 使用OpenCL for FPGA设计200万点频域滤波器
使用OpenCL for FPGA设计200万点频域滤波器
考虑在当前 FPGA 架构上创建一个支持 100 万到 1600 万个点的频域滤波器,采样率从每秒 1.2 亿到 2.4 亿个样本。该示例着眼于使用 OpenCL 的 200 万点单精度频域滤波器的设计决策选项。
这种滤波器使用数百万点一维 (1D) FFT 将其输入转换为频域,将每个频率和相位分量乘以一个单独的用户提供的值,然后将结果转换回时域快速傅里叶变换。整个系统的总体目标性能要求是每秒 1.5 亿个样本 (MSPS),在具有两个 DDR3 外部存储器组的当前一代 FPGA 上实现 200 万点的样本大小。输入和输出通过 10 Gb 以太网 (GbE) 直接进入 FPGA。
该设计使用面向具有 Stratix V GSD8 FPGA 的 BittWare S5-PCIe-HQ 板的 Altera SDK for OpenCL FPGA 编译器。使用 OpenCL 而不是低级语言有两个原因:
第一个原因是设计数百万点滤波器需要构建复杂但高效的外部存储系统。使用较低级别的设计工具,创建单个块,例如片上 FFT 或拐角转角相对容易(特别是因为每个 FPGA 供应商都已经提供了包含此类块的库)。然而,创建外部存储器系统通常需要大量的 HDL 工作。正如我们稍后会看到的,这种情况可能特别具有挑战性,因为整个系统的配置在一开始是未知的。
选择 OpenCL 的第二个原因是对 FPGA 逻辑的主机级控制。对于这个设计,从一开始就很明显,两个完整副本的数百万点 FFT 内核无法容纳在单个设备上,因此单个数据集必须至少通过 FPGA 逻辑两次才能产生最终输出。协调这种共享,同时允许动态改变数据集大小、乘法系数,甚至完全改变 FPGA 功能以实现其他功能,最好留给 CPU。
使用面向 FPGA 的 OpenCL 编译器解决了这两个挑战,因为它构建了一个定制的高效外部存储器系统,同时允许对 FPGA 逻辑进行细粒度控制。
片上 FFT
对于这个设计,假设我们已经有一个 FFT 内核,可以处理完全适合 FPGA 的数据大小(称为“片上 FFT”),因为每个 FPGA 供应商都提供这样的内核。这样的核心至少可以通过以下方式参数化:
数据类型(固定或单精度浮点)
要处理的点数 (N)
并行处理的点数 (POINTS)
动态支持更改要处理的点数
给定这样一个片上 FFT 核,构建整个系统需要两个步骤:首先,构建一个可以处理数百万点的 FFT 核,其次,将两个这样的核拼接在一起,并在它们之间进行复杂的乘法运算以创建整个系统。
数百万点 FFT
使用外部存储实现 FFT 的经典方法是图 1 所示的六步算法,该算法将单个一维数据集视为二维 (2M = 2K x 1K)[1]。
图 1:六步 FFT 算法的逻辑视图。
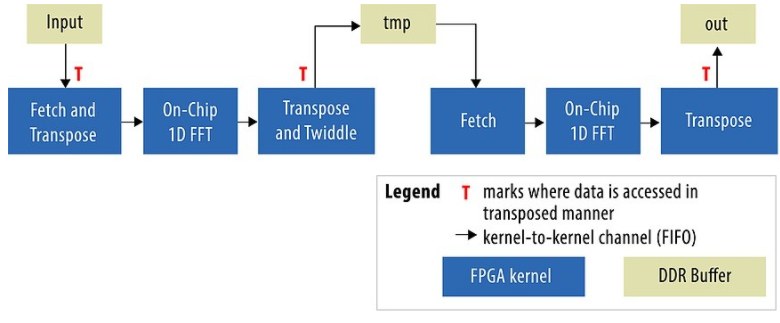
六步算法显示了单独的计算内核和外部内存缓冲区。“Fetch”内核从外部存储器读取数据,可选择转置,并将其输出到通道(在 OpenCL 2.0 命名法中也称为“管道”)。在硬件中,通道被实现为具有编译器计算深度的 FIFO。“片上 1D FFT”是未经修改的供应商的 FFT 内核,使用通道获取输入并产生位反转输出。“转置”总是转置从其输入通道读取的数据,可选择将其乘以特殊的旋转因子,并以自然顺序将输出写入外部存储器。
