 如何使用xilinx的HLS工具进行算法的硬件加速
如何使用xilinx的HLS工具进行算法的硬件加速
【引言】
本系列教程演示如何使用xilinx的HLS工具进行算法的硬件加速。分为三个部分,分别为HLS端IP设计,vivado硬件环境搭建,SDK端软件控制。在HLS端,要将进行硬件加速的软件算法转换为RTL级电路,生成便于嵌入式使用的axi控制端口,进行数据的传输和模块的控制。【HLS介绍】
HLS可以将算法直接映射为RTL电路,实现了高层次综合。vivado-HLS可以实现直接使用 C,C++ 以及 System C 语言对Xilinx的FPGA器件进行编程。用户无需手动创建 RTL,通过高层次综合生成HDL级的IP核,从而加速IP创建。HLS的官方参考文档主要为:ug871( ug871-vivado-high-level-synthesis-tutorial.pdf )和ug902(ug902-vivado-high-level-synthesis.pdf)。 对于Vivado Hls来说,输入包括Tesbench,C/C++源代码和Directives,相应的输出为IP Catalog,DSP和SysGen,特别的,一个工程只能有一个顶层函数用于综和,这个顶层函数下面的子函数也是可以被综合的,会生成相应的VHDL和Verilog代码,所以,C综合后的RTL代码结构通常是跟原始C描述的结构是一致的,除非是子函数功能很简单,所需要的逻辑量很小。并不是所有的C/C++都可以被综合,动态内存分配和涉及到操作系统层面的操作不可以被综合。Vivado HLS 的设计流程如下:
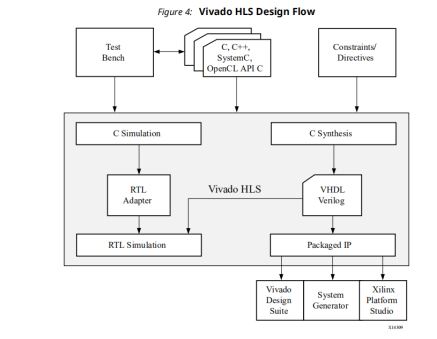
在整个流程中,用户先创建一个设计 C、C++ 或 SystemC 源代码,以及一个C的测试平台。通过 Vivado HLS Synthesis 运行设计,生成 RTL 设计,代码可以是 Verilog,也可以是 VHDL。有了 RTL 后,随即可以执行设计的 Verilog 或 VHDL 仿真,或使用工具的C封装器技术创建 SystemC 版本。然后可以进行System C架构级仿真,进一步根据之前创建的 C 测试平台,验证设计的架构行为和功能。设计固化后,就可以通过 Vivado 设计套件的物理实现流程来运行设计,将设计编程到器件上,在硬件中运行和/或使用 IP 封装器将设计转为可重用的 IP。
