 一文详解C++中的移动语义
一文详解C++中的移动语义
一直以来,C++中基于值语义的拷贝和赋值严重影响了程序性能。尤其是对于资源密集型对象,如果进行大量的拷贝,势必会对程序性能造成很大的影响。
为了尽可能的减小因为对象拷贝对程序的影响,开发人员使出了万般招式:尽可能的使用指针、引用。而编译器也没闲着,通过使用RVO、NRVO以及复制省略技术,来减小拷贝次数来提升代码的运行效率。
但是,对于开发人员来说,使用指针和引用不能概括所有的场景,也就是说仍然存在拷贝赋值等行为;对于编译器来说,而对于RVO、NRVO等编译器行为的优化需要满足特定的条件(具体可以参考文章编译器之返回值优化)。
为了解决上述问题,自C++11起,引入了移动语义,更进一步对程序性能进行优化 。
C++11新标准重新定义了lvalue和rvalue,并允许函数依照这两种不同的类型进行重载。通过对于右值(rvalue)的重新定义,语言实现了移动语义(move semantics)和完美转发(perfect forwarding),通过这种方法,C++实现了在保留原有的语法并不改动已存在的代码的基础上提升代码性能的目的。
本文的主要内容如下图所示:
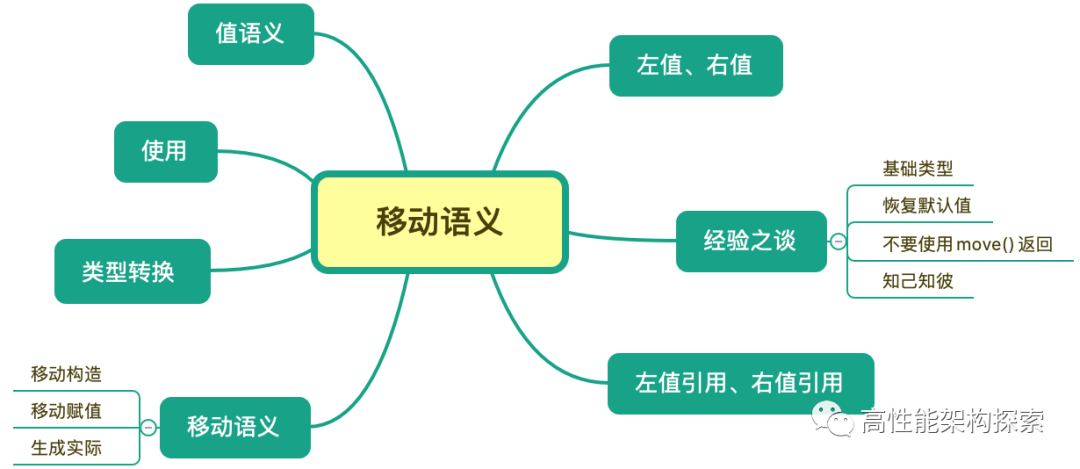
值语义
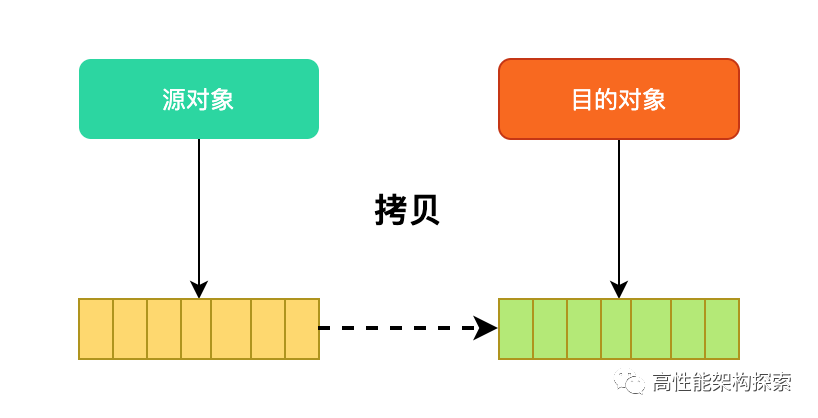
值语义(value semantics)指目标对象由源对象拷贝生成,且生成后与源对象完全无关,彼此独立存在,改变互不影响,就像int类型互相拷贝一样。C++的内置类型(bool/int/double/char)都是值语义,标准库里的complex<> 、pair<>、vector<>、map<>、string等等类型也都是值语意,拷贝之后就与原对象脱离关系。
C++中基于值语义的拷贝构造和赋值拷贝,会招致对资源密集型对象不必要拷贝,大量的拷贝很可能成为程序的性能瓶颈。
首先,我们看一段例子:
BigObjfun(BigObjobj){
BigObjo;
//dosth
returno;
}
intmain(){
fun(BigObj());
return0;
}
在上述代码中,我们定义了一个函数fun()其参数是一个BigObj对象,当调用fun()函数时候,会通过调用BigObj的拷贝构造函数,将obj变量传递给fun()的参数。
编译器知道何时调用拷贝构造函数或者赋值运算符进行值传递。如果涉及到底层资源,比如内存、socket等,开发人在定义类的时候,需要实现自己的拷贝构造和赋值运算符以实现深拷贝。然而拷贝的代价很大,当我们使用STL容器的时候,都会涉及到大量的拷贝操作,而这些会浪费CPU和内存等资源。
正如上述代码中所示的那样,当我们将一个临时变量(BigObj(),也称为右值)传递给一个函数的时候,就会导致拷贝操作,那么我们该如何避免此种拷贝行为呢?这就是我们本文的主题:移动语义。
左值、右值
关于左值、右值,我们在之前的文章中已经有过详细的分享,有兴趣的同学可以移步【Modern C++】深入理解左值、右值,在本节,我们简单介绍下左值和右值的概念,以方便理解下面的内容。
左值(lvalue,left value),顾名思义就是赋值符号左边的值。准确来说,左值是表达式结束(不一定是赋值表达式)后依然存在的对象。
