 推动处理车辆传感器数据
推动处理车辆传感器数据
现在还有许多其他人正在竞相处理所有这些车辆传感器数据。其中,东芝一直在发展其 Visconti 图像识别处理器系列,以满足日益苛刻的欧洲新车评估计划 (Euro NCAP) 要求。
从 2014 年开始,Euro NCAP 开始根据主动安全技术对车辆进行评级,例如车道偏离警告 (LDW)、车道保持辅助 (LKA) 和自动紧急制动 (AEB)。这些要求在 2016 年扩展到日间行人 AEB 和速度辅助系统 (SAS)。2018 年,这些要求将进一步扩大,包括夜间行人 AEB,以及日间和夜间骑车人 AEB(图 1)。

图 1.欧洲新车评估计划 (Euro NCAP) 的要求近年来有所扩展,包括许多高级驾驶员辅助系统 (ADAS) 功能。
为了满足能够在白天和夜间环境中准确识别移动和静止物体的视觉系统的需求,东芝的 TMPV7608XBG Visconti4 处理器等图像识别处理器采用了一套计算技术(图 2)。除了 CPU 和 DSP 之外,8 个硬件加速模块使设备能够高效地执行高度专业化的汽车计算机视觉 (CV) 工作负载,例如仿射变换(线性映射)、过滤、直方图、匹配和金字塔图像生成。
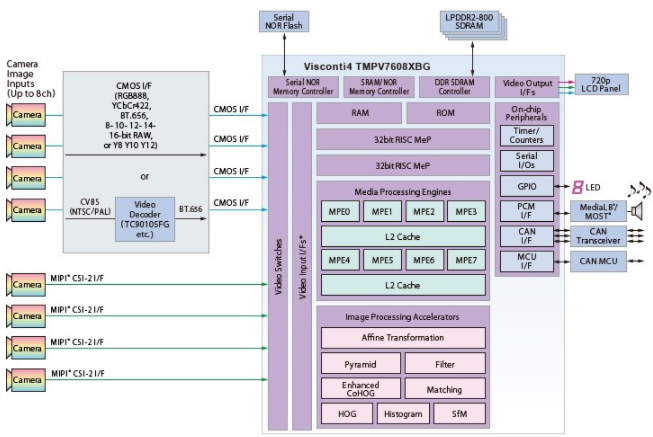
图 2. Toshiba TMPV7608XBG Visconti4 图像识别处理器利用 CPU、图像处理引擎 (DSP) 和图像处理加速器(硬件加速器)来计算一系列汽车计算机视觉 (CV) 工作负载。
TMPV7608XBG 上的两个新硬件加速模块专门解决了夜间和移动/静止物体检测的挑战:增强的定向梯度共现直方图 (CoHOG) 和运动结构 (SfM) 加速器。
对于夜间 ADAS 应用,增强型 CoHOG 加速器通过结合基于亮度和颜色的特征描述符来抵消物体与其周围环境之间的低对比度,从而超越了传统的模式识别。据东芝称,增强型 CoHOG 加速器不仅可以减少物体识别所需的时间,而且可以在夜间实现与白天一样可靠的行人检测。
同时,SfM 加速器使用来自单目相机的连续图像来开发高度、宽度和到对象距离的三维估计(图 3)。因此可以在没有任何学习曲线的情况下检测静止物体,并且可以应用运动分析和模式识别来检测运动物体,例如行人或车辆。由于 3D 信息减少了图像中的感兴趣区域,ADAS 系统能够更快地识别障碍物并做出反应。
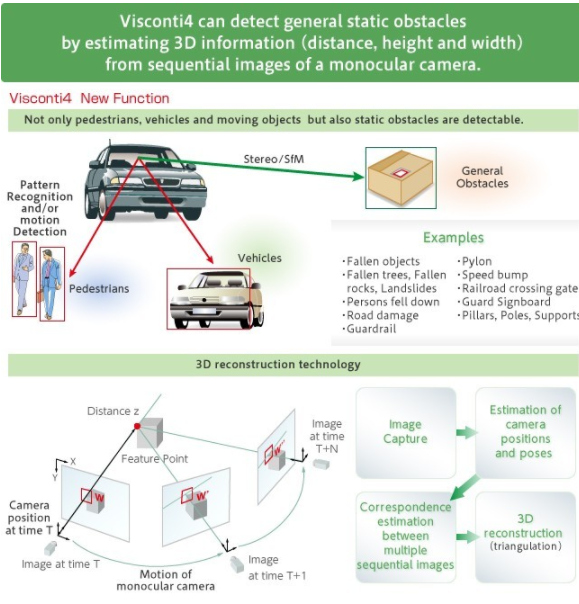
图 3. TMPV7608XBG 的运动结构 (SfM) 加速器使用三维映射来检测静止和移动物体。
