 FPGA与GPU架构的背景
FPGA与GPU架构的背景

人工智能(AI)模型的规模和复杂度以每年大约 10 倍的速度不断增加,AI 解决方案提供商面临着巨大的压力,他们必须缩短产品上市时间,提高性能,快速适应不断变化的形势。模型复杂性日益增加,AI 优化的硬件随之出现。
例如,近年来,图形处理单元(GPU)集成了 AI 优化的算法单元,以提高 AI 计算吞吐量。然而,随着 AI 算法和工作负载的演变与发展,它们会展现出一些属性,让我们难以充分利用可用的 AI 计算吞吐量,除非硬件提供广泛的灵活性来适应这种算法变化。近期的论文表明,许多 AI 工作负载都难以实现 GPU 供应商报告的全部计算能力。即使对于高度并行的计算,如一般矩阵乘法(GEMM),GPU 也只能在一定规模的矩阵下实现高利用率。因此,尽管 GPU 在理论上提供较高的 AI 计算吞吐量(通常称为“峰值吞吐量”),但在运行 AI 应用时,实际性能可能低得多。
FPGA 可提供一种不同的 AI 优化的硬件方法。与 GPU 不同,FPGA 提供独特的精细化空间可重构性。这意味着我们可以配置 FPGA 资源,以极为准确的顺序执行精确的数学函数,从而实施所需的操作。每个函数的输出都可以直接路由到需要它的函数的输入之中。这种方法支持更加灵活地适应特定的 AI 算法和应用特性,从而提高可用 FPGA 计算能力的利用率。此外,虽然 FPGA 需要硬件专业知识才能编程(通过硬件描述语言),但专门设计的软核处理单元(也就是重叠结构),允许 FPGA 以类似处理器的方式编程。FPGA 编程完全通过软件工具链来完成,简化了任何特定于 FPGA 的硬件复杂性。
FPGA与GPU架构的背景
2020 年,英特尔 宣布推出首款 AI 优化的 FPGA — 英特尔 Stratix 10 NX FPGA 器件。英特尔 Stratix 10 NX FPGA 包括 AI 张量块,支持 FPGA 实现高达 143 INT8 和 286 INT4 峰值 AI 计算 TOPS 或 143 块浮点 16(BFP16)和 286 块浮点 12(BFP12)TFLOPS。最近的论文表明,块浮点精度可为许多 AI 工作负载提供更高的精度和更低的消耗。NVIDIA GPU 同样也提供张量核。但从架构的角度来看,GPU 张量核和 FPGA AI 张量块有很大的不同,如下图所示。