可以将左值看作是一个关联了名称的内存位置,允许程序的其他部分来访问它。在这里,我们将 "名称" 解释为任何可用于访问内存位置的表达式。所以,如果 arr 是一个数组,那么 arr[1] 和 *(arr+1) 都将被视为相同内存位置的“名称”。
左值具有以下特征:
- 可通过取地址运算符获取其地址
- 可修改的左值可用作内建赋值和内建符合赋值运算符的左操作数
- 可以用来初始化左值引用(后面有讲)
C++11将右值分为纯右值和将亡值两种。纯右值就是C++98标准中右值的概念,如非引用返回的函数返回的临时变量值;一些运算表达式,如1+2产生的临时变量;不跟对象关联的字面量值,如2,'c',true,"hello";这些值都不能够被取地址。
而将亡值则是C++11新增的和右值引用相关的表达式,这样的表达式通常是将要移动的对象、T&&函数返回值、std::move()函数的返回值等。
左值引用、右值引用
在明确了左值和右值的概念之后,我们将在本节简单介绍下左值引用和右值引用。
按照概念,对左值的引用称为左值引用,而对右值的引用称为右值引用。既然有了左值引用和右值引用,那么在C++11之前,我们通常所说的引用又是什么呢?其实就是左值引用,比如:
inta=1;
int&b=a;
在C++11之前,我们通过会说b是对a的一个引用(当然,在C++11及以后也可以这么说,大家潜移默化的认识就是引用==左值引用),但是在C++11中,更为精确的说法是b是一个左值引用。
在C++11中,为了区分左值引用,右值引用用&&来表示,如下:
int&&a=1;//a是一个左值引用
intb=1;
int&&c=b;//错误,右值引用不能绑定左值
跟左值引用一样,右值引用不会发生拷贝,并且右值引用等号右边必须是右值,如果是左值则会编译出错,当然这里也可以进行强制转换,这将在后面提到。
在这里,有一个大家都经常容易犯的一个错误,就是绑定右值的右值引用,其变量本身是个左值。为了便于理解,代码如下:
intfun(int&a){
std::cout<< "infun(int&)"<< std::endl;
}
intfun(int&&a){
std::cout<< "infun(int&)"<< std::endl;
}
intmain(){
inta=1;
int&&b=1;
fun(b);
return0;
}
代码输出如下:
infun(int&)
左值引用和右值引用的规则如下:
- 左值引用,使用T&,只能绑定左值
- 右值引用,使用T&&,只能绑定右值
- 常量左值,使用const T&,既可以绑定左值,又可以绑定右值,但是不能对其进行修改
- 具名右值引用,编译器会认为是个左值
- 编译器的优化需要满足特定条件,不能过度依赖
好了,截止到目前,相信你对左值引用和右值引用的概念有了初步的认识,那么,现在我们介绍下为什么要有右值引用呢?我们看下述代码:
BigObjfun(){
returnBigObj();
}
BigObjobj=fun();//C++11以前
BigObj&&obj=fun();//C++11
上述代码中,在C++11之前,我们只能通过编译器优化(N)RVO的方式来提升性能,如果不满足编译器的优化条件,则只能通过拷贝等方式进行操作。自C++11引入右值引用后,对于不满足(N)RVO条件,也可以通过避免拷贝延长临时变量的生命周期,进而达到优化的目的。