如图所示,数据通过 Fetch ➝ 1D FFT ➝ Transpose (F1T) 管道发送两次以产生最终输出。这为我们提供了第一个重要的设计选择:要么拥有一个 F1T 管道副本以节省空间,要么拥有两个副本以获得更高的吞吐量。
该算法的初始原型设计是在模拟器中完成的,以确保转置和旋转因子的地址操作是正确的。仿真器将 OpenCL 内核编译为 x86-64 二进制代码,可以在没有 FPGA 的开发机器上运行。从模拟器到硬件编译是一个轻松的步骤,因为模拟器中功能正确的代码变成了硬件中功能正确的代码,因此不需要模拟。
出于性能和面积原因,唯一需要修改的是 Fetch 和 Transpose 内核使用的本地内存系统。高效的转置需要缓冲POINTS本地内存中的列/行数据。OpenCL 编译器分析 OpenCL 代码中对本地存储器的所有访问,并创建针对该代码优化的自定义片上存储器系统。在 POINTS=4 的情况下,原始转置内核有四次写入和四次读取。一个双泵的片上 RAM 块最多可以服务四个单独的请求,其中最多两个是写入。为了支持四写四读,片上存储器需要同时复制并包含请求仲裁逻辑,这会导致区域膨胀和性能损失。但是,可以更改写入模式以使所有四个写入连续。OpenCL 编译器将这四次写入分组为一次宽写入,只提供对本地内存系统的五次访问:一次写入和四次读取。有了这样的改变,
将设计编译到硬件后,就可以测量性能了。使用 FPGA 上的 F1T 流水线的单个副本,我们测量了 217 MSPS,POINTS=4 和 457 MSPS,POINTS=8,对于 400 万-点 FFT[2]。POINTS=8 版本使用了两倍的片上 Block RAM,并且此配置中的两个副本不适合。这为我们提供了第一个要探索的设计维度——并行处理的点数与面积。
全过滤设计
现在我们有了数百万点的 FFT,我们准备将整个设计放在一起。只需拼接两个片外 FFT,我们就可以得到图 2 中整个流水线的逻辑视图。
图 2:为简洁起见,完整过滤器系统的此逻辑视图显示 F1T 管道表示为单个块。
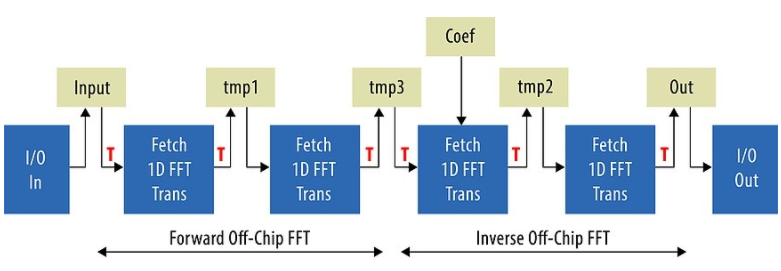
除了复制单个片外 FFT 计算流水线外,系统还添加了以下部分:
频域中的复数乘法被吸收到第三个 F1T 块中。coef缓冲区保存着两百万个复数乘法系数。
添加了 I/O 输入和 I/O 输出内核,以真实地模拟外部存储器上 10 GbE 通道的额外负载。使用这些内核,我们可以继续纯粹基于软件的开发,并在核心计算管道完全优化之前离开以太网通道集成。内核中的 I/O 每个时钟周期生成一个样本,而 I/O 输出每个时钟周期消耗一个样本。
正如片外 FFT 的实验所示,我们只能拟合两个 F1T 块,并且只能使用 POINTS=4。因此,数据必须通过硬件两次才能进行完整计算。这使我们的 200 万个点的整体系统吞吐量仅为 120 MSPS,低于我们 150 MSPS 的目标。但是,通过将数据大小减少到 100 万个点,我们能够拟合 POINTS=8 的版本并获得 198 MSPS 的吞吐量。这表明,只要我们能制作一个适合 200 万个点的 POINTS=8 版本,性能还是有的。
选择图 2 中完整流水线的优化结构是整个设计过程的下一步。我们可以做的第一个改进是删除tmp3缓冲区。双方以相同的方式访问它(转置写入和读取),因此第二个和第三个 F1T 块可以通过通道直接连接。这需要让 Transpose 内核将其输出写入外部存储器或写入通道,并对 Fetch 进行类似的更改。这种变化是由主机动态控制的,因此可以使用单个物理 Fetch 实例。请注意,这会改变我们与外部存储器的连接,但我们完全不必担心这一点,因为 OpenCL 编译器总是为我们的系统生成高效的自定义外部存储器互连。
