 一道非常经典的回溯算法问题:子集划分问题
一道非常经典的回溯算法问题:子集划分问题
我经常说回溯算法是笔试中最好用的算法,只要你没什么思路,就用回溯算法暴力求解,即便不能通过所有测试用例,多少能过一点。
回溯算法的技巧也不难,回溯算法就是穷举一棵决策树的过程,只要在递归之前「做选择」,在递归之后「撤销选择」就行了。
但是,就算暴力穷举,不同的思路也有优劣之分。
本文就来看一道非常经典的回溯算法问题:子集划分问题。这道题可以帮你更深刻理解回溯算法的思维,得心应手地写出回溯函数。
题目非常简单:
给你输入一个数组nums和一个正整数k,请你判断nums是否能够被平分为元素和相同的k个子集。
函数签名如下:
booleancanPartitionKSubsets(int[]nums,intk);
我们之前背包问题之子集划分写过一次子集划分问题,不过那道题只需要我们把集合划分成两个相等的集合,可以转化成背包问题用动态规划技巧解决。
但是如果划分成多个相等的集合,解法一般只能通过暴力穷举,时间复杂度爆表,是练习回溯算法和递归思维的好机会。
一、思路分析
首先,我们回顾一下以前学过的排列组合知识:
1、P(n, k)(也有很多书写成A(n, k))表示从n个不同元素中拿出k个元素的排列(Permutation/Arrangement)总数;C(n, k)表示从n个不同元素中拿出k个元素的组合(Combination)总数。
2、「排列」和「组合」的主要区别在于是否考虑顺序的差异。
3、排列、组合总数的计算公式:
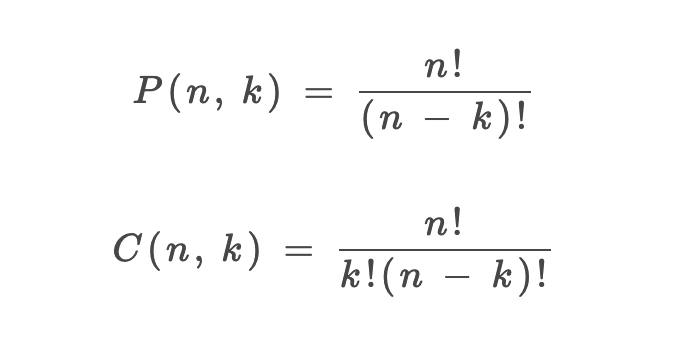
好,现在我问一个问题,这个排列公式P(n, k)是如何推导出来的?为了搞清楚这个问题,我需要讲一点组合数学的知识。
排列组合问题的各种变体都可以抽象成「球盒模型」,P(n, k)就可以抽象成下面这个场景:
