 存内计算并不满足于现有的算力
存内计算并不满足于现有的算力
谈到存内计算,大部分人的第一印象就是超低功耗和大算力。存内计算技术打破了冯诺依曼架构的限制,冲破了内存墙,为半导体产业带来了新的创新。但你可能会问,存内计算的应用场景到底有哪些呢?
边缘计算的下一步
边缘计算可以说是众多存内计算技术与公司走的第一步,存内计算凭借其低功耗的特性,可穿戴等端侧设备可以说是为该技术量身定制的。在其架构的优越性之下,存内计算又比一众传统边缘AI芯片有着更加可观的算力。所以,对于智能手表、智能眼镜这类对功耗需求高,又有一定AI计算需求的应用来说,存内计算芯片无疑是不二之选。
不过如今的MCU已经将功耗降到了极低的水准,部分也能完成一些简单的AI运算,如果仅仅是在语音识别、事件检测这些应用上来竞争的话,即便这些存内计算有优势,可能在实际使用过程中,除了续航之外,用户的切身感知到的变化会比较小。

WTM2101存内计算芯片 / 知存科技
但边缘计算并不只局限于此,还有图像处理这一老大难亟待解决,这一应用相比上述那些又有着更高的算力要求。国内领先的存内计算公司知存科技近日透露,他们正在打造算力更强的下一代存内计算芯片就是面向超清视频处理的,根据其给出的演示所示,该芯片主要针对AI插帧、AI超分辨率、AI视频降噪和AI高动态分辨率,这些在边缘端感知更加明显的AI应用。
而以上这些AI应用,也仅仅只是存内计算往智能手机等消费级边缘端走的下一步,边缘AI芯片的终极目标都是自动驾驶。如若能做到更高的算力,存内计算芯片就有机会冲进汽车市场,与自动驾驶芯片的玩家硬碰硬。
超越GPU的算力
既然存内计算已经证实了自己在边缘端的算力优势,那有没有机会与GPU这类算力猛禽一决高下呢?我们以波动仿真为例,波动仿真在许多应用中都有普及,比如医学影像、石油勘探、减轻地震灾害以及国防系统等。然而大部分应用在使用波动仿真时,都要用到超级计算机对波动方程多重求解。虽然这类应用不像可穿戴一样,对于成本和体积要求不高,但对于速度和能耗还是比较重视的。
目前主导的波动仿真解决方案还是CPU和GPU,但由于本身的并行性缺失,即便是高端的CPU运行再小的问题,也需要大量时间才能完成计算。而GPU凭借其巨大的内存带宽优势,无疑拥有着更高的速度。即便如此,在实际应用中,波动仿真是一个极端的数据移动过程,GPU依然会遇到瓶颈,即便几百GB/s的内存带宽没法免受影响,最终导致用于数据移动的功耗甚至高于计算的功耗。
而存内计算可以减少处理器之间的数据移动,因为它消除了片外与片内存储之间的数据移动,但存内之间的数据移动依然是一大问题。埃克森美孚的研究人员就想出了Wave-PIM这种存内计算方案,利用超大规模集成电路常用的H树架构,来减少内存区块之间数据移动的延迟。他们以900GB/s带宽的16GB HBM2内存进行模拟,得出了52.8TFLOPS(FP32)的成绩,超过了Tesla V100 GPU。这证明了存内计算芯片,即使是在服务器级和HPC级的应用上,也有着独到的优势。

UPMEM PIM / UPMEM
不过如今GPU内存带宽已经随着HBM3和英伟达的H100芯片做到了3TB/s,而业界目前在内存带宽上占优的存内计算方案,法国公司UPMEM的DDR4 PIM,也只做到了2.5TB/s。哪怕存内计算有着功耗上的巨大优势,但性能上要想进一步超越GPU,还是需要更先进的内存技术和更多的架构创新。好在如今越来越多的公司开始走上存内计算的商业化尝试,存储厂商们虽然还没有确定走这一方向,但存内计算与其发展技术并无冲突,而且从生产创新和投资方向来看,他们已经开始布局这一技术了,未来高性能计算上很有可能出现存储厂商与GPU厂商互卷的情况。
-
半导体产业
+关注
关注
6文章
510浏览量
34548 -
边缘计算
+关注
关注
22文章
3176浏览量
49980 -
算力
+关注
关注
1文章
1048浏览量
15159
发布评论请先 登录
相关推荐
存算一体行业2024年回顾与2025年展望
存算于芯 · 智启未来 — 2024苹芯科技产品发布会盛大召开

aic3106作为slave,sclk与Wclk是否可以不满足sclk=2*wclk*采样位数?
存力与算力并重:数据时代的双刃剑
当运放用作比较器时,虚短特性是不满足的,为什么还会出现?
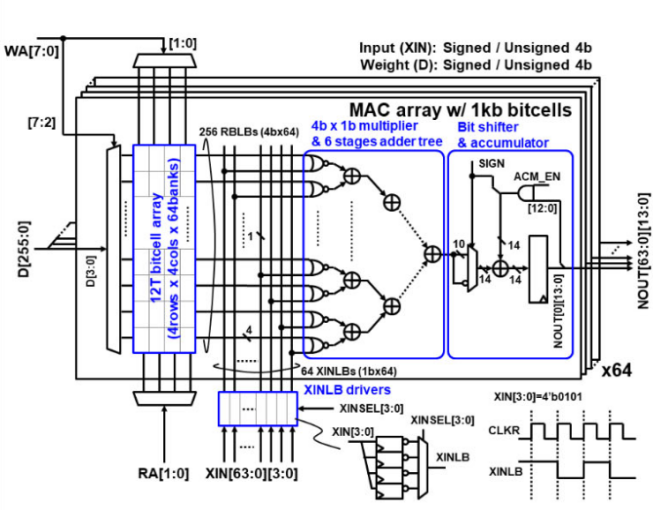

探索存内计算—基于 SRAM 的存内计算与基于 MRAM 的存算一体的探究






 工商网监
工商网监
评论