 Swin Transformer在MIM中的应用
Swin Transformer在MIM中的应用
自何恺明MAE横空出世以来,MIM(Masked Image Modeling)这一自监督预训练表征越来越引发关注。
但与此同时, 研究人员也不得不思考它的局限性。
MAE论文中只尝试了使用原版ViT架构作为编码器,而表现更好的分层设计结构(以Swin Transformer为代表),并不能直接用上MAE方法。
于是,一场整合的范式就此在研究团队中上演。
代表工作之一是来自清华、微软亚研院以及西安交大提出SimMIM,它探索了Swin Transformer在MIM中的应用。
但与MAE相比,它在可见和掩码图块均有操作,且计算量过大。有研究人员发现,即便是SimMIM的基本尺寸模型,也无法在一台配置8个32GB GPU的机器上完成训练。
基于这样的背景,东京大学&商汤&悉尼大学的研究员,提供一个新思路。

不光将Swin Transformer整合到了MAE框架上,既有与SimMIM相当的任务表现,还保证了计算效率和性能——
将分层ViT的训练速度提高2.7倍,GPU内存使用量减少70%。
来康康这是一项什么研究?
当分层设计引入MAE
这篇论文提出了一种面向MIM的绿色分层视觉Transformer。
即允许分层ViT丢弃掩码图块,只对可见图块进行操作。
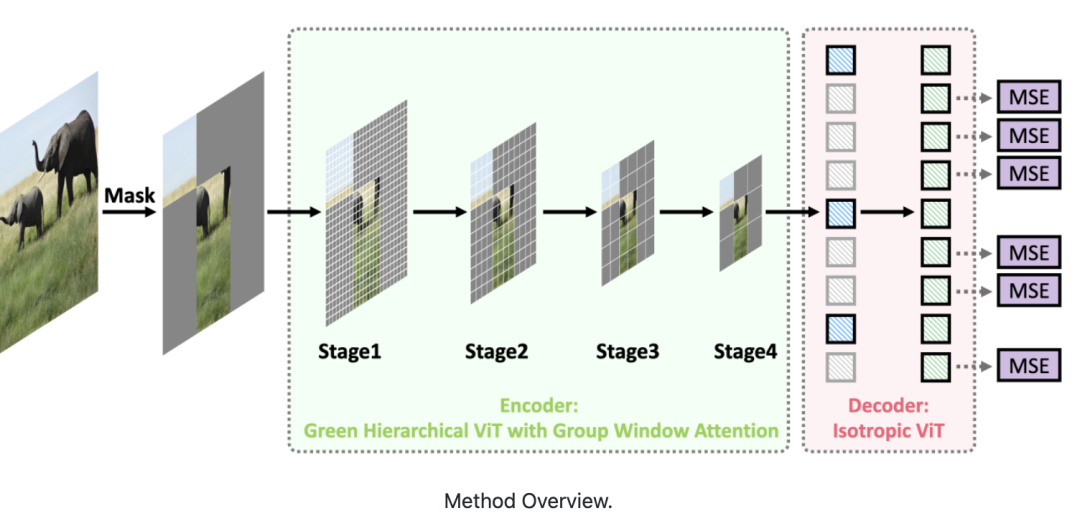
具体实现,由两个关键部分组成。
首先,设计了一种基于分治策略的群体窗口注意力方案。
将具有不同数量可见图块的局部窗口聚集成几个大小相等的组,然后在每组内进行掩码自注意力。
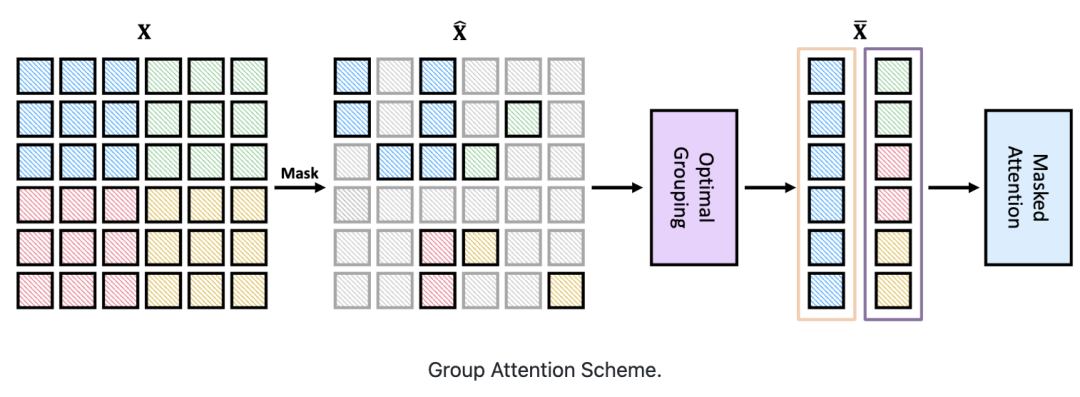
其次,把上述分组任务视为有约束动态规划问题,受贪心算法的启发提出了一种分组算法。

