 稠密检索模型在zero-shot场景下的泛化能力
稠密检索模型在zero-shot场景下的泛化能力
引言
随着预训练语言模型在自然语言处理领域的蓬勃发展,基于预训练语言模型的稠密检索(dense retrieval)近年来也变成了主流的一阶段检索(召回)技术,在学术界和工业界均已经得到了广泛的研究。与传统的基于字面匹配的稀疏检索(sparse retrieval)模型相比,稠密检索模型通过学习低维的查询和文档向量来实现语义级别的检索,能够更好地理解用户的查询意图,返回能够更好地满足用户信息需求的结果。
通常情况下,训练一个优秀的稠密检索模型离不开大规模的人工标注数据,然而,在很多应用场景和业务问题上,这种与领域相关的大规模标注数据非常难以获得,因此稠密检索模型的零样本域外泛化能力(zero-shot OOD generalizability)就变得非常重要。在实际应用中,不同领域之间通常存在较大差异,这种zero-shot能力直接影响着稠密检索模型在现实场景中的大规模应用。相比之下,传统的BM25可以简单有效地部署在不同场景下,如果稠密检索模型无法在现实场景中取得比BM25显著优异的性能,则稠密检索模型的应用价值将会大打折扣。
目前,已经有一些工作开始研究如何评估稠密检索模型的zero-shot泛化能力以及提高该能力的方法。现有的一些研究指出,稠密检索模型的zero-shot能力非常有限,在某些场景下甚至无法超越传统的BM25算法。然而,现有研究的实验设置相对比较单一,大多关注于模型在不同目标领域上的测试结果,而没有关注不同的源域设置会如何影响模型的zero-shot泛化性能,从而导致我们并不清楚是什么因素影响了稠密检索模型的零样本泛化能力。
因此,本文针对zero-shot场景下的稠密检索模型泛化能力进行了较为深入的研究,旨在理解何种因素影响了稠密检索模型的zero-shot泛化能力,以及如何改善这些因素从而提升模型的zero-shot泛化能力。为此,我们设计了充分的实验,从源域query分布、源域document分布、数据规模、目标域分布偏移程度等几个方面进行了全面的分析,并发现了不同因素对模型zero-shot泛化能力的影响。另外,我们还系统梳理了近期出现的几种提升zero-shot泛化性能的优化策略,并指出每种策略是如何影响上述几个因素从而实现改进的。
背景和设置
Zero-shot场景下的稠密检索