Step 1: 新建一个工程
1,Creat New Project新建文档,输入工程名称和工程路径。完成后点击Next。
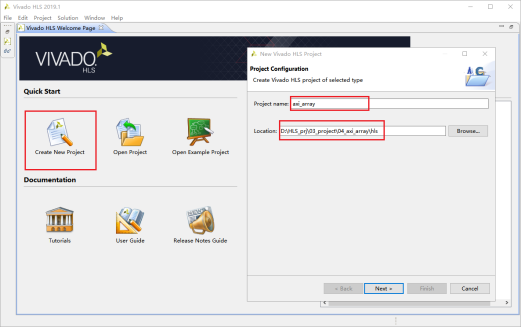
2,添加设计文件,并制定顶层函数。完成后点击Next。
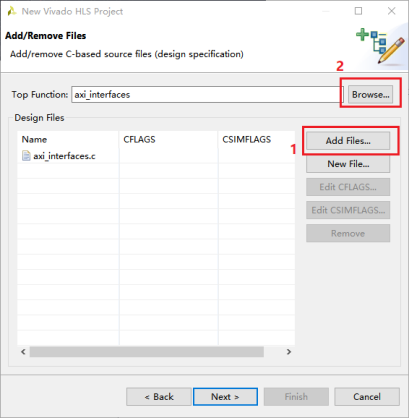
3,添加C语言仿真文件。完成后点击Next。
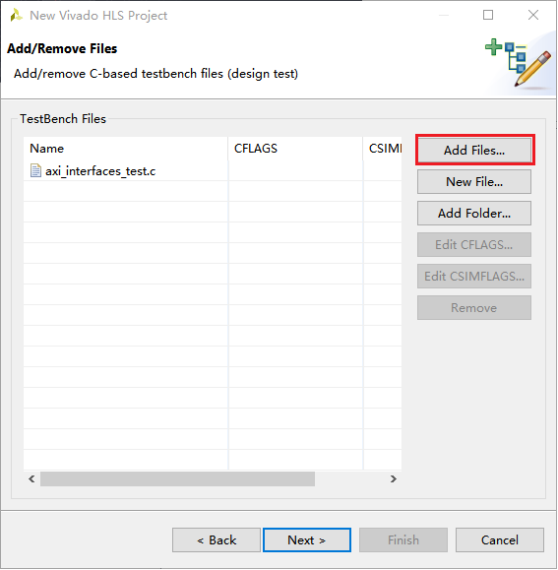
5,工程新建成功后进入的开发界面,HLS是典型的Eclipse界面,和SDK的界面十分相似。
导入的文件的代码如下:1,源文件。axi_interfaces.c
2,头文件。axi_interfaces.htypedef int din_t; typedef int dout_t; typedefintdacc_t; voidaxi_interfaces(dout_td_o[N],din_td_i[N]); int main () { // Create input data din_t d_i[N] = {10, 20, 30, 40, 50, 60, 70, 80, 11, 21, 31, 41, 51, 61, 71, 81, 12, 22, 32, 42, 52, 62, 72, 82, 13, 23, 33, 43, 53, 63, 73, 83}; dout_t d_o[N]; int i, retval=0; FILE*fp; // Call the function to operate on the data axi_interfaces(d_o,d_i); // Save the results to a file fp=fopen("result.dat","w"); fprintf(fp, "Din Dout "); for(i=0;i fprintf(fp, "%d %d ", d_i[i], d_o[i]); } fclose(fp); // Compare the