 处理器架构探索的混合创新
处理器架构探索的混合创新

架构探索一直是产品设计的圣杯。它有可能彻底改变产品工程。研究和用例评估表明,在架构探索期间可以实现 80% 的系统优化和几乎 100% 的性能/功耗权衡。
不幸的是,除了公司投入大量资源和时间的利基领域外,架构探索未能起飞。架构探索被高度误解,并且已经推出了声称架构探索但围绕现有产品(例如指令集模拟器、软件时序分析器和硬件验证)的产品。用一组类库突出显示语言不足以建立方法、轻松创建模型、针对基准进行验证和性能系统优化。
架构探索的主要障碍是缺乏高端内核、互连、缓存和内存的架构模型。有限的模型范围往往适用于架构探索不会增加显着价值的低端处理器,每秒运行最多 1,000 条指令的周期精确模型,需要很长时间来安装、学习和组装,并在 IP 发货后很好地发布。这些模型需要数周时间才能运行一个基准测试,并且对于比较验证很有用。此外,它们不能跨内核、SoC、系统和软件进行扩展。
架构模型往往是 IP 提供商和 EDA 供应商的低优先级,因为他们必须提供 RTL 和软件工具,例如编译器、调试器和验证 IP。此外,为大规模分发创建架构模型需要特殊的技能,因为每个核心类型的流程都重新开始。组装需要很长时间,需要多种资源,并且运行速度极慢。每个新的处理器内核都有很多变化——缓存的读/写宽度、多线程、ISA 版本、可变流水线阶段、用于将指令分派到执行单元的调度逻辑以及指令缓冲区。
具有随机性的传统架构模型被组装大型系统和数据中心的公司使用。这些模型将模拟不同类型的请求和任务的延迟和功耗。
另一个主要问题是验证过程。对于新处理器,用于验证模型准确性的基准数据有限。这个问题对于功耗、高速缓存命中未命中率和内存吞吐量而言更为严重。当然,FPGA 板可以通过使用旧版本的内核以及更新的缓存、互连和内存设置来减轻一些负载。测试新内核正确性的最佳方法是仔细检查每个可能的场景,包括并发执行,运行缓存层次结构和 DMA 的旧跟踪,并生成确保绝对覆盖的场景。
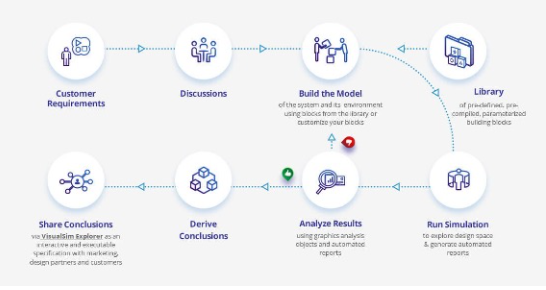
图 1:基于 RISC-V 和 ARM 的 VisualSim 处理器架构探索
Mirabilis Design 最近采用的一种方法是在具有图形开发环境的离散事件模拟器上提供混合处理器架构库。这类架构模型消除了早期方法的所有问题。这是一个通用的生成器,它使用电子表格来定义核心配置。内部定序器通过消除不影响流正确性、性能和功率的逻辑来优化仿真性能,并提供灵活的选项列表来定义不同的管道变体。这种方法的美妙之处在于可以快速构建新的甚至不存在的内核。
这种方法有多种好处,包括:
单个库模块可以将微控制器建模为高性能处理器。
处理器库具有研究单个集群、多核集群组、片上系统和完整系统(如 ECU、雷达或超级计算机)的仿真性能。
这种方法提供了一个庞大的供应商内核库。
混合核心与随机核心不同,具有运行软件跟踪的能力。
扩展库具有使生成的内核与缓存、动态系统缓存、TileLink、AMBA AXI、NoC、DDR、LPDDR、GDDR、DMA 和桥完全集成的所有连接性和方法。
