Arm处理器是基于精简指令集计算机(RISC)原理设计的,指令集和相关译码机制较为简单,具有32位Arm指令集和16位Thumb指令集,Arm指令集效率高,但是代码密度低,而Thumb指令集具有更好的代码密度,却仍然保持Arm的大多数性能上的优势,它是Arm指令集的子集。所有Arm指令都是可以有条件执行的,而Thumb指令仅有一条指令具备条件执行功能。Arm程序和Thumb程序可相互调用,相互之间的状态切换开销几乎为零。
Cortex-M0处理器基于ARMv6-M架构,是一款功耗和性能较为均衡的处理器。Cortex-M0只支持56条指令的小指令集,其中大部分指令是16位指令。
Arm Cortex-M 指令集对比:
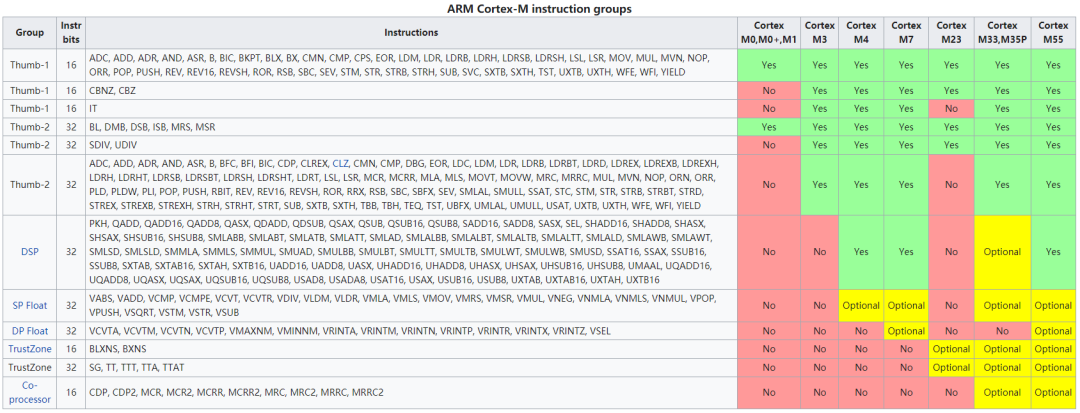
1. 指令集
1.1 在处理器内移动数据
MOV,;RmandRncanbehighorlowregisters. MOVS, MOVS,#immed8;8位立即数值 MRS, MSR,
1.2 存储器访问
确保访问的内存地址是对齐的,这一点很重要。在ARMv6-M架构(包括Cortex-M0和Cortex-M0处理器)上不支持非对齐传输。任何未对齐内存访问的尝试都会导致HardFault异常。
LDR
1.3 栈空间访问
PUSH{,,..} PUSH{,,..,LR} POP{,,..} POP{,,..,PC}
1.4 算数运算
ADD,;Rd=Rd+Rm.Rd,Rmcanbehighorlowregisters. ADDS,,;Rd=Rn+Rm SUBS,,;Rd=Rn–Rm ADDS,,#immed3;Rd=Rn+ZeroExtend(#immed3) SUBS,,#immed3;Rd=Rn–ZeroExtend(#immed3) ADDS,#immed8;Rd=Rd+ZeroExtend(#immed8) SUBS,#immed8;Rd=Rd–ZeroExtend(#immed8) ADCS,,;Rd=Rd+Rm+Carry SBCS,,;Rd=Rd–Rm–Borrow ADDSP,SP,#immed7;SP=SP+ZeroExtend(#immed7<<2) SUB SP, SP, #immed7 ; SP = SP – ZeroExtend(#immed7<<2) ADD SP, ;SP=SP+Rm.Rmcanbehighorlowregister. ADD,SP,;Rd=Rd+SP.Rdcanbehighorlowregister. ADD,SP,#immed8;Rd=SP+ZeroExtend(#immed8<<2) ADD ,PC,#immed8;Rd=(PC[31:2]<<2) + ZeroExtend(#immed8<<2) ADR ,
1.5 逻辑运算
ANDS,,;Rd=AND(Rd,Rm) ORRS,,;Rd=OR(Rd,Rm) EORS,,;Rd=XOR(Rd,Rm) BICS,,;Rd=AND(Rd,NOT(Rm)) MVNS,;Rd=NOT(Rm) TST,;AND(Rn,Rm)
1.6 移位和循环操作
ASRS,,#immed5;Rd=Rm>>immed5 LSLS,,#immed5;Rd=Rm<<#immed5 LSRS ,,#immed5;Rd=Rm>>#immed5ASRS,,;Rd=Rd>>Rm LSLS,,;Rd=Rd<,,;Rd=Rd>>RmRORS,,;Rd=RdrotaterightbyRmbits //Rotate_Left(Data,offset)=Rotate_Right(Data,(32-offset))
1.7 展开和顺序反转操作
这些反向指令通常用于在小端和之间转换数据大整数。
REV,;Byte-ReverseWord //Rd={Rm[7:0],Rm[15:8],Rm[23:16],Rm[31:24]} REV16,;Byte-ReversePackedHalfWord //Rd={Rm[23:16],Rm[31:24],Rm[7:0],Rm[15:8]} REVSH,;Byte-ReverseSignedHalfWord //Rd=SignExtend({Rm[7:0],Rm[15:8]})
1.8 扩展操作
它们通常用于数据类型转换。
