 缓解模型训练成本过高的问题
缓解模型训练成本过高的问题
我们都知道,为了让以深度神经网络为基础的模型更快地训练,人们提出了单机多卡、多机多卡等分布式训练的方式,那么,在模型预测推理阶段,有什么方法可以加速推理呢?遗憾的是,并行/分布式的加速方法并不适用于模型推理阶段。
但这并不意味着没有方法可以加速模型的推理。既然多核的方式不行,可以考虑在单核上面的加速,比如减小模型大小(即模型压缩)。
模型压缩可以分为模型剪枝(pruning)和模型蒸馏(distillation)。由于模型中的参数对模型推理的贡献天生就是不平等的,我们可以利用剪枝将贡献度不高的模型参数剪去,从而减小模型大小,但剪枝带来的加速比并不高,最多只有2~3倍的速度提升;蒸馏的方法可以带来较大的加速比,推理精度也不会有太大的损失,但通常情况下,蒸馏会用到大量无标签的数据预训练学生模型(student),然后用任务相关的带标签数据进一步微调或蒸馏学生模型,但是,预训练阶段又可能会花费大量的时间。
那么有没有什么方法既能获得较大的加速比和较低的精度损失,又可以缓解模型训练成本过高的问题呢?
最近丹琦女神组提出了解决这一问题的方法,让我们一起来看看吧。
论文标题:
Structured Pruning Learns Compact and Accurate Models
论文链接:
https://arxiv.org/pdf/2204.00408.pdf
github地址:
https://github.com/princeton-nlp/CoFiPruning
背景介绍
在介绍这篇论文提出的方法之前,还需要简单说明下作者研究的背景。
作者提出的模型压缩方法针对的是原模型(教师模型)为transformer 架构的模型压缩。众所周知, transformer 由多个块组成,每个块由一个多头自注意力(multi-head self-attention,MHA)和两个前馈神经网络(FFN)组成。其中, MHAs 和 FFNs 的参数量比为 1:2。在 GPU 上,两者的推理时间基本相同,而在 CPU 上, FFNs 则会耗费更多的推理时间。
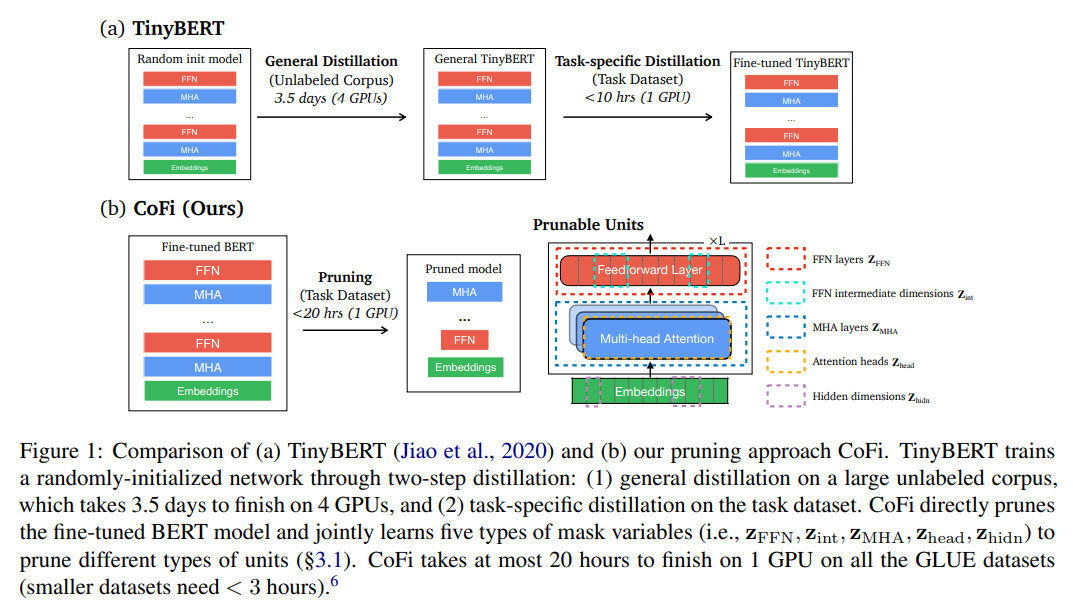
