 几种基于深度学习的中文纠错模型
几种基于深度学习的中文纠错模型
1 简介
在之前的篇章我们对中文文本纠错做了一个系统的介绍,曾经盛行的纠错系统都是基于混淆集+n-gram语言模型的,其中混淆集构建成本巨大,同时相对笨重,而n-gram语言模型也没考到句子的语义信息,所以导致最终的F1得分都比较小,很难满足真实场景的需要,泛化能力很比较差。同时以往的纠错系统都是基于pipeline的,检测任务跟纠错任务是相互分开的,各个环节紧急相连,前面的环节如果出现了错误,后面的环节也很难进行修正。任何一个环节出现了问题,都会影响整体的结果。
随着深度学习的兴起,人们逐渐用深度学习模型去替换以往的混淆集+n-gram语言模型的方式,根据句子的语义信息去进行纠错,同时,还将检测任务跟纠正任务联合到一起,做成一个end2end的系统,避免pipeline方式带来的问题。在这里我们介绍几种基于深度学习的中文纠错模型,让大家对于中文文本纠错有更加深入的理解。
2Confusionset-guided Pointer Network
Confusionset-guided Pointer Network是一个seq2seq模型,同时学习如何从原文本复制一个正确的字或者从混淆集中生成一个候选字。整个模型分为encoder跟decoder两部分。其中encoder用的BiLSTM用于获取原文本的高层次表征,例如图中左下角部分,decoder部分用的带注意力机制的循环神经网络,在解码的每个时刻,都能生成相应的上下文表征。生成的上下文表征有两个用途,第一个是利用这部分表征作为输入,通过矩阵乘法跟softmax来计算当前位置生成全词表中各个字的概率(右边的概率图)。