可以向后引用变量缺点: 不能对该变量进行任何扩展,
例如CFLAGS = $(CFLAGS)-0会造成死循环
-
简单方式
VAR:=var
m:=mm
x:=$(m)
y:=$(x)bar
x:=later
echo$(x)$(y)
如:m变量的值为mm ,m的值赋给给x
(这个变量的方式更像是c语言)
==用?=定义变量==
dir:=/foo/bar
FOO?=bar
FOO是?
?含义是,如果FOO没有被定义过,那么变量FO0的值就是“bar”,如果FOO先前被定义过,那么这条语将什么也不做,其等价于:
ifeq($(originFOO),undefined)
FOO=bar
endif
- 为变量添加值
你可以通过 += 为已定义的变量添加新的值
Main=hello.ohello-1.o
Main+=hello-2.o
- 预定义变量
| -AR | 库文件维护程序的名称,默认值为ar。AS汇编程序的名称默认值为as。 |
| -CC | C编译器的名称,默认值为cc。CPPC预编译器的名称,默认值 为$(CC) -E。 |
| -CXX | C++编译器的名称,默认值为g++。 |
| -FC | FORTRAN编译器的名称,默认值为 f77 |
| -RM | 文件删除程序的名称,默认值为rm -f |
- 自动变量
| - $* | 不包含扩展名的目标文件名称 |
| -$+ | 所有的依赖文件,以空格分开,并以出现的先后为序,可能包含重复的依赖文件 |
| -$< | 第一个依赖文件的名称 |
| -$? | 所有时间戳比目标文件晚的的依赖文件,并以空格分开 |
| -$@ | 目标文件的完整名称 |
| -$^ | 所有不重复的目标依赖文件,以空格分开 |
| -$% | 如果目标是归档成员,则该变量表示目标的归档成员名称 |
**
$@:目标文件,$^: 所有的依赖文件,$<:第一个依赖文件**。这三个变量十分常见且重要
objects=fun1.ofun2.omain.o
test:$(objects)