这些使用混合处理器的模型可用于选择时钟速度、缓冲区大小、宽度和容量,同时提供拓扑、路由、flit 大小和设备连接性。在电源方面,系统模型可以确定最佳电源状态集和最佳电源管理算法。在这个早期阶段分析功率可以深入了解配电、电池容量、充电系统和热要求。混合模型的准确性使软件性能调整和调度器和仲裁器的选择成为可能。
需要为性能生成的所需指标是延迟、吞吐量、缓冲区占用率、命中率、流水线停顿、MIPS 和周期/指令。对平均和瞬时功率、能耗、每个任务和设备的功率以及能源管理算法的影响进行真正的功率分析指标。高级分析将涵盖功能正确性、发生故障时的行为和服务质量。
要在混合处理器中定义的属性包括对执行单元和延迟周期的 ISA 分配、浮点和整数单元的数量、每个集群的核心数、有序和无序的分布以及大/小数量核心。缓存配置可以涵盖包含/排除、容量、关联性、银行计数、暂存器的使用以及各种替换和写入策略。对于互连,吞吐量要求、缓冲区占用率、最有效的仲裁算法以及传输突发/闪存大小。在内存中,该模型可以测量跟踪、顺序和随机地址的带宽、延迟和打开/关闭页面。
在 SoC 级别,使用了 DMA 与 TCP 传输、张量操作探索和拆分锁安排。必须对系统进行跨集群的任务分区、内存控制器调度、路由器数量和设备连接性测试。随着系统越来越接近客户部署,可以扩展相同的模型以集成多处理器集成,最大限度地减少芯片到芯片的开销,将应用程序分配到处理器以及存储策略。
架构师可以从供应商列表中选择或在几天内创建一个新的。一旦处理器内核被实例化,用户就可以连接其他半导体 IP 以形成完整的 SoC。在短时间内,用户可以拥有一个多核多集群、基于 NoC 的 SoC,带有 GPU、TPU/AI 加速器、内存、显示控制器、以太网和其他接口。为了模拟这个模型,IO 由泊松分布和数据范围生成的数据流触发,处理器执行软件跟踪以执行模拟。多个 SoC 可以通过连贯的 PCIe 或 CXL 组合,或与高速以太网或可靠的 OpenVPX 背板连接。
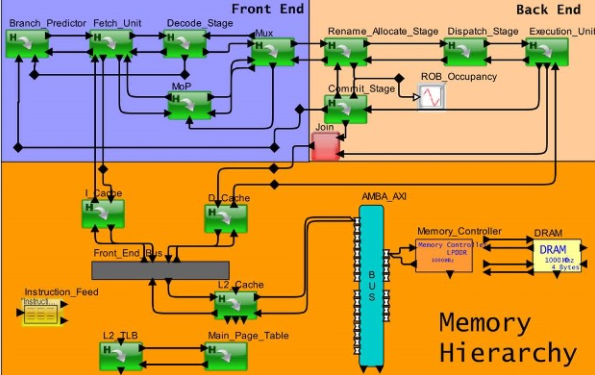
图 2:具有高速缓存存储器层次结构的乱序处理器管道的系统级模型
新的混合处理器对加载/存储行为具有指令感知,按顺序/无序执行,支持多指令获取和分派,支持每个流水线阶段的不同属性,支持之间的流控制阶段、任务发布队列、跳转流水线阶段、流水线和缓存之间的缓冲、可变读写宽度和抢占支持。混合方法可以扩展到 20 个整数、浮点、向量、分支、加载和存储类型的执行单元。同时,每个执行单元的流水线级数可以是可变的,最多可以定义为 20 个。
混合处理器的所有这些新功能都支持带有缓存地址的执行软件跟踪。为了准备在此处理器模型上执行的软件,全自动系统会生成指令序列、指令高速缓存地址和数据高速缓存地址以用于加载存储。架构模型与流量和软件执行的结合提供了一个有效的平台来测试内核、缓存、互连和内存的准确性。该测试涵盖了端到端设计的延迟和功耗,还测量了缓存命中率和内存吞吐量。这种新的基准测试方法可以增强用户的信心,并确保进行高质量的权衡分析。
