 CN0549状态监测平台及如何利用进行应用程序开发
CN0549状态监测平台及如何利用进行应用程序开发
在本文中,我们将重点介绍可用于CN0549不同组件的软件生态系统、数据分析工具和软件集成,以及工程师和数据科学家如何利用它们进行应用程序开发。这是关于使用 CN0549 开发平台的基于状态的监控 (CbM) 和预测性维护 (PdM) 应用程序的两部分系列文章中的第二篇。新平台旨在加速定制 CbM 解决方案从原型到生产的开发流程。第 1 部分侧重于 MEMS 振动技术和捕获用于 CbM 应用的高质量振动数据。
生产之旅以及如何更快地做到这一点!
在构建状态监测解决方案时,它们必须包含传感器、本地处理、连接以及某种形式的软件或固件,以使其全部发挥作用。CN0549 通过为硬件和软件方面提供可定制的选项来应对所有这些挑战,因此工程师和软件开发人员可以在使用通用工具和基础设施的同时在其应用程序中进行设计权衡。例如,如果您想选择一个特定的微控制器或 FPGA 进行处理,更喜欢使用 Python 编码,或者有一个您想要重用的最喜欢的传感器。这使得 CN0549 成为那些希望构建优化的 CbM 解决方案的强大平台,可以根据他们的需求定制处理、功率、性能、软件和数据分析。
嵌入式系统开发流程
让我们考虑一个嵌入式系统从概念到生产的通用开发流程。图 1 提供了抽象流的顶层概览。
图 1 所示设计过程的第一步是数据研究阶段。在这个阶段,用户将他们的需求映射到他们的应用程序所需的不同硬件和软件需求。从硬件角度来看,这些参数可能是冲击容限、模拟信号带宽或测量范围等参数。在考虑软件要求时,样本数量、采样率、频谱、过采样和数字滤波是 CbM 应用的重要参数。该平台非常有用且灵活,允许研究人员使用不同的传感器组合并根据自己的应用需求调整数据采集参数。
数据研究阶段之后是算法开发阶段,在此阶段证明了系统的应用或使用。这通常需要在最终移植到嵌入式系统的高级工具中开发模型或设计算法。然而,在优化设计之前,必须使用真实数据和硬件在环进行验证,而这正是 CN0549 真正擅长的地方,因为它不仅提供与流行的高级分析工具的直接集成,而且还允许硬件在循环验证。
一旦设计得到验证,优化和嵌入必要的软件组件的工作就开始了。在嵌入式设计细化阶段,这可能需要重新实现某些算法或软件层才能在 FPGA 或资源受限的微控制器中工作。在将设计移植到原型或接近生产硬件以进行最终验证时,必须非常小心地持续验证设计。

图 1. 嵌入式系统开发流程。
最后,我们到达了生产阶段,这可能与设计开始使用的原始开发环境几乎没有相似之处,但仍然需要满足相同的要求。由于最终系统可能已经远离原始研究系统,因此运行相同的代码或测试可能是不可能的或极其困难的。这可能会导致生产测试问题和单元故障,并且可能需要额外的时间和金钱投资来进行补救。
通过最大限度地重复使用来降低风险
在设计过程中降低风险的最简单方法之一是在每个阶段重复使用尽可能多的硬件和软件组件,CN0549 提供了许多开箱即用的资源,供开发人员在开发流程的所有阶段直接利用。CN0549 解决方案提供原理图和电路板布局文件、用于优化和全功能环境的开放软件堆栈,以及用于 MATLAB® 和 Python 等高级工具的集成选项。最终用户可以利用 ADI 的经过验证的组件,并在从研究到生产的过程中选择他们想要维护或更改的组件。这也使最终用户能够专注于算法开发和系统集成,而不是使用 ADI 零件的原理图输入或基础软件开发。利用硬件模块和重用软件层,