但是仅仅使用右值引用还不足以完全达到优化目的,毕竟右值引用只能绑定右值。那么,对于左值,我们又该如何优化呢?是否可以通过左值转成右值,然后进行优化呢?等等
为了解决上述问题,标准引入了移动语义。通移动语义,可以在必要的时候避免拷贝;标准提供了move()函数,可以将左值转换成右值。接下来,就开始我们本文的重点-移动语义。
移动语义
移动语义是Howard Hinnant在2002年向C++标准委员会提议的,引用其在移动语义提案上的一句话:
移动语义不是试图取代复制语义,也不是以任何方式破坏它。相反,该提议旨在增强复制语义
对于刚刚接触移动语义的开发人员来说,很难理解为什么有了值语义还需要有移动语义。
我们可以想象一下,有一辆汽车,在内置发动机的情况下运行平稳,有一天,在这辆车上安装了一个额外的V8发动机。当有足够燃料的时候,V8发动机就能进行加速。所以,汽车是值语义,而V8引擎则是移动语义。在车上安装引擎不需要一辆新车,它仍然是同一辆车,就像移动语义不会放弃值语义一样。
所以,如果可以,使用移动语义,否则使用值语义,换句话说就是,如果燃料充足,则使用V8引擎,否则使用原始默认引擎。
好了,截止到现在,我们对移动语义有一个感官上的认识,它属于一种优化,或者说属于锦上添花。再次引用Howard Hinnant在移动语义提案上的一句话:
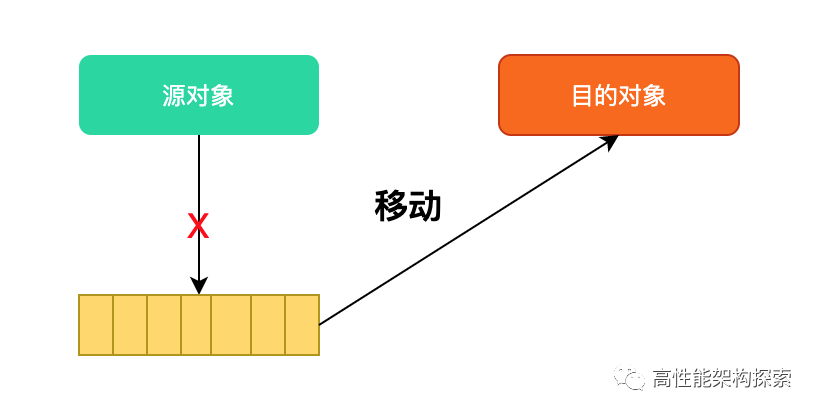
移动语义主要是性能优化:将昂贵的对象从内存中的一个地址移动到另外一个地址的能力,同时窃取源资源以便以最小的代价构建目标
在C++11之前,当进行值传递时,编译器会隐式调用拷贝构造函数;自C++11起,通过右值引用来避免由于拷贝调用而导致的性能损失。
右值引用的主要用途是创建移动构造函数和移动赋值运算符。移动构造函数和拷贝构造函数一样,将对象的实例作为其参数,并从原始对象创建一个新的实例。
但是,移动构造函数可以避免内存重新分配,这是因为移动构造函数的参数是一个右值引用,也可以说是一个临时对象,而临时对象在调用之后就被销毁不再被使用,因此,在移动构造函数中对参数进行移动而不是拷贝。换句话说,右值引用和移动语义允许我们在使用临时对象时避免不必要的拷贝。
移动语义通过移动构造函数和移动赋值操作符实现,其与拷贝构造函数类似,区别如下:
- 参数的符号必须为右值引用符号,即为&&
- 参数不可以是常量,因为函数内需要修改参数的值
- 参数的成员转移后需要修改(如改为nullptr),避免临时对象的析构函数将资源释放掉
为了方便我们理解,下面代码包含了完整的移动构造和移动运算符,如下:
classBigObj{
public:
explicitBigObj(size_tlength)
:length_(length),data_(newint[length]){
}
//Destructor.
~BigObj(){
if(data_!=NULL){
delete[]data_;
length_=0;
}
}
//拷贝构造函数
BigObj(constBigObj&other)
:length_(other.length_),data(newint[other.length_]){
std::copy(other.mData,other.mData+mLength,mData);
}
//赋值运算符
BigObj&operator=(constBigObj&other){
if(this!=&other;){