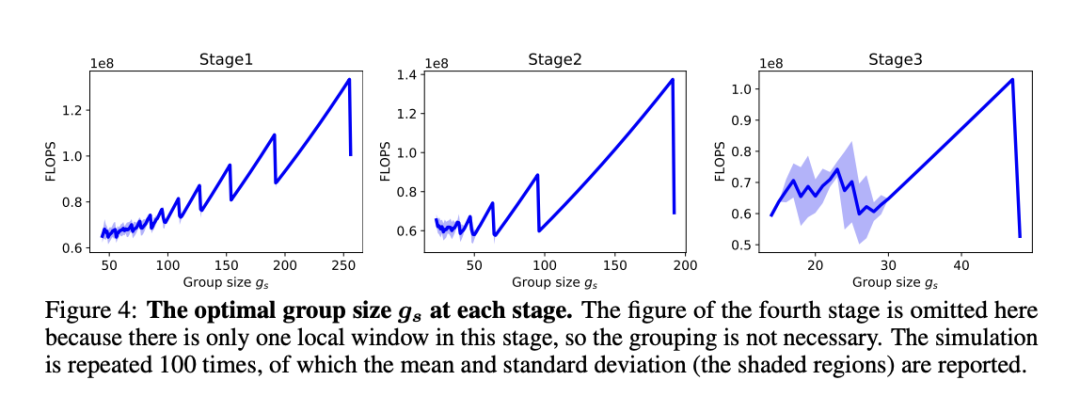
它可以自适应选择最佳分组大小,并将局部窗口分成最少的一组,从而使分组图块上的注意力整体计算成本最小。
表现相当,训练时间大大减少
结果显示,在ImageNet-1K和MS-COCO数据集上实验评估表明,与基线SimMIM性能相当的同时,效率提升2倍以上。
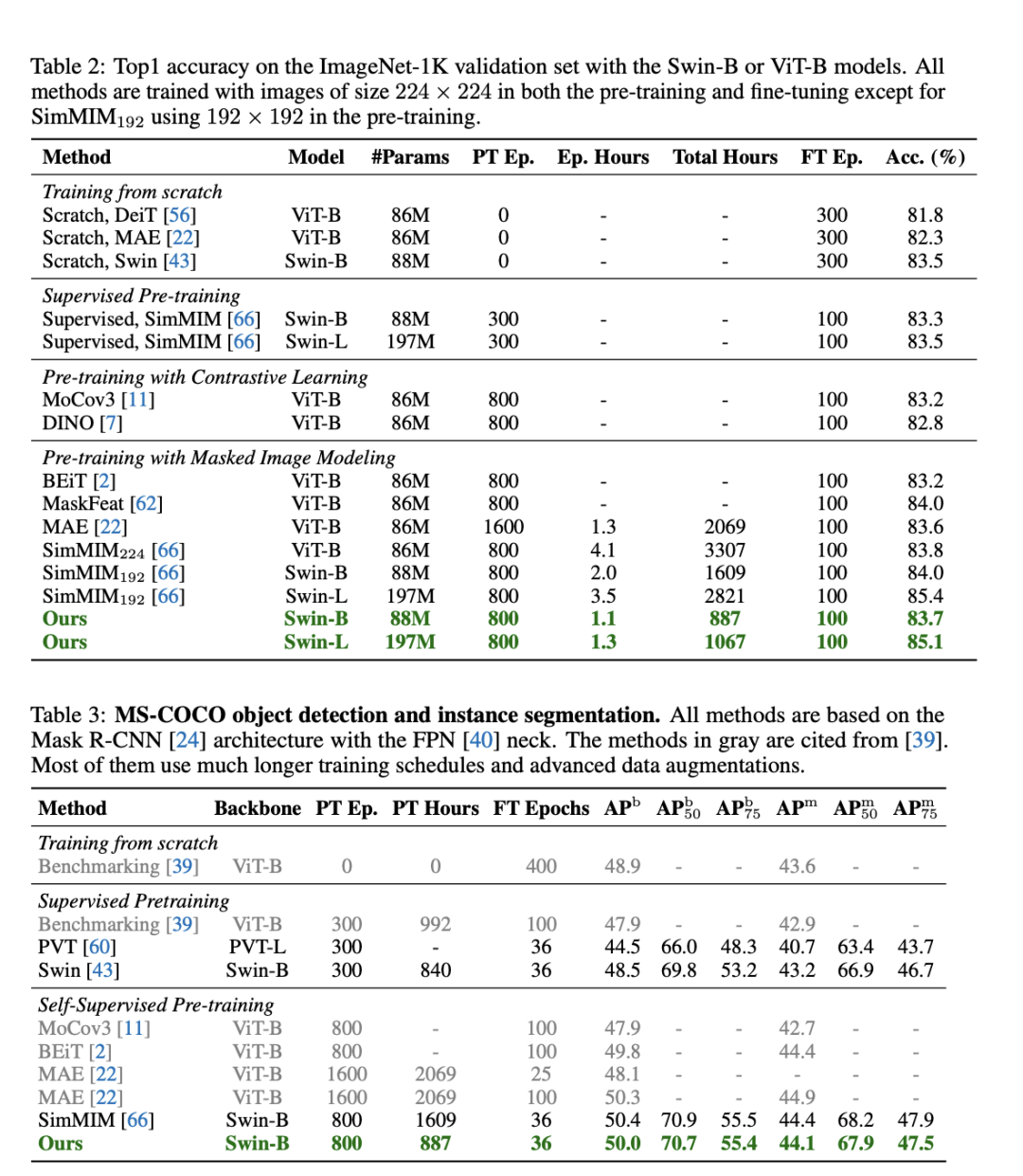
而跟SimMIM相比,这一方法在所需训练时间大大减少,消耗GPU内存也小得多。具体而言,在相同的训练次数下,在Swin-B上提高2倍的速度和减少60%的内存。