这些加速器与 TMPV7608XBG 的 DSP 子系统中的八个媒体处理引擎 (MPE) 一起运行,每个都配备双精度浮点单元 (FPU)。因此,该设备可以同时并行执行 8 个图像识别应用程序,响应时间为 50 毫秒。以 266.7 MHz 的时钟频率运行,与之前的 Visconti 处理器相比,这意味着处理时间减少了 50%(图 5)。
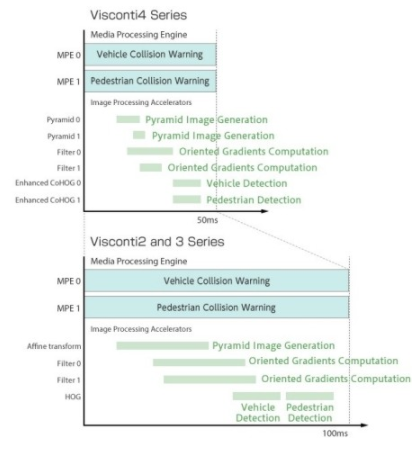
图 5. TMPV7608XBG Visconti4 处理器的性能与上一代 Visconti 处理器相比,处理时间减少了 50%。
东芝公开的 Visconti4 图像识别处理器设计中标包括 DENSO Corporation 的基于前置摄像头的主动安全系统。
但图像处理只是当今汽车安全系统中的一块拼图。除了摄像头之外,现代 ADAS 应用和半自动车辆还依赖于雷达、激光雷达、接近传感器、GPS、车联网 (V2X) 连接和其他有源组件的输入。来自所有这些输入的数据必须实时处理、分析和融合,以便在危险情况下迅速采取纠正措施。
人工智能 (AI) 似乎是在自动和半自动车辆用例中执行驾驶策略和做出实时决策的理想技术。然而,传统的基于云的 AI 实现不适合汽车安全应用,这主要是因为与数据传输相关的延迟,还因为隐私、安全、成本和网络覆盖问题。
作为替代方案,能够运行片上人工或深度神经网络 (ANN/DNN) 的超级计算机级处理器正在被设计到特斯拉等汽车安全系统的电子控制单元 (ECU) 中。例如,NVIDIA 声称其 Drive PX Pegasus 平台的变体将提供高达每秒 320 万亿次深度学习操作 (TOPS),这对于 5 级自动驾驶汽车来说已经足够了。
不幸的是,这些处理器也有其自身的挑战。除了相当大的功耗和单位成本外,这些芯片的裸片尺寸也很大(图 7)。如果将每年生产的大约 1 亿辆汽车中的每辆都考虑到一个这样的处理器,那么汽车市场的需求量将是目前为智能手机生产的芯片的三倍。这远远超过了当前的硅晶片制造能力。
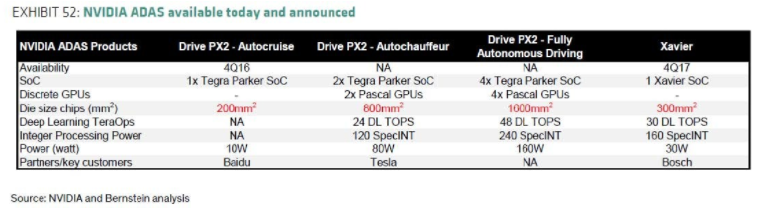
图 7.虽然高性能处理器提供了运行片上神经网络以实现完全自动驾驶的计算能力,但目前生产它们所需的芯片尺寸超过了硅晶圆的制造能力。资料来源:英伟达和伯恩斯坦研究。
同样,DSP IP 模块提供的解决方案更适合嵌入式汽车用例,CEVA 深度神经网络 (CDNN) 就是一个例子。CDNN 包括神经网络生成器、软件框架和硬件加速器,专为与 CEVA-XM 成像和视觉 DSP 内核配合使用(图 8)。这里的价值主张是降低功耗、降低成本以及在整个系统设计中分配智能的能力。