新的混合处理器可供使用 ARM 或 RISC-V 内核开发定制 SoC 的系统公司、集成多个非异构主设备、加速器、GPU 和其他处理单元的半导体公司,以及实施新应用程序和高级 AI/ML 工作负载的 AI 公司使用。 系统和半导体的竞争在所有市场上都很重要,新产品的时间安排正在缩短。由于半导体短缺,公司必须更长时间地使用现有 SoC,识别新应用并支持现有设备上增加的功能。进行广泛的架构覆盖将提供对实际性能和容量的详细视图,从而为将产品集成到其环境中的客户提供有价值的见解。
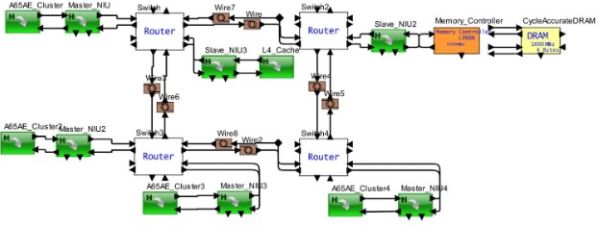
图 3:具有 Aaa65AE 的多集群多核处理器,用于汽车安全关键型应用
混合处理器的一个重要附带好处是能够运行软件并准确查看目标配置上的软件性能。当今的 SoC 配置非常复杂,以至于在 FPGA 上运行它会导致您错过一致性、数据分配、跨集群的工作负载分配以及数据路径和缓存之间复杂的通信。当一组软件任务在多核架构上同时运行时,软件团队可以及早了解时序和功耗。
类似地,每个内核都提供了缓存层次结构的变化以及与诸如回写、宽度、块大小、预取条件、存储体、关联性、私有与系统等项目的连接。然后是来自DDR、LPDDR、GDDR、HBM的内存,以及商业内存控制器中不同类型的调度器。最后,不同的互连选项:供应商特定的片上网络、极小的 NoC、AMBA 变体和 Tilelink。为此添加 DMA、网桥、中断、动态共享缓存单元、IO、以太网、CAN/CAN-FD 和 PCIe 以获得完整的要求。
混合处理器是电子设计行业的一项重大创新。它为架构师提供了更多的权力,并使团队能够在开发之前可视化系统行为。由于分析速度很快,真正的架构覆盖是可能的,并且可以涵盖性能、功率、服务质量、效率、可靠性和功能正确性。通过添加软件性能分析和调整,所有系统团队都可以在同一环境中参与。随着设计人员参与新应用、小型工艺技术和不断增加的功率要求,混合处理器是未来。
审核编辑:郭婷
-
处理器
+关注
关注
68文章
20368浏览量
255533 -
以太网
+关注
关注
41文章
6268浏览量
181838 -
soc
+关注
关注
40文章
4652浏览量
230507
发布评论请先 登录
探索Bourns® IsoMOV™ 混合保护器:电子保护新突破
探索LM9704实时数字图像处理器:功能、特性与应用
探索 HIP6302EVAL1:AMD 处理器多相电源转换解决方案
探索MPC184:强大的安全处理器
探索MCF548x ColdFire®微处理器:特性、设计考量与性能分析
探索MCF5207与MCF5208:高集成32位微处理器的技术剖析
探索ADSP - 21371/ADSP - 21375 SHARC处理器:高性能音频处理的利器
SMJ320C80数字信号处理器:架构、特性与应用全解析
探索TDA54x Jacinto™处理器:高性能与安全的完美融合
TAS3103A数字音频处理器:特性、架构与应用详解
Cortex-M0 处理器介绍
【「AI芯片:科技探索与AGI愿景」阅读体验】+第二章 实现深度学习AI芯片的创新方法与架构
龙芯处理器支持WINDOWS吗?
Analog Devices Inc. ADSP1802 SHARC®处理器数据手册
技术分享 | 如何在2k0300(LoongArch架构)处理器上跑通qt开发流程




评论