 用于加速嵌入式视觉和推理的开放标准
用于加速嵌入式视觉和推理的开放标准
机器学习领域的不断发展为部署利用神经网络推理的设备和应用程序创造了新的机会,这些设备和应用程序具有前所未有的基于视觉的功能和准确性水平。但是,快速发展的领域已经让位于处理器、加速器和库的混乱局面。本文介绍了开放互操作性标准及其在降低成本和降低在实际产品中使用推理和视觉加速的障碍方面的作用。
每个行业都需要开放标准,通过增加生态系统元素之间的互操作性来降低成本和缩短上市时间。开放标准和专有技术具有复杂且相互依存的关系。专有 API 和接口通常是达尔文式的试验场,并且可以在智能市场领导者手中保持主导地位,这是理所当然的。强大的开放标准源于行业对成熟技术的更广泛需求,可以提供健康、激励的竞争。从长远来看,不受任何一家公司控制或依赖于任何一家公司的开放标准通常可以成为行业向前发展的连续性线索,因为技术、平台和市场地位不断变化和发展。
Khronos Group 是一个非营利性标准联盟,任何公司都可以加入,拥有超过 150 名成员。所有标准组织的存在都是为了为竞争者提供一个安全的场所,让他们为了所有人的利益进行合作。Khronos Group 的专业领域是创建开放、免版税的 API 标准,使软件应用程序库和引擎能够利用硅加速的力量来满足要求苛刻的用例,例如 3D 图形、并行计算、视觉处理和推理。
创建嵌入式机器学习应用程序
许多互操作部分需要协同工作来训练神经网络并将其成功部署在嵌入式加速推理平台上——如图 1 所示。有效的神经网络训练通常需要大型数据集,使用浮点精度并在强大的 GPU 上运行- 加速台式机或云端。训练完成后,经过训练的神经网络将被引入为快速张量操作优化的推理运行时引擎,或将神经网络描述转换为可执行代码的机器学习编译器。无论使用引擎还是编译器,最后一步都是在从 GPU 到专用张量处理器的各种加速器架构之一上加速推理代码。
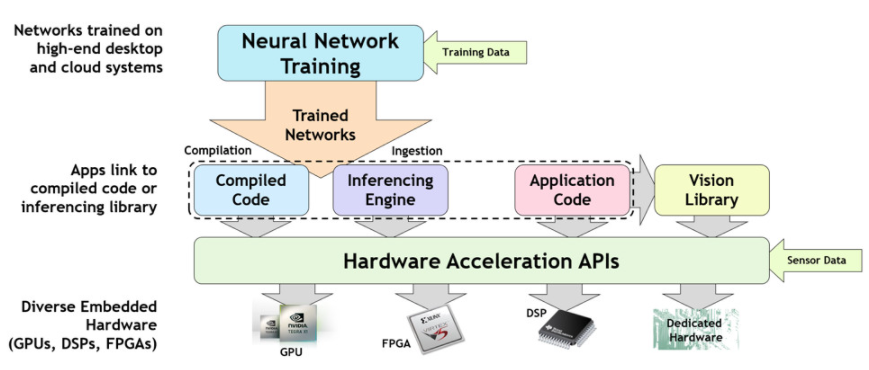
图 1. 训练神经网络并将其部署在加速推理平台上的步骤
那么,行业开放标准如何帮助简化这一过程呢?图 2. 说明了在视觉和推理加速领域中使用的 Khronos 标准。总的来说,随着处理器频率扩展让位于并行编程作为以可接受的成本和功率水平提供所需性能的最有效方式,人们对所有这些标准的兴趣越来越大。
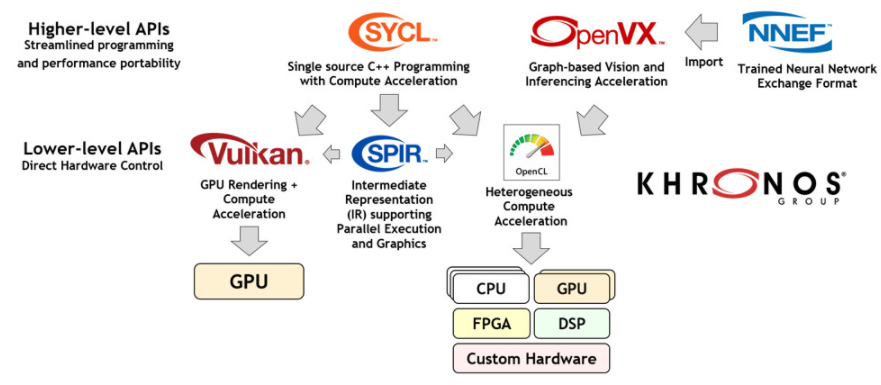
