 微调前给预训练模型参数增加噪音提高效果的方法
微调前给预训练模型参数增加噪音提高效果的方法
写在前面
昨天看完NoisyTune论文,做好实验就来了。一篇ACL2022通过微调前给预训练模型参数增加噪音提高预训练语言模型在下游任务的效果方法-NoisyTune,论文全称《NoisyTune: A Little Noise Can Help You Finetune Pretrained Language Models Better》。
paper地址:https://aclanthology.org/2022.acl-short.76.pdf
由于仅加两行代码就可以实现,就在自己的数据上进行了实验,发现确实有所提高,为此分享给大家;不过值得注意的是,「不同数据需要加入噪音的程度是不同」,需要自行调参。
模型
自2018年BERT模型横空出世,预训练语言模型基本上已经成为了自然语言处理领域的标配,「pretrain+finetune」成为了主流方法,下游任务的效果与模型预训练息息相关;然而由于预训练机制以及数据影响,导致预训练语言模型与下游任务存在一定的Gap,导致在finetune过程中,模型可能陷入局部最优。
为了减轻上述问题,提出了NoisyTune方法,即,在finetune前加入给预训练模型的参数增加少量噪音,给原始模型增加一些扰动,从而提高预训练语言模型在下游任务的效果,如下图所示,
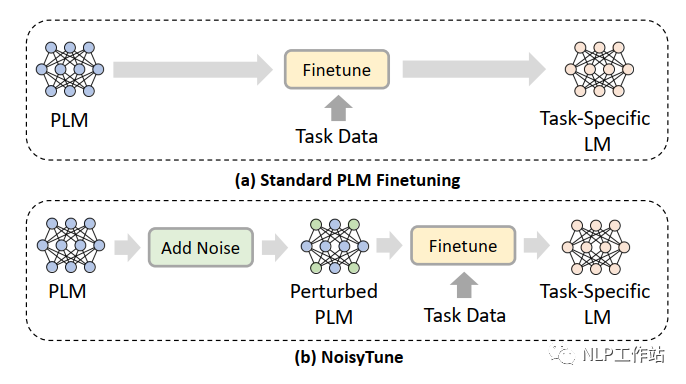
通过矩阵级扰动(matrix-wise perturbing)方法来增加噪声,定义预训练语言模型参数矩阵为,其中,表示模型中参数矩阵的个数,扰动如下:
其中,表示从到范围内均匀分布的噪声;表示控制噪声强度的超参数;表示标准差。
代码实现如下:
forname,parainmodel.namedparameters():
model.statedict()[name][:]+=(torch.rand(para.size())−0.5)*noise_lambda*torch.std(para)
这种增加噪声的方法,可以应用到各种预训练语言模型中,可插拔且操作简单。
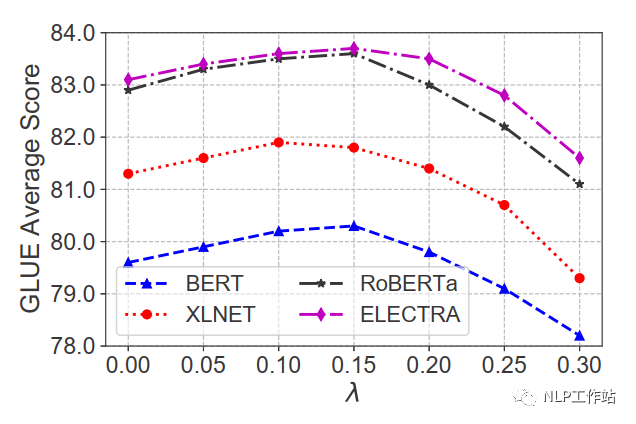