第二个用途是利用这部分上下文表征加上位置信息来计算当前时刻复制原文本某个位置的字的概率或者需要生成原文本中不存在的字的概率(左边的概率图,这里其实是一个分类模型,假设原文本的长度是n,那么全部分类有n+1种,其中1至n的标签的概率代表当前时刻要复制原文本第i个位置的字的概率,第n+1的类别代表当前时刻要生成原文本不存在的字的概率。如果是1至n中某个类别的概率最大,那么当前位置的解码结果就是复制对应概率最大的原文本的某个字,如果是第n+1个类别概率最大,那么就会用到前面提及的第一个用途,计算当前位置词表中各个字的概率,取其中概率最大的字作为当前时刻解码的结果)。这里要注意的是,生成新字为了保证结果更加合理,会事先构建好一个混淆集,对于每个字,都有若干个可能错别字(形近字或者同音字等),模型会对生成的候选会限制在这个字的混淆集中,也不是在全词表中选择,所以才称为confusionset-guided。训练时会联合encoder跟decoder一同训练,以预测各个类别的交叉熵损失作为模型优化目标。
Confusionset-guided Pointer Network看起来跟之前提及的CopyNet思路很接近文本生成系列之文本编辑,同时考虑到copy原文跟生成新字两种可能性,相对于之前的seq2seq模型的改进主要是引入混淆集来控制可能的候选字符。这种设置也比较合理,中文的错别字多是在形状或者发音上有一定相似之处,通过混淆集可以进一步约束纠错的结果,防止纠错的不可控。但是由于生成的结果一定来源于混淆集,所以混淆集的质量也影响了最终纠错的效果。一个合理的混淆集的构建都需要付出比较大的代价。
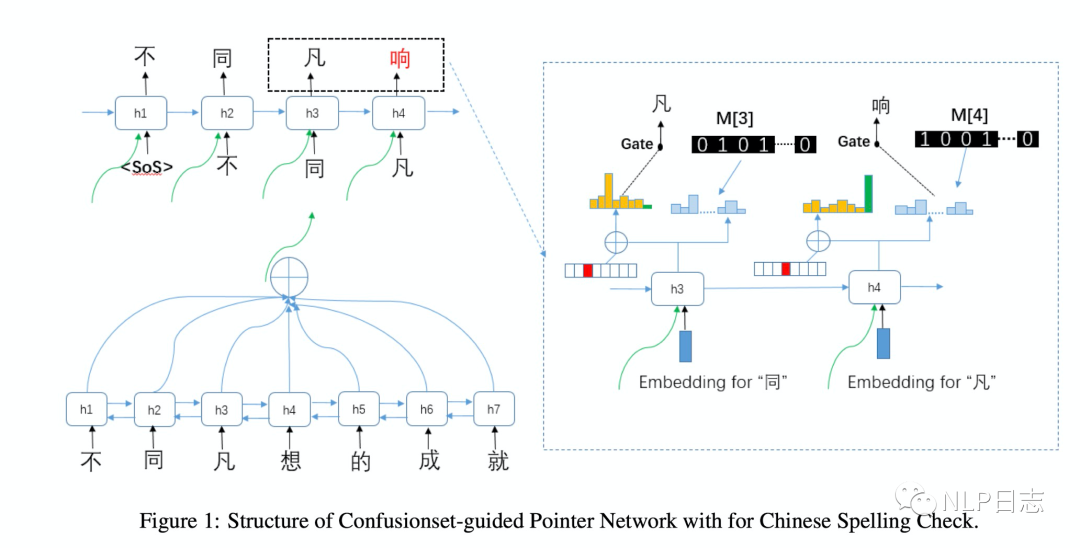
图1:Confusionset-guided Pointer Network框架
3 FASPell