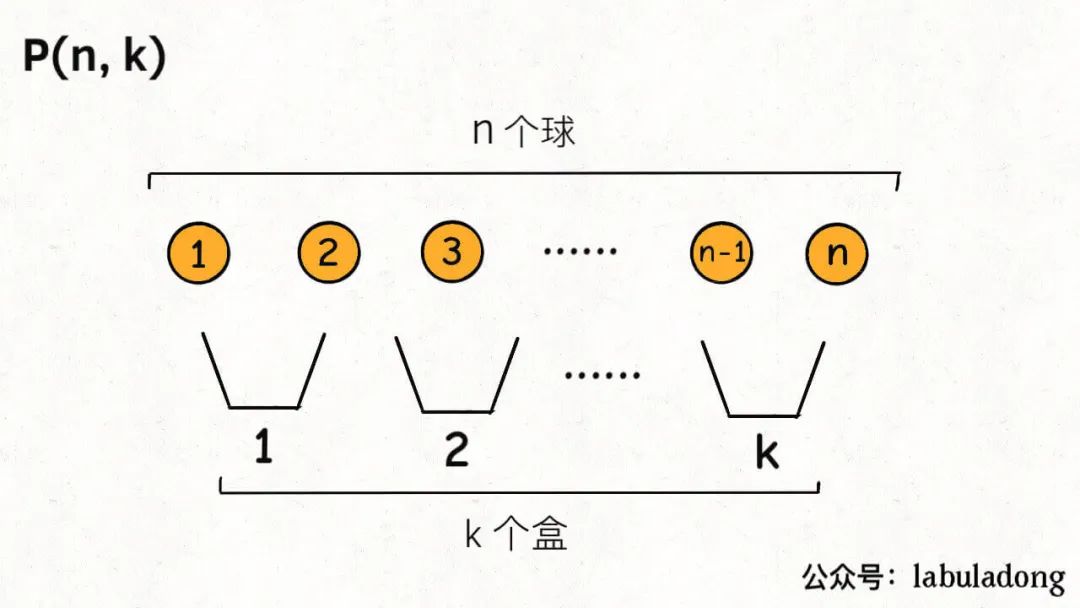
即,将n个标记了不同序号的球(标号为了体现顺序的差异),放入k个标记了不同序号的盒子中(其中n >= k,每个盒子最终都装有恰好一个球),共有P(n, k)种不同的方法。
现在你来,往盒子里放球,你怎么放?其实有两种视角。
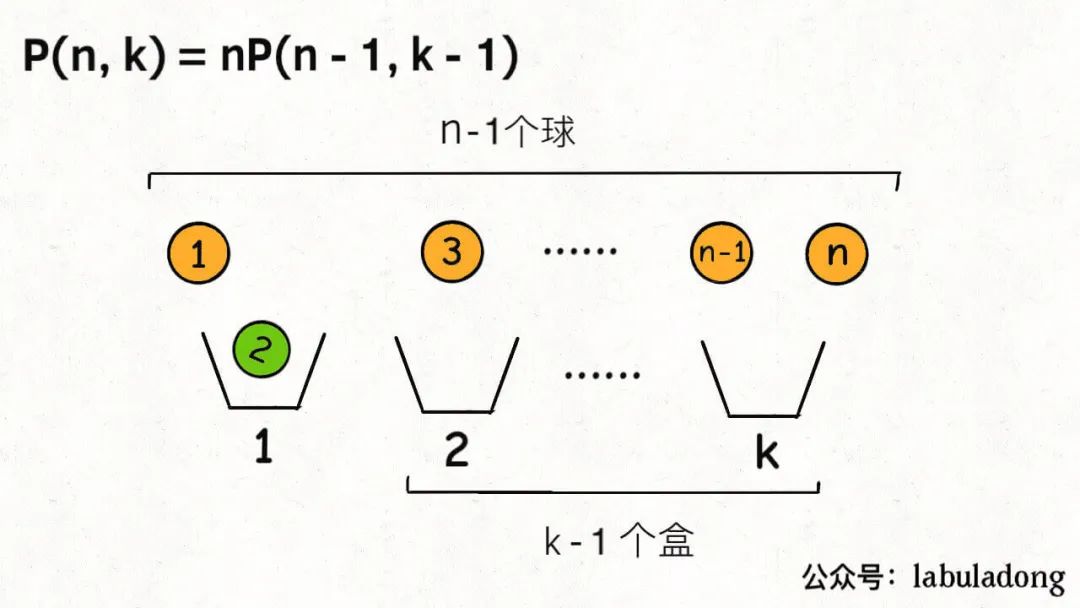
首先,你可以站在盒子的视角,每个盒子必然要选择一个球。
这样,第一个盒子可以选择n个球中的任意一个,然后你需要让剩下k - 1个盒子在n - 1个球中选择:
另外,你也可以站在球的视角,因为并不是每个球都会被装进盒子,所以球的视角分两种情况:
1、第一个球可以不装进任何一个盒子,这样的话你就需要将剩下n - 1个球放入k个盒子。
2、第一个球可以装进k个盒子中的任意一个,这样的话你就需要将剩下n - 1个球放入k - 1个盒子。
结合上述两种情况,可以得到:
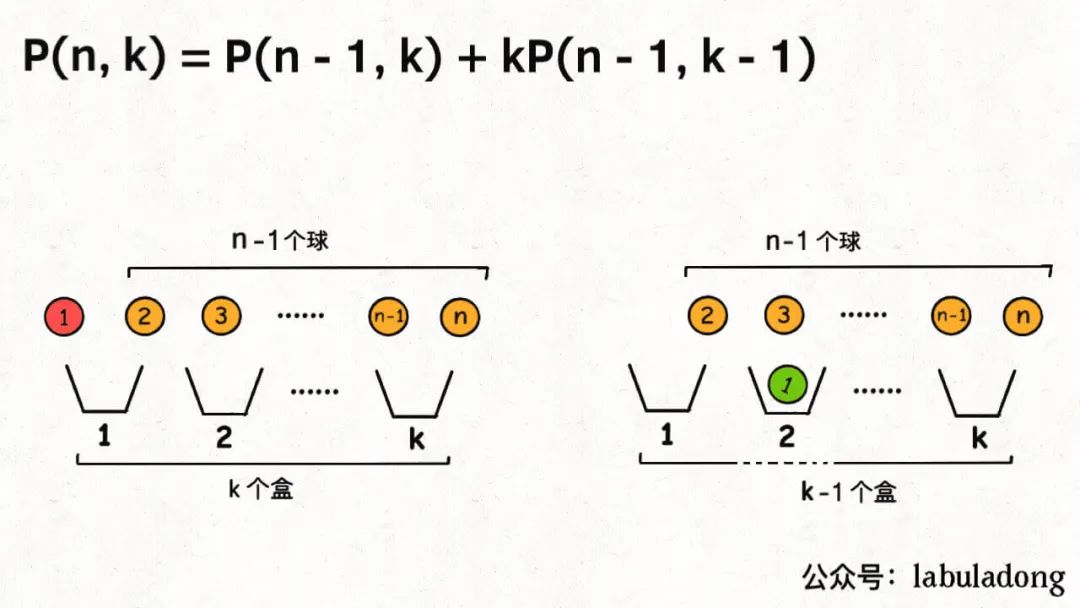
你看,两种视角得到两个不同的递归式,但这两个递归式解开的结果都是我们熟知的阶乘形式:
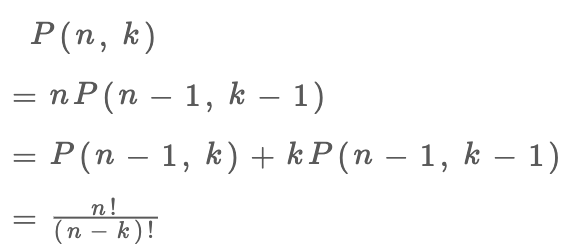
至于如何解递归式,涉及数学的内容比较多,这里就不做深入探讨了,有兴趣的读者可以自行学习组合数学相关知识。
回到正题,这道算法题让我们求子集划分,子集问题和排列组合问题有所区别,但我们可以借鉴「球盒模型」的抽象,用两种不同的视角来解决这道子集划分问题。
把装有n个数字的数组nums分成k个和相同的集合,你可以想象将n个数字分配到k个「桶」里,最后这k个「桶」里的数字之和要相同。
前文回溯算法框架套路说过,回溯算法的关键在哪里?
