 如何编写优质嵌入式C程序
如何编写优质嵌入式C程序
本文面向的,正是使用单片机、ARM7、Cortex-M3这类微控制器的编程人员。
C语言诡异且有种种陷阱和缺陷,需要程序员多年历练才能达到较为完善的地步。
总是有大批的初学者,前仆后继的倒在这些陷阱和缺陷上,民用设备、工业设备甚至是航天设备都不例外。本文将结合具体例子再次审视它们,希望引起足够重视。深入理解C语言特性,是编写优质嵌入式C程序的基础。
由于篇幅限制,后续再推送编译器、防御性编程、测试和编程思想这几个方面的内容,来讨论如何编写优质嵌入式C程序。
1 处处都是陷阱
1.1 无心之过
1) “=”和”==”
将比较运算符”==”误写成赋值运算符”=”,可能是绝大多数人都遇到过的,比如下面代码:
if(x=5){//其它代码}
代码的本意是比较变量x是否等于常量5,但是误将”==”写成了”=”,if语句恒为真。如果在逻辑判断表达式中出现赋值运算符,现在的大多数编译器会给出警告信息。比如keil MDK会给出警告提示:“warning: #187-D: use of "=" where"==" may have been intended”,但并非所有程序员都会注意到这类警告,因此有经验的程序员使用下面的代码来避免此类错误:
if(5==x){//其它代码}
将常量放在变量x的左边,即使程序员误将’==’写成了’=’,编译器会产生一个任谁也不能无视的语法错误信息:不可给常量赋值!
2) 复合赋值运算符
复合赋值运算符(+=、*=等等)虽然可以使表达式更加简洁并有可能产生更高效的机器代码,但某些复合赋值运算符也会给程序带来隐含Bug,比如”+=”容易误写成”=+”,代码如下:
tmp=+1;代码本意是想表达tmp=tmp+1,但是将复合赋值运算符”+=”误写成”=+”:将正整数常量1赋值给变量tmp。编译器会欣然接受这类代码,连警告都不会产生。
如果你能在调试阶段就发现这个Bug,真应该庆祝一下,否则这很可能会成为一个重大隐含Bug,且不易被察觉。
复合赋值运算符”-=”也有类似问题存在。
3) 其它容易误写
- 使用了中文标点
- 头文件声明语句最后忘记结束分号
- 逻辑与&&和位与&、逻辑或||和位或|、逻辑非!和位取反~
- 字母l和数字1、字母O和数字0
这些误写其实容易被编译器检测出,只需要关注编译器对此的提示信息,就能很快解决。
1.2 数组下标
数组常常也是引起程序不稳定的重要因素,C语言数组的迷惑性与数组下标从0开始密不可分,你可以定义int test[30],但是你绝不可以使用数组元素test [30],除非你自己明确知道在做什么。
1.3 容易被忽略的break关键字
1) 不能漏加的break
switch…case语句可以很方便的实现多分支结构,但要注意在合适的位置添加break关键字。程序员往往容易漏加break从而引起顺序执行多个case语句,这也许是C的一个缺陷之处。
对于switch…case语句,从概率论上说,绝大多数程序一次只需执行一个匹配的case语句,而每一个这样的case语句后都必须跟一个break。去复杂化大概率事件,这多少有些不合常情。
2) 不能乱加的break
break关键字用于跳出最近的那层循环语句或者switch语句,但程序员往往不够重视这一点。
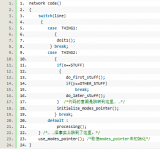
1990年1月15日,AT&T电话网络位于纽约的一台交换机宕机并且重启,引起它邻近交换机瘫痪,由此及彼,一个连着一个,很快,114型交换机每六秒宕机重启一次,六万人九小时内不能打长途电话。
当时的解决方式:工程师重装了以前的软件版本。。。事后的事故调查发现,这是break关键字误用造成的。《C专家编程》提供了一个简化版的问题源码:

那个程序员希望从if语句跳出,但他却忘记了break关键字实际上跳出最近的那层循环语句或者switch语句。现在它跳出了switch语句,执行了use_modes_pointer()函数。但必要的初始化工作并未完成,为将来程序的失败埋下了伏笔。
1.4 意想不到的八进制
将一个整形常量赋值给变量,代码如下所示:
int a=34, b=034;变量a和b相等吗?