这是爱奇艺发布在EMNLP2019的基于词的中文纠错的方法,FASPell有两个特别的点,一个是用BERT为基础的DAE取代了传统的混淆集,另一点是使用置信度-相似度的解码器来过滤候选集,从而提高纠错效果。
FASPell首先利用Bert来生成句子每个字符的可能候选结果,但是Bert的预训练任务MLM中选中的token有10%是被随机替代的,这跟文本纠错的场景不符,所以需要对Bert进行一定的微调。具体过程就是对MLM任务做一定调整,调整策略如下
a)如果文本没有错误,那么沿用之前Bert的策略。
b)如果文本有错误,那么随机选择的要mask的位置的字,如果处于错误的位置,那么设置对应的标签为纠错后的字,也就是相对应的正确的字。如果不是处于错误的位置,那么设置对应的标签为原来文本中的字。
在获得文本可能的候选结果后,FASPell利用置信度-相似度的解码器来过滤这些候选结果。这里为什么需要对Bert生成的候选字进行过滤呢?因为汉语中常见的错误大部分在字形或者发音有一定相似之处,但是Bert生成的候选字并没有考虑到中文纠错的背景,所以Bert提供的候选结果很多都是纠错任务不相关的。这里每个位置的候选词的置信度由Bert计算得到,相似度这里包括字形相似度跟音素相似度,其中因素相似度考虑到在多种语言中的发音。对于每个位置的候选词,只有当置信度,字形相似度跟音素相似度满足某个条件时,才会用这个候选字符替代到原文对应字符。至于这个过滤条件,一般是某种加权组合,通常需要置信度跟相似度的加权和超过一定阈值才会进行纠错,加权相关的参数可以通过训练集学习得到,在推理时就可以直接使用。
FASPell没有单独的检测模块,利用BERT来生成每个位置的候选字,避免了以往构建混淆集的工作,同时利用后续的置信度-相似度的解码器,对候选结果进行过滤,从而进一步提高纠错效果。
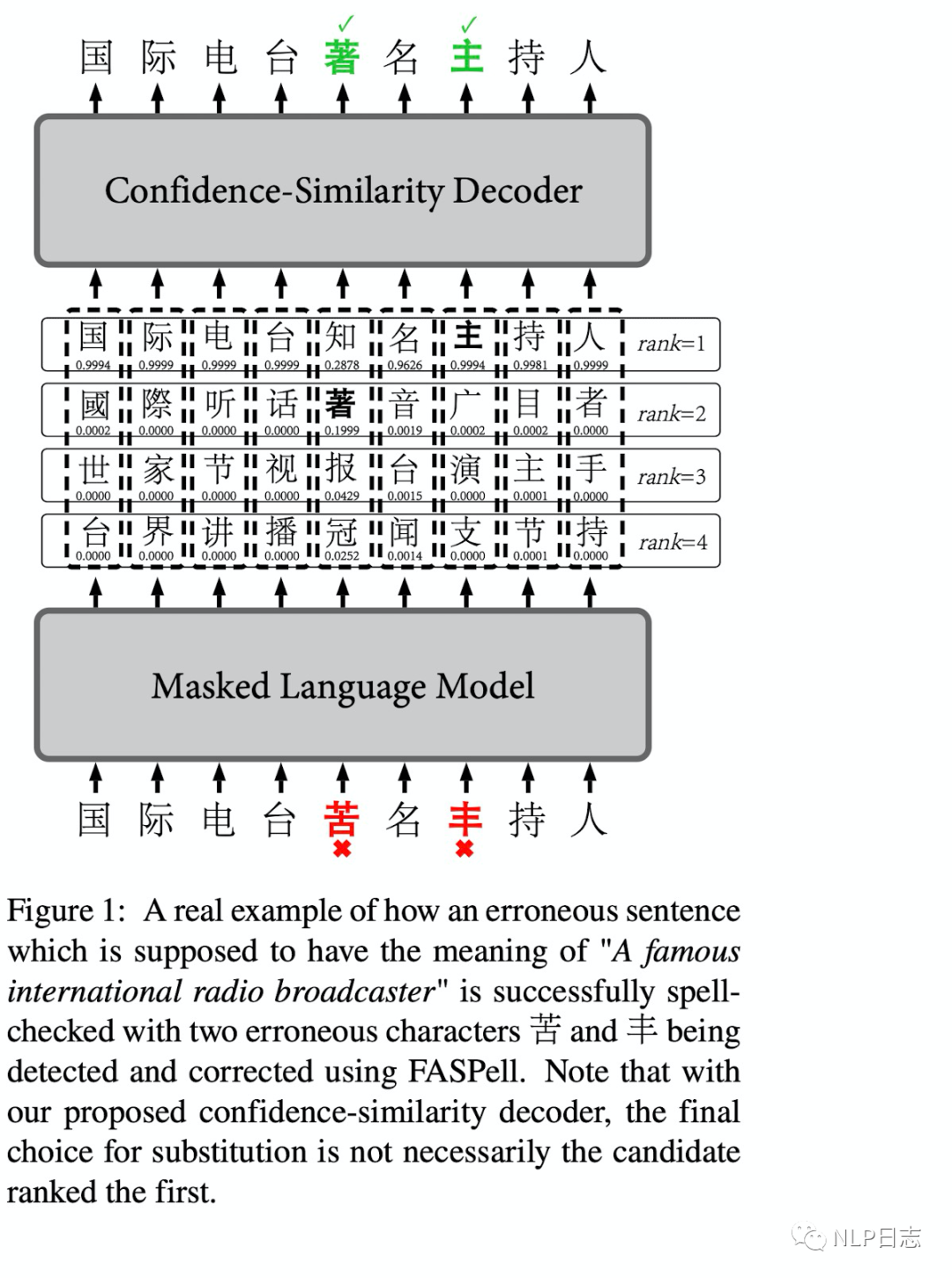