正如前面所述,模型压缩可以归纳为两种方法:知识蒸馏和剪枝。知识蒸馏在通常情况下,需要预先定义一个结构固定的学生网络(当然,也有一些尝试动态学生网络的研究),通过用大量无标签数据预训练学生网络的方式进行模型参数初始化,然后用任务特定的带标签数据微调学生模型,当然,学生模型的初始化方式可以有很多种,例如用教师模型的某些层初始化学生模型等,但基本的解决思想是一致的。
剪枝则指的是从原模型中去除冗余的参数,按照剪枝的粒度可以分为以下几种:
层剪枝(layer pruning):从模型中删去整个 block 块(包括 MHA 和 FFN ),一些研究表明,去除 50% 的层并不会有太多的精度下降,而且还可以获得 2X 的加速比;
头剪枝(head pruning):通过 mask 矩阵只保留一部分 head,但研究表明,这种做法并不能带来较大的加速比,当仅保留一个 head 的时候,加速比为 1.4X;
前馈神经网络剪枝(FFN pruning):去除整个 FFN 层或者去除 FFN 层的某些维度;
更加细粒度的块和非结构化的剪枝:去除 MHA 和 FFN 中更小的块或者去除某些参数权重,目前这种做法很难优化模型,也难以获得推理加速
除此之外,还可以将剪枝和蒸馏融合起来,但目前,该方法具体实现尚不清晰。
结构化剪枝方法 CoFi
为获得较大的加速比和较低的精度损失,以及缓解模型训练成本过高的问题,作者提出了结构化剪枝方法CoFi(Coarse- andFine-grained Pruning),方法由两个部分组成:粗粒度和细粒度的剪枝以及从原模型(未剪枝)到剪枝模型的逐层蒸馏
粗粒度和细粒度的剪枝
在头剪枝(head pruning)中,经常通过由 组成的 mask 矩阵来保留一部分 head ,但是,当 mask 矩阵全为 0,即去除掉所有的 head 时,会使模型优化变得困难。为此,作者为每一层的 MHA 和 FFN 引入两个掩码变量 和 ,多头自注意力和前馈神经网络可以表示为:
其中, 是输入向量, 是 head 数量, , , , 分别是 query、key、value 和输出的权重矩阵, 是 attention 函数, 和 分别是 FFN 的两个权重, 和 分别是掩码矩阵变量。
作者用 和 控制每一层的 MHA 和 FFN 是否剪枝以及 和 控制每一层的 MHA 和 FFN 中的哪些 head 和哪些维度需要剪枝。