gccfun1.ofun2.omain.o-otest
fun2.o:fun2.c
gcc-c-Wallfun2.c-ofun2.o
fun1.o:fun1.c
gcc-c-Wallfun1.c-ofun1.o
main.o:main.c
gcc-c-Wallmain.c-omain.o
.PHONY:clean
clean
rm*.otest
变量修改:
objects=fun1.ofun2.omain.o
CFLAGS=-c-Wall
test:$(objects)
gcc$(objects)-otest
fun2.o:$<
gcc $(CFLAGS) fun2.c -o $@
fun1.o:$<
gcc $(CFLAGS) fun1.c -o $@
main.o:$<
gcc $(CFLAGS) main.c -o $@
.PHONY:clean
clean
rm *.o test
环境变量
- make在启动时会自动读取系统当前已经定义了的环境变量,并且会创建与之具有相同名称和数值的变量
- 如果用户在Makefile中定义了相同名称的变量,那么用户自定义变量将会覆盖同名的环境变量
==直接运行make选项==
| -C | dir读入指定目录下的Makefile |
| -f | file读入当前目录下的file文件作为Makefile |
| -i | 忽略所有的命令执行错误 |
| -I | dir指定被包含的Makefile所在目录 |
| -n | 只打印要执行的命令,但不执行这些命令 |
| -p | 显示make变量数据库和隐含规则 |
| -s | 在执行命令时不显示命令 |
| -w | 如果make在执行过程中改变目录,打印当前目录名 |
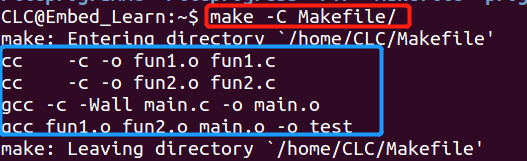
-C :dir读入指定目录下的Makefile
make -C Makefile/文件下的makefile

-f :file 读入当前目录下的file文件作为Makefile