答案是不相等的。我们知道,16进制常量以’0x’为前缀,10进制常量不需要前缀,那么8进制呢?它与10进制和16进制表示方法都不相同,它以数字’0’为前缀,这多少有点奇葩:三种进制的表示方法完全不相同。
如果8进制也像16进制那样以数字和字母表示前缀的话,或许更有利于减少软件Bug,毕竟你使用8进制的次数可能都不会有误使用的次数多!下面展示一个误用8进制的例子,最后一个数组元素赋值错误:
a[0]=106; /*十进制数106*/a[1]=112; /*十进制数112*/a[2]=052; /*实际为十进制数42,本意为十进制52*/
1.5指针加减运算
**指针的加减运算是特殊的。**下面的代码运行在32位ARM架构上,执行之后,a和p的值分别是多少?
int a=1;int *p=(int *)0x00001000;a=a+1;p=p+1;
对于a的值很容判断出结果为2,但是p的结果却是0x00001004。指针p加1后,p的值增加了4,这是为什么呢?原因是指针做加减运算时是以指针的数据类型为单位。p+1实际上是按照公式p+1*sizeof(int)来计算的。不理解这一点,在使用指针直接操作数据时极易犯错。
某项目使用下面代码对连续RAM初始化零操作,但运行发现有些RAM并没有被真正清零。
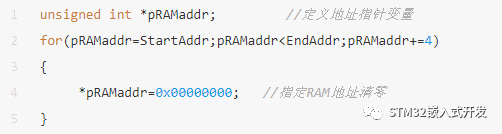
通过分析我们发现,由于pRAMaddr是一个无符号int型指针变量,所以pRAMaddr+=4代码其实使pRAMaddr偏移了4*sizeof(int)=16个字节,所以每执行一次for循环,会使变量pRAMaddr偏移16个字节空间,但只有4字节空间被初始化为零。其它的12字节数据的内容,在大多数架构处理器中都会是随机数。
1.6关键字sizeof
不知道有多少人最初认为sizeof是一个函数。其实它是一个关键字,其作用是返回一个对象或者类型所占的内存字节数,对绝大多数编译器而言,返回值为无符号整形数据。需要注意的是,使用sizeof获取数组长度时,不要对指针应用sizeof操作符,比如下面的例子:
void ClearRAM(char array[]){int i ;for(i=0;i{array[i]=0x00;}}int main(void){char Fle[20];ClearRAM(Fle); //只能清除数组Fle中的前四个元素}
我们知道,对于一个数组array[20],我们使用代码sizeof(array)/sizeof(array[0])可以获得数组的元素(这里为20),但数组名和指针往往是容易混淆的,有且只有一种情况下数组名是可以当做指针的,那就是**数组名作为函数形参时,数组名被认为是指针,同时,它不能再兼任数组名。
**注意只有这种情况下,数组名才可以当做指针,但不幸的是这种情况下容易引发风险。在ClearRAM函数内,作为形参的array[]不再是数组名了,而成了指针。sizeof(array)相当于求指针变量占用的字节数,在32位系统下,该值为4,sizeof(array)/sizeof(array[0])的运算结果也为4。所以在main函数中调用ClearRAM(Fle),也只能清除数组Fle中的前四个元素了。
1.7增量运算符’++’和减量运算符‘--‘
增量运算符”++”和减量运算符”--“既可以做前缀也可以做后缀。**前缀和后缀的区别在于值的增加或减少这一动作发生的时间是不同的。**作为前缀是先自加或自减然后做别的运算,作为后缀时,是先做运算,之后再自加或自减。许多程序员对此认识不够,就容易埋下隐患。下面的例子可以很好的解释前缀和后缀的区别。
int a=8,b=2,y;y=a+++--b;
代码执行后,y的值是多少?
这个例子并非是挖空心思设计出来专门让你绞尽脑汁的C难题(如果你觉得自己对C细节掌握很有信心,做一些C难题检验一下是个不错的选择。那么,《The C Puzzle Book》这本书一定不要错过),你甚至可以将这个难懂的语句作为不友好代码的例子。但是它也可以让你更好的理解C语言。根据运算符优先级以及编译器识别字符的贪心法原则,第二句代码可以写成更明确的形式:
y=(a++)+(--b);当赋值给变量y时,a的值为8,b的值为1,所以变量y的值为9;赋值完成后,变量a自加,a的值变为9,千万不要以为y的值为10。这条赋值语句相当于下面的两条语句:
y=a+(--b);a=a+1;
1.8逻辑与’&&’和逻辑或’||’的陷阱
为了提高系统效率,逻辑与和逻辑或操作的规定如下:**如果对第一个操作数求值后就可以推断出最终结果,第二个操作数就不会进行求值!**比如下面代码:
if((i>=0)&&(i++ <=max)){//其它代码}
在这个代码中,只有当i>=0时,i++才会被执行。这样,i是否自增是不够明确的,这可能会埋下隐患。逻辑或与之类似。
1.9结构体的填充
结构体可能产生填充,因为对大多数处理器而言,访问按字或者半字对齐的数据速度更快,当定义结构体时,编译器为了性能优化,可能会将它们按照半字或字对齐,这样会带来填充问题。比如以下两个个结构体:
第一个结构体:
struct {char c;short s;int x;}str_test1;
第二个结构体:
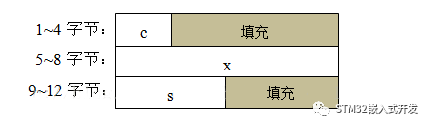
struct {char c;int x;short s;}str_test2;
这两个结构体元素都是相同的变量,只是元素换了下位置,那么这两个结构体变量占用的内存大小相同吗?