图2: FASPell框架
4Soft-Masked BERT
Soft-masked Bert是字节发表在ACL 2020的中文纠错方法,针对目前主流的深度学习纠错方法都是利用Bert生成各个位置的可能候选,但是Bert本身缺乏判断每个位置是否需要纠错的能力,也就是缺乏检测能力。为此,提出了一个包含检测网络跟纠正网络的中文纠错方法。整个流程是经过检测网络,然后再经过纠错网络。其中检测网络是的双向GRU+全连接层做一个二分类任务,计算原文本每个位置是否有错误的概率。每个位置有错别字的概率为p,没有错别字的概率是1-p,如图中左边部分。纠正网络采用的是预训练模型Bert,但是在嵌入层的地方有所不同,每个位置的嵌入是由原文本中对应位置的字的词嵌入跟[MASK]的词嵌入的加权和得到的,这里的[MASK]的权重等于检测网络预测的当前位置是错别字的概率。具体如图4所示,所以如果检测网络判断当前位置是错别字的概率较高,那么在纠正网络中该位置的词嵌入中[MASK]的权重就更高,反之,如果检测网络判断当前位置是错别字的概率很低,那么在纠正网络中该位置的词嵌入中[MASK]的权重就更低。利用Bert获得每个位置的表征后,将Bert最后一层的输出加上原文本中对应位置的词嵌入作为每个时刻最终的表征,通过全连接层+Softmax去预测每个位置的字,最终选择预测概率最大的字作为当前结果的输出。训练过程中联合训练检测网络跟纠正网络的,模型的目标包括两部分,一个是检测网络的对数似然函数,另一个是纠正网络的对数似然函数,通过加权求和联合这两部分,使得加权和的负数尽可能小,从而同时优化这两个网络的参数。
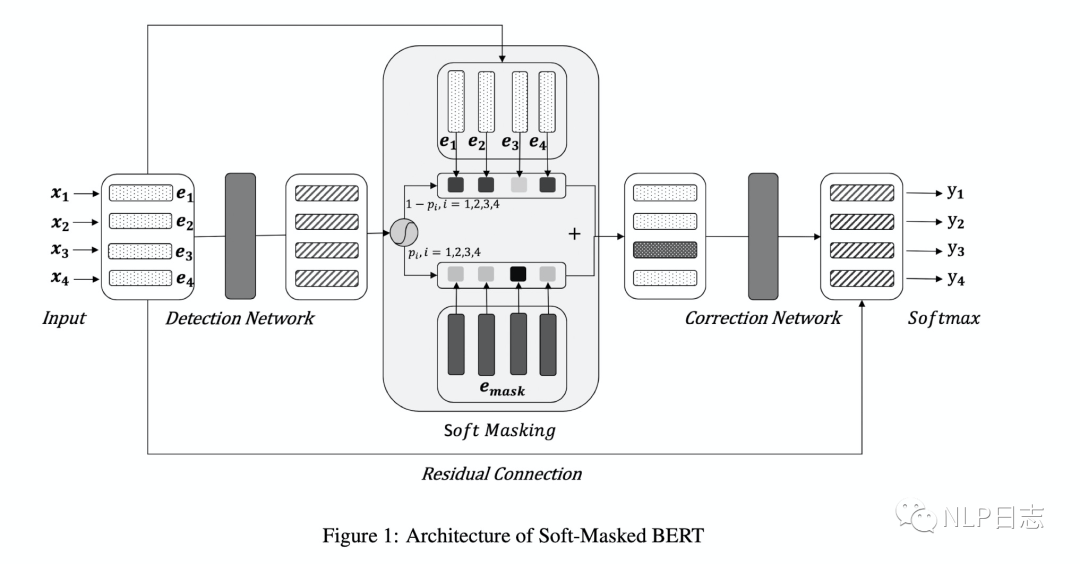
图3: Soft-Masked BERT框架