c make -f Refuel.debugmake -f Refuel.debug clean就可以把Refuel.debug当作Makefile来用
-i :忽略所有的命令执行错误
假如我们在写代码时候,gcc -c -Wall fun2.c o $@写-o忘记了-这种时候,我们make -i,它会把小错误先忽略,把代码中能正常执行的先执行,错误的提示出来,不执行
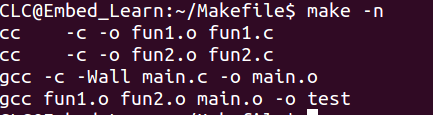
-n :只打印要执行的命令,但不执行这些命令 不是真的执行了命令,而是像模拟了执行命令
在U-Boot中我们会看到一些内核的Makefile, 如 config.mk 这样的文件中罗列了一些变量的声明
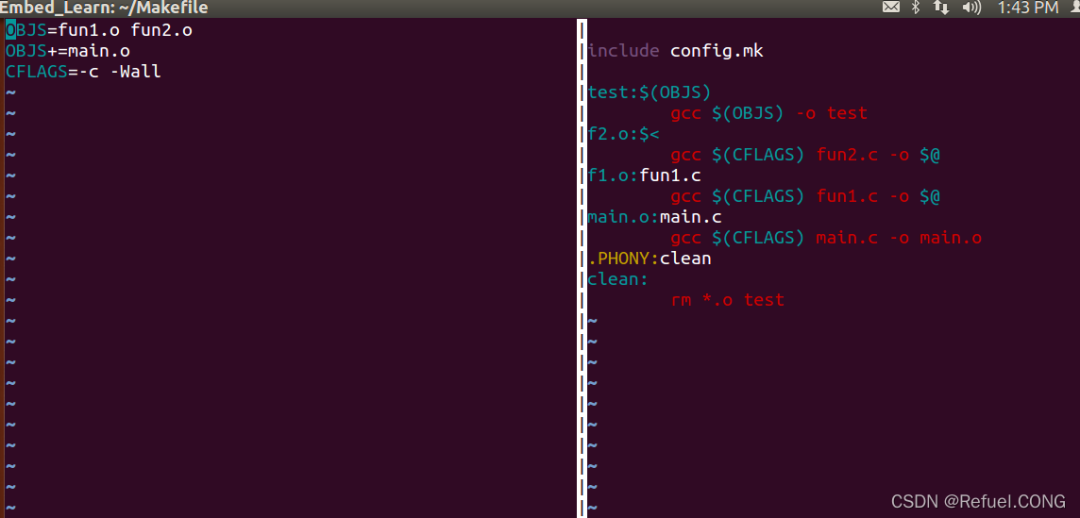
5. Makefile的隐含规则
- ==隐含规则1:==编译C程序的隐含规则——让make自动推导
它可以自动推导文件以及文件依赖关系后面的命令,于是我们就没必要去在每一个[.o]文件后都写上类似的命令,因为,我们的make会自动识别,并自己推导命令。只要make看到一个[.o]文件,它就会自动的把[.c]文件加在依赖关系中,如果make找到一个whatever.o,那么whatever.c,就会是whatever.o的依赖文件。并且 cc -c whatever.c 也会被推导出来,于是,我们的makefile再也不用写得这么复杂。
objects=fun1.ofun2.omain.o
test:$(objects)
gcc$(objects)-otest
fun2.o:fun2.c
fun1.o:fun1.c
main.o:main.c
.PHONY:clean
clean
rm*.otest
这种方法,也就是make的“隐晦规则”。上面文件内容中,“.PHONY”表示,clean是个伪目标文件。
总结:“$(CC) -c $(CPPFLAGS) $(CFLAGS)**”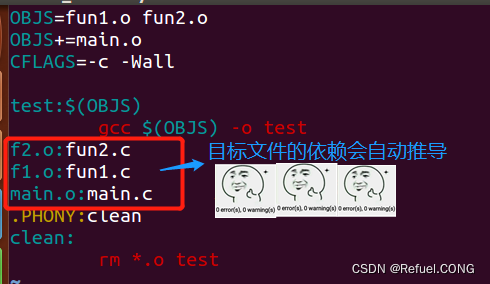