关键是要知道怎么「做选择」,这样才能利用递归函数进行穷举。
那么模仿排列公式的推导思路,将n个数字分配到k个桶里,我们也可以有两种视角:
视角一,如果我们切换到这n个数字的视角,每个数字都要选择进入到k个桶中的某一个。
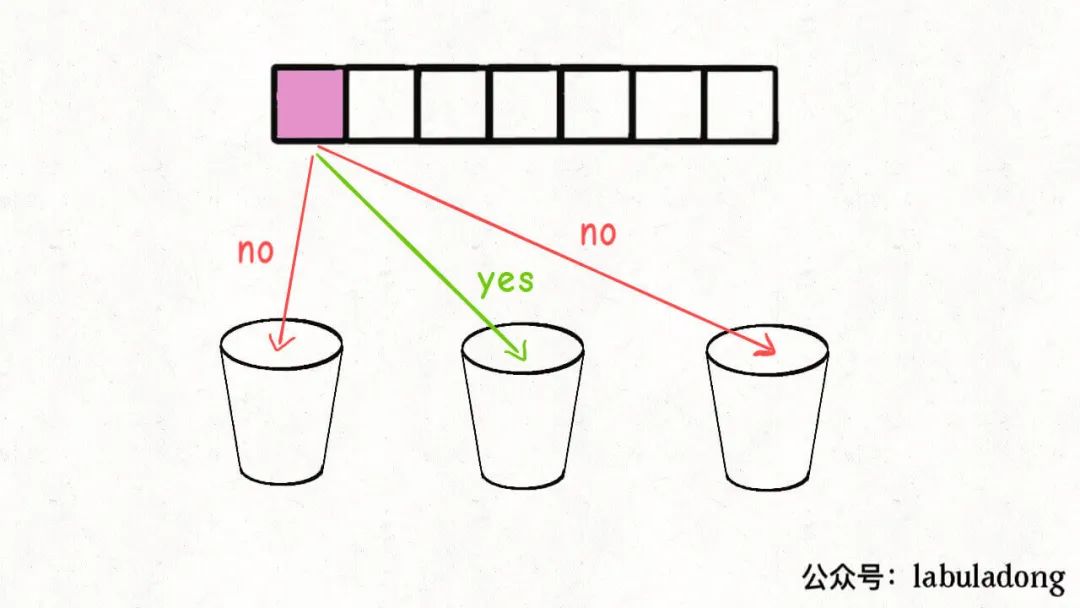
视角二,如果我们切换到这k个桶的视角,对于每个桶,都要遍历nums中的n个数字,然后选择是否将当前遍历到的数字装进自己这个桶里。
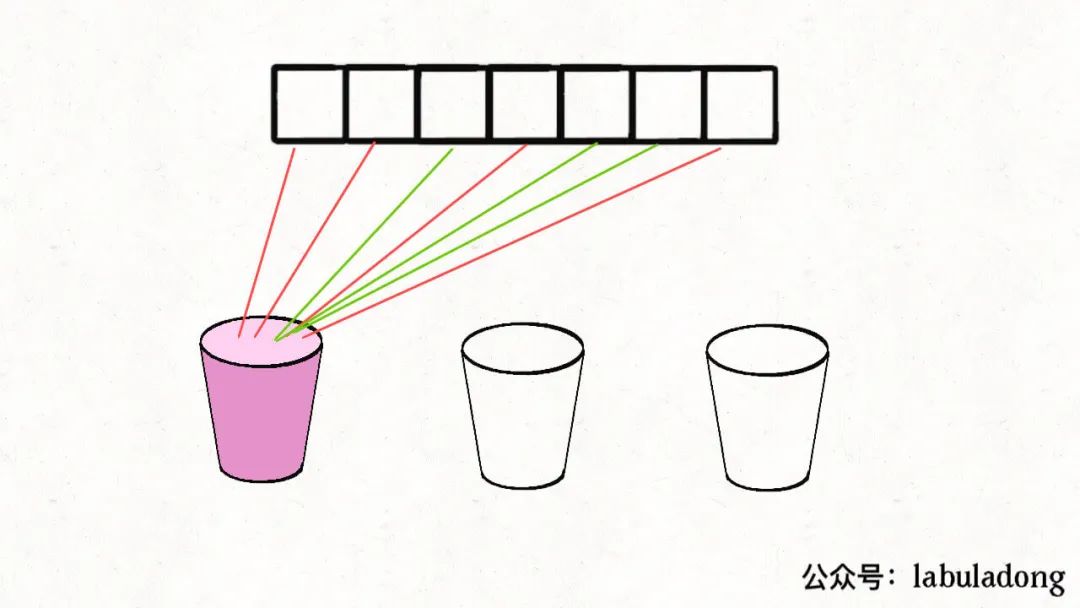
你可能问,这两种视角有什么不同?