results file with the golden results retval = system("diff --brief -w result.dat result.golden.dat"); if (retval != 0) { printf("Test failed !!! "); retval=1; } else { printf("Test passed ! "); } // Return 0 if the test passes return retval; }
4,测试数据。result.golden.datDin Dout 10 10 20 20 30 30 40 40 50 50 60 60 70 70 80 80 11 21 21 41 31 61 41 81 51 101 61 121 71 141 81 161 12 33 22 63 32 93 42 123 52 153 62 183 72 213 82 243 13 46 23 86 33 126 43 166 53 206 63 246 73 286 83 326
Step 2: C源代码验证
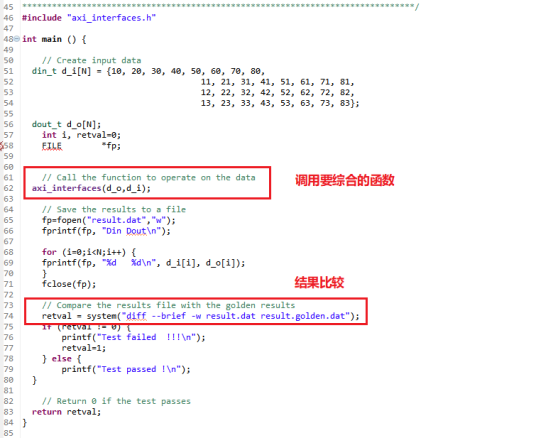
本步骤是对功能代码的逻辑验证,相当于功能前仿。1,测试程序的代码入下图。该程序先调用综合的函数,得到计算结果,再和预先的数据集进行比较,最后返回计较的结果。计算结果和预先的数据集一致时,测试通过,不一致时,测试失败。需要查看代码,寻找错误。
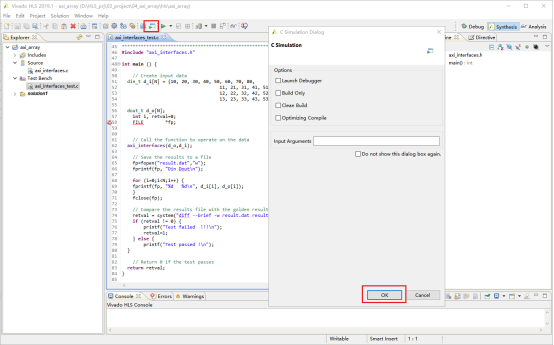
2,点击红框中的按钮,开始C源代码验证。
3,验证的结果显示在控制栏中。如图显示,测试通过。
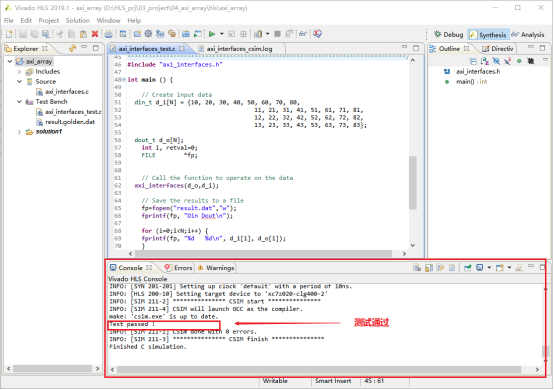
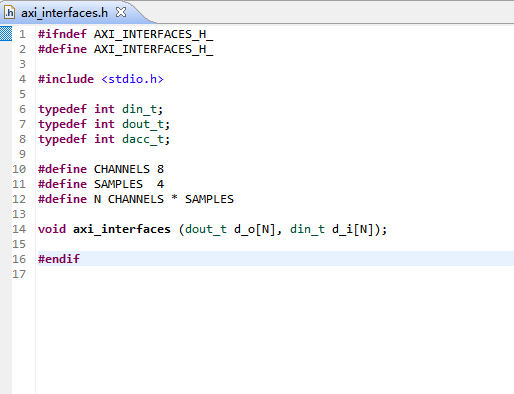
4,在头文件中,重定义了数据类型,参数,并进行了函数声明。
Step 3: 高层次综合
本步骤是把功能代码的综合成RTL逻辑。1,点击红框中的按钮,将C代码综合成RTL。综合完成后,查看结果。
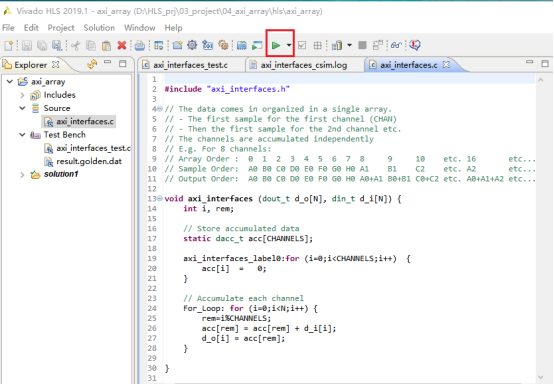