- 隐含规则2:链接0bject文件的隐含规则
“$(CC)$(LDFLAGS) $(LOADLIBES)$(LDLIBS)”。这个规则对于只有一个源文件的工程有效,同时也对多个 Object文件(由不同的源文件生成)的也有效。例如如下
规则:x : x.o y.o z.o并且“ x.c ”、“ y.c ”和 “ z.c ” 都存在时,隐含规则将执行如下命令:
cc -c x.c -o x.occ -c y.c -o y.occ -c z.c -o z.occ x.o y.o z.o -o x
如果没有一个源文件(如上例中的x.c)和你的目标名字(如上例中的x)相关联,那么,你最好写出自己的生成规则,不然,隐含规则会报错的
fun1:fun1.ofun2.omain.o
这样就不会报错。
Makefile 总述
Makefile里主要包含了五个东西:显式规则、隐晦规则、变量定义、文件指示和注释。
显式规则。显式规则说明了,如何生成一个或多的的目标文件。这是由Makefile的书写者明显指出,要生成的文件,文件的依赖文件,生成的命令。
隐晦规则。由于我们的make有自动推导的功能,所以隐晦的规则可以让我们比较粗糙地简略地书写Makefile,这是由make所支持的。
变量的定义。在Makefile中我们要定义一系列的变量,变量一般都是字符串,这个有点你C语言中的宏,当Makefile被执行时,其中的变量都会被扩展到相应的引用位置上。
文件指示。其包括了三个部分,一个是在一个Makefile中引用另一个Makefile,就像C语言中的include一样;另一个是指根据某些情况指定Makefile中的有效部分,就像C语言中的预编译#if一样;还有就是定义一个多行的命令。有关这一部分的内容,我会在后续的部分中讲述。
注释。Makefile中只有行注释,和UNIX的Shell脚本一样,其注释是用“#”字符,这个就像C/C++中的“//”一样。如果你要在你的Makefile中使用“#”字符,可以用反斜框进行转义,如:“#”。
VPATH的用法
1. Makefile的 VPATH