稠密检索任务旨在通过给定的query,在一个庞大的document语料库中召回与query高度相关的document(本文中document泛指语料库中的文本内容,可以是句子,段落,文章等),其中query和document的语义相关性通常建模为query和document表示向量的点积或余弦相似度。本文主要关注zero-shot场景下的稠密检索,即使用源域上的标注数据训练模型,在目标领域的测试集上评估模型,且不能使用该目标域上的标注数据进一步训练模型。
数据集
为了能够更全面地评估稠密检索模型的zero-shot泛化能力,我们收集了12个当前常用的检索数据集,它们分属于多个不同领域,其数据特性也各不相同。我们把这些数据集划分为源域数据集和目标域数据集,其中每个数据集都有对应的query集合和document集合。数据的统计信息如下表所示:
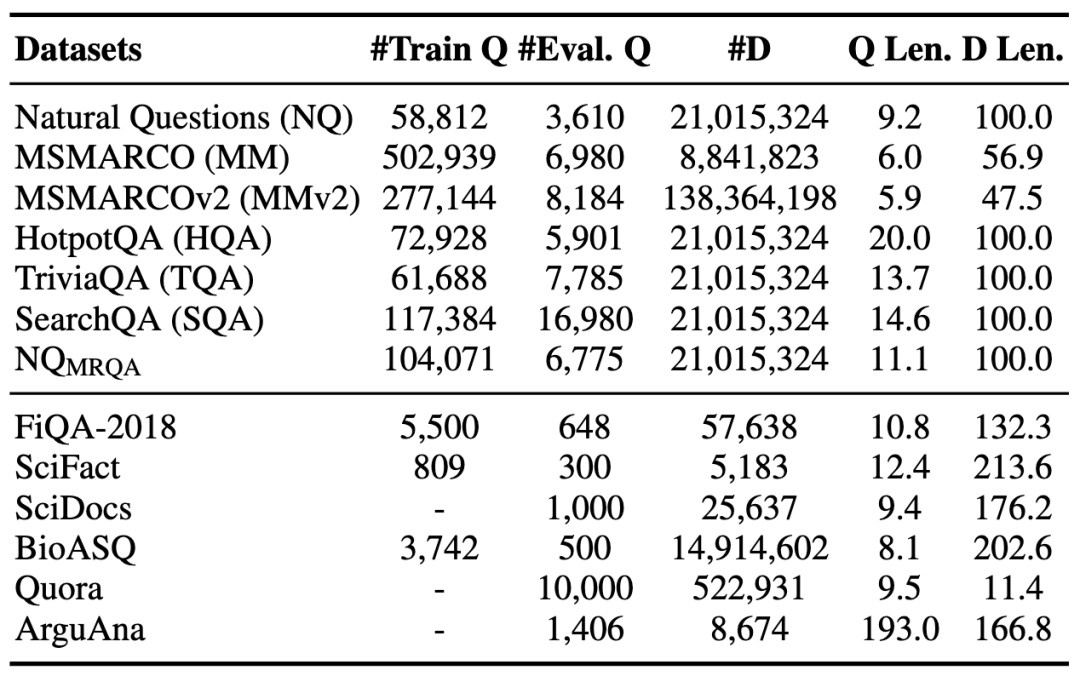
表1 数据集概览。上半部分为源领域数据集,下半部分为目标领域数据集
后续分析实验中,我们采用控制变量法,分别调整源领域上训练样本的构造方式,从而探索样本层面不同因素对于模型zero-shot能力的影响。我们使用
MSMARCO和NQ上的初步分析
为了初步理解稠密检索模型的zero-shot泛化能力,我们首先在两个最常用的公开检索数据集MSMARCO和NQ上进行实验。本文中我们使用RocketQAv2[1]作为基础模型,在这两个数据集上分别训练模型(RocketQA(MSMARCO/NQ)),同时进行了域内和域外的模型性能评测,结果如下表所示:
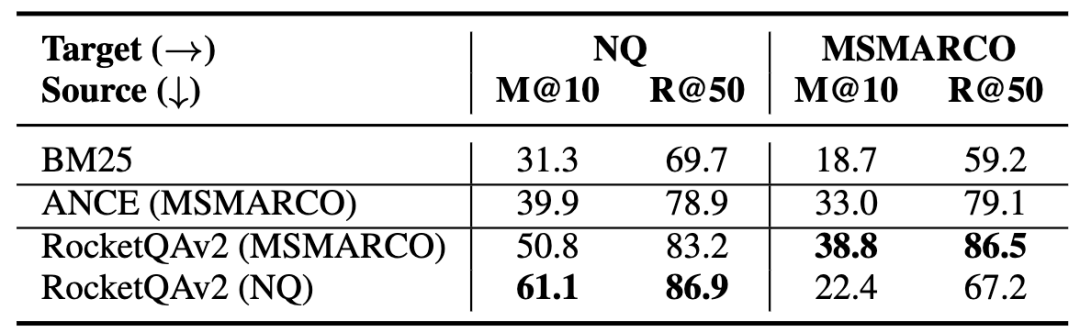
表2 MSMARCO和NQ上的评估结果
可以发现,在这两个数据集上,稠密检索模型的zero-shot评估结果均优于BM25。同时,RocketQAv2(MSMARCO)的zero-shot泛化性能损失(MRR@10 61.1 -> 50.8)要低于RocketQAv2(NQ)的zero-shot泛化性能损失(MRR@10 38.8 -> 22.4),说明在MSMARCO上训练的稠密检索模型的zero-shot泛化性能更好。