用不同的视角进行穷举,虽然结果相同,但是解法代码的逻辑完全不同,进而算法的效率也会不同;对比不同的穷举视角,可以帮你更深刻地理解回溯算法,我们慢慢道来。
二、以数字的视角
用 for 循环迭代遍历nums数组大家肯定都会:
for(intindex=0;index< nums.length; index++) {
System.out.println(nums[index]);
}
递归遍历数组你会不会?其实也很简单:
voidtraverse(int[]nums,intindex){
if(index==nums.length){
return;
}
System.out.println(nums[index]);
traverse(nums,index+1);
}
只要调用traverse(nums, 0),和 for 循环的效果是完全一样的。
那么回到这道题,以数字的视角,选择k个桶,用 for 循环写出来是下面这样:
//k个桶(集合),记录每个桶装的数字之和
int[]bucket=newint[k];
//穷举nums中的每个数字
for(intindex=0;index< nums.length; index++) {
//穷举每个桶
for(inti=0;i< k; i++) {
//nums[index]选择是否要进入第i个桶
//...
}
}
如果改成递归的形式,就是下面这段代码逻辑:
//k个桶(集合),记录每个桶装的数字之和
int[]bucket=newint[k];
//穷举nums中的每个数字
voidbacktrack(int[]nums,intindex){
//basecase
if(index==nums.length){
return;
}
//穷举每个桶
for(inti=0;i< bucket.length; i++) {
//选择装进第i个桶
bucket[i]+=nums[index];
//递归穷举下一个数字的选择
backtrack(nums,index+1);
//撤销选择
bucket[i]-=nums[index];
}
}
虽然上述代码仅仅是穷举逻辑,还不能解决我们的问题,但是只要略加完善即可:
//主函数
booleancanPartitionKSubsets(int[]nums,intk){
//排除一些基本情况
if(k>nums.length)returnfalse;
intsum=0;
for(intv:nums)sum+=v;
if(sum%k!=0)returnfalse;
//k个桶(集合),记录每个桶装的数字之和
int[]bucket=newint[k];
//理论上每个桶(集合)中数字的和
inttarget=sum/k;
//穷举,看看nums是否能划分成k个和为target的子集
returnbacktrack(nums,0,bucket,target);
}
//递归穷举nums中的每个数字
booleanbacktrack(
int[]nums,intindex,int[]bucket,inttarget){
if(index==nums.length){
//检查所有桶的数字之和是否都是target
for(inti=0;i< bucket.length; i++) {
if(bucket[i]!=target){
returnfalse;
}
}
//nums成功平分成k个子集
returntrue;
}
//穷举nums[index]可能装入的桶
for(inti=0;i< bucket.length; i++) {
//剪枝,桶装装满了
if(bucket[i]+nums[index]>target){
continue;
}
//将nums[index]装入bucket[i]
bucket[i]+=nums[index];
//递归穷举下一个数字的选择
if(backtrack(nums,index+1,bucket,target)){
returntrue;
}
//撤销选择
bucket[i]-=nums[index];
}
//nums[index]装入哪个桶都不行
returnfalse;
}
有之前的铺垫,相信这段代码是比较容易理解的。这个解法虽然能够通过,但是耗时比较多,其实我们可以再做一个优化。
主要看backtrack函数的递归部分:
for(inti=0;i< bucket.length; i++) {
//剪枝
if(bucket[i]+nums[index]>target){
continue;
}
if(backtrack(nums,index+1,bucket,target)){
returntrue;
}
}
如果我们让尽可能多的情况命中剪枝的那个 if 分支,就可以减少递归调用的次数,一定程度上减少时间复杂度。
如何尽可能多的命中这个 if 分支呢?要知道我们的index参数是从 0 开始递增的,也就是递归地从 0 开始遍历nums数组。
如果我们提前对nums数组排序,把大的数字排在前面,那么大的数字会先被分配到bucket中,对于之后的数字,bucket[i] + nums[index]会更大,更容易触发剪枝的 if 条件。
所以可以在之前的代码中再添加一些代码:
booleancanPartitionKSubsets(int[]nums,intk){
//其他代码不变
//...
