 我们如何定义ROI?
我们如何定义ROI?
OpenCV是一个巨大的开源库,广泛用于计算机视觉,人工智能和图像处理领域。它在现实世界中的典型应用是人脸识别,物体检测,人类活动识别,物体跟踪等。
现在,假设我们只需要从整个输入帧中检测到一个对象。因此,代替处理整个框架,如果可以在框架中定义一个子区域并将其视为要应用处理的新框架,该怎么办。我们要完成一下三个步骤:
•定义兴趣区
•在ROI中检测轮廓
•阈值检测轮廓轮廓线
什么是ROI?
简而言之,我们感兴趣的对象所在的帧内的子区域称为感兴趣区域(ROI)。
我们如何定义ROI?
在输入帧中定义ROI的过程称为ROI分割。
在“ ROI细分”中,(此处)我们选择框架中的特定区域,并以矩形方法提供其尺寸,以便它将在框架上绘制矩形的ROI。
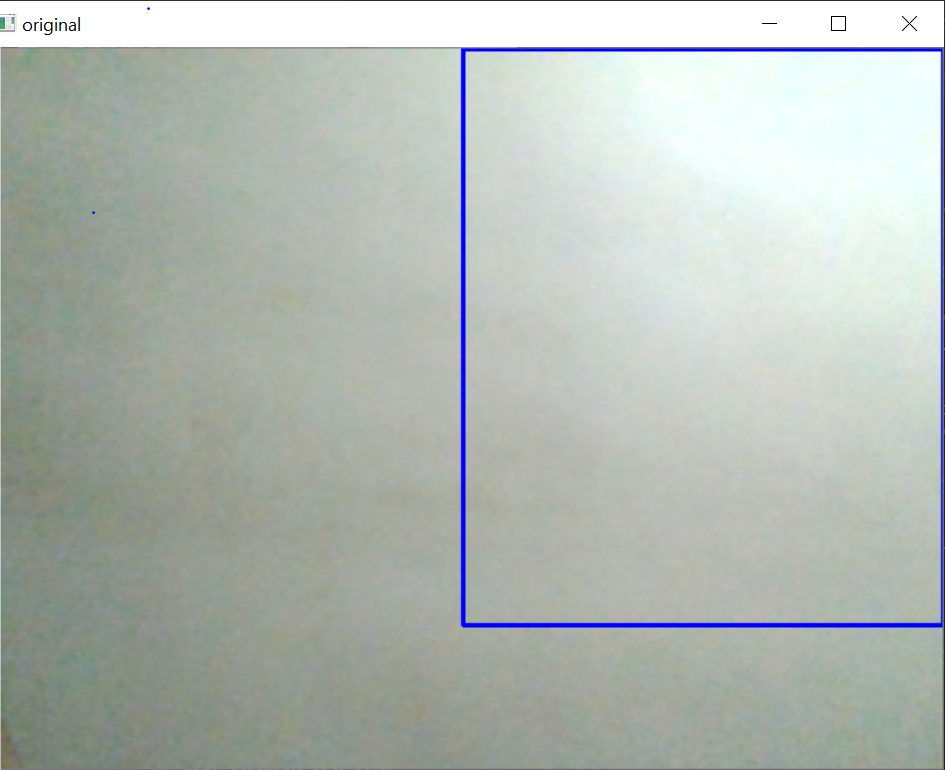
(输出)蓝色矩形覆盖的区域是我们的投资回报率
现在,如果您也想绑定感兴趣的对象,那么我们可以通过在ROI中找到轮廓来实现。
什么是轮廓?
轮廓线是表示或说是限制对象形状的轮廓。
如何在框架中找到轮廓?
对我而言,在将ROI框架设为阈值后,找到轮廓效果最佳。因此,要找到轮廓,手上的问题是-
什么是阈值?
阈值不过是图像分割的一种简单形式。这是将灰度或rgb图像转换为二进制图像的过程。例如

(这是RGB帧)