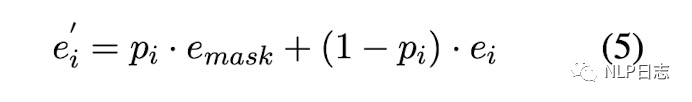
图4: Softed-masked embedding
Soft-Masked BERT相比直接采用预训练模型BERT,利用检测网络从而得到更合理的soft-masked embedding,缓解了Bert缺乏充足检测能力的问题,虽然改动不大,但是效果提升明显。
5 MLM-phonetics
个人感觉MLM-phonetics是在soft-masked BERT的基础上做的优化,思路也比较接近,同样是包括检测网络跟纠正网络,主要有几点不同,
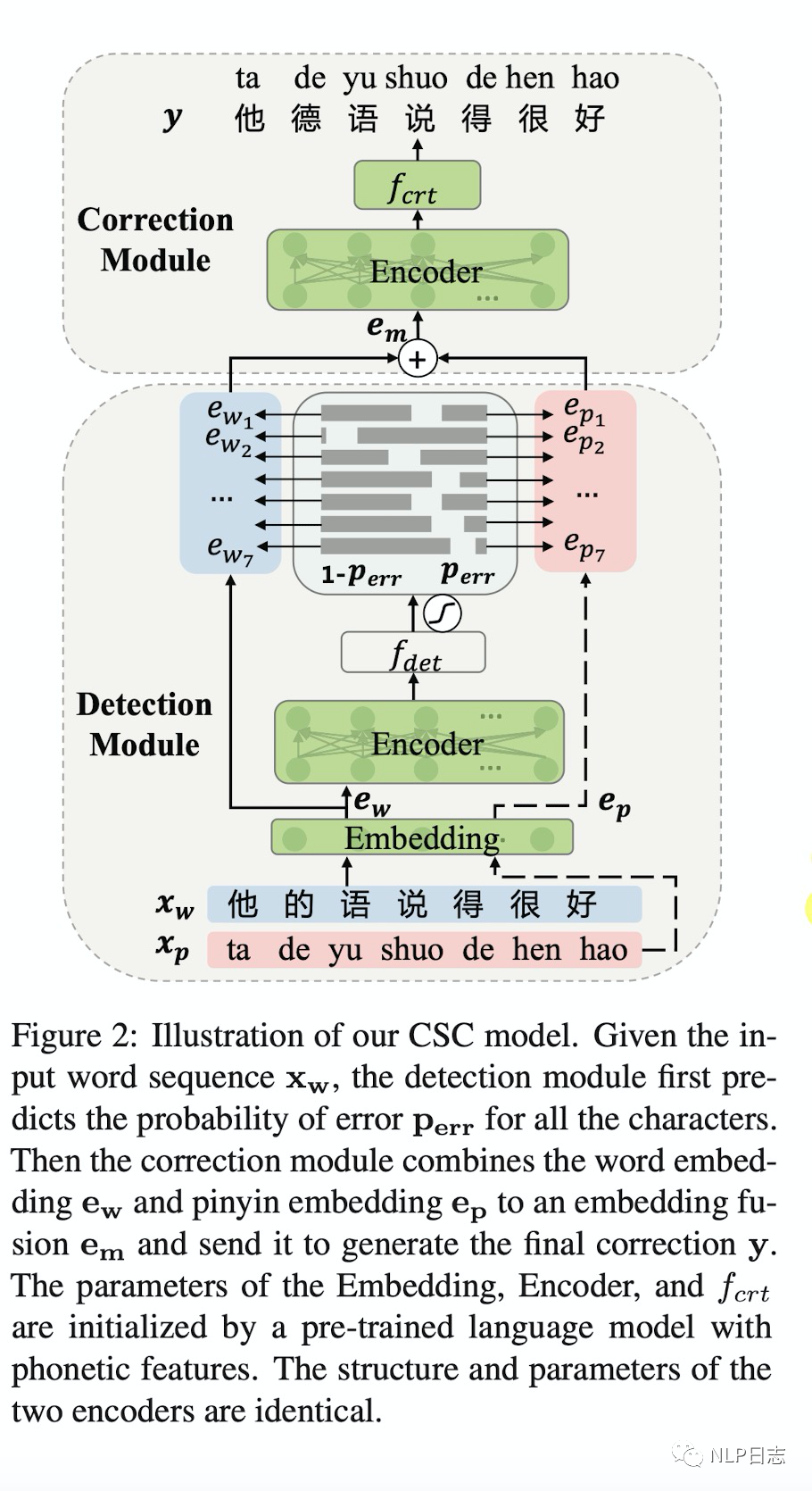
图5: MLM-phonetics框架
a)纠正网络的词嵌入组成不同,Soft-Masked BERT的词嵌入由原文本中各个位置本身的词嵌入和[MASK]的词嵌入组成,而MLM-phonetics则是将相应[MASK]的词嵌入替换为相应位置对应的拼音序列的嵌入。
b)目标函数不同,MLM-phonetics在纠正网络的目标函数中加入了检测网络的预测结果作为一个权重项。
c)检测网络不同,MLM-phonetics的检测网络采用了预训练模型Bert。
d) BERT预训练任务不同,为了更加适配中文纠错任务的场景,MLM-phonetics的Bert的MLM任务中预测的字都是根据汉字常见的错误选取的,要不在字形上有相似之处,要不在发音上有相似之处。
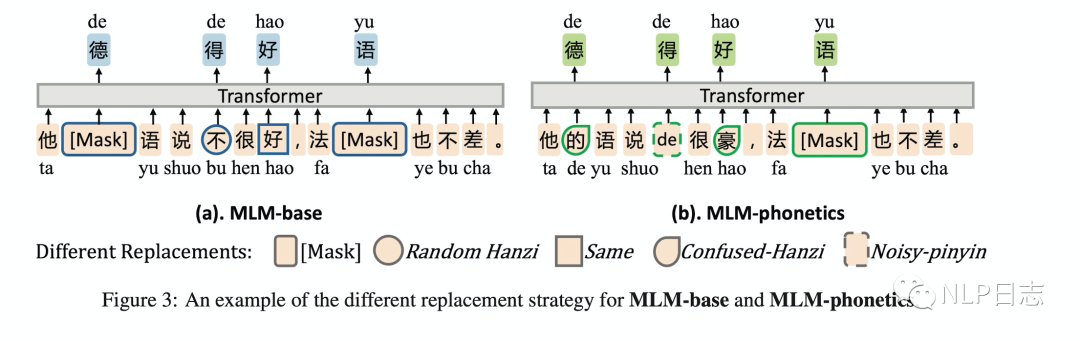
图6: MLM-phonetics预训练任务
6 总结
为了对比上述几种中文纠错方法之间的差异,可以直接比较这几种方法在几个常见中文纠错数据集上的性能表现,在F1值上都远超基于混淆集+n-gram语言模型的方式。