/*降序排序nums数组*/
Arrays.sort(nums);
for(i=0,j=nums.length-1;i< j; i++, j--) {
//交换nums[i]和nums[j]
inttemp=nums[i];
nums[i]=nums[j];
nums[j]=temp;
}
/*******************/
returnbacktrack(nums,0,bucket,target);
}
由于 Java 的语言特性,这段代码通过先升序排序再反转,达到降序排列的目的。
三、以桶的视角
文章开头说了,以桶的视角进行穷举,每个桶需要遍历nums中的所有数字,决定是否把当前数字装进桶中;当装满一个桶之后,还要装下一个桶,直到所有桶都装满为止。
这个思路可以用下面这段代码表示出来:
//装满所有桶为止
while(k>0){
//记录当前桶中的数字之和
intbucket=0;
for(inti=0;i< nums.length; i++) {
//决定是否将nums[i]放入当前桶中
bucket+=nums[i]or0;
if(bucket==target){
//装满了一个桶,装下一个桶
k--;
break;
}
}
}
那么我们也可以把这个 while 循环改写成递归函数,不过比刚才略微复杂一些,首先写一个backtrack递归函数出来:
booleanbacktrack(intk,intbucket,
int[]nums,intstart,boolean[]used,inttarget);
不要被这么多参数吓到,我会一个个解释这些参数。如果你能够透彻理解本文,也能得心应手地写出这样的回溯函数。
这个backtrack函数的参数可以这样解释:
现在k号桶正在思考是否应该把nums[start]这个元素装进来;目前k号桶里面已经装的数字之和为bucket;used标志某一个元素是否已经被装到桶中;target是每个桶需要达成的目标和。
根据这个函数定义,可以这样调用backtrack函数:
booleancanPartitionKSubsets(int[]nums,intk){
//排除一些基本情况
if(k>nums.length)returnfalse;
intsum=0;
for(intv:nums)sum+=v;
if(sum%k!=0)returnfalse;
boolean[]used=newboolean[nums.length];
inttarget=sum/k;
//k号桶初始什么都没装,从nums[0]开始做选择
returnbacktrack(k,0,nums,0,used,target);
}