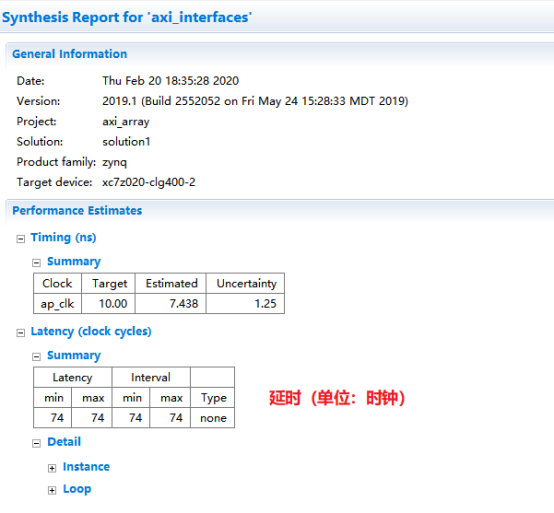
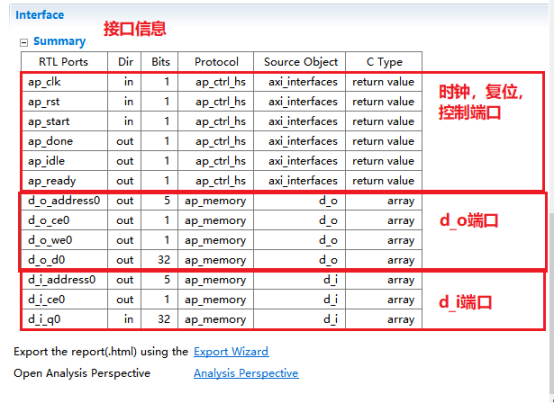
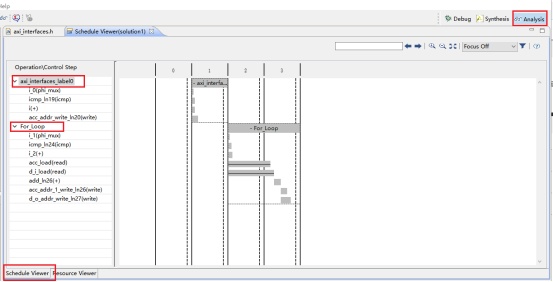
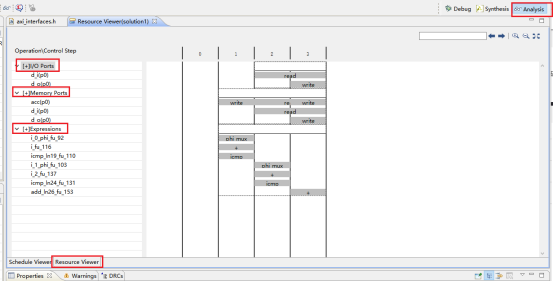
3,端口分析。(1)控制端口用于控制和显示该模块的工作状态。各个端口的功功能如下,默认情况下会生成下面四个控制端口。lap_start(in):为高时,该模块开始处理数据。lap_done(out):为高时,表示模块处理数据完成。lap_idle(out):表明模块是否处于空闲态。高电平有效。为高时,该处于空闲态。lap_ready(out):为高时,表示模块可以接受新的数据。(2)数据端口用于传递模块的输入输出参数。参数d_o,d_i 为数组类型,故默认状态下回生成内存接口。内存接口 (数组类型参数)数据来自外部的memory,通过地址信号读取相应的数据,输入到该模块中。输入数组从外部内存中读源数据,输出数组从向外部内存写入结果数据。各个端口的定义如下。laddress:地址信号lce0:片选信号lwe0:写使能信号ld0 :数据信号4,综合结果分析。在分析界面,可以看到模块的运行情况。包括数据依赖关系和各个周期执行的操作,IO口的读写,内存端口的访问等等。
Step 4: 综合优化
在使用高层次综合,创造高质量的RTL设计时,一个重要部分就是对C代码进行优化。Vivado HLS拥有自动优化的功能,试图最小化loop(循环)和function(函数)的latency。除了自动优化,我们可以手动进行程序优化,即用在不同的solution中添加不同的directive(优化指令)的方法,进行优化和性能对比。其中,对同一个工程,可以建立多个不同的solution(解决方案),为不同的solution添加directive可以达到如下目的。优化的类型可分为如下类别:l端口优化。指定不同类型的模块端口。l函数优化。加快函数的执行速度,减小执行周期。l循坏优化。利用展开和流水线形式,减小循环的执行周期。1,点击下面红框的图标,新建solution。
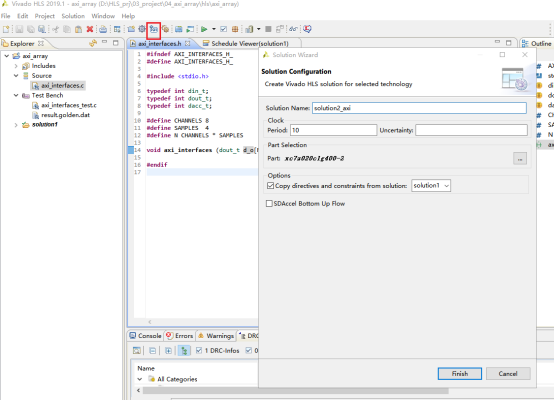