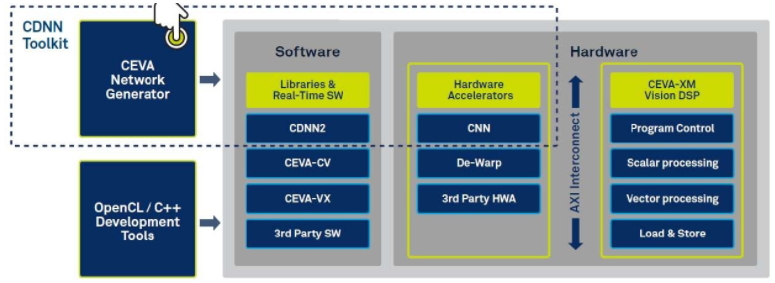
图 8. CEVA 深度神经网络 (CDNN) 是一个用于在嵌入式 DSP 上开发、生成和部署神经网络的工具包。
CDNN 的核心是像 CEVA-XM6 这样的 DSP,它包括矢量和标量处理单元以及 3D 数据处理模式。矢量和标量处理单元使 -XM6 非常适合传感器数据融合,而其 3D 数据处理方案有助于加速神经网络性能(图 9)。在 CDNN 环境中,这些 DSP 配备一个或多个硬件加速器,在卷积神经网络 (CNN) 处理中每个周期提供 512 次乘法累加 (MAC) 操作。所有其他神经网络层——任何类型或数量——都由 DSP 本身运行。
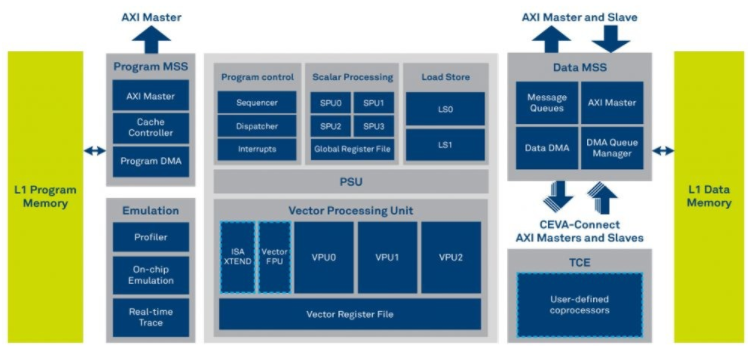
图 9.矢量和标量处理单元与 3D 数据处理方案相结合,使 CEVA-XM6 DSP 非常适合汽车安全和人工智能工作负载。
但 CDNN 工具包的独特之处在于 CEVA 网络生成器。网络生成器将在 Caffe 和 TensorFlow 等框架中开发的预训练神经网络转换为可以在嵌入式系统中运行的实时神经网络模型。从那里,第二代 CDNN 软件框架可用于应用程序调整。
据 CEVA, Inc. 称,CDNN 工具包处理 CNN 的速度比基于 GPU 的替代方案快四倍,能效提高 25 倍。该公司负责市场情报、投资者和公共关系的副总裁 Richard Kingston 表示,该技术目前在汽车领域获得了超过五项设计胜利,著名的合作伙伴是安森美半导体、NEXTCHIP 以及正在使用的一级汽车 OEM它在完全自主的车辆设计中。
审核编辑:郭婷
-
传感器
+关注
关注
2552文章
51222浏览量
754637 -
处理器
+关注
关注
68文章
19347浏览量
230242 -
半导体
+关注
关注
334文章
27516浏览量
219766
发布评论请先 登录
相关推荐
2025年引起轰动的10大传感器技术
康谋分享 | 如何应对ADAS/AD海量数据处理挑战?

工业传感器如何实现数据采集?
汽车传感器的功能与种类
传感器的数据怎么传到云平台
车载传感器网络是什么意思啊
车载传感器主要有哪些传感器
汽车横摆率传感器的功能重要性
温度传感器的常见故障及处理方法
为坚固耐用型车辆的控制机构选择和应用线性位置传感器

CMOS图像传感器的制造工艺





 工商网监
工商网监
评论