其实这两个结构体变量占用的内存是不同的,对于Keil MDK编译器,默认情况下第一个结构体变量占用8个字节,第二个结构体占用12个字节,差别很大。第一个结构体变量在内存中的存储格式如下图所示:
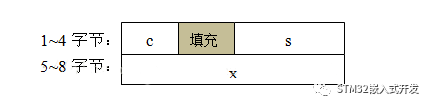
第二个结构体变量在内存中的存储格式如下图所示。对比两个图可以看出MDK编译器是是怎么将数据对齐的,这其中的填充内容是之前内存中的数据,是随机的,所以不能在结构之间逐字节比较;另外,合理的排布结构体内的元素位置,可以最大限度减少填充,节省RAM。
2 不可轻视的优先级
C语言有32个关键字,却有34个运算符。要记住所有运算符的优先级是困难的。稍不注意,你的代码逻辑和实际执行就会有很大出入。
比如下面将BCD码转换为十六进制数的代码:
result=(uTimeValue>>4)*10+uTimeValue&0x0F;这里uTimeValue存放的BCD码,想要转换成16进制数据,实际运行发现,如果uTimeValue的值为0x23,按照我设定的逻辑,result的值应该是0x17,但运算结果却是0x07。经过种种排查后,才发现’+’的优先级是大于’&’的,相当于(uTimeValue>>4)*10+uTimeValue与0x0F位与,结果自然与逻辑不符。符合逻辑的代码应该是:
result=(uTimeValue>>4)*10+(uTimeValue&0x0F);不合理的#define会加重优先级问题,让问题变得更加隐蔽。

编译器在编译后将宏带入,原代码语句变为:
if(IO0PIN&(1<<11) ==(1<<11)){//其它代码}
运算符'=='的优先级是大于'&'的,代码IO0PIN&(1<<11) ==(1<<11))等效为IO0PIN&0x00000001:判断端口P0.0是否为高电平,这与原意相差甚远。因此,使用宏定义的时候,最好将被定义的内容用括号括起来。
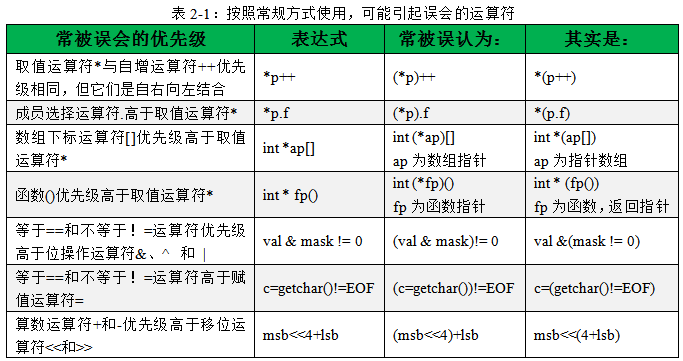
按照常规方式使用时,可能引起误会的运算符还有很多,如下表所示。C语言的运算符当然不会只止步于数目繁多!
 有一个简便方法可以避免优先级问题:不清楚的优先级就加上”()”,但这样至少有会带来两个问题:
有一个简便方法可以避免优先级问题:不清楚的优先级就加上”()”,但这样至少有会带来两个问题:
- 过多的括号影响代码的可读性,包括自己和以后的维护人员
- 别人的代码不一定用括号来解决优先级问题,但你总要读别人的代码
无论如何,在嵌入式编程方面,该掌握的基础知识,偷巧不得。建议花一些时间,将优先级顺序以及容易出错的优先级运算符理清几遍。
隐式转换
C语言的设计理念一直被人吐槽,因为它认为C程序员完全清楚自己在做什么,其中一个证据就是隐式转换。C语言规定,**不同类型的数据(比如char和int型数据)需要转换成同一类型后,才可进行计算。
**如果你混合使用类型,比如用char类型数据和int类型数据做减法,C使用一个规则集合来自动(隐式的)完成类型转换。这可能很方便,但也很危险。
这就要求我们理解这个转换规则并且能应用到程序中去!