delete[]data_;
length_=other.length_;
data_=newint[length_];
std::copy(other.data_,other.data_+length_,data_);
}
return*this;
}
//移动构造函数
BigObj(BigObj&&other):data_(nullptr),length_(0){
data_=other.data_;
length_=other.length_;
other.data_=nullptr;
other.length_=0;
}
//移动赋值运算符
BigObj&operator=(BigObj&&other){
if(this!=&other;){
delete[]data_;
data_=other.data_;
length_=other.length_;
other.data_=NULL;
other.length_=0;
}
return*this;
}
private:
size_tlength_;
int*data_;
};
intmain(){
std::vectorv;
v.push_back(BigObj(25));
v.push_back(BigObj(75));
v.insert(v.begin()+1,BigObj(50));
return0;
}
移动构造
移动构造函数的定义如下:
BigObj(BigObj&&other):data_(nullptr),length_(0){
data_=other.data_;
length_=other.length_;
other.data_=nullptr;
other.length_=0;
}
从上述代码可以看出,它不分配任何新资源,也不会复制其它资源:other中的内存被移动到新成员后,other中原有的内容则消失了。换句话说,它窃取了other的资源,然后将other设置为其默认构造的状态。
在移动构造函数中,最最关键的一点是,它没有额外的资源分配,仅仅是将其它对象的资源进行了移动,占为己用。
在此,我们假设data_很大,包含了数百万个元素。如果使用原来拷贝构造函数的话,就需要将该数百万元素挨个进行复制,性能可想而知。而如果使用该移动构造函数,因为不涉及到新资源的创建,不仅可以节省很多资源,而且性能也有很大的提升。
移动赋值运算符
代码如下:
BigObj&operator=(constBigObj&other){
if(this!=&other;){
delete[]data_;
length_=other.length_;
data_=newint[length_];
std::copy(other.data_,other.data_+length_,data_);
}
return*this;
}
移动赋值运算符的写法类似于拷贝赋值运算符,所不同点在于:移动赋值预算法会破坏被操作的对象(上述代码中的参数other)。
移动赋值运算符的操作步骤如下:
- 释放当前拥有的资源
- 窃取他人资源
- 将他人资源设置为默认状态
- 返回*this
在定义移动赋值运算符的时候,需要进行判断,即被移动的对象是否跟目标对象一致,如果一致,则会出问题,如下代码:
data=std::move(data);
在上述代码中,源和目标是同一个对象,这可能会导致一个严重的问题:它最终可能会释放它试图移动的资源。为了避免此问题,我们需要通过判断来进行,比如可以如下操作:
