 使用NVIDIA A30 GPU加速AI推理工作负载
使用NVIDIA A30 GPU加速AI推理工作负载
NVIDIA A30 GPU 基于最新的 NVIDIA Ampere 体系结构,可加速各种工作负载,如大规模人工智能推理、企业培训和数据中心主流服务器的 HPC 应用程序。 A30 PCIe 卡将第三代 Tensor 内核与大容量 HBM2 内存( 24 GB )和快速 GPU 内存带宽( 933 GB / s )组合在一个低功耗外壳中(最大 165 W )。
A30 支持广泛的数学精度:
双精度( FP64 )
单精度( FP32 )
半精度( FP16 )
脑浮 16 ( BF16 )
整数( INT8 )
它还支持 Tensor Float 32 ( TF32 )和 Tensor Core FP64 等创新技术,提供了一个单一的加速器来加速每个工作负载。
图 1 显示了 TF32 ,其范围为 FP32 ,精度为 FP16 。 TF32 是 PyTorch 、 TensorFlow 和 MXNet 中的默认选项,因此在上一代 NVIDIA Volta 架构中实现加速不需要更改代码。
A30 的另一个重要特点是多实例 GPU ( MIG )能力。 MIG 可以最大限度地提高从大到小工作负载的 GPU 利用率,并确保服务质量( QoS )。单个 A30 最多可以被划分为四个 MIG 实例,以同时运行四个应用程序,每个应用程序都与自己的流式多处理器( SMs )、内存、二级缓存、 DRAM 带宽和解码器完全隔离。有关更多信息,请参阅 支持的 MIG 配置文件 。
对于互连, A30 支持 PCIe Gen4 ( 64 GB / s )和高速第三代 NVLink (最大 200 GB / s )。每个 A30 都可以支持一个 NVLink 桥接器与一个相邻的 A30 卡连接。只要服务器中存在一对相邻的 A30 卡,这对卡就应该通过跨越两个 PCIe 插槽的 NVLink 桥接器连接,以获得最佳桥接性能和平衡的桥接拓扑。
性能和平衡的桥接拓扑。
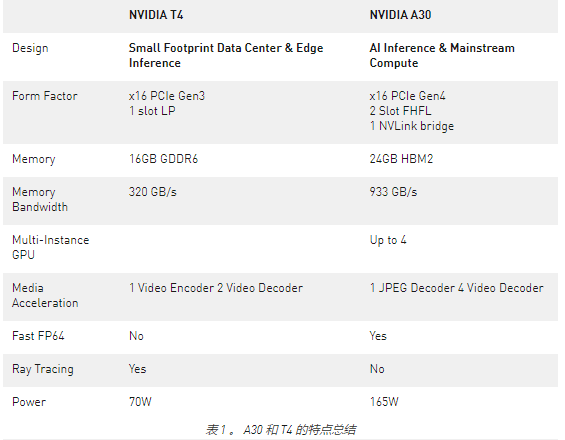
除了表 1 中总结的硬件优势外, A30 可以实现比 T4 GPU 更高的每美元性能。 A30 还支持端到端软件堆栈解决方案:
图书馆
GPU 加速了 PyTorch 、 TensorFlow 和 MXNet 等深度学习框架
优化的深度学习模型
可从 NGC 和[2000]以上的容器中获得
性能分析
为了分析 A30 相对于 T4 和 CPU 的性能改进,我们使用以下数据集对 MLPerf 推断 v1.1 。 中的六个模型进行了基准测试:
ResNet-50v1 。 5 ( ImageNet )
SSD 大尺寸 ResNet-34 ( COCO )
3D Unet (布拉茨 2019 )
DLRM ( 1TB 点击日志,离线场景)
BERT (第 1.1 版,第 384 小节)
RNN-T (图书馆语言)
MLPerf 基准测试套件 涵盖了广泛的推理用例,从图像分类和对象检测到推荐,以及自然语言处理( NLP )。
图 2 显示了 A30 与 T4 和 BERT 在人工智能推理工作负载上的性能比较结果。对于 CPU 推断, A30 比 CPU 快约 300 倍。
与T4相比,A30在使用这六种机型进行推理时提供了大约3-4倍的性能加速比。性能加速是由于30个较大的内存大小。这使得模型的批量更大,内存带宽更快(几乎是3倍T4),可以在更短的时间内将数据发送到计算核心。
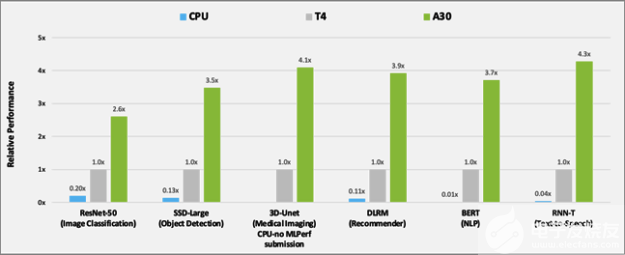
图 2 使用 MLPerf 比较 A30 与 T4 和 CPU 的性能。
CPU:8380H (不在 3D Unet 上提交)
除了人工智能推理之外, A30 还可以快速预训练人工智能模型,例如 BERT 大型 TF32 ,以及使用 FP64 张量核加速 HPC 应用。带有 TF32 的 A30 Tensor Cores 的性能比 T4 高出 10 倍,无需对代码进行任何更改。它们还提供了自动混合精度的额外 2 倍提升,使吞吐量增加了 20 倍。
硬件解码器
在构建视频分析或视频处理管道时,必须考虑以下几个操作:
计算模型或预处理步骤的需求。 这取决于 Tensor 内核、 GPU DRAM 和其他硬件组件,它们可以加速模型或帧预处理内核。
传输前的视频流编码。 这样做是为了最小化网络上所需的带宽。为了加快这一工作量,请使用 NVIDIA 硬件解码器。
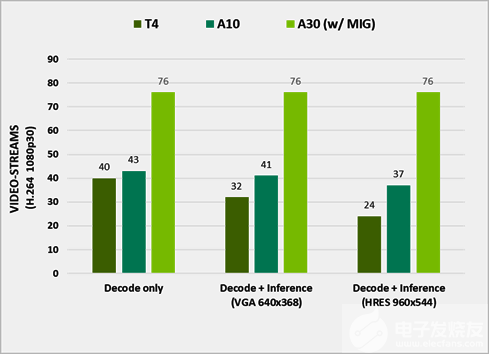
图 3 在不同 GPU 上处理的流的数量
使用 DeepStream 5.1 测试性能。它代表了 e2e 在视频捕获和解码、预处理、批处理、推理和后处理方面的性能。已关闭输出渲染以获得最佳性能,运行 ResNet10 、 ResNet18 和 ResNet50 网络以推断 H.264 1080p30 视频流。
A30 旨在通过提供四个视频解码器、一个 JPEG 解码器和一个光流解码器来加速智能视频分析( IVA )。
要使用这些解码器和计算资源来分析视频,请使用 NVIDIA DeepStream SDK ,它为基于人工智能的多传感器处理、视频、音频和图像理解提供了一个完整的流分析工具包。有关更多信息,请参阅 TAO 工具包与 DeepStream 的集成 或者 使用 NVIDIA DeepStream 构建实时编校应用程序,第 1 部分:培训 。
接下来呢?
A30 代表了数据中心最强大的端到端人工智能和 HPC 平台,使研究人员、工程师和数据科学家能够交付真实世界的结果,并将解决方案大规模部署到生产中。有关更多信息,请参阅 NVIDIA A30 Tensor Core GPU 数据表 和 NVIDIA A30 GPU 加速器产品简介 。
关于作者
Maggie Zhang 是 NVIDIA 的深度学习工程师,致力于深度学习框架和应用程序。她在澳大利亚新南威尔士大学获得计算机科学和工程博士学位,在那里她从事 GPU / CPU 异构计算和编译器优化。
Tanay Varshney 是 NVIDIA 的一名深入学习的技术营销工程师,负责广泛的 DL 软件产品。他拥有纽约大学计算机科学硕士学位,专注于计算机视觉、数据可视化和城市分析的横断面。
Davide Onofrio 是 NVIDIA 的高级深度学习软件技术营销工程师。他在 NVIDIA 专注于深度学习技术开发人员关注内容的开发和演示。戴维德在生物特征识别、虚拟现实和汽车行业担任计算机视觉和机器学习工程师已有多年经验。他的教育背景包括米兰理工学院的信号处理博士学位。Ivan Belyavtsev 是一名图形开发工程师,主要致力于开发人员支持和优化基于虚拟引擎的游戏。他还是 Innopolis 大学游戏开发领域的计算机图形学导师。
Shar Narasimhan 是 AI 的高级产品营销经理,专门从事 NVIDIA 的 Tesla 数据中心团队的深度学习培训和 OEM 业务。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
4990浏览量
103105 -
人工智能
+关注
关注
1791文章
47314浏览量
238624 -
深度学习
+关注
关注
73文章
5503浏览量
121198
发布评论请先 登录
相关推荐
《CST Studio Suite 2024 GPU加速计算指南》
深度学习工作负载中GPU与LPU的主要差异

NVIDIA加速AI在日本各行各业的应用
日本企业借助NVIDIA产品加速AI创新
FPGA和ASIC在大模型推理加速中的应用

NVIDIA助力丽蟾科技打造AI训练与推理加速解决方案

NVIDIA与思科合作打造企业级生成式AI基础设施
AMD助力HyperAccel开发全新AI推理服务器

英伟达推出全新NVIDIA AI Foundry服务和NVIDIA NIM推理微服务
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
NVIDIA加速微软最新的Phi-3 Mini开源语言模型
利用NVIDIA组件提升GPU推理的吞吐
全新NVIDIA RTX A400和A1000 GPU全面加强AI设计与生产力工作流
NVIDIA 发布全新交换机,全面优化万亿参数级 GPU 计算和 AI 基础设施






 工商网监
工商网监
评论