2,不同solution位于不同的文件夹中。
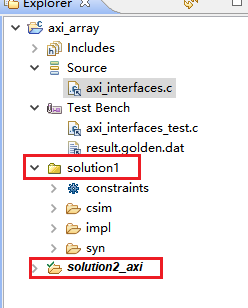
3,选中综合文件。可以在direct框中看可进行优化的标签。
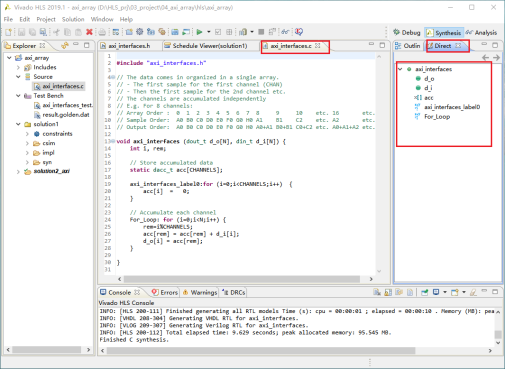
4,双击选择d_o,选择interface,s_axilite。点击ok。将d_o的端口类型设置为s_axilite类型。
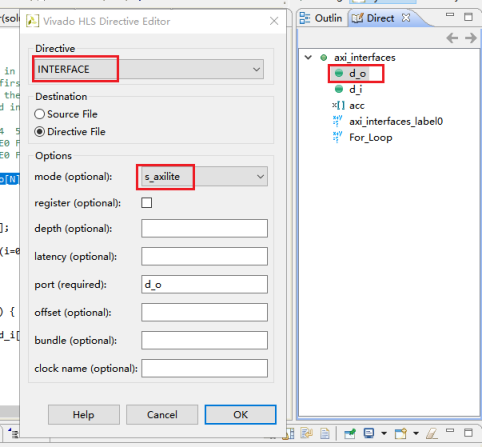
5,参考d_o,将d_i的接口类型也设置为s_axilite。将d_i的端口类型设置为s_axilite类型。
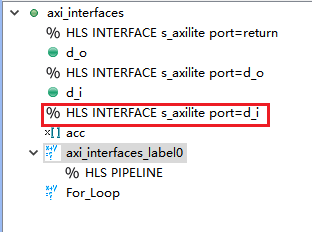
6,双击选择函数名称axi_interface,选择interface,s_axilite。点击ok。将控制端口的端口类型设置为s_axilite类型。
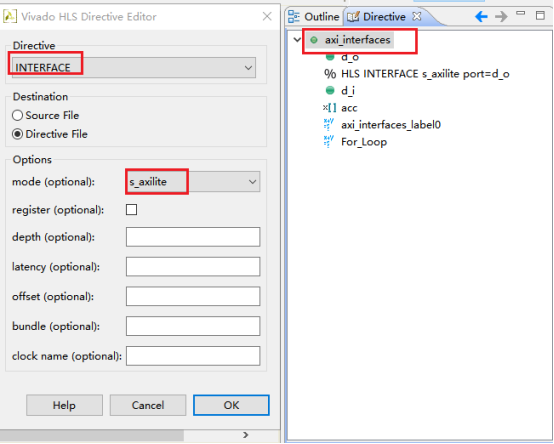
7,双击循环标签,选择流水线优化(pipeline),点击ok。
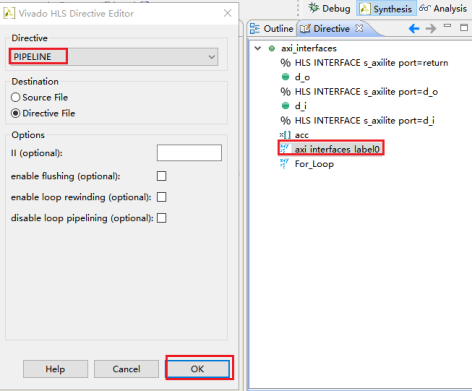
8,双击循环标签,选择循环展开优化(unroll),点击ok。
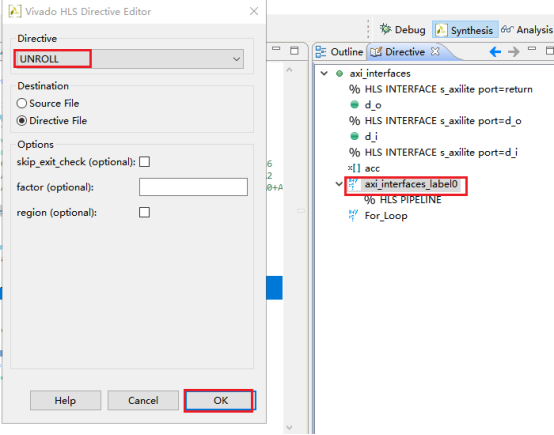
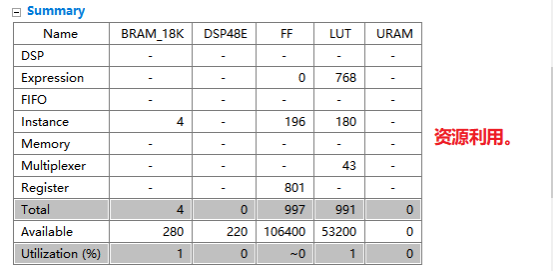
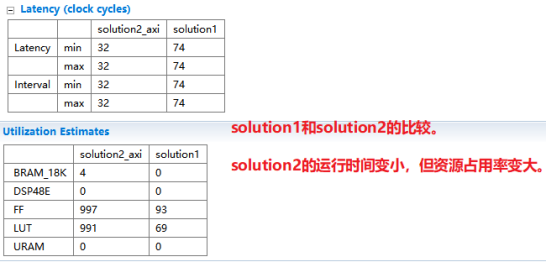
9,同上,也将标签为for_loop的循环进行流水线和展开优化。10,最终的优化情况总结如下。
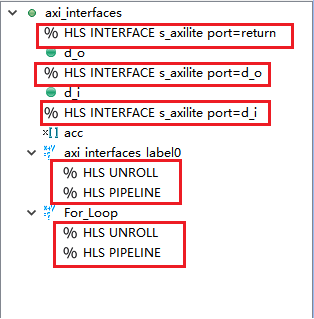
11,重新进行函数综合,查看综合报告如下。

Step 5: 综合结果文件
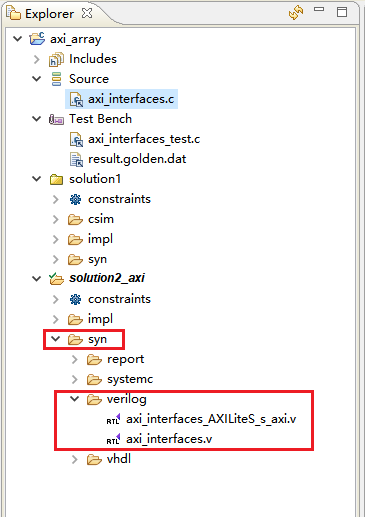
综合完成后,在各个solution的syn文件夹中可以看到综合器生成的RTL代码。包括systemc,VHDL,Verilog。
Step 6: 导出IP
在菜单里Solution>Export TL,设置如下,点击ok。