进一步,我们还在六个目标域数据集上分别测试了RocketQAv2(MSMARCO)和RocketQAv2(NQ)的zero-shot性能(表3 A部分)。我们发现RocketQAv2(MSMARCO)几乎在所有目标域数据集上的性能都领先于RocketQAv2(NQ)。另外值得注意的是,BM25也是一个较强的baseline,在某些数据集上大幅领先稠密检索模型。
通过初步实验,可以发现在不同的源域数据集上训练的模型的zero-shot泛化能力存在差异,但是由于MSMARCO和NQ的差异点很多,从目前的实验结果不能得到更多的结论。接下来,我们会从多个方面深入地分析有哪些因素影响着模型的zero-shot泛化能力。
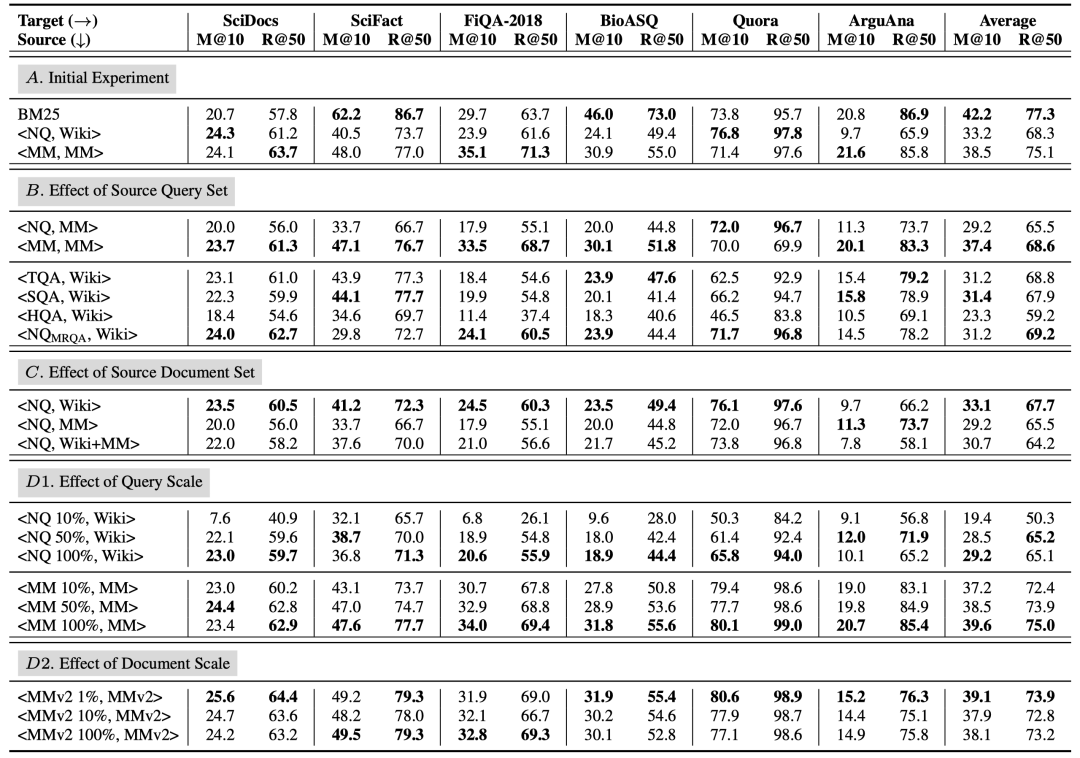
表3 六个目标集上的评估结果。M@10和R@50分别为检索模型的MRR@10和Recall@50的结果
分析与发现
1. 源领域query集合的影响
实验结果
为了研究源域query集合分布的影响,我们在下面的实验中固定住document集合不变,只改变query集合进行分析。
首先,我们固定MSMARCO作为document集合,分别使用NQ和MSMARCO的query集合构造训练数据。另外,我们还收集了MRQA中的四个数据集,包括TriviaQA,SearchQA,HotpotQA和NQ,它们统一使用Wikipedia作为document集合。
表3(B部分)展示了模型在六个目标数据集上的zero-shot结果。使用NQ训练的模型整体的zero-shot泛化性能弱于使用MSMARCO训练的模型,和上面初步实验中的结果一致,这也证明了源域query集合对稠密检索模型的zero-shot能力有比较大的影响。同时我们发现HotpotQA训练的模型在目标域数据集上的效果最差,因为它的query主要由多跳问题组成,说明特殊格式的源域query集合可能会影响模型的zero-shot泛化性能。
基于这些实验分析,我们对更细节的因素进行了研究。
query的词汇重叠
词汇重叠率是衡量两个领域相似性的重要指标,对于每个源域query集合和目标域query集合的组合,我们计算了它们的weighted Jaccard相似度,该指标越高说明两个集合的词汇重叠程度越高。
图1(红线)展示了在六个目标域上,不同的源域和目标域query词汇重叠程度与模型zero-shot性能的关系(对应表3结果),我们发现它们之间存在一定的正相关关系,因为更大的词项重叠程度意味着更大的领域相似度。document的词汇重叠情况也有类似的结果(蓝线),不再额外赘述。