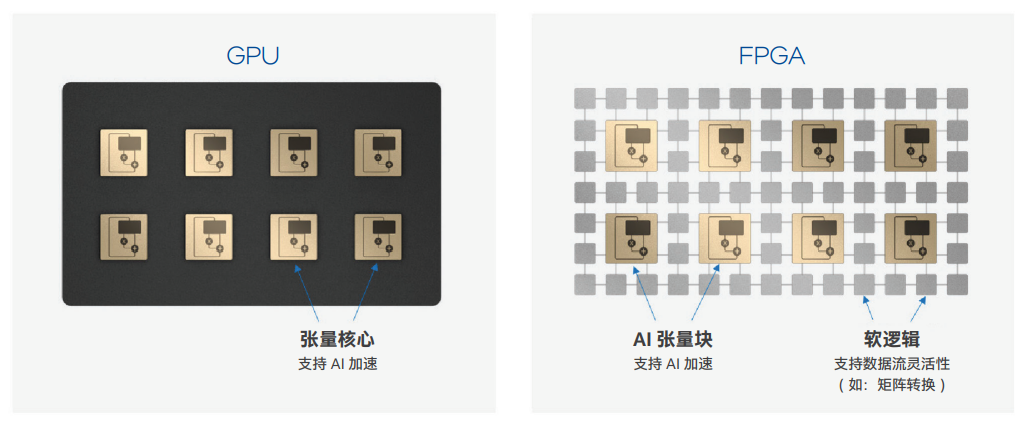
GPU 和 FPGA 都有张量核心。FPGA 有可以在数据流内外编织的软逻辑
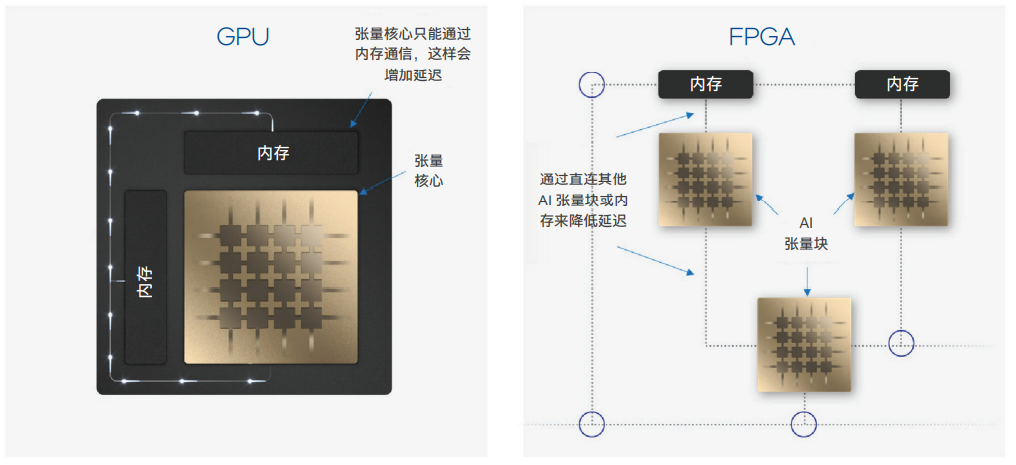
(左)GPU 数据从张量核心处理的内存系统中读取,写回内存系统。(右)FPGA 数据可以从内存中读取,但数据流可以并行安排到一个或多个张量核心。任意数量的张量核心都能以最小的传输开销使用输出。数据可以被写回内存或路由到其他任何地方
英特尔研究人员开发了一种名为神经处理单元(NPU)的 AI 软处理器。这种 AI 软处理器适用于低延迟、低批量推理。它将所有模型权重保持在一个或多个连接的 FPGA 上以降低延迟,从而确保模型持久性。
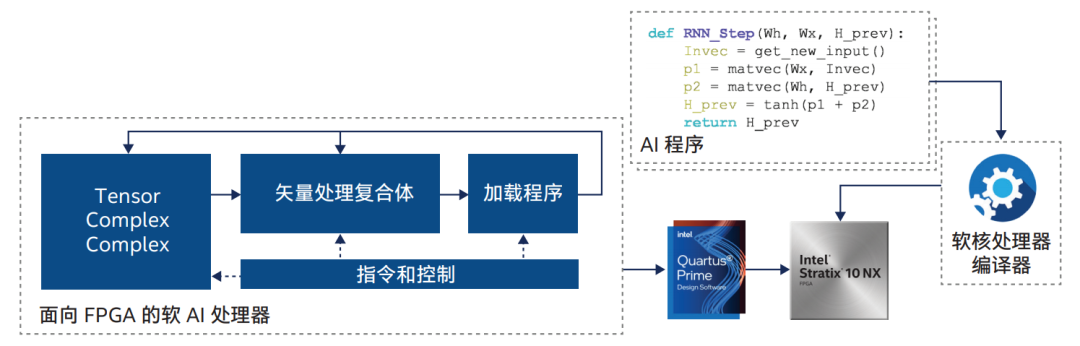
NPU 重叠架构和用于编程 NPU 软核处理器的前端工具链高级概述
FPGA与GPU性能比较
本次研究的重点是计算性能。下图比较了英特尔 Stratix 10 NX FPGA 上的 NPU 与 NVIDIA T4 和 V100 GPU 运行各种深度学习工作负载的性能,包括多层感知器(MLP)、一般矩阵向量乘法(GEMV)、递归神经网络(RNN)、长期短期记忆(LSTM)和门控循环单元(GRU)。GEMV 和 MLP 由矩阵大小来指定,RNN、LSTM 和 GRU 则通过大小和时间步长来指定。例如,LSTM-1024-16 工作负载表示包含 1024x1024 矩阵和 16 个时间步长的 LSTM。
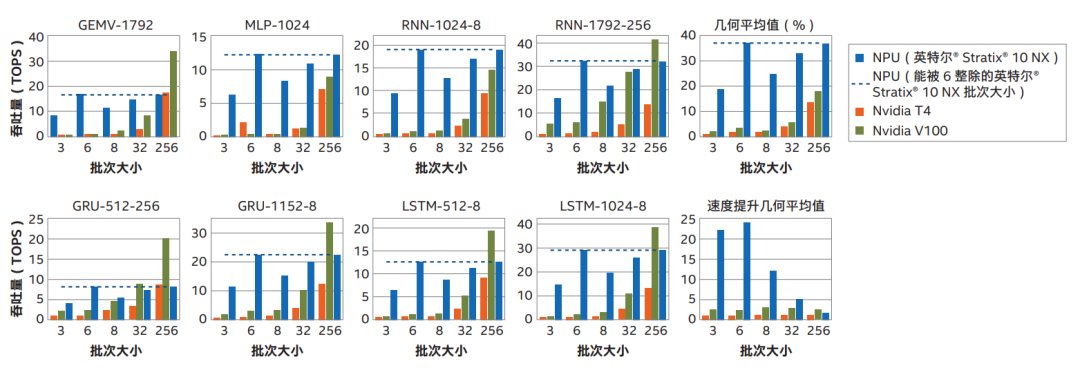
NVIDIA V100 和 NVIDIA T4 与英特尔 Stratix 10 NX FPGA 上的 NPU 在不同批处理规模下的性能。虚线显示 NPU 在批次大小可被 6 整除情况下的性能