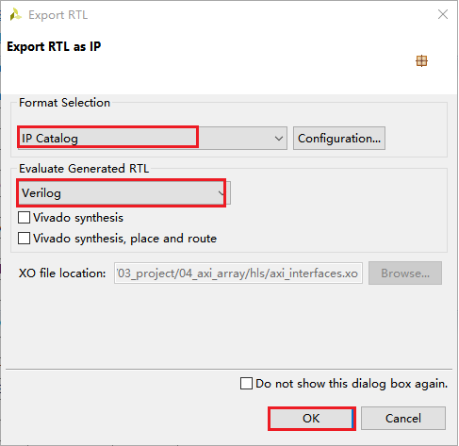
IP封装完成后,会在impl文件夹中输出ip文件夹,其中包含了RTL代码(hdl),模块驱动(drivers),文档(doc)等信息,其中包含一个压缩包文件,是用于建立vivado工程所用的IP压缩包。
Step 7: 总结
本文重点讲解了hls软件的使用方法和优化方法,在C语言模块设计上没有重点讲解。在掌握了hls软件的基本用法和优化方法后,接下来就可以设计更加复杂的C语言模块,进行rtl综合,加快设计开发的速度。审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
算法
+关注
关注
23文章
4633浏览量
93474 -
Xilinx
+关注
关注
71文章
2172浏览量
122346 -
Vivado
+关注
关注
19文章
815浏览量
66960
原文标题:Vivado-hls使用实例
文章出处:【微信号:zhuyandz,微信公众号:FPGA之家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于Xilinx XCKU115的半高PCIe x8 硬件加速卡
基于Xilinx XCKU115的半高PCIe x8 硬件加速卡,支持2x72bit(数据位宽64bit+ECC)DDR4存储,数据传输速率 2400Mb/s。DDR4单簇容量4GB,两组总容量为8GB

适用于数据中心应用中的硬件加速器的直流/直流转换器解决方案
电子发烧友网站提供《适用于数据中心应用中的硬件加速器的直流/直流转换器解决方案.pdf》资料免费下载
发表于 08-26 09:38
•0次下载

优化 FPGA HLS 设计
用的参考设计。该参考设计针对具有 Dual ARM® Cortex®-A9 MPCore™ 的 FPGA。
我们使用 Xilinx HLS 工具来打开此设计。
它的时钟周期为 5.00 ns,即
发表于 08-16 19:56
PSoC 6 MCUBoot和mbedTLS是否支持加密硬件加速?
。 使用 MCUBoot 验证两个应用程序时,运行时间大约需要五秒钟。