图 2. 用于加速视觉和推理应用程序和引擎的 Khronos 标准
从广义上讲,这些标准可以分为两组:高级和低级。高级 API 侧重于易于编程,具有跨多个硬件架构的有效性能可移植性。相比之下,低级 API 提供对硬件资源的直接、显式访问,以实现最大的灵活性和控制。每个项目都必须了解最适合其开发需求的 API 级别。此外,高级 API 通常会在其实现中使用低级 API。
让我们更详细地了解其中的一些 Khronos 标准。
SYCL - C++ 单源异构编程
SYCL(发音为“镰刀”)使用 C++ 模板库来调度标准 ISO C++ 应用程序的选定部分以卸载处理器。SYCL 使复杂的 C++ 机器学习框架和库能够直接编译并加速到在许多情况下优于手动调整代码的性能水平。如图 3 所示,默认情况下,SYCL 是通过较低级别的 OpenCL 标准 API 实现的:将用于加速的代码提供给 OpenCL,而剩余的主机代码则通过系统的默认 CPU 编译器提供。
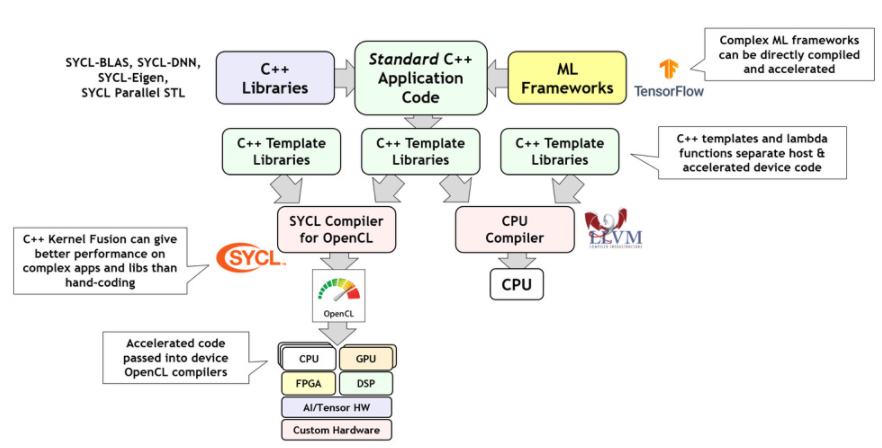
图 3. SYCL 将标准 C++ 应用程序拆分为 CPU 和 OpenCL 加速代码
越来越多的 SYCL 实现,其中一些使用专有后端,例如 NVIDIA 的 CUDA 用于加速代码。值得注意的是,英特尔的新 oneAPI Initiative 包含一个名为 DPC++ 的并行 C++ 编译器,它是基于 OpenCL 的符合 SYCL 实现。
NNEF——神经网络交换格式
当今使用的神经网络训练框架有数十种,包括 Torch、Caffe、TensorFlow、Theano、Chainer、Caffe2、PyTorch 和 MXNet 等等,并且都使用专有格式来描述他们训练的网络。还有数十种甚至数百种嵌入式推理处理器进入市场。迫使许多硬件供应商理解和导入如此多的格式是一个典型的碎片问题,可以通过如图 4 所示的开放标准来解决。
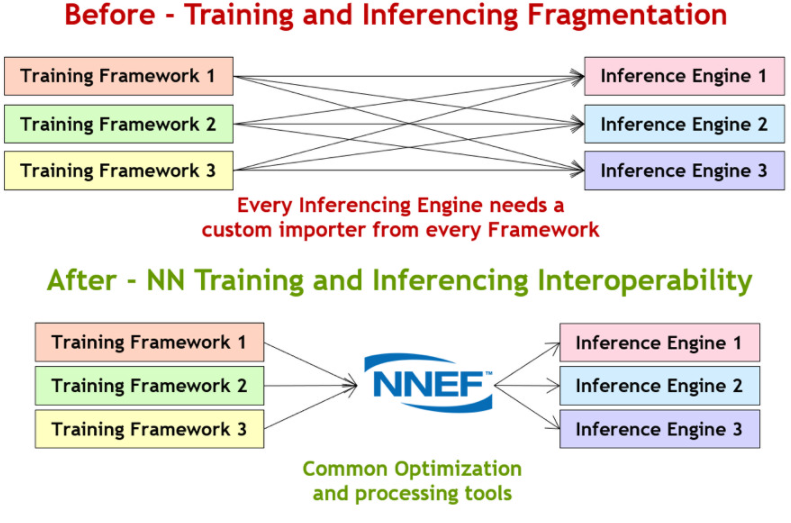
图 4. NNEF 神经网络交换格式通过推理加速器简化训练网络的摄取
NNEF 文件格式旨在在网络训练和推理芯片领域之间架起一座有效的桥梁——Khronos 久经考验的多公司治理模型为硬件社区提供了关于格式如何以满足需求的方式发展的强烈声音。开发处理器工具链和框架的公司,通常在安全关键市场。