软件开发流程和过程
CN0549 在开发过程中为工程师提供了多种选择,允许他们使用常用语言(包括 C 或 C++)工作,同时使用他们熟悉的数据分析工具,例如 MATLAB 或 Python。这主要是通过利用和构建开放标准以及支持来自不同制造商的多个嵌入式平台的现有解决方案来完成的。
CN0549 系统堆栈
图 2 所示的系统堆栈提供了构成 CN0549 系统的不同组件的基本概览。左上角的深蓝色方框是传感器和数据采集 (DAQ) 板,而浅蓝色和紫色方框勾勒出用于数据处理的 FPGA 分区。该平台直接支持英特尔 DE10-Nano 和 Xilinx® CoraZ7-07s,涵盖两大主要 FPGA 供应商。绿色框表示与主机 PC 的连接。这提供了从硬件到用于算法开发的高级数据分析工具的直接数据访问。
所有的 HDL 代码都是开源的,它允许开发人员进行修改以将数字信号处理 (DSP) 插入可编程逻辑 (PL) 内的数据流中,如图 2 所示。这可以是从滤波器到状态机的任何东西,甚至是机器学习,根据你的系统划分,这一步也可以在用户空间或者应用层完成。由于代码是公开可用的,它可以移植到来自不同制造商的其他 FPGA 或移植到不同的处理器系列,具体取决于您的最终应用需求。
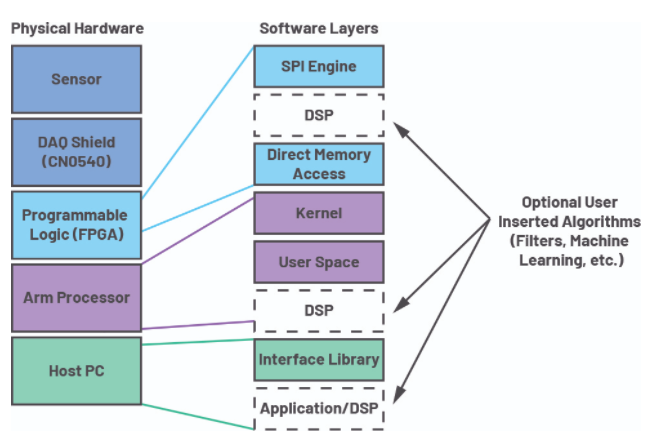
图 2. CN0549 平台的系统堆栈。
Arm® 处理器内部有两个软件选项。它们的使用将取决于用例,并且大多数开发人员都可能会使用它们:
Linux®:为内核中的输入输出工业 (IIO) 框架内构建的 DAQ shield 提供内核驱动程序。这与一个名为 Kuiper Linux 的完整嵌入式 Linux 发行版相结合,该发行版在 Arm 核心用户空间中运行并基于 Raspberry Pi OS。
无操作系统:裸机项目提供了与 Linux 内核中使用的相同驱动程序,可与 Xilinx 或 Intel 的 SDK 一起使用。这也可以作为替代实现方式实现到实时操作系统 (RTOS) 环境中。
建议开发人员从 Linux 开始学习并开始使用他们的系统进行开发,因为它提供了最多的工具。Linux 还提供了大量的软件包和驱动程序,为理想的开发环境创造了条件。一旦系统设计稳定并准备好进行优化,通常会切换到无操作系统并仅发布必要的软件。但是,这高度依赖于应用程序,由于它们提供的灵活性,许多人将发布完整的 Linux 系统。
与可编程逻辑的 HDL 一样,整个内核源代码、Kuiper Linux 映像和 No-OS 项目都是完全开源的,最终用户可以根据需要修改任何组件。如果需要,这些代码库也可以移植到不同的处理器系统或不同的运行时环境。
图 2 的最后一个组件是与主机 PC 的连接,如绿色框所示。在运行系统时,可以配置设备,并将数据流式传输到主机系统进行分析,开发人员将在主机上利用 MATLAB 或 TensorFlow 等标准工具创建算法。然后最终将这些算法转移到嵌入式目标,允许它们使用本地处理能力进行更快的算法开发迭代。
访问 CbM 数据——入门