如下表所示,在BERT、XLNET、RoBERTa和ELECTRA上均取得不错的效果。
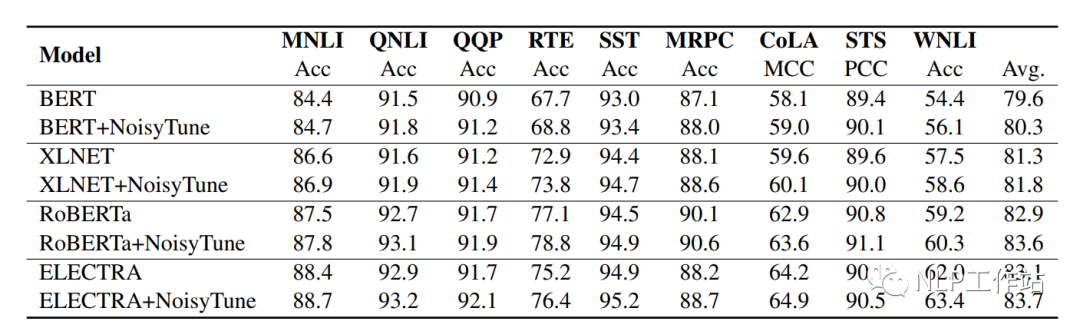
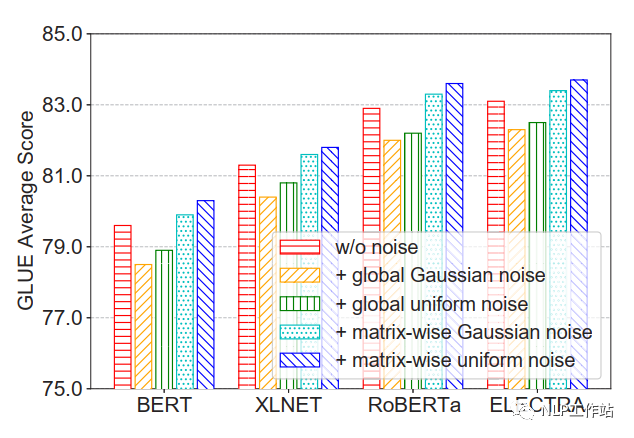
并且比较的四种不同增加噪声的方法,发现在矩阵级均匀噪声最优。
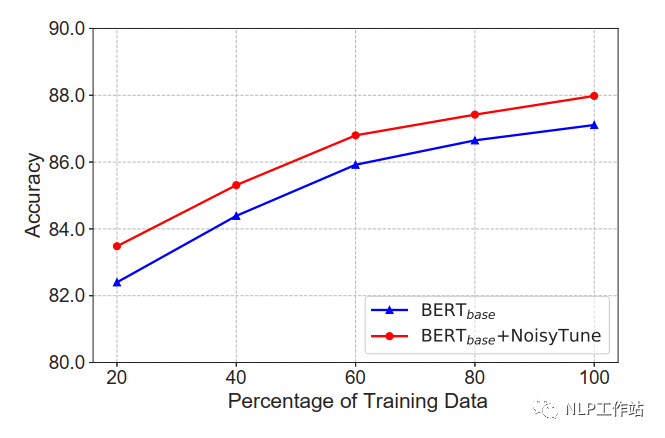
在不同数据量下,NoisyTune方法相对于finetune均有所提高。
在不同噪声强度下,效果提升不同,对于GLUE数据集,在0.1-0.15间为最佳。
总结
蛮有意思的一篇论文,加入少量噪音,提高下游微调效果,并且可插拔方便易用,可以纳入到技术库中。
本人在自己的中文数据上做了一些实验,发现结果也是有一些提高的,一般在0.3%-0.9%之间,但是噪声强度在0.2时最佳,并且在噪声强度小于0.1或大于0.25后,会比原始效果差。个人实验结果,仅供参考。
审核编辑 :李倩
-
噪音
+关注
关注
1文章
170浏览量
23959 -
模型
+关注
关注
1文章
3393浏览量
49367 -
自然语言处理
+关注
关注
1文章
623浏览量
13683
原文标题:ACL2022 | NoisyTune:微调前加入少量噪音可能会有意想不到的效果
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
用PaddleNLP在4060单卡上实践大模型预训练技术

【「基于大模型的RAG应用开发与优化」阅读体验】+大模型微调技术解读
《具身智能机器人系统》第7-9章阅读心得之具身智能机器人与大模型
预训练和迁移学习的区别和联系
大语言模型的预训练
大模型为什么要微调?大模型微调的原理
人脸识别模型训练失败原因有哪些
预训练模型的基本原理和应用
【大语言模型:原理与工程实践】大语言模型的预训练
【大语言模型:原理与工程实践】大语言模型的基础技术
【大语言模型:原理与工程实践】核心技术综述
【大语言模型:原理与工程实践】揭开大语言模型的面纱
基于双级优化(BLO)的消除过拟合的微调方法






 工商网监
工商网监
评论