VPATH: 虚路径
-
在一些大的工程中,有大量的源文件,我们通常的做法是把这许多的源文件分类,并存放在==不同的目录中==。所以,当make需要去找寻文件的依赖关系时,你可以在文件前加上路径,但 ==最好的方法是把一个路径告诉make,让make在自动去找==。
-
Makefile文件中的特殊变量“VPATH”就是完成这个功能的,如果没有指明这个变量,make只会在当前的目录中去找寻依赖文件和目标文件。如果定义了这个变量,那么,make就会在当当前目录找不到的情况下,到所指定的目录中去找寻文件了。
-
VPATH = src:../headers -
上面的的定义指定两个目录,“src”和“../headers”,make会按照这个顺序进行搜索。目录由“冒号”分隔。(当然,当前目录永远是最高优先搜索的地方)
另一个设置文件搜索路径的方法是使用make的“vpath”关键字(注意,它是全小写的),这不是变量,这是一个make的关键字,这和上面提到的那个VPATH变量很类似,但是它更为灵活。它可以指定不同的文件在不同的搜索目录中。这是一个很灵活的功能。它的使用方法有三种:
1.vpath< pattern>< directories>
//为符合模式< pattern>的文件指定搜索目录。
2.vpath< pattern>
//清除符合模式< pattern>的文件的搜索目录。
3.vpath
//清除所有已被设置好了的文件搜索目录。
vapth使用方法中的< pattern>需要包含“%”字符。“%”的意思是匹配零或若干字符,例如,“%.h”表示所有以“.h”结尾的文件。< pattern>指定了要搜索的文件集,而< directories>则指定了的文件集的搜索的目录。例如:
vpath%.h../headers
该语句表示,要求make在“../headers”目录下搜索所有以“.h”结尾的文件。(如果某文件在当前目录没有找到的话)
我们可以连续地使用vpath语句,以指定不同搜索策略。如果连续的vpath语句中出现了相同的< pattern>,或是被重复了的< pattern>,那么,make会按照vpath语句的先后顺序来执行搜索。如:
vpath %.c foo
vpath % blish
vpath %.c bar
其表示“.c”结尾的文件,先在“foo”目录,然后是“blish”,最后是“bar”目录。
vpath %.c foo:bar
vpath % blish而上面的语句则表示“.c”结尾的文件,先在“foo”目录,然后是“bar”目录,最后才是“blish”目录。
分布不同路径的程序。在不同的目录下写了程序,如果不用VPATH如何去写makefile呢?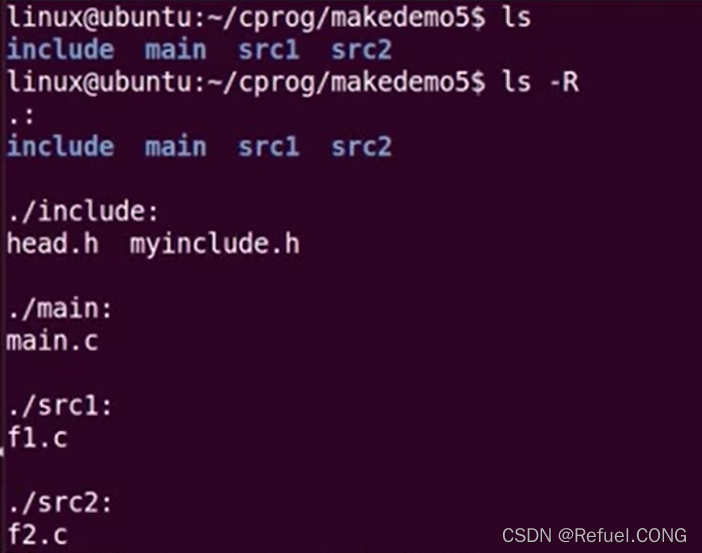
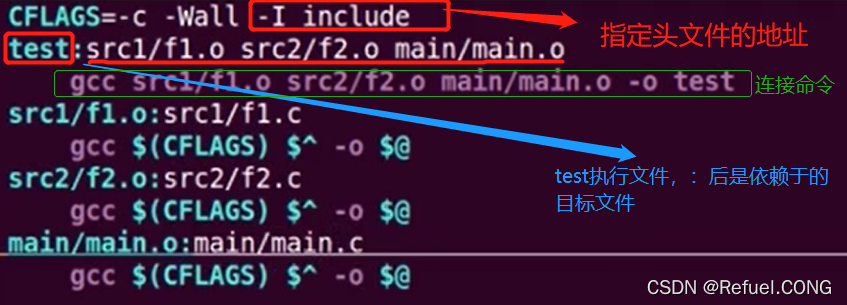 在这里插入图片描述
在这里插入图片描述
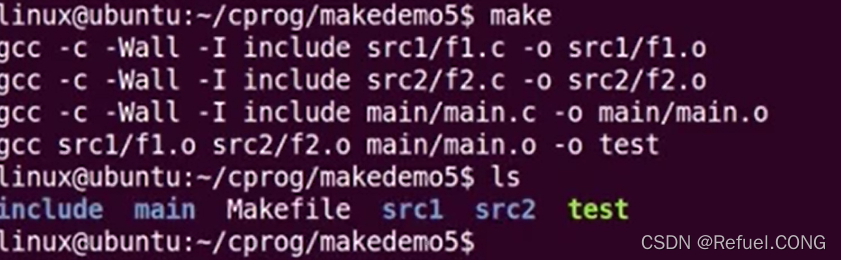
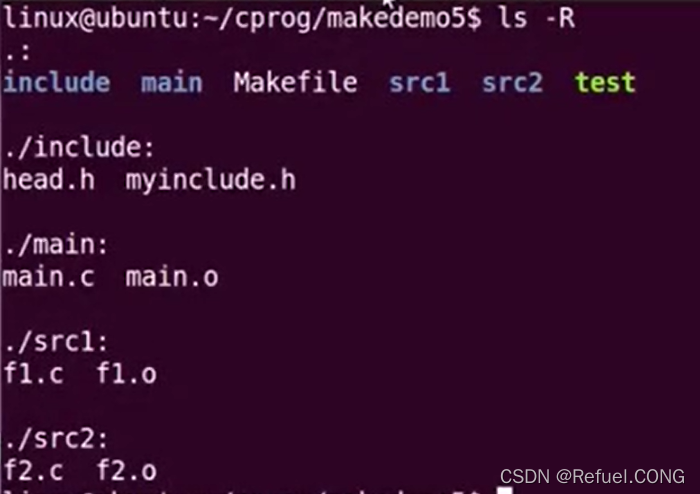 ==不同文件我们怎么删除不想要的中间文件呢?==通过指令:
==不同文件我们怎么删除不想要的中间文件呢?==通过指令:find ./ -name "*.o",找到所有.o的文件我们输入指令:find ./ -name "*.o" -exec rm {} ;,意思为,我把找到的结果拿来给rm去删除,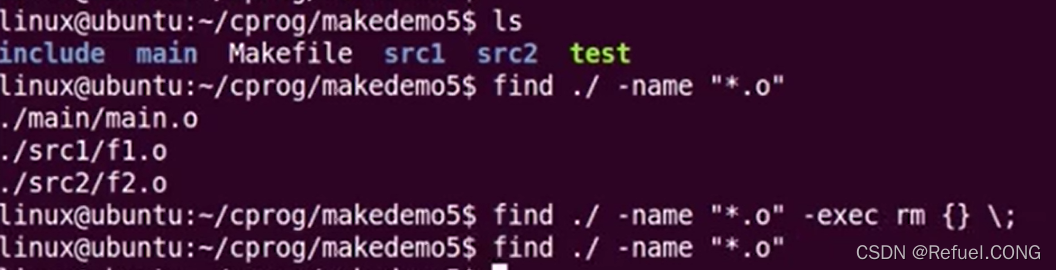 这样.o文件就在不同的目录下删除了
这样.o文件就在不同的目录下删除了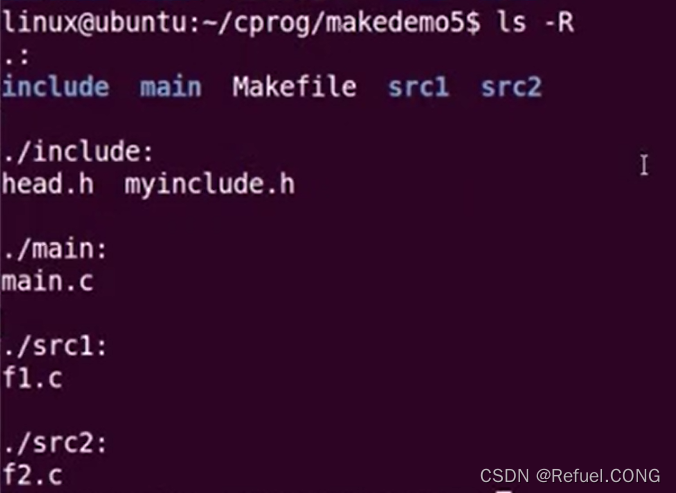
2. Makefile 中 VPATH使用


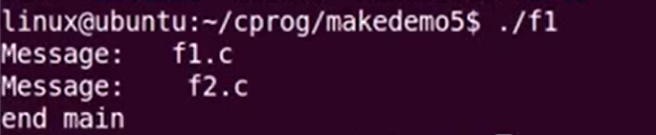
嵌套的Makefile
每个文件都一个自己的makefile,makefile互相调用子makefile案例:
我们看到有许多目录和外部makefile,在每个目录下有.c程序和子makefile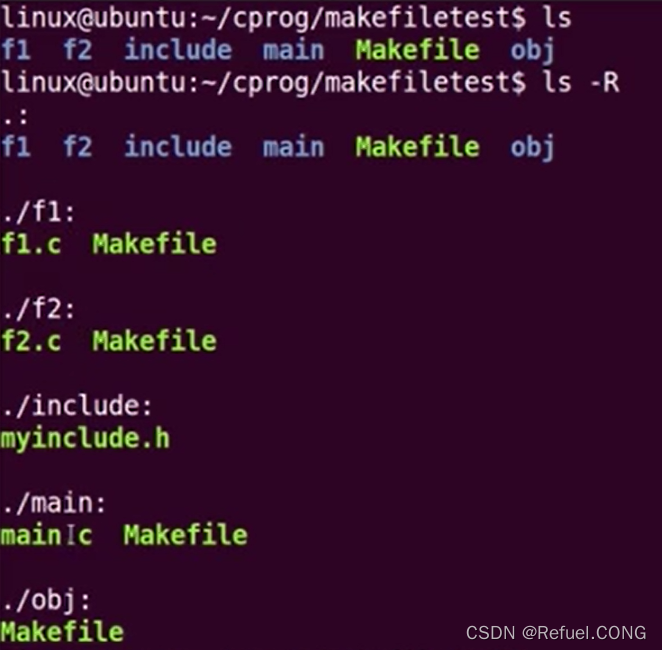 在第一个目录f1中的子makefile是把f1.c 生成为f1.o放到了OBJS_DIR obj中
在第一个目录f1中的子makefile是把f1.c 生成为f1.o放到了OBJS_DIR obj中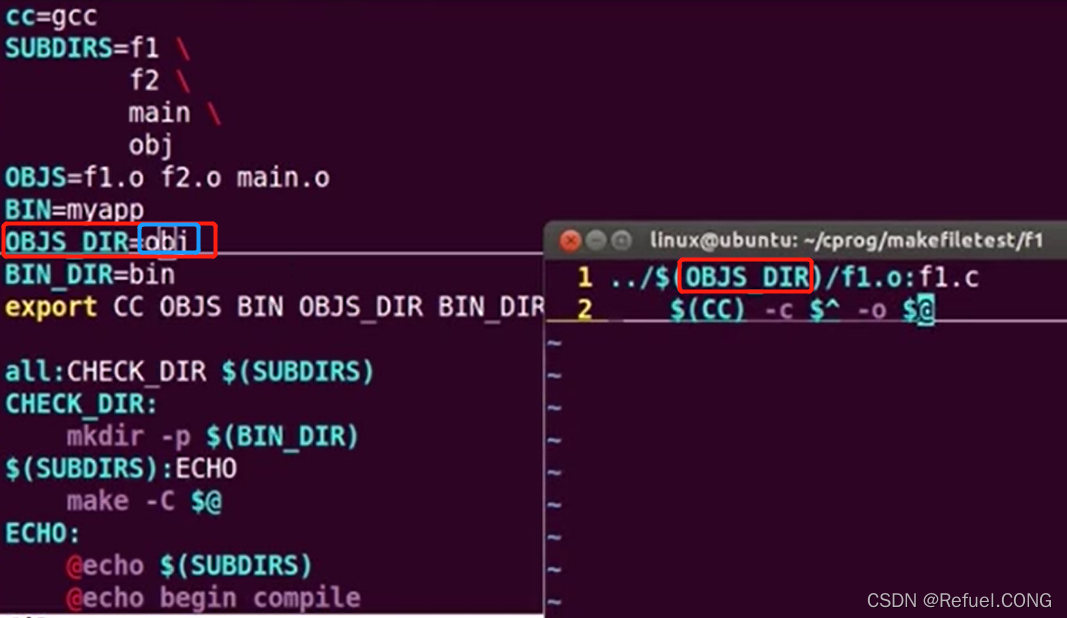
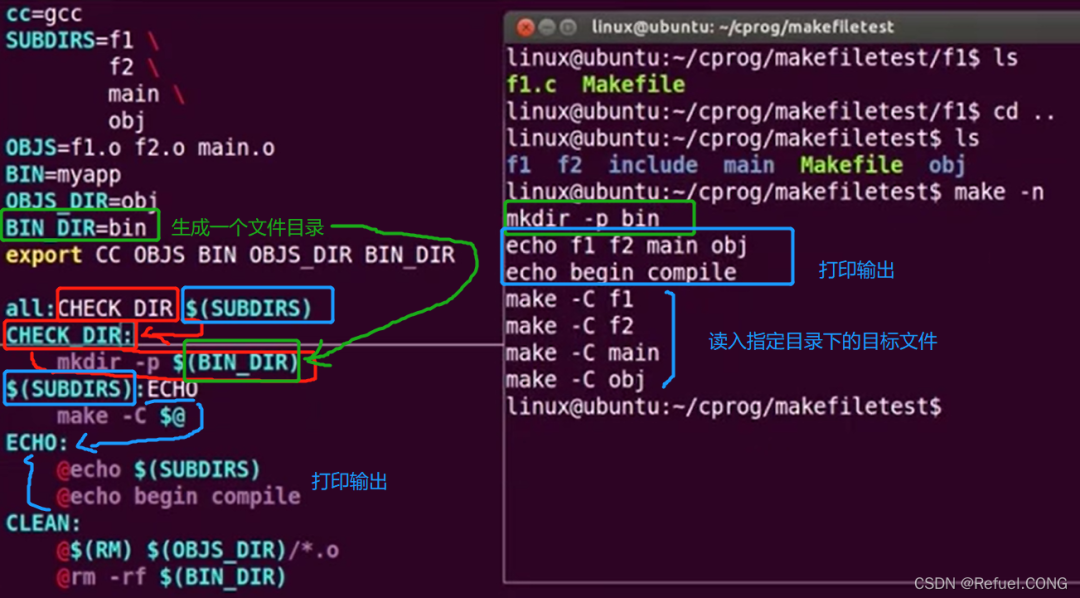
-
我们注意到有一句@echo $(SUBDIRS)
-
@(RM)并不是我们自己定义的变量,那它是从哪里来的呢? 就是make -f
-
make -C $@
-
export CC OBJS BIN OBJS_DIR BIN_DIR :是让子makefile也可以调用
审核编辑 :李倩
-
操作系统
+关注
关注
37文章
6905浏览量
123871 -
编译
+关注
关注
0文章
663浏览量
33090 -
Makefile
+关注
关注
1文章
125浏览量
19230
原文标题:Linux C基础——” Makefile “ 文件管理大师你拜访过嘛?
文章出处:【微信号:yikoulinux,微信公众号:一口Linux】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
嵌入式学习-飞凌嵌入式ElfBoard ELF 1板卡-Linux内核移植之Makefile介绍
飞凌嵌入式ElfBoard ELF 1板卡-Linux内核移植之Makefile介绍
Lua语法基础教程(下篇)
Lua语法基础教程(中篇)
stm32cubmx生成的makefile编译无法启动线程怎么解决?
关于Makefile自动生成-autotools的使用

FPGA学习笔记---基本语法
如何在esp-idf的开发环境中编译外部应用工程?
STM32CubeMX生成的makefile如何更改程序烧录地址?
快来用Makefile管理工程,提高工作效率!






 工商网监
工商网监
评论