实现backtrack函数的逻辑之前,再重复一遍,从桶的视角:
1、需要遍历nums中所有数字,决定哪些数字需要装到当前桶中。
2、如果当前桶装满了(桶内数字和达到target),则让下一个桶开始执行第 1 步。
下面的代码就实现了这个逻辑:
booleanbacktrack(intk,intbucket,
int[]nums,intstart,boolean[]used,inttarget){
//basecase
if(k==0){
//所有桶都被装满了,而且nums一定全部用完了
//因为target==sum/k
returntrue;
}
if(bucket==target){
//装满了当前桶,递归穷举下一个桶的选择
//让下一个桶从nums[0]开始选数字
returnbacktrack(k-1,0,nums,0,used,target);
}
//从start开始向后探查有效的nums[i]装入当前桶
for(inti=start;i< nums.length; i++) {
//剪枝
if(used[i]){
//nums[i]已经被装入别的桶中
continue;
}
if(nums[i]+bucket>target){
//当前桶装不下nums[i]
continue;
}
//做选择,将nums[i]装入当前桶中
used[i]=true;
bucket+=nums[i];
//递归穷举下一个数字是否装入当前桶
if(backtrack(k,bucket,nums,i+1,used,target)){
returntrue;
}
//撤销选择
used[i]=false;
bucket-=nums[i];
}
//穷举了所有数字,都无法装满当前桶
returnfalse;
}
这段代码是可以得出正确答案的,但是效率很低,我们可以思考一下是否还有优化的空间。
首先,在这个解法中每个桶都可以认为是没有差异的,但是我们的回溯算法却会对它们区别对待,这里就会出现重复计算的情况。
什么意思呢?我们的回溯算法,说到底就是穷举所有可能的组合,然后看是否能找出和为target的k个桶(子集)。
那么,比如下面这种情况,target = 5,算法会在第一个桶里面装1, 4:
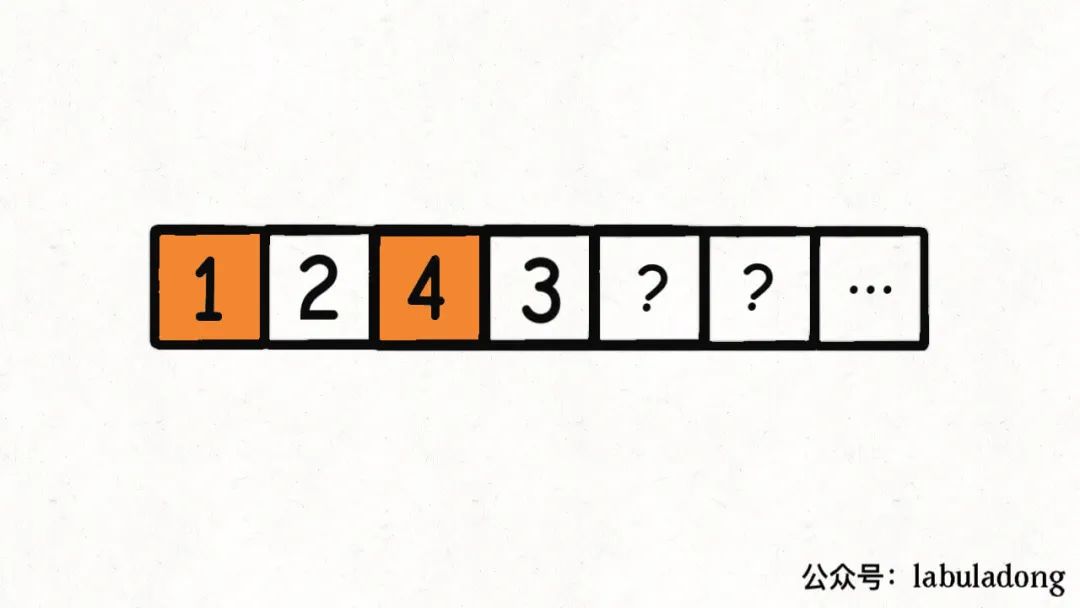
现在第一个桶装满了,就开始装第二个桶,算法会装入2, 3:
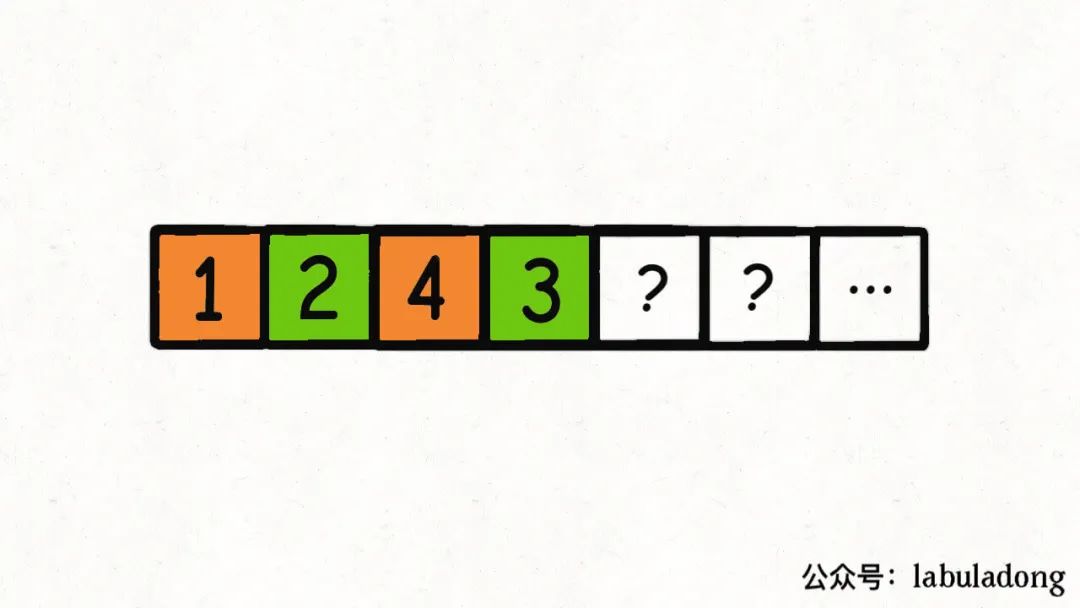
然后以此类推,对后面的元素进行穷举,凑出若干个和为 5 的桶(子集)。
但问题是,如果最后发现无法凑出和为target的k个子集,算法会怎么做?