进一步的改进是将第二个转置“T”从写入tmp1移动到从tmp1读取(tmp1中的数据存储方式不同,但最终效果相同)。这消除了对转置使用的一个本地内存缓冲区的需要。尽管这种改变并不难实施,但我们决定放弃它以代替更激进的想法。
我们最初的转置实现分两个阶段完成:
首先将所有需要的数据加载到本地内存中,然后使用转置地址从本地内存中读取。为了有效利用这样的管道,OpenCL 编译器会自动对本地内存系统进行双缓冲。这样,管道的加载部分可以将数据加载到一个副本中,而读取部分可以从另一个副本中读取先前的数据集。
这种自动双缓冲对我们的转置算法来说是正确的,但它很昂贵。相反,我们将转置内核重写为就地。这样的内核只需要一个缓冲区,并且支持同时读取和写入多个数据点(但是关于这个转置内核我们将在另一时间详细描述)。
通过这些更改,我们能够在 POINTS=8 配置中安装 200 万点 FFT,并实现 164 MSPS 吞吐量。
调度
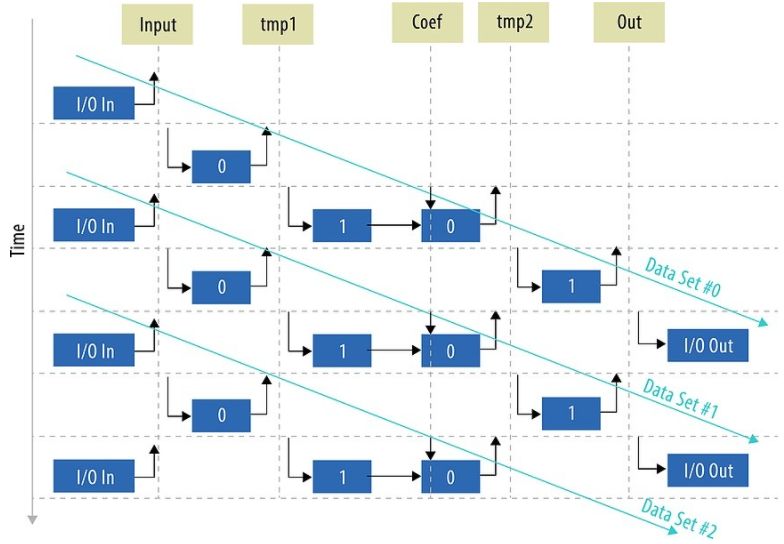
只有两个 F1T 副本可以容纳,但图 3 显示了如何安排数据流以充分利用管道。请注意,在稳定状态下,管道会在一次处理两个和三个数据集之间交替,而无需额外的缓冲区。此调度由在 CPU 上运行的主机程序控制,并使用 Dynamic Profiler 工具进行验证。
图 3:在内核调度方面,“0”是 F1T 管道的第一个物理副本,“1”是第二个副本。紫色箭头通过管道跟随单个数据集。
缓冲区分配
在 OpenCL 系统中,主机程序控制哪个 DDR bank 包含哪些缓冲区。由于 DDR bank 在读取或写入时效率最高,但不是两者兼而有之,因此我们可以将五个缓冲区拆分为两个 DDR bank,如下所示:
DDR bank #0 获得输入和tmp2
DDR bank #1 获取tmp1、coef和out
将缓冲区分配给 DDR bank 是 OpenCL 主机程序中的一行更改。编译器和底层平台负责其余的工作。鉴于这种自动化,我们可以在 2-DDR 和 4-DDR 板上进行试验,以找到每个板的缓冲区到 bank 的最佳映射。
结论
本文介绍如何使用 Altera OpenCL SDK for FPGA 设计 200 万点频域滤波器。所有功能验证均使用软件样式的仿真完成,并且每个硬件编译都能正常工作。我们没有打开硬件模拟器,也从不担心时序收敛。
作者:Dmitry Denisenko,Mykhailo Popryaga
审核编辑:郭婷
-
滤波器
+关注
关注
161文章
7859浏览量
178895 -
DDR
+关注
关注
11文章
715浏览量
65502 -
模拟器
+关注
关注
2文章
881浏览量
43409
发布评论请先 登录
相关推荐
模拟低通滤波器的设计方法有哪些
emi滤波器是什么滤波器
带通滤波器的插损与哪些因素有关
全通滤波器零极点的特点有哪些
陷波滤波器怎么进行滤波
陷波滤波器和超前滞后滤波器的差别是什么
iir滤波器和fir滤波器的优势和特点
高通滤波器和低通滤波器判别方法
低通滤波器、高通滤波器、带通滤波器的简单介绍
梳状滤波器的相关知识

滤波器滤波的本质:信号时频特性的选择与处理|维爱普电源滤波器






 工商网监
工商网监
评论