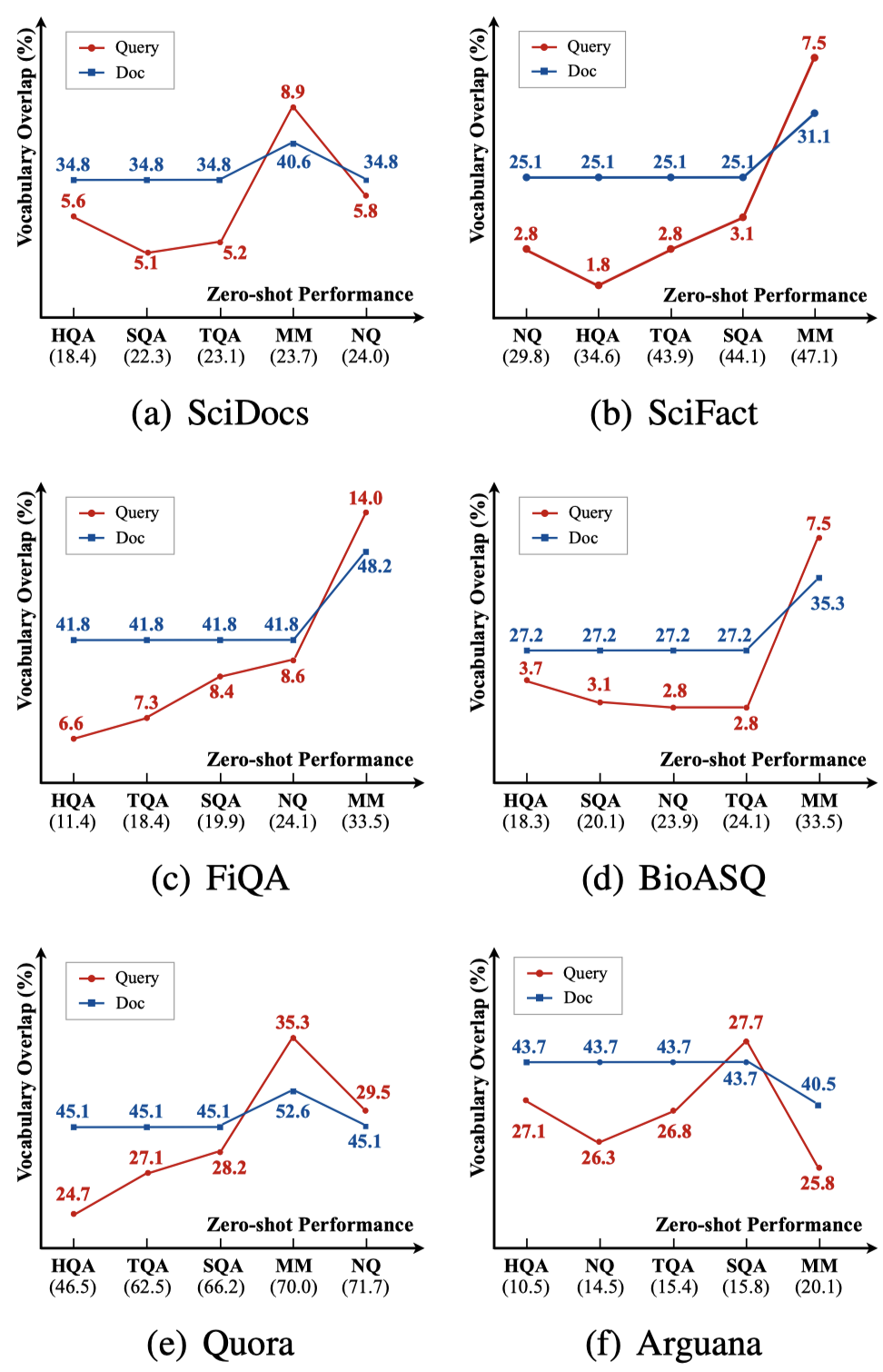
图1 词项重叠程度与zero-shot性能的关系。横坐标对应在不同源领域训练模型从低到高的zero-shot性能,纵坐标表示源领域和目标领域间query/document的词项重叠程度。
query的类型分布
另一个重要的因素是query的类型分布,我们分析了不同源域和目标域数据集各自的query类型分布,主要关注“WH”、”Y/N“和陈述类的query占整个query集合的比例,我们同时计算了每个query类型分布的信息熵来体现平衡性,如图2所示。
首先,我们发现模型在query类型分布更均衡的源域数据集上训练模型可能有助于更稳定的整体zero-shot泛化性能。如图2所示,MSMARCO数据集包含最全面和多样化的query类型,这使得在该数据集训练的模型具有最好的zero-shot能力。虽然NQ数据集多样性也较高,但是该数据集上占比最高query类型的是”Who“类型,我们猜测由于这种问题类型在其他大多数数据集中出现频率较低,过度学习该类型的问题可能不利于模型的zero-shot泛化能力。
另外,当源域和目标域query集合的query类型分布一致性较高时,模型在该目标域上的zero-shot泛化性能也较好。比如在SearchQA上训练的模型在ArguAna和SciFact数据集上都有不错的表现,而这几个数据集中的query绝大多数都为陈述类问题。
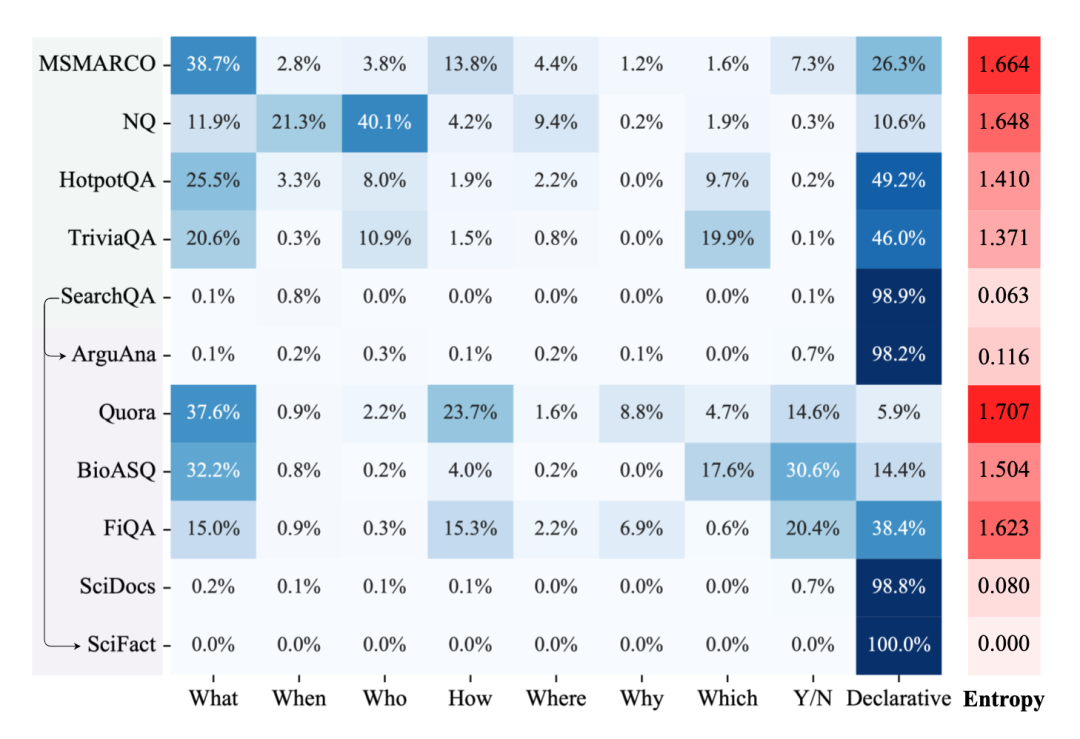
图2 各数据集的query类型分布及信息熵
2. 源领域document集合的影响
与针对query集合的分析类似,我们在不同实验设置下固定NQ的query集合作为源域query集合,并分别使用Wikipedia和MSMARCO作为源域document集合,另外我们还合并了这两个集合组成一个新的document集合,用于研究在原document集合中引入额外document的影响。
测试结果如表3(C部分)所示,我们发现引入了额外document后,训练出来的模型在目标域上的zero-shot性能有所下降。一个可能的原因是query集合的短答案标注是基于原始的document集合,而这种数据标注方式并不能很好地适应其他document集合,从而导致性能下降。但从整体上来看,document集合的影响不如query集合的影响显著。