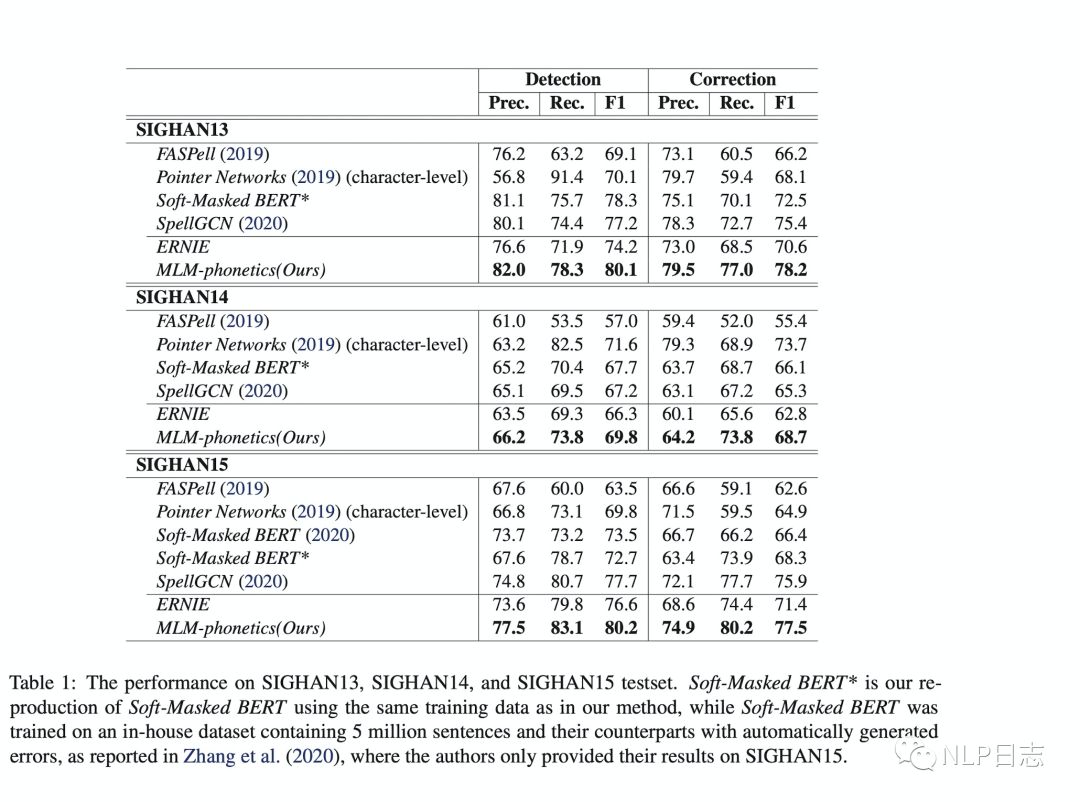
图7:不同纠错模型的效果对比
除此之外,关于中文纠错任务,还有一些需要注意的点。
a)由于纠错任务可以分为检测跟纠正两个过程,所以相应的错误也可以分为这两种类型。目前基于BERT的中文纠错方法的检测错误的比例要高于纠正错误的比例,这也得益于Bert训练过程的MLM任务。
b)中文纠错方法基本都是以字为基本单位,很大程度是因为以词为单位的话会引入分词模块的错误,但是可以用分词的结构来作为字的特征增强。
c)目前中文纠错任务有两种类型的错误还没有很好的解决。第一种是模型需要强大推理能力才能解决,例如“他主动牵了姑娘的手,心里很高心,嘴上却故作生气。”这里虽然容易检测出“高心”是错别字,但是至于要把它纠正为“寒心”还是“高兴”需要模型有强大的推理能力才可以。第二种错误是由于缺乏常识导致的(缺乏对这个世界的认识),例如“芜湖:女子落入青戈江,众人齐救援。”需要知道相关的地理知识才能把“青戈江”纠正为“青弋江”。
审核编辑 :李倩
-
检测
+关注
关注
5文章
4496浏览量
91539 -
文本
+关注
关注
0文章
118浏览量
17092 -
深度学习
+关注
关注
73文章
5506浏览量
121259
原文标题:中文文本纠错系列之深度学习篇
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
深度学习模型的鲁棒性优化
深度学习模型有哪些应用场景
深度神经网络模型量化的基本方法

深度学习模型中的过拟合与正则化
深度学习中的时间序列分类方法
深度学习中的模型权重
人工智能深度学习的五大模型及其应用领域
深度学习的典型模型和训练过程
为什么深度学习的效果更好?






 工商网监
工商网监
评论