(这是二进制阈值帧)
因此,在对rgb帧进行阈值处理后,程序很容易找到轮廓,因为由于ROI中感兴趣对象的颜色将是黑色(在简单的二进制脱粒中)或白色(在如上所述的反向二进制脱粒中),因此分割(将背景与前景即我们的对象分开)将很容易完成。
在对框架进行阈值处理并检测到轮廓之后,我们应用凸包技术对围绕对象点的紧密拟合凸边界进行设置。实施此步骤后,框架应如下所示-
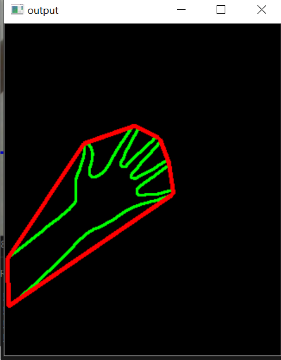
我们可以做的另一件事是,我们可以遮盖ROI以仅显示被检测到的轮廓本身覆盖的对象。再次-
什么是图像MASK?
图像MASK是隐藏图像的某些部分并显示某些部分的过程。这是图像编辑的非破坏性过程。在大多数情况下,它使您可以在以后根据需要调整和调整遮罩。通常,它是一种有效且更具创意的图像处理方式。
因此,基本上在这里我们将掩盖ROI的背景。为此,首先我们将修复ROI的背景。然后,在固定背景之后,我们将从框架中减去背景,并用wewant背景(这里是一个简单的黑色框架)替换它。
实施上述技术,我们应该得到如下输出:

(背景被遮罩以仅捕获对象)
这是所说明技术的理想实现的完整代码。
import cv2import numpy as npimport copyimport mathx=0.5 # start point/total widthy=0.8 # start point/total widththreshold = 60 # BINARY thresholdblurValue = 7 # GaussianBlur parameterbgSubThreshold = 50learningRate = 0# variablesisBgCaptured = 0 # whether the background captureddef removeBG(frame): #Subtracting the backgroundfgmask = bgModel.apply(frame,learningRate=learningRate)kernel = np.ones((3, 3), np.uint8)fgmask = cv2.erode(fgmask, kernel, iterations=1)res = cv2.bitwise_and(frame, frame, mask=fgmask)return res# Cameracamera = cv2.VideoCapture(0)camera.set(10,200)while camera.isOpened():ret, frame = camera.read()frame = cv2.bilateralFilter(frame, 5, 50, 100) # smoothening filterframe = cv2.flip(frame, 1) # flip the frame horizontallycv2.rectangle(frame, (int(x * frame.shape[1]), 0),(frame.shape[1], int(y * frame.shape[0])), (255, 0, 0), 2) #drawing ROIcv2.imshow('original', frame)# Main operationif isBgCaptured == 1: # this part wont run until background capturedimg = removeBG(frame)img = img[0:int(y * frame.shape[0]),int(x * frame.shape[1]):frame.shape[1]] # clip the ROIcv2.imshow('mask', img)# convert the image into binary imagegray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)blur = cv2.GaussianBlur(gray, (blurValue, blurValue), 0)cv2.imshow('blur', blur)ret, thresh = cv2.threshold(blur, threshold, 255, cv2.THRESH_BINARY) #thresholding the framecv2.imshow('ori', thresh)# get the coutoursthresh1 = copy.deepcopy(thresh)contours, hierarchy = cv2.findContours(thresh1, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) #detecting contourslength = len(contours)maxArea = -1if length > 0:for i in range(length): # find the biggest contour (according to area)temp = contours[i]area = cv2.contourArea(temp)if area > maxArea:maxArea = areaci = ires = contours[ci]hull = cv2.convexHull(res) #applying convex hull techniquedrawing = np.zeros(img.shape, np.uint8)cv2.drawContours(drawing, [res], 0, (0, 255, 0), 2) #drawing contourscv2.drawContours(drawing, [hull], 0, (0, 0, 255), 3) #drawing convex hullcv2.imshow('output', drawing)# Keyboard OPk = cv2.waitKey(10)if k == 27:camera.release()cv2.destroyAllWindows()breakelif k == ord('b'): # press 'b' to capture the backgroundbgModel = cv2.createBackgroundSubtractorMOG2(0, bgSubThreshold)isBgCaptured = 1print( 'Background Captured')elif k == ord('r'): # press 'r' to reset the backgroundbgModel = NoneisBgCaptured = 0print('ResetBackGround')
审核编辑 :李倩
-
人脸识别
+关注
关注
76文章
4012浏览量
81891 -
OpenCV
+关注
关注
31文章
635浏览量
41345
原文标题:基于OpenCV的区域分割、轮廓检测和阈值处理
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
《DNK210使用指南 -CanMV版 V1.0》第三十八章 image码识别实验
抖动定义和测量

电位的定义与规定
SPI总线的定义和特点
如何使用云服务器刷写自定义固件?
GPT的定义和演进历程
为什么我们需要软件定义的工厂?
SIM卡座的接口定义

高速pcb的定义是什么
TSMaster 自定义 LIN 调度表编程指导

PHP用户定义函数详细讲解

IGBT和MOSFET在对饱和区的定义差别
物联网中继器的定义和作用
EMC和MEA的定义和区别





 工商网监
工商网监
评论