3. 数据规模的影响
由于稠密检索比较依赖于大规模训练数据,因此数据规模的影响也值得关注。
Query规模
Query的规模指源域数据集上训练集query的数量。我们使用不同数据规模的NQ和MSMARCO数据集进行实验,每个数据集的训练集中随机采样10%、50%和100%的query子集,构造三组训练集,分别训练模型并进行域内和域外的测试。
表4展示了模型在NQ和MSMARCO上的域内测试效果,表3(D1部分)展示了模型在六个目标域上的zero-shot性能。首先可以发现,随着query规模的提高,模型在域内和域外的性能都有提高,在数据规模较小时,模型性能对于query规模的变动可能更敏感。另外,“NQ 100%”和“MSMARCO 10%”数据量基本一致,但是MSMARCO训练的模型仍然具有较好的zero-shot性能,说明了MSMARCO数据集上更好的zero-shot泛化能力并不完全来自于更大的query规模。
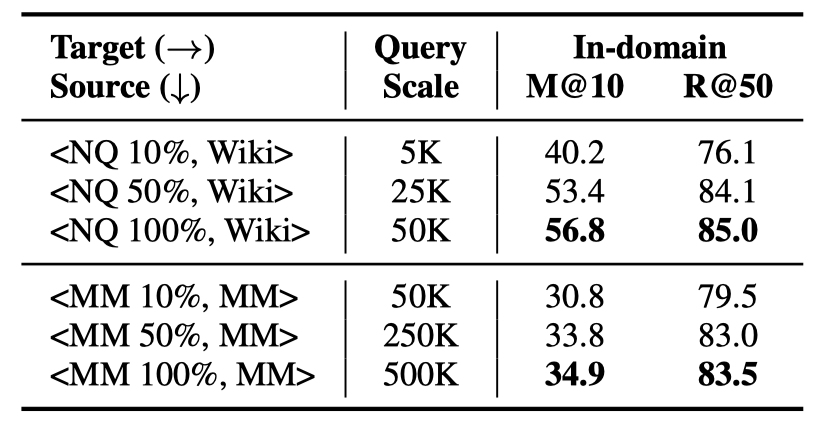
表4 不同规模query集合训练的模型在NQ和MSMARCO上的领域内测试结果
Document规模
我们使用MSMARCOv2 passage版本的数据集进行document规模的分析,它拥有140M左右段落,据我们所知,这是目前最大的公开document集合。
我们随机从MSMARCOv2的document集合中采样了1%、10%和100%三个子集,各包含1.4M、14M和140M的document,结合MSMARCOv2的query集合,构造了三组训练数据来训练模型。
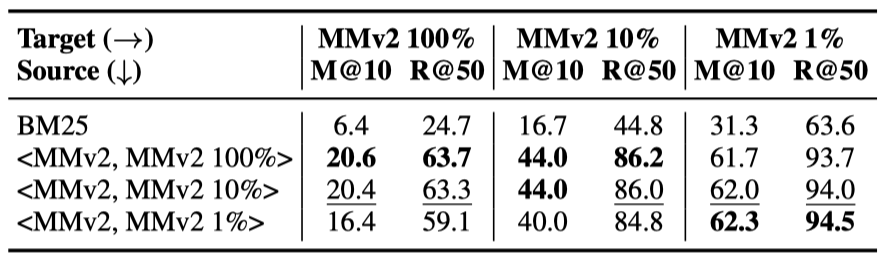
表5 MSMARCOv2上的不同document规模实验
首先我们使用采样的三组不同规模的document集合,在MSMARCOv2 dev集合上对三个模型进行了测试。如表5所示,在更大规模的域内document集合上训练的模型在域内看起来有更好的性能。