SXTB,;SignedExtendedByte //Rd=SignExtend(Rm[7:0]) SXTH,;SignedExtendedHalfWord //Rd=SignExtend(Rm[15:0]) UXTB,;UnsignedExtendedByte //Rd=ZeroExtend(Rm[7:0]) UXTH,;UnsignedExtendedHalfWord //Rd=ZeroExtend(Rm[15:0])
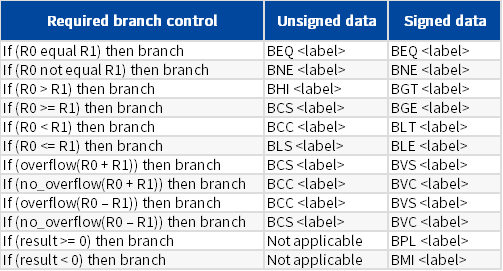
1.9 程序流控制
B
条件转移指令B
1.10 内存屏障指令
在Cortex-M0和Cortex-M0处理器上支持内存屏障指令,从而在Cortex-M处理器和其他ARM处理器家族中提供更好的兼容性。
//数据内存屏障,确保所有内存访问都完成 //在新的内存访问被提交之前。
DMB
//数据同步屏障,确保所有的内存访问都完成 //在执行下一条指令之前。
DSB
//指令同步障碍,刷新管道和 //确保之前所有的指令都已完成 //在执行新指令之前。
ISB
1.11 异常相关指令
SVC ; Supervisor call CPSIE I ; Enable Interrupt (Clearing PRIMASK) CPSID I ; Disable Interrupt (Setting PRIMASK)
1.12 睡眠模式功能相关说明
//等待中断,停止程序执行,直到一个中断到达, //如果处理器进入调试状态。
WFI
//等待事件,如果设置了内部事件寄存器,则清除 //内部事件注册和继续执行。 //停止程序执行,直到事件(如中断)到达 //如果处理器进入调试状态。
WFE
//发送事件,设置本地事件寄存器并发送一个事件脉冲 //多处理器系统中的其他微处理器。
SEV
1.13 其他说明
NOP;NoOperation BKPT;Breakpoint YIELD;ExecuteasNOPontheCortex-M0processor
2. 指令说明
2.1 可访问high registers的指令
绝大部分指令只能访问low registers,也就是只能访问R0~R7寄存器。可以访问high registers的指令只有两条,这两条指令都不更新APSR,指令没有S后缀。
MOV,;RmandRncanbehighorlowregisters. ADD,;Rd=Rd+Rm.Rd,Rmcanbehighorlowregisters.
其它两条和SP加法有关的可以访问high registers的指令其本质是ADD指令。
ADDSP, ADD,SP,
2.2 分配临时变量的指令
函数内的临时变量分配到堆栈,进入函数给临时变量分配空间时使用SUB指令。
SUB SP, SP, #immed7 ; SP = SP – ZeroExtend(#immed7<<2)
退出函数释放临时变量空间时使用ADD指令。
ADD SP, SP, #immed7 ; SP = SP + ZeroExtend(#immed7<<2)
上面两条指令的立即数只有7位,最多可以增减SP指针127个字空间,如果超过127个字,使用这条指令:
ADD SP, ; SP = SP + Rm. Rm can be high or low register.
只有ADD指令,没有SUB指令,如果需要SUB,那么给Rm赋值负数即可。
2.3 取临时变量地址的指令
在堆栈分配了临时变量空间后,总要取得临时变量的地址才能做进一步的操作。
ADD , SP, #immed8 ; Rd = SP + ZeroExtend(#immed8<<2)
立即数不够,可以用寄存器。
ADD , SP, ; Rd = Rd + SP. Rd can be high or low register.
2.4 RSBS指令
RSBS , , #0 ; Rd = 0 – Rm, Reverse Subtract (negative)
这是倒过来的减法,常量减去寄存器值,而且常量只能是0。所以这条指令实质上就是一条取负数指令。
Rd = 0 - Rm 等价于:Rd = -Rm Rd 寄存器值等于负的 Rm 寄存器值。
 一文详解Arm Cortex-M处理器指令集
一文详解Arm Cortex-M处理器指令集







评论