除此之外,作者还对 和 的输出在维度上作剪枝操作。具体做法是将掩码变量 应用到模型中所有的权重矩阵,掩码跨层共享的原因是作者考虑到模型中的残差使得隐向量中的每个维度都可以连接到下一层相应的维度。
此外,作者定义了预期稀疏度:
其中, 是整个模型大小, 是 block 层数, 是隐藏层维度, 是多头自注意力的每个 head 的向量维度, 是前馈网络的维度,一般情况下,。
模型训练阶段,所有的掩码元素的值处于之间,推理阶段,会将低于阈值的掩码变量映射为 0,得到最终的剪枝模型,其中,阈值由每个权重矩阵的预期稀疏度确定。
从原模型到剪枝模型的蒸馏
考虑到将剪枝和蒸馏融合可以提高性能,作者提出了用于剪枝的逐层蒸馏方法。与一般的蒸馏做法不同,作者没有预先定义从教师网络到学生网络的固定的层映射,而是动态地搜索两者之间的层映射。具体来说,假设 表示准备将知识蒸馏到学生网络的教师网络的层的集合, 是层映射函数,表示从教师网络的第 层映射到的学生网络的层,那么,隐藏层的蒸馏 可以定义为:
其中, 是线性变换矩阵, 和 分别是第 层学生网络和第 层教师网络的隐藏层表示。 定义如下:
其中,计算两个层集合之间的距离(MSE)的操作是可以并行执行的。通过上面的层映射函数,教师网络和学生网络之间的层映射总是按照最有利于剪枝的方向进行。
最后,作者将逐层蒸馏和来自预测层(模型输出)的蒸馏结合起来,得到最终的loss:
其中, 是超参, 和 分别是学生模型和教师模型的输出概率分布。
实验
数据集
作者使用的是 GLUE 数据集和 SQuAD v1.1 数据集,其中, GLUE 数据集包括 SST2、MNLI、QQP、QNLI、MRPC、CoLA、STS-B 和 RTE 八个数据集。
在四个相对较大的 GLUE 数据集(包括 MNLI、QNLI、SST-2 和 QQP)以及 SQuAD 数据集上,作者训练了 20 个 epoch,并对最终的学生网络微调了额外 20 个 epoch。在前 20 个 epoch 中,作者使用蒸馏的目标函数对模型进行微调 1 个 epoch,然后在 2 个 epoch 之内使模型达到期望的目标稀疏度。而对于四个较小的 GLUE 数据集,作者训练了 100 个 epoch 并微调 20 个 epoch。作者用蒸馏目标函数微调模型 4 个epoch,并在接下来的 20 个 epoch 内将模型剪枝到期望的目标稀疏度。在达到目标稀疏度后,还会在剩余的训练 epoch 阶段继续剪枝以搜索性能更好的网络结构。