之后,我们依然在目标领域上对上述三个模型进行了zero-shot性能测试。我们意外地发现使用1% document规模训练的模型获得了最好的zero-shot效果。我们猜测在更大规模的document集合上采样的负样本可能带来更丰富的本领域特征,导致对本领域的过度拟合,这可能会损害模型在其他领域上的泛化能力。
进一步地,我们查看了MSMARCOv2上三个document集合、以及MSMARCO上document集合的主题重合情况,使用与前文类似的方法计算不同document集合间的词项重叠率。我们发现虽然MSMARCOv2有大规模的document集合,但相比于MSMARCO和MSMARCOv2的两个子集,并没有带来与数据量成正比的更丰富的主题,可能这也是模型在这种大规模document库上效果不佳的原因之一,即对源域上的document集合产生了过拟合。
4. 目标集合的有偏情况
BEIR[2]指出了稀疏检索模型通常被用于数据集构造,这可能导致BM25在这种数据集上的评测结果偏高。因此,我们定量地研究了这种有偏情况是如何影响稀疏检索和稠密检索模型的zero-shot泛化性能的。
我们计算了不同目标域测试集上query和正例document间的词项重叠率,并研究这种词项匹配程度如何影响不同检索模型的zero-shot泛化性能。这里的词项重叠率计算方式为每对query-document中出现词项重叠的个数除以query长度(去掉停用词后),并在整个测试集上求平均。
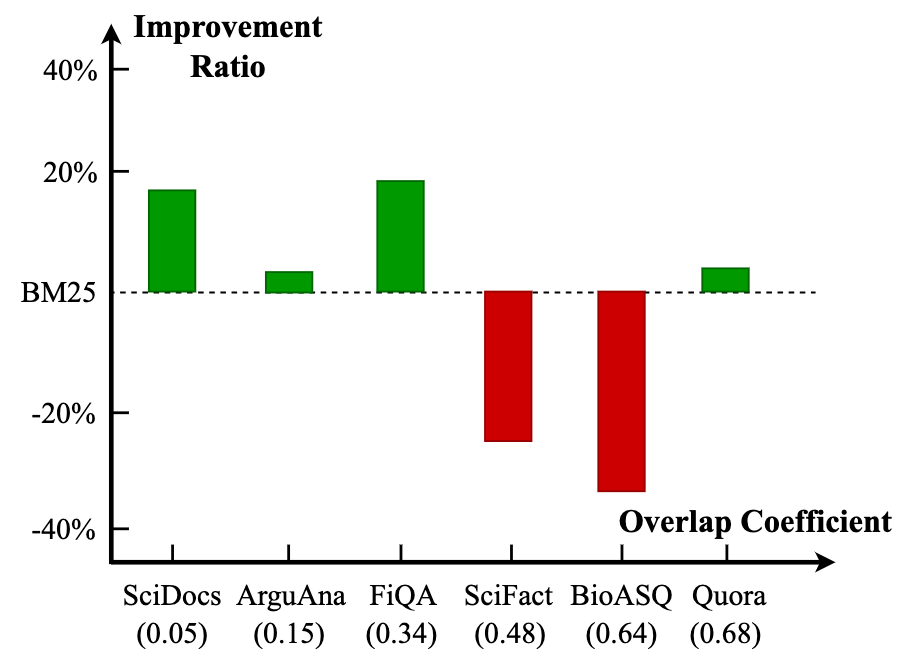
图3 稠密检索模型相比于BM25的效果提升比例和query与标注document的overlap coefficient间的关系
我们计算了六个目标域测试集上query和正例document的词项重叠率,并据其对数据集做排序。图3展示了其与稀疏、稠密检索模型的性能差异的关系。
我们发现整体上,BM25在有更大词项重叠率的目标域测试集上表现更好,这也与预期相符,而稠密检索模型在词项重叠率更小的时候有更好的表现,这说明现有的数据集中确实存在一定程度的模型偏好,从而导致BM25相比于稠密检索模型有着更好的zero-shot泛化性能,这种有偏情况体现在query和标注的document之间的词项重叠率中。
模型分析
现有方案归纳
表6总结了现有的zero-shot稠密检索相关的方法。随后,我们分类讨论了目前的主要技术以及代表性方法。
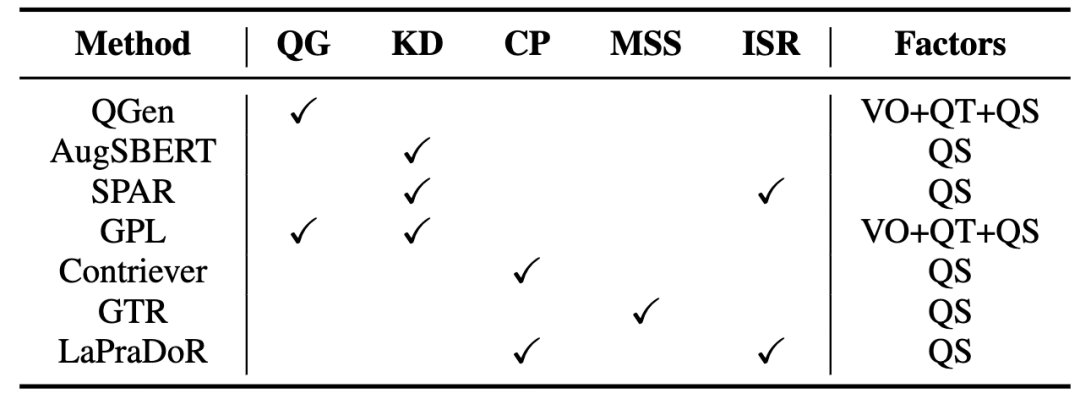