if(this==&other){
return*this
}
生成时机
众所周知,在C++中有四个特殊的成员函数:默认构造函数、析构函数,拷贝构造函数,拷贝赋值运算符。
之所以称之为特殊的成员函数,这是因为如何开发人员没有定义这四个成员函数,那么编译器则在满足某些特定条件(仅在需要的时候才生成,比如某个代码使用它们但是它们没有在类中明确声明)下,自动生成。这些由编译器生成的特殊成员函数是public且inline。
自C++11起,引入了另外两只特殊的成员函数:移动构造函数和移动赋值运算符。如果开发人员没有显示定义移动构造函数和移动赋值运算符,那么编译器也会生成默认。
与其他四个特殊成员函数不同,编译器生成默认的移动构造函数和移动赋值运算符需要,满足以下条件:
- 如果一个类定义了自己的拷贝构造函数,拷贝赋值运算符或者析构函数(这三者之一,表示程序员要自己处理对象的复制或释放问题),编译器就不会为它生成默认的移动构造函数或者移动赋值运算符,这样做的目的是防止编译器生成的默认移动构造函数或者移动赋值运算符不是开发人员想要的
- 如果类中没有提供移动构造函数和移动赋值运算符,且编译器不会生成默认的,那么我们在代码中通过std::move()调用的移动构造或者移动赋值的行为将被转换为调用拷贝构造或者赋值运算符
- 只有一个类没有显示定义拷贝构造函数、赋值运算符以及析构函数,且类的每个非静态成员都可以移动时,编译器才会生成默认的移动构造函数或者移动赋值运算符
- 如果显式声明了移动构造函数或移动赋值运算符,则拷贝构造函数和拷贝赋值运算符将被隐式删除(因此程开发人员必须在需要时实现拷贝构造函数和拷贝赋值运算符)
与拷贝操作一样,如果开发人员定义了移动操作,那么编译器就不会生成默认的移动操作,但是编译器生成移动操作的行为和生成拷贝操作的行为有些许不同,如下:
-
两个拷贝操作是独立的:声明一个不会限制编译器生成另一个。所以如果你声明一个拷贝构造函数,但是没有声明拷贝赋值运算符,如果写的代码用到了拷贝赋值,编译器会帮助你生成拷贝赋值运算符。
同样的,如果你声明拷贝赋值运算符但是没有拷贝构造函数,代码用到拷贝构造函数时编译器就会生成它。上述规则在C++98和C++11中都成立。
-
两个移动操作不是相互独立的。如果你声明了其中一个,编译器就不再生成另一个。如果你给类声明了,比如,一个移动构造函数,就表明对于移动操作应怎样实现,与编译器应生成的默认逐成员移动有些区别。
如果逐成员移动构造有些问题,那么逐成员移动赋值同样也可能有问题。所以声明移动构造函数阻止编译器生成移动赋值运算符,声明移动赋值运算符同样阻止编译器生成移动构造函数。
类型转换-move()函数
在前面的文章中,我们提到,如果需要调用移动构造函数和移动赋值运算符,就需要用到右值。那么,对于一个左值,又如何使用移动语义呢?自C++11起,标准库提供了一个函数move()用于将左值转换成右值。
首先,我们看下cppreference中对move语义的定义:
std::move is used to indicate that an object t may be "moved from", i.e. allowing the efficient transfer of resources from t to another object.