- 当出现在表达式里时,有符号和无符号的char和short类型都将自动被转换为int类型,在需要的情况下,将自动被转换为unsigned int(在short和int具有相同大小时)。这称为类型提升。
提升在算数运算中通常不会有什么大的坏处,但如果位运算符 ~ 和 << 应用在基本类型为unsigned char或unsigned short 的操作数,结果应该立即强制转换为unsigned char或者unsigned short类型(取决于操作时使用的类型)。
uint8_t port =0x5aU;uint8_t result_8;result_8= (~port) >> 4;
假如我们不了解表达式里的类型提升,认为在运算过程中变量port一直是unsigned char类型的。我们来看一下运算过程:~port结果为0xa5,0xa5>>4结果为0x0a,这是我们期望的值。
但实际上,result_8的结果却是0xfa!在ARM结构下,int类型为32位。变量port在运算前被提升为int类型:~port结果为0xffffffa5,0xa5>>4结果为0x0ffffffa,赋值给变量result_8,发生类型截断(这也是隐式的!),result_8=0xfa。经过这么诡异的隐式转换,结果跟我们期望的值,已经大相径庭!正确的表达式语句应该为:
result_8=(unsigned char) (~port) >> 4; /*强制转换*/- 在包含两种数据类型的任何运算里,两个值都会被转换成两种类型里较高的级别。类型级别从高到低的顺序是long double、double、float、unsigned long long、long long、unsigned long、long、unsigned int、int。
这种类型提升通常都是件好事,但往往有很多程序员不能真正理解这句话,比如下面的例子(int类型表示16位)。
uint16_t u16a = 40000; /* 16位无符号变量*/uint16_t u16b= 30000; /*16位无符号变量*/uint32_t u32x; /*32位无符号变量 */uint32_t u32y;u32x = u16a +u16b; /* u32x = 70000还是4464 ? */u32y =(uint32_t)(u16a + u16b); /* u32y = 70000 还是4464 ? */
u32x和u32y的结果都是4464(70000%65536)!不要认为表达式中有一个高类别uint32_t类型变量,编译器都会帮你把所有其他低类别都提升到uint32_t类型。正确的书写方式:
u32x = (uint32_t)u16a +(uint32_t)u16b;//或者:u32x = (uint32_t)u16a + u16b;
后一种写法在本表达式中是正确的,但是在其它表达式中不一定正确,比如:
uint16_t u16a,u16b,u16c;uint32_t u32x;u32x= u16a + u16b + (uint32_t)u16c;/*错误写法,u16a+ u16b仍可能溢出 */
-
在赋值语句里,计算的最后结果被转换成将要被赋予值的那个变量的类型。这一过程可能导致类型提升也可能导致类型降级。降级可能会导致问题。比如将运算结果为321的值赋值给8位char类型变量。程序必须对运算时的数据溢出做合理的处理。很多其他语言,像Pascal(C语言设计者之一曾撰文狠狠批评过Pascal语言),都不允许混合使用类型,但C语言不会限制你的自由,即便这经常引起Bug。
-
当作为函数的参数被传递时,char和short会被转换为int,float会被转换为double。
当不得已混合使用类型时,一个比较好的习惯是使用类型强制转换。强制类型转换可以避免编译器隐式转换带来的错误,同时也向以后的维护人员传递一些有用信息。这有个前提:你要对强制类型转换有足够的了解!下面总结一些规则:
- 并非所有强制类型转换都是由风险的,把一个整数值转换为一种具有相同符号的更宽类型时,是绝对安全的。
- 精度高的类型强制转换为精度低的类型时,通过丢弃适当数量的最高有效位来获取结果,也就是说会发生数据截断,并且可能改变数据的符号位。
- 精度低的类型强制转换为精度高的类型时,如果两种类型具有相同的符号,那么没什么问题;需要注意的是负的有符号精度低类型强制转换为无符号精度高类型时,会不直观的执行符号扩展,例如:
unsigned int bob;signed char fred = -1;bob=(unsigned int )fred; /*发生符号扩展,此时bob为0xFFFFFFFF*/
-
单片机
+关注
关注
6049文章
44681浏览量
641056 -
嵌入式
+关注
关注
5103文章
19263浏览量
309881 -
C语言
+关注
关注
180文章
7618浏览量
138599
原文标题:嵌入式开发中的C语言1️⃣——特性
文章出处:【微信号:c-stm32,微信公众号:STM32嵌入式开发】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐










 工商网监
工商网监
评论