表6 Zero-shot稠密检索方法及其采用的技术和涉及到的影响因素。其中VO、QT和QS分别代表vocabulary overlap,query type和query scale
Query生成(QG)
Query生成方法通常使用现成的query生成模型为目标域的document生成伪query,从而实现目标域的数据增广。这种方法可以提高源域和目标域的词汇重叠率,同时也提高了训练数据规模(query规模)。比如QGen[3]在源域训练了一个生成模型,为目标域的document生成伪query;GPL[4]使用一个经过预训练的T5模型生成伪query然后使用MarginMSE loss来实现更稳定的模型训练。
知识蒸馏(KD)
知识蒸馏是稠密检索中一个常用的方法,其利用一个性能更强大的教师模型来提升稠密检索模型的性能。当前研究表明,这种方式也有助于提高模型的域外检索性能。基于知识蒸馏的方法缓解了数据匮乏的问题,其相当于增加训练数据规模(query规模)。比如AugSBERT[5]和GPL使用一个交互式模型来标注无标签的query-document对训练稠密检索模型;SPAR[6]提出通过使用BM25召回的段落让稠密检索模型蒸馏BM25的知识。
对比学习预训练(CP)
随着无监督对比学习在NLP领域的兴起,研究者开始应用该方法到zero-shot稠密检索中。其基本思路为利用无标签语料库构造大规模伪标签训练数据,让模型可以在预训练阶段就学会捕获两个文本间的匹配关系,其本质上仍然是增大训练数据规模。Contriever[7]和LaPraDoR[8]是两个典型的无监督预训练方法,它们通过dropout等方法构造了大规模的伪标签预训练数据进行对比学习预训练。
扩大模型规模(MSS)
增大预训练语言模型的规模带来性能提升已经成为了一个广泛的共识。近期,这种方法也已经在zero-shot稠密检索领域得到了证明。GTR[9]是一个基于50亿参数的T5模型的稠密检索模型,其使用了20亿query-document对进行预训练,证明了增大模型和数据的规模可以持续带来性能提升。
结合稀疏检索(ISR)
很多工作已经指出稀疏检索在zero-shot场景下的强大能力,稀疏检索和稠密检索模型在处理不同数据时各有优劣。因此,对这两种模型做一个有效的结合是很重要的性能提升手段,我们认为该方法更多地是实现了稠密检索和稀疏检索模型的集成。比如SPAR通过知识蒸馏的方式把稀疏检索模型的能力融入稠密检索模型中;LaPraDoR把稀疏检索模型和稠密检索模型的相似度打分进行了乘性结合,提升了模型的zero-shot泛化能力。