In particular, std::move produces an xvalue expression that identifies its argument t. It is exactly equivalent to a static_cast to an rvalue reference type.
从上述描述,我们可以理解为std::move()并没有移动任何东西,它只是进行类型转换而已,真正进行资源转移的是开发人员实现的移动操作。
该函数在STL中定义如下:
template<typename_Tp>
constexprtypenamestd::remove_reference<_Tp>::type&&
move(_Tp&&__t)noexcept
{returnstatic_cast<typenamestd::remove_reference<_Tp>::type&&>(__t);}
从上面定义可以看出,std::move()并不是什么黑魔法,而只是进行了简单的类型转换:
- 如果传递的是左值,则推导为左值引用,然后由static_cast转换为右值引用
- 如果传递的是右值,则推导为右值引用,然后static_cast转换为右值引用
使用move之后,就意味着两点:
- 原对象不再被使用,如果对其使用会造成不可预知的后果
- 所有权转移,资源的所有权被转移给新的对象
使用
在某些情况下,编译器会尝试隐式移动,这意味着您不必使用std::move()。只有当一个非常量的可移动对象被传递、返回或赋值,并且即将被自动销毁时,才会发生这种情况。
自c++11起,开始支持右值引用。标准库中很多容器都支持移动语义,以std::vector<>为例,**vector::push_back()**定义了两个重载版本,一个像以前一样将const T&用于左值参数,另一个将T&&类型的参数用于右值参数。如下代码:
intmain(){
std::vectorv;
v.push_back(BigObj(10));
v.push_back(BigObj(20));
return0;
}
两个push_back()调用都将解析为push_back(T&&),因为它们的参数是右值。push_back(T&&)使用BigObj的移动构造函数将资源从参数移动到vector的内部BigObj对象中。而在C++11之前,上述代码则生成参数的拷贝,然后调用BigObj的拷贝构造函数。
如果参数是左值,则将调用push_back(T&):
intmain(){
std::vectorv;
BigObjobj(10);
v.push_back(obj);//此处调用push_back(T&)
return0;
}
对于左值对象,如果我们想要避免拷贝操作,则可以使用标准库提供的move()函数来实现(前提是类定义中实现了移动语义),代码如下:
intmain(){
std::vectorv;
BigObjobj(10);
v.push_back(std::move(obj));//此处调用push_back(T&&)
return0;
}
我们再看一个常用的函数swap(),在使用移动构造之前,我们定义如下:
template
voidswap(T&a,T&b) {
Ttemp=a;//调用拷贝构造函数
a=b;//调用operator=
b=temp;//调用operator=
}
如果T是简单类型,则上述转换没有问题。但如果T是含有指针的复合数据类型,则上述转换中会调用一次复制构造函数,两次赋值运算符重载。
而如果使用move()函数后,则代码如下:
template
voidswap(T&a,T&b) {
Ttemp=std::move(a);
a=std::move(b);
b=std::move(temp);
}
与传统的swap实现相比,使用move()函数的swap()版本减少了拷贝等操作。如果T是可移动的,那么整个操作将非常高效。如果它是不可移动的,那么它和普通的swap函数一样,调用拷贝和赋值操作,不会出错,且是安全可靠的。
经验之谈
对int等基础类型进行move()操作,不会改变其原值
对于所有的基础类型-int、double、指针以及其它类型,它们本身不支持移动操作(也可以说本身没有实现移动语义,毕竟不属于我们通常理解的对象嘛),所以,对于这些基础类型进行move()操作,最终还是会调用拷贝行为,代码如下:
intmain()
{
inta=1;
int&&b=std::move(a);
std::cout<< "a="<< a << std::endl;
std::cout<< "b="<< b << std::endl;
return0;
}
最终结果输出如下:
a=1
b=1
move构造或者赋值函数中,请将原对象恢复默认值
我们看如下代码:
classBigObj{
public:
explicitBigObj(size_tlength)
:length_(length),data_(newint[length]){
}
//Destructor.