使用 Arm 处理器和 PL 通常发生在设计流程的更进一步阶段,此时系统正在针对部署进行优化。因此,开发人员最初的一个常见入口点将涉及从工作站远程连接到嵌入式系统。在嵌入式系统上运行 Linux 时,由于基础架构的设计方式,在工作站上远程或本地运行代码是一个相对透明的过程。这主要是由于一个名为libIIO的开放库。 libIIO 是一个接口库,它允许对内核中 Linux IIO 框架内构建的不同设备驱动程序进行简化且一致的访问模型。该库是 CbM 平台使用如此灵活并提供数据流和设备控制功能的核心。
libIIO 本身分为两个主要组件:
libIIO 库,这是一个用于访问不同 IIO 驱动程序属性或函数的 C 库。这包括流入和流出 ADC、DAC 和传感器等设备的数据流。
称为 iiod 的 IIO 守护进程负责管理 libIIO 库或使用该库的客户端与实际驱动程序的内核接口之间的访问。
libIIO 和 iiod 本身是由不同的组件编写的,这些组件允许以不同的方法访问所谓的后端中的驱动程序。后端允许本地和远程用户对 libIIO 进行控制和数据流,并且由于它们是组件化的,因此可以将新的后端添加到系统中。目前,libIIO 支持四个后端:
本地:允许访问连接到同一台机器的硬件的本地可访问驱动程序。
USB:利用 libusb,此后端允许通过 USB 链接远程控制驱动程序。
串行:为通过串行连接连接的板提供更通用的接口。UART 是最常见的用途。
网络:最常用的远程后端,它是基于 IP 的,用于跨网络访问驱动程序。
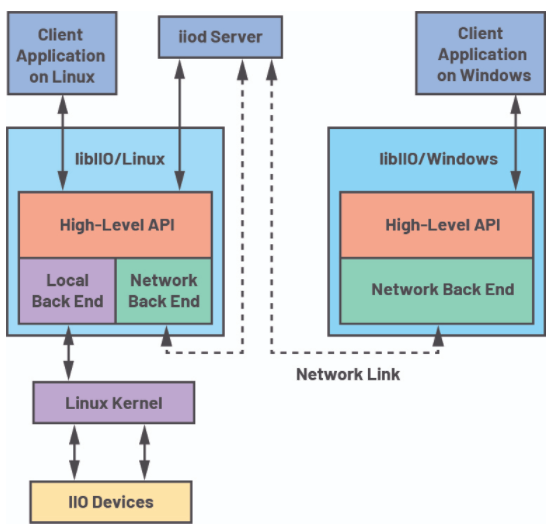
图 3. 使用网络后端的 libIIO 系统概要。
图 3 提供了如何使用 libIIO 的组件以及它们如何适应整个系统的系统级概览。图的左侧是嵌入式系统,它安装了 libIIO 库并运行 iiod 守护进程。从嵌入式系统,用户可以访问本地后端,甚至网络后端。在他们的代码中,他们可以通过单行更改在两者之间切换以解决任一后端。不需要对目标代码进行其他更改。

图 4. libIIO 远程与本地示例。
图 3 的左侧代表一个远程主机,它可以运行任何操作系统。有适用于 Windows、macOS、Linux 和 BSD 的官方软件包。图中使用了网络或基于 IP 的后端,但这也可以是串行、USB 或 PCIe 连接。从用户的角度来看,libIIO 可以从 C 库本身或许多与其他语言的可用绑定中得到利用,包括:Python、C#、Rust、MATLAB 和 Node.js。为需要与其应用程序中的不同驱动程序交互的用户提供大量选择。
应用程序和工具
在开始使用新设备时,一般不建议直接使用 libIIO。因此,存在许多构建在 libIIO 之上的更高级别的应用程序,它们为任何 IIO 设备从命令行和 GUI 格式提供基本的可配置性。这些分别是 IIO 工具和 IIO 示波器。
IIO 工具是一组与 libIIO 一起提供的命令行工具,可用于通过脚本进行低级调试和自动任务。例如,对于实验室测试,将平台设置为不同的采样率模式并收集一些数据可能很有用。这可以通过几行 bash 或通过利用 IIO 工具的批处理脚本轻松完成。图 5 显示了一个简单的示例,可以在本地或远程运行以修改采样率和更改 ADC 的输入共模。该示例使用了一个名为 iio_attr 的 IIO 工具,它允许用户轻松更新设备配置。
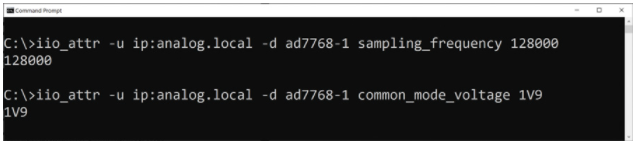
图 5. IIO 工具的 iio_attr 部分的示例用法。