方法比较
我们本着尽量进行公平对比的原则,对现有的zero-shot稠密检索方法性能进行了整理,提取或复现了部分方法在三个目标数据集上的效果,展示在表7中。
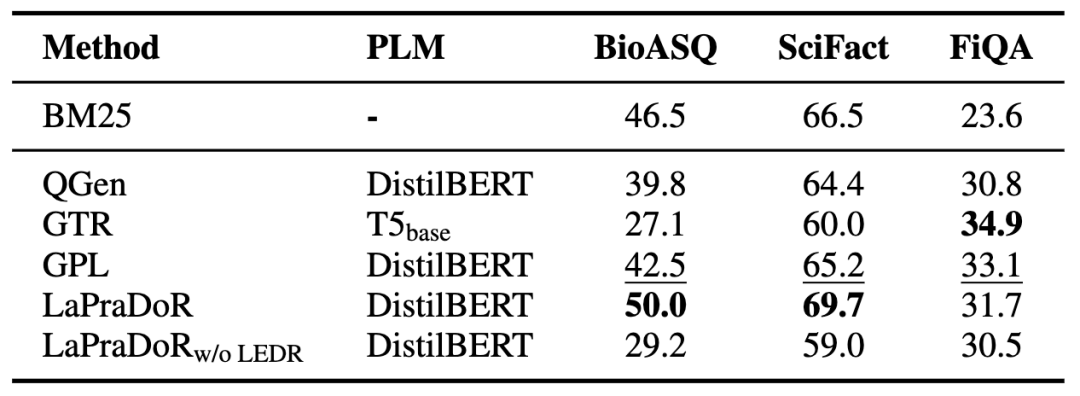
表7 不同方法在三个目标领域数据集上的NDCG@10结果
首先我们发现LaPraDoR整体表现最好,而去掉ISR策略后,模型性能在BioASQ和SciFact上有较大下滑,说明引入稀疏检索模型在有偏情况较严重的数据集上更有效。GPL也获得了较好的效果,它涉及到前文分析中的提升词汇重叠程度、提高query规模和拟合query类型分布三个因素。我们也发现,除了结合稀疏检索类方法,现有方法的zero-shot性能在BioASQ和SciFact数据集上仍然整体落后于BM25。我们猜测其原因很大程度上是前文分析提到的这两个数据集比较依赖于词项匹配,导致稠密检索方法相比于稀疏检索方法具有天然的劣势。
总结和展望
本文深入地研究了稠密检索模型在zero-shot场景下的泛化能力,广泛地分析了不同因素对模型zero-shot泛化能力的影响。具体来讲,我们发现词汇重叠、query类型分布以及数据规模是影响该能力的重要因素。另外,数据集的构造方式可能会影响对稀疏检索模型和稠密检索模型的zero-shot泛化能力的对比。我们认为,稠密检索模型的zero-shot泛化能力仍有提升空间,并且值得进一步地深入研究。
审核编辑 :李倩
-
模型
+关注
关注
1文章
3243浏览量
48834 -
检索
+关注
关注
0文章
27浏览量
13155 -
自然语言处理
+关注
关注
1文章
618浏览量
13560
原文标题:总结和展望
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【书籍评测活动NO.52】基于大模型的RAG应用开发与优化
模块化仪器的技术原理和应用场景
华为云 Astro Zero 低代码平台案例:小、轻、快、准助力销售作战数字化经营
大模型时代,程序员当下如何应对 AI 的挑战






 工商网监
工商网监
评论