NNEF 并不是业界唯一的神经网络交换格式,ONNX 是由 Facebook 和微软共同创立的开源项目,是一种被广泛采用的格式,主要专注于训练框架之间的网络交换。NNEF 和 ONNX 是互补的,因为 ONNX 跟踪培训创新和机器学习研究社区的快速变化,而 NNEF 的目标是嵌入式推理硬件供应商,这些供应商需要一种具有更深思熟虑的路线图演变的格式。Khronos 围绕 NNEF 发起了一个不断发展的开源工具生态系统,包括来自关键框架的导入器和导出器以及一个模型动物园,以使硬件开发人员能够测试他们的推理解决方案。
OpenVX – 便携式加速视觉处理
OpenVX(VX 代表“视觉加速”)通过提供图形级抽象来简化视觉和推理软件的开发,使程序员能够通过连接一组函数或“节点”来构建他们所需的功能。这种高级抽象使芯片供应商能够非常有效地优化他们的 OpenVX 驱动程序,以便在几乎任何处理器架构上高效执行。随着时间的推移,OpenVX 在原始视觉节点旁边添加了推理功能——毕竟神经网络只是另一个图!通过将 NNEF 训练的网络直接导入 OpenVX 图中,OpenVX 和 NNEF 之间的协同作用越来越大,如图 5 所示。
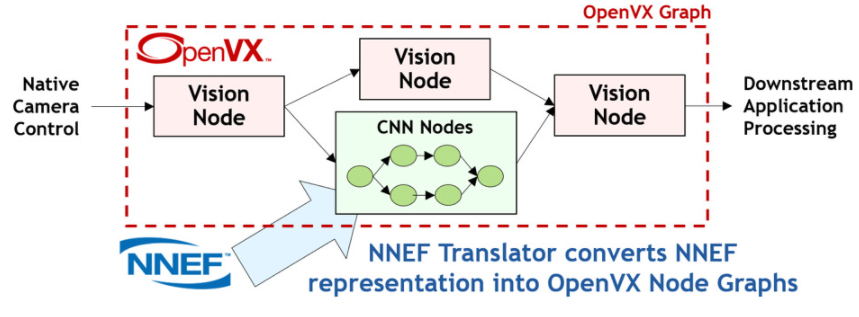
图 5. OpenVX 图可以描述从 NNEF 文件导入的视觉节点和推理操作的任意组合
OpenVX 1.3 于 2019 年 10 月发布,使针对垂直细分市场(例如推理)的精心挑选的规范子集能够被实施和测试,使其符合官方标准。OpenVX 还与 OpenCL 深度集成,使程序员能够添加自己的自定义加速节点以在 OpenVX 图形中使用 - 提供简单的可编程性和可定制性的独特组合。
OpenCL – 异构并行编程
OpenCL 是一种低级标准,用于对 PC、服务器、移动设备和嵌入式设备中的各种异构处理器进行跨平台并行编程。OpenCL 提供基于 C 和 C++ 的语言来构建内核程序,这些程序可以在具有 OpenCL 编译器的系统中的任何处理器上并行编译和执行,从而为程序员明确控制在哪些处理器上执行哪些内核。OpenCL 运行时协调加速器设备的发现,为选定的设备编译内核,以复杂的同步级别执行内核并收集结果,如图 6 所示。
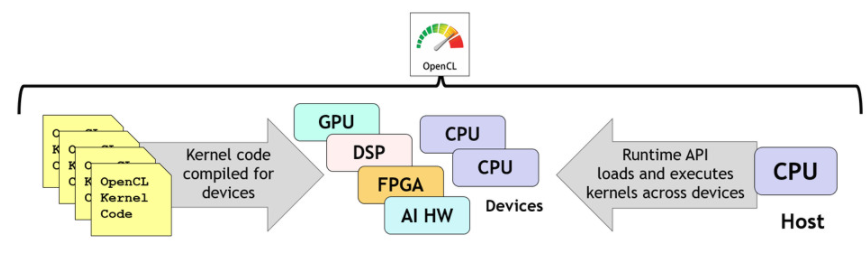
图 6. OpenCL 使 C 或 C++ 内核程序能够跨异构处理器的任意组合并行编译和执行
OpenCL 在整个行业中广泛使用,为计算、视觉和机器学习库、引擎和编译器提供最低的“接近金属”执行层。