~BigObj(){
if(data_!=NULL){
delete[]data_;
length_=0;
}
}
//拷贝构造函数
BigObj(constBigObj&other)=default;
//赋值运算符
BigObj&operator=(constBigObj&other)=default;
//移动构造函数
BigObj(BigObj&&other):data_(nullptr),length_(0){
data_=other.data_;
length_=other.length_;
}
private:
size_tlength_;
int*data_;
};
intmain(){
BigObjobj(1000);
BigObjo;
{
o=std::move(obj);
}
//useobj;
return0;
}
在上述代码中,调用移动构造函数后,没有将原对象回复默认值,导致目标对象和原对象的底层资源(data_)执行同一个内存块,这样就导致退出main()函数的时候,原对象和目标对象均调用析构函数释放同一个内存块,进而导致程序崩溃。
不要在函数中使用std::move()进行返回
我们仍然以Obj进行举例,代码如下:
Objfun(){
Objobj;
returnstd::move(obj);
}
intmain(){
Objo1=fun();
return0;
}
程序输出:
inObj()0x7ffe600d79e0
inObj(constObj&&obj)
in~Obj()0x7ffe600d79e0
如果把fun()函数中的std::move(obj)换成return obj,则输出如下:
inObj()0x7ffcfefaa750
通过上述示例的输出,是不是有点超出我们的预期。从输出可以看出来,第二种方式(直接return obj)比第一种方式少了一次move构造和析构。这是因为编译器做了NRVO优化。
所以,我们需要切记:如果编译器能够对某个函数做(N)RVO优化,就使用(N)RVO,而不是自作聪明使用std::move()。
知己知彼
STL中大部分已经实现移动语义,比如std::vector<>,std::map<>等,同时std::unique_ptr<>等不能被拷贝的类也支持移动语义。
我们看下如下代码:
classBigObj
{
public:
BigObj(){
std::cout<<__PRETTY_FUNCTION__<<std::endl;
}
~BigObj(){
std::cout<<__PRETTY_FUNCTION__<<std::endl;
}
BigObj(constBigObj&b){
std::cout<<__PRETTY_FUNCTION__<<std::endl;
}
BigObj(BigObj&&b){
std::cout<<__PRETTY_FUNCTION__<<std::endl;
}
};
intmain(){
std::arrayv;
autov1=std::move(v);
return0;
}
上述代码输出如下:
BigObj::BigObj()
BigObj::BigObj()
BigObj::BigObj(BigObj&&)
BigObj::BigObj(BigObj&&)
BigObj::~BigObj()
BigObj::~BigObj()
BigObj::~BigObj()
BigObj::~BigObj()
而如果把main()函数中的std::array<>换成std::vector<>后,如下:
intmain(){
std::vectorv;
v.resize(2);
autov1=std::move(v);
return0;
}
则输出如下:
BigObj::BigObj()
BigObj::BigObj()
BigObj::~BigObj()
BigObj::~BigObj()
从上述两处输出可以看出,std::vector<>对应的移动构造不会生成多余的构造,且原本的element都移动到v1中;而相比std::array<>中对应的移动构造却有很大的区别,基本上会对每个element都调用移动构造函数而不是对std::array<>本身。
因此,在使用std::move()的时候,最好要知道底层的基本实现原理,否则往往会得到我们意想不到的结果。
原文标题:【Modern C++】深入理解移动语义
文章出处:【微信公众号:Linux爱好者】欢迎添加关注!文章转载请注明出处。
-
C++
+关注
关注
22文章
2109浏览量
73669 -
代码
+关注
关注
30文章
4790浏览量
68646 -
语义
+关注
关注
0文章
21浏览量
8664
原文标题:【Modern C++】深入理解移动语义
文章出处:【微信号:LinuxHub,微信公众号:Linux爱好者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一文详解Linux C++内存管理
一文初识C++







 工商网监
工商网监
评论