作者在每个数据集上依次训练并微调不同目标稀疏度的模型。此外,作者在实验中发现,训练结束后的微调可以有效地保持模型不会有太大的精度损失。
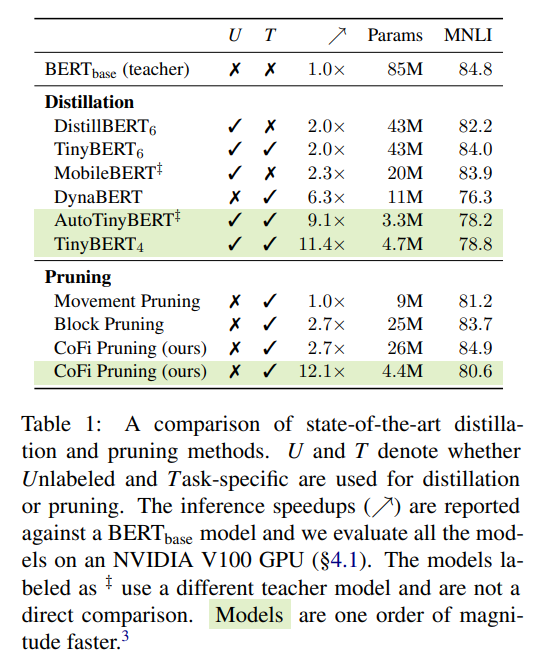
模型对比
作者将 、、、、 作为 baseline,对比了 CoFi 和 baseline 在不同的加速比和模型大小的情况下准确率(acc)和 f1 的变化
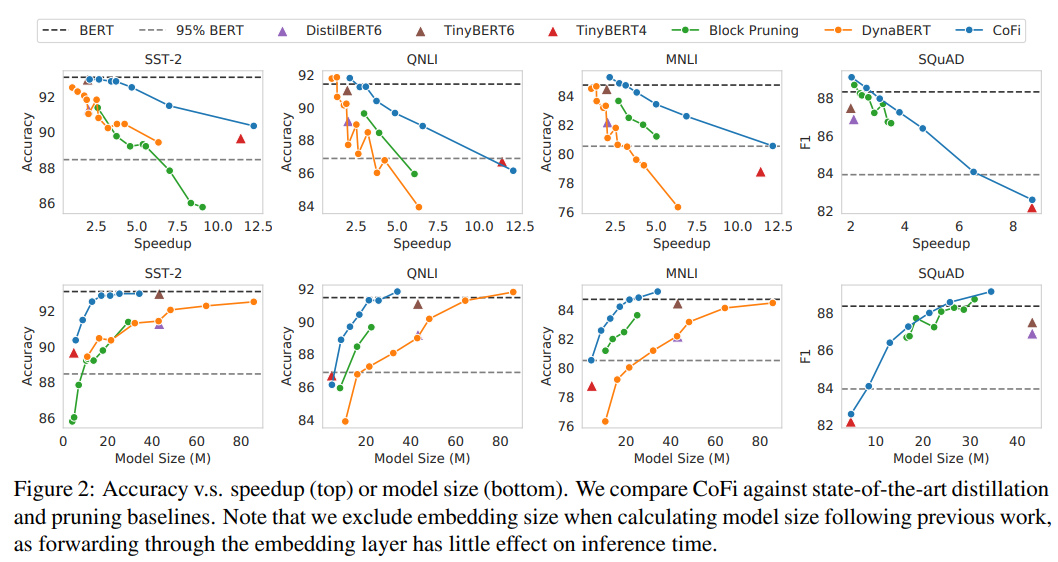
可以看到,在相同的加速比或相同的模型大小下,作者提出的方法 CoFi 都可以获得更高的准确率(acc)或 f1
此外,作者还展示了 CoFi 和 的对比结果。
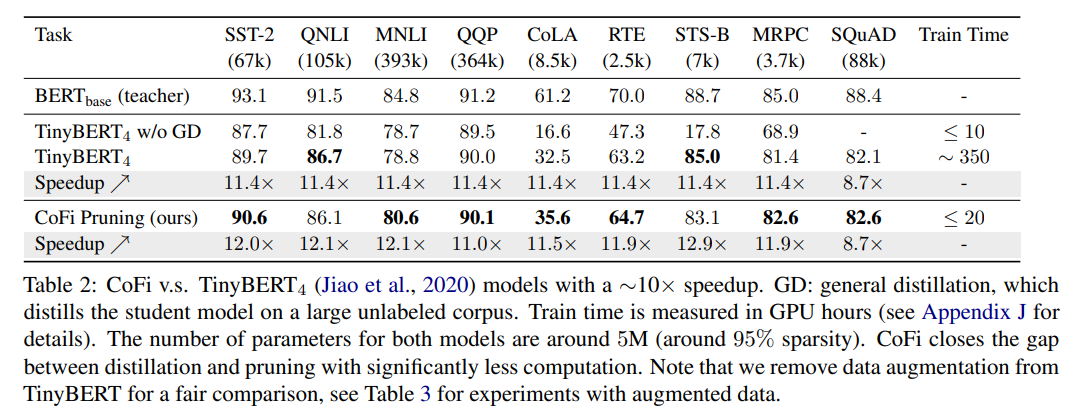
其中, 使用大量无标签数据通过预训练的方式初始化学生网络,和大规模预训练语言模型一样,这种从大规模语料库中获取通用知识的方式对学生模型性能有着十分重要的作用,但预训练会花费太多的时间,如下图所示:
从表 2 可以看到,CoFi 可以获得和 基本一致的加速比和略高的模型预测准确度,与此同时,CoFi 模型的训练时间较 得到了大幅的缩减,也证明了以蒸馏目标函数训练的剪枝方法在模型压缩方面是经济且高效的。
除此之外,作者还使用相同的任务特定的数据分别为 和 CoFi 做数据增强,并对比了数据增强后的模型性能。
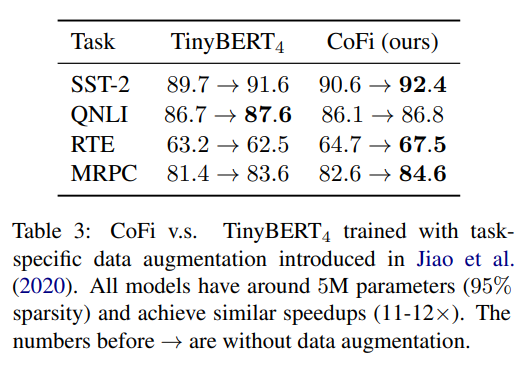
可以看到,数据增强后,CoFi 也基本有着高于 的模型性能。
▲sota剪枝和蒸馏方法的性能对比
消融实验
作者做了一系列的消融实验,证明了 CoFi 各个模块的有效性。实验结果如下所示:
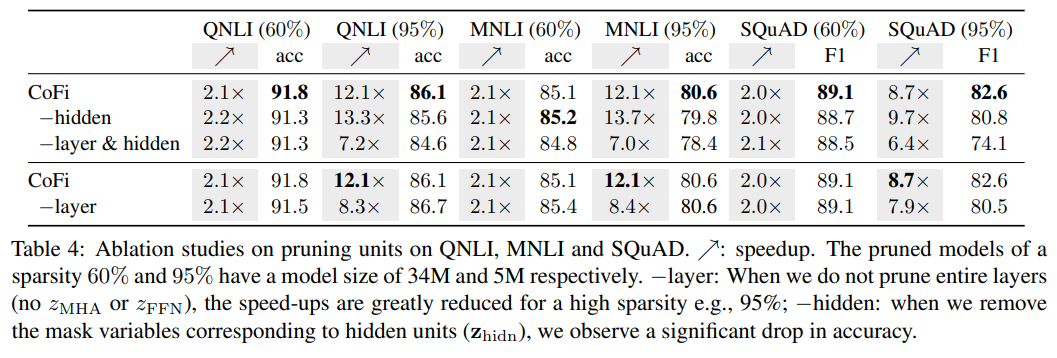
▲CoFi消融实验-剪枝单元
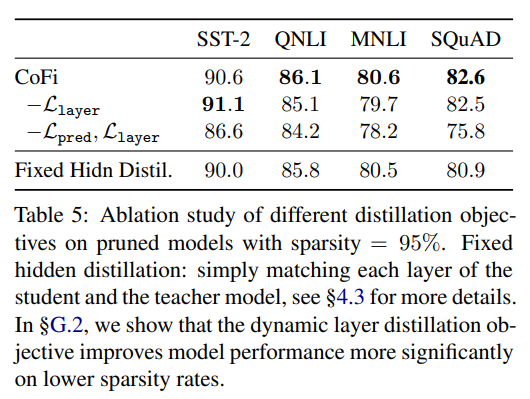
▲CoFi消融实验-蒸馏目标函数
剪枝后的模型的结构