OpenCL 最初是为在高端 PC 和超级计算机硬件上执行而设计的,但在与 OpenVX 类似的演变过程中,需要 OpenCL 的处理器越来越小,精度也越来越低,因为它们以边缘视觉和推理为目标。OpenCL 工作组正在努力定义为嵌入式处理器量身定制的功能,并使供应商能够交付针对关键功耗和成本敏感用例的选定功能,并且完全符合要求。
关于作者:
Neil Trevett 是 NVIDIA 开发者生态系统副总裁,他帮助应用程序利用先进的 GPU 和芯片加速。Neil is also the elected President of the Khronos Group, where he initiated the OpenGL ES standard used by billions worldwide every day, helped catalyze the WebGL and glTF projects to bring interactive 3D graphics to the Web, fostered the creation of the OpenVX standard for vision和推理加速,并主持定义异构并行计算的开放标准的 OpenCL 工作组。在 NVIDIA Neil 站在将交互式 3D 引入 PC 的硅革命的最前沿,他建立了 3Dlabs 的嵌入式图形部门,为各种非 PC 平台带来先进的视觉处理。
审核编辑:郭婷
-
处理器
+关注
关注
68文章
19274浏览量
229734 -
gpu
+关注
关注
28文章
4735浏览量
128914 -
机器学习
+关注
关注
66文章
8412浏览量
132600
发布评论请先 登录
相关推荐

嵌入式和人工智能究竟是什么关系?

嵌入式主板是什么意思?嵌入式主板全面解析
飞凌嵌入式「在线文档」功能上线 | 开放灵活,尽在掌握

嵌入式linux开发板芯片的工作原理
Astra™ SL系列SL1680详细介绍,嵌入式物联网处理器
机器视觉在嵌入式中的应用
嵌入式学习-飞凌嵌入式ElfBoard ELF 1板卡-如何移植NCNN?
嵌入式技术领域的视觉、安全与AI应用
AI与开源力推嵌入式系统创新升级
嵌入式主板,你了解多少?
嵌入式fpga是什么意思
高端嵌入式实验平台
啥是嵌入式?嵌入式都有啥?薪资如何?前景如何





 工商网监
工商网监
评论