在 README.md 的 \"安全 \"一栏中写道
与软件实现相比,硬件加速加密技术将启动时间缩短了四倍多
发表于 05-29 08:17
简谈Xilinx Zynq-7000嵌入式系统设计与实现
设计。
最大优点可实现硬件加速:
设计者可以根据需求在硬件实现和软件实现之间进行权衡,使所设计的嵌入式系统满足最好的性价比要求,例如,在实现一个嵌入式系统设计时,当使用软件实现算法
发表于 05-08 16:23
新思科技硬件加速解决方案技术日在成都和西安站成功举办
近日,【新思科技技术日】硬件加速验证解决方案专场成都站和西安站顺利举行,来自国内领先的系统级公司、芯片设计公司以及高校的250多名开发者们积极参与。
Elektrobit利用其首创的硬件加速软件优化汽车通信网络的性能
Elektrobit今日宣布推出 EB zoneo GatewayCore——首款支持、配置和集成现代微控制器新一代硬件加速器的软件产品,可应用于先进的汽车电子/电气架构(基于被广泛采用
简谈Xilinx Zynq-7000嵌入式系统设计与实现
定制协处理器引擎来高效的实现该算法,这个使用硬件逻辑实现的协处理器,可以通过AMBA接口与全可编程SoC内的ARM Cortex A9嵌入式处理器连接,此外,通过XilinX所提供的最新高级综合
发表于 04-10 16:00

为何高端FPGA都非常重视软件
)应用程序提供了统一的编程模型。除了核心开发工具外,Vitis还提供了一套丰富的硬件加速库,这些库针对Xilinx硬件平台进行了预优化。”
发表于 03-23 16:48
【国产FPGA+OMAPL138开发板体验】(原创)7.硬件加速Sora文生视频源代码
算法,如循环神经网络(RNN)或Transformer,用于文本处理,以及卷积神经网络(CNN)或生成对抗网络(GAN)用于视频生成。通常涉及对模型中的计算密集型部分进行硬件加速。文本到视频生成模型
发表于 02-22 09:49
音视频解码器硬件加速:实现更流畅的播放效果
随着多媒体内容的日益丰富和高清化,传统的软件解码已经难以满足人们对流畅播放体验的需求。因此,音视频解码器硬件加速技术的出现,为提升播放效果带来了革命性的改变。 硬件加速的原理 硬件加速的核心






 工商网监
工商网监
评论