回溯算法会回溯到第一个桶,重新开始穷举,现在它知道第一个桶里装1, 4是不可行的,它会尝试把2, 3装到第一个桶里:
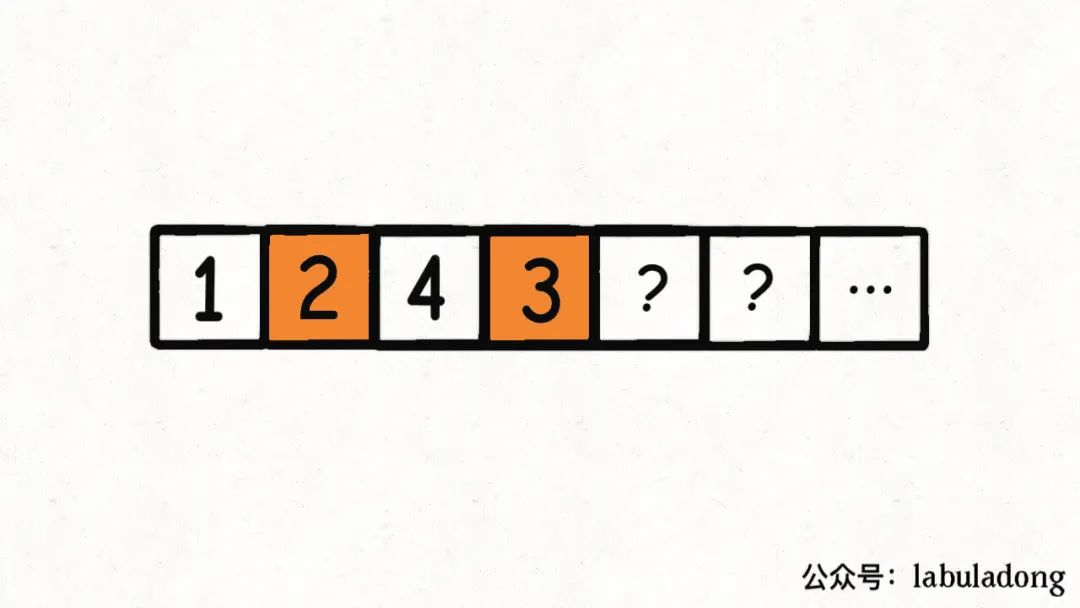
现在第一个桶装满了,就开始装第二个桶,算法会装入1, 4:
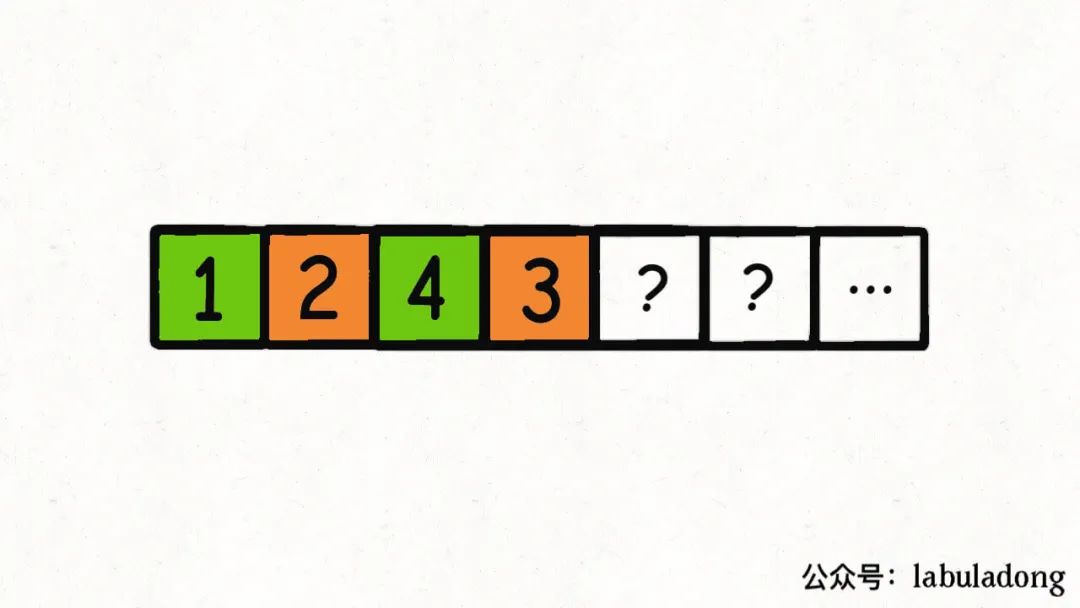
好,到这里你应该看出来问题了,这种情况其实和之前的那种情况是一样的。也就是说,到这里你其实已经知道不需要再穷举了,必然凑不出来和为target的k个子集。
但我们的算法还是会傻乎乎地继续穷举,因为在她看来,第一个桶和第二个桶里面装的元素不一样,那这就是两种不一样的情况呀。
那么我们怎么让算法的智商提高,识别出这种情况,避免冗余计算呢?
你注意这两种情况的used数组肯定长得一样,所以used数组可以认为是回溯过程中的「状态」。
所以,我们可以用一个memo备忘录,在装满一个桶时记录当前used的状态,如果当前used的状态是曾经出现过的,那就不用再继续穷举,从而起到剪枝避免冗余计算的作用。
有读者肯定会问,used是一个布尔数组,怎么作为键进行存储呢?这其实是小问题,比如我们可以把数组转化成字符串,这样就可以作为哈希表的键进行存储了。
看下代码实现,只要稍微改一下backtrack函数即可:
//备忘录,存储used数组的状态
HashMapmemo=newHashMap<>();
booleanbacktrack(intk,intbucket,int[]nums,intstart,boolean[]used,inttarget){
//basecase
if(k==0){
returntrue;
}
//将used的状态转化成形如[true,false,...]的字符串
//便于存入HashMap
Stringstate=Arrays.toString(used);
if(bucket==target){
//装满了当前桶,递归穷举下一个桶的选择
booleanres=backtrack(k-1,0,nums,0,used,target);
//将当前状态和结果存入备忘录
memo.put(state,res);
returnres;
}
if(memo.containsKey(state)){
//如果当前状态曾今计算过,就直接返回,不要再递归穷举了
returnmemo.get(state);
}
//其他逻辑不变...