从这些结果可以充分地看出,英特尔 Stratix 10 NX FPGA 不仅可以在低批次实时推理时实现比 GPU 高一个数量级的性能,还可以有效地进行高批次实时推理。
由于架构上的差异和灵活编程模型,英特尔 Stratix 10 NX FPGA 还可实现更出色的端到端性能。不会产生与 GPU 相同的开销。
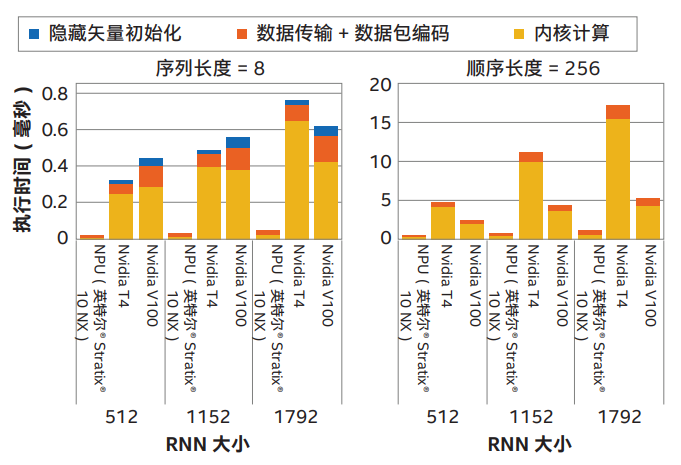
短序列和长序列时 RNN 工作负载的系统级执行时间(越低越好)
结论
英特尔 Stratix 10 NX FPGA 采用高度灵活的架构,所实现的平均性能比 NVIDIA T4 GPU 和 NVIDIA V100 GPU 分别高 24 倍和 12 倍。
由于其较高的计算密度,英特尔 Stratix 10 NX FPGA 可为以实际可达到性能为重要指标的高性能、延迟敏感型 AI 系统提供至关重要的功能。
审核编辑 :李倩
-
FPGA
+关注
关注
1664文章
22519浏览量
639772 -
英特尔
+关注
关注
61文章
10331浏览量
181173 -
算法
+关注
关注
23文章
4811浏览量
98630
原文标题:实际性能超过GPU,英特尔®Stratix®10 NX FPGA如何助您在AI加速领域赢得先机?
文章出处:【微信号:zhuyandz,微信公众号:FPGA之家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
内存要取代GPU?HBM之父警告:以英伟达GPU为核心的架构要被颠覆

登临科技GPU+架构助力铁路检测智能化升级
基于openEuler平台的CPU、GPU与FPGA异构加速实战

FPGA+GPU异构混合部署方案设计
摩尔线程公布全功能GPU架构路线图:以“花港”新架构与万卡训练集群,开启自主算力新时代

AMD UltraScale架构:高性能FPGA与SoC的技术剖析
FPGA+DSP/ARM架构开发与应用
如何看懂GPU架构?一分钟带你了解GPU参数指标

【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】+NVlink技术从应用到原理
GPU架构深度解析



评论