作者研究了经过 CoFi 剪枝后得到的模型的结构,作者分别在五个数据集上在不同的目标稀疏度下训练微调得到剪枝后的模型,并对模型的 FFN 层的平均中间维度以及 MHA 层的 head 平均剩余数量做了统计,结果如下:
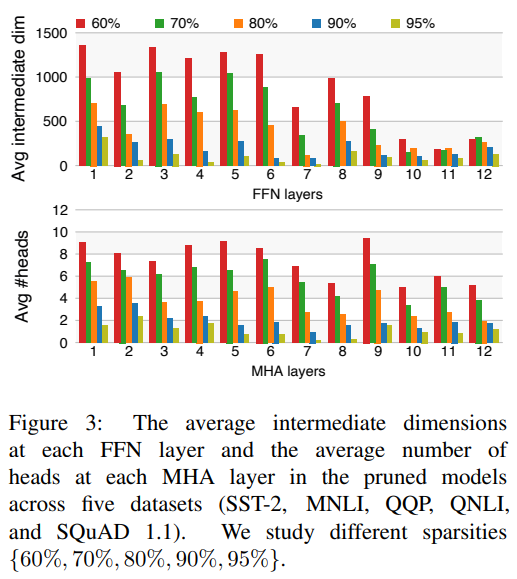
可以看到:
几乎在所有的稀疏度下,前馈神经网络层都存在明显的剪枝,这表明 FFN 层比 MHA 层存在更多的冗余信息;
CoFi 倾向于更多地剪枝上层网络结构
作者还详细地展示了不同数据集下经 CoFi 剪枝后的模型的具体结构,下图展示的是每个模型每层 MHA 和 FFN 模块的保留情况。尽管模型大小基本一致,但不同的数据集却训练出结构存在明显差异的模型,从侧面也证明了不同的数据集存在不同的最优学生模型。
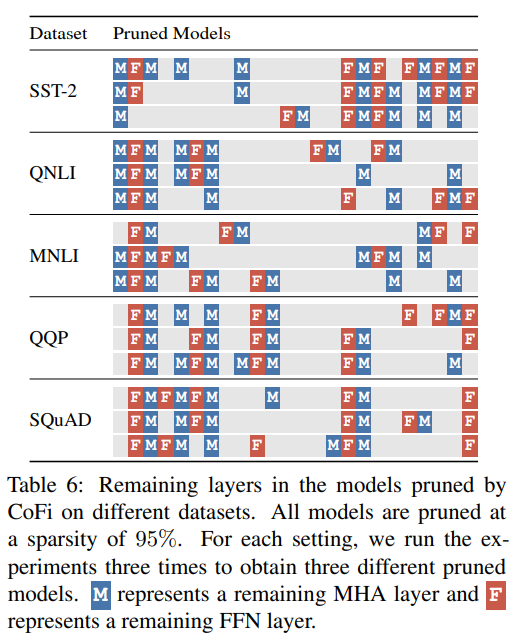
▲经CoFi剪枝后的模型不同层子模块保留情况
总结
作者提出的结构化剪枝方法 CoFi 在几乎没有太多精度损失的情况下,达到了 10 倍以上的加速比,同时,和常规的蒸馏做法相比,避免了因使用大量无标签数据预训练模型而带来的训练成本过高的问题,按作者的话来说,该方法可以是蒸馏的一个有效替代品。
当然,作者也指出,尽管 CoFi 可以应用到任务无关的模型的剪枝中,比如大规模预训练语言模型,但由于上游剪枝方案设计的复杂性,作者还是将 CoFi 的应用场景限制到任务相关的模型压缩中。试想下,如果可以将任务无关的模型压缩到可以部署到移动设备或者可穿戴智能设备上,那么,世界又会是一番怎样的景象呢?不知道这是不是丹琦女神给我们新开的一个“坑”呢?
审核编辑 :李倩
-
cpu
+关注
关注
68文章
10944浏览量
213823 -
神经网络
+关注
关注
42文章
4789浏览量
101552 -
模型
+关注
关注
1文章
3410浏览量
49463
原文标题:ACL'22 | 陈丹琦提出CoFi模型剪枝,加速10倍,精度几乎无损
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
马斯克揭秘Grok 3训练成本:20万块英伟达GPU
让大模型训练更高效,奇异摩尔用互联创新方案定义下一代AI计算






 工商网监
工商网监
评论