值得一提的是,该研究团队在有8个32GB V100 GPU的单机上进行评估的,而SimMIM是在2或4台机器上进行评估。
研究人员还发现,效率的提高随着Swin-L的增大而变大,例如,与SimMIM192相比,速度提高了2.7倍。
实验的最后,提到了算法的局限性。其中之一就是需要分层次掩码来达到最佳的效率,限制了更广泛的应用。这一点就交给未来的研究。
而谈到这一研究的影响性,研究人员表示,主要就是减轻了MIM的计算负担,提高了MIM的效率和有效性。
审核编辑 :李倩
-
编码器
+关注
关注
45文章
3701浏览量
135690 -
数据集
+关注
关注
4文章
1212浏览量
24964
原文标题:何恺明MAE局限性被打破,与Swin Transformer结合,训练速度大大提升 | 东大&商汤&悉大
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何使用MATLAB构建Transformer模型

transformer专用ASIC芯片Sohu说明

Transformer是机器人技术的基础吗

自动驾驶中一直说的BEV+Transformer到底是个啥?

英伟达推出归一化Transformer,革命性提升LLM训练速度
Transformer能代替图神经网络吗
Transformer语言模型简介与实现过程
Transformer架构在自然语言处理中的应用
Transformer模型在语音识别和语音生成中的应用优势
使用PyTorch搭建Transformer模型
Transformer 能代替图神经网络吗?

基于xLSTM和Transformer的模型评估:xLSTM在“语言能力”的表现
视觉Transformer基本原理及目标检测应用





 工商网监
工商网监
评论