}
这样提交解法,发现执行效率依然比较低,这次不是因为算法逻辑上的冗余计算,而是代码实现上的问题。
因为每次递归都要把used数组转化成字符串,这对于编程语言来说也是一个不小的消耗,所以我们还可以进一步优化。
注意题目给的数据规模nums.length <= 16,也就是说used数组最多也不会超过 16,那么我们完全可以用「位图」的技巧,用一个 int 类型的used变量来替代used数组。
具体来说,我们可以用整数used的第i位((used >> i) & 1)的 1/0 来表示used[i]的 true/false。
这样一来,不仅节约了空间,而且整数used也可以直接作为键存入 HashMap,省去数组转字符串的消耗。
看下最终的解法代码:
publicbooleancanPartitionKSubsets(int[]nums,intk){
//排除一些基本情况
if(k>nums.length)returnfalse;
intsum=0;
for(intv:nums)sum+=v;
if(sum%k!=0)returnfalse;
intused=0;//使用位图技巧
inttarget=sum/k;
//k号桶初始什么都没装,从nums[0]开始做选择
returnbacktrack(k,0,nums,0,used,target);
}
HashMapmemo=newHashMap<>();
booleanbacktrack(intk,intbucket,
int[]nums,intstart,intused,inttarget){
//basecase
if(k==0){
//所有桶都被装满了,而且nums一定全部用完了
returntrue;
}
if(bucket==target){
//装满了当前桶,递归穷举下一个桶的选择
//让下一个桶从nums[0]开始选数字
booleanres=backtrack(k-1,0,nums,0,used,target);
//缓存结果
memo.put(used,res);
returnres;
}
if(memo.containsKey(used)){
//避免冗余计算
returnmemo.get(used);
}
for(inti=start;i< nums.length; i++) {
//剪枝
if(((used>>i)&1)==1){//判断第i位是否是1
//nums[i]已经被装入别的桶中
continue;
}
if(nums[i]+bucket>target){
continue;
}
//做选择
used|=1<< i; //将第i位置为1
bucket+=nums[i];
//递归穷举下一个数字是否装入当前桶
if(backtrack(k,bucket,nums,i+1,used,target)){
returntrue;
}
//撤销选择
used^=1<< i; //使用异或运算将第i位恢复0
bucket-=nums[i];
}
returnfalse;
}
至此,这道题的第二种思路也完成了。
四、最后总结
本文写的这两种思路都可以算出正确答案,不过第一种解法即便经过了排序优化,也明显比第二种解法慢很多,这是为什么呢?
我们来分析一下这两个算法的时间复杂度,假设nums中的元素个数为n。
先说第一个解法,也就是从数字的角度进行穷举,n个数字,每个数字有k个桶可供选择,所以组合出的结果个数为k^n,时间复杂度也就是O(k^n)。
第二个解法,每个桶要遍历n个数字,对每个数字有「装入」或「不装入」两种选择,所以组合的结果有2^n种;而我们有k个桶,所以总的时间复杂度为O(k*2^n)。
当然,这是对最坏复杂度上界的粗略估算,实际的复杂度肯定要好很多,毕竟我们添加了这么多剪枝逻辑。不过,从复杂度的上界已经可以看出第一种思路要慢很多了。
所以,谁说回溯算法没有技巧性的?虽然回溯算法就是暴力穷举,但穷举也分聪明的穷举方式和低效的穷举方式,关键看你以谁的「视角」进行穷举。
通俗来说,我们应该尽量「少量多次」,就是说宁可多做几次选择,也不要给太大的选择空间;宁可「二选一」选k次,也不要 「k选一」选一次。
好了,这道题我们从两种视角进行穷举,虽然代码量看起来多,但核心逻辑都是类似的,相信你通过本文能够更深刻地理解回溯算法。
审核编辑 :李倩
-
回溯算法
+关注
关注
0文章
10浏览量
6597 -
数组
+关注
关注
1文章
417浏览量
25945
原文标题:集合划分问题:排列组合中的回溯思想
文章出处:【微信号:TheAlgorithm,微信公众号:算法与数据结构】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
ADS1256 8通道依次采样,数据不正确怎么解决?
RVBacktrace RISC-V极简栈回溯组件

机器学习的经典算法与应用

求助,关于STM32上开发函数调用堆栈回溯的问题求解
freertos系统如何划分任务?
vlan的划分方法有哪些?有哪几种?
光子集成芯片是什么
光子集成芯片的应用前景
微波光子集成芯片和硅基光子集成芯片的区别
微波光子集成芯片的基本原理
滚柱导轨精度等级是如何划分?






 工商网监
工商网监
评论