但是,用户最常见的入口点是 GUI 应用程序 IIO 示波器,通常称为 OSC。OSC 与 IIO 工具一样,被设计成通用的,可以控制任何 IIO 驱动程序,并且由于它基于 libIIO,它可以远程运行或在板上运行。但是,它还包含一个插件系统,其中可以为特定驱动程序或驱动程序组合添加专门的选项卡。图 6 显示了为基于CN0540的板自动加载的插件选项卡,包括控制和监控选项卡。这些选项卡提供了一个简单的界面来访问 CN0540 的 ADC、DAC 和控制引脚的低级功能,以及数据采集板和测试点监控的基本图。Analog Devices上提供了更多 OSC 文档 如果您想了解其他可用的默认选项卡和插件,请访问Wiki 。
OSC 的最后一个重要方面是捕获窗口。捕获窗口为从 ADC 或任何基于 libIIO 的缓冲区收集的数据提供绘图功能。图 7 显示了在频域模式下使用的捕获窗口,其中绘制了数据的频谱信息。其他图,包括时域图、相关图和星座图,都是可用的。这对于抽查设备、调试或在评估过程中很有用。这些图包括常见的实用程序,如标记、峰值检测、谐波检测,甚至相位估计。由于 OSC 也是开源的,因此任何人都可以对其进行扩展以添加更多插件或绘图,甚至修改现有功能。
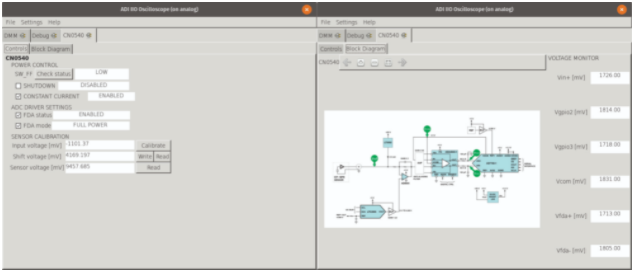
图 6. CN0540 IIO 示波器插件选项卡。
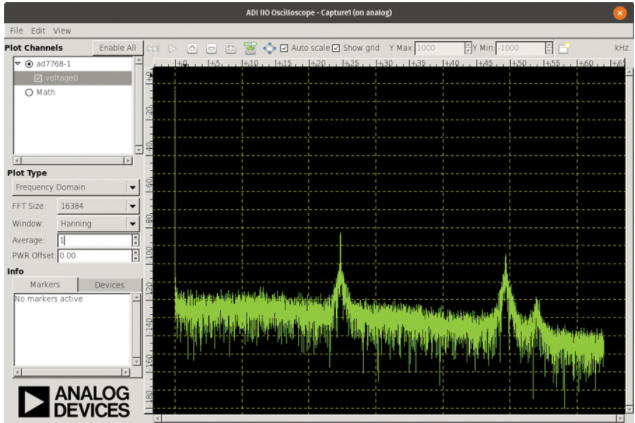
图 7. 频域模式下的 IIO 示波器捕获窗口。
算法开发环境集成
到目前为止,我们已经介绍了大多数工程师在首次使用 CN0549 时开始使用的核心低级工具。首先了解这些很重要,这样开发人员才能了解系统的灵活性以及他们可以使用的不同选择或接口。然而,在基线系统启动并运行后,开发人员将希望使用 MATLAB 或 Python 等工具快速将数据转移到算法开发中。这些程序可以从硬件导入数据。必要时可以设计额外的控制逻辑。
在机器学习开发周期的上下文中,通常有一个通用流程,开发人员将遵循独立于他们所需的软件环境来处理数据。图 8 中概述了此过程的一个示例,其中收集数据,分为测试和训练,开发模型或算法,最后部署模型以进行现场推理。对于实际服务,会不断执行整个过程,以将新知识引入生产模型。TensorFlow、PyTorch 或 MATLAB 机器学习工具箱等工具都考虑到了这个过程。这个过程是有意义的,但通常可以忽略或完全忽略收集、组织和管理数据的复杂任务。为了简化这个任务,
Python 集成——连接到 Python 分析工具
首先,从 Python 开始,CN0549 的设备特定类可通过模块PyADI-IIO获得。图 6 提供了一个配置设备采样率和通过以太网提取缓冲区的简单示例。没有复杂的寄存器序列、晦涩的内存控制调用或需要记忆的随机位。这是由驱动程序、libIIO 和 PyADI-IIO 为您管理的,这些驱动程序在电路板上运行、在工作站上远程运行,甚至在云中。
可通过 pip 和 conda 安装的 PyADI-IIO 将控制旋钮公开为易于使用和记录的属性。它还以通常可消化的类型(如 NumPy 数组或本机类型)提供数据,并在可用时处理数据流的单位转换。这使得 PyADI-IIO 可以轻松添加到 Jupyter Notebook 等环境中,并且可以轻松地将数据输入机器学习管道,而无需求助于不同的工具或复杂的数据转换——允许开发人员专注于他们的算法,而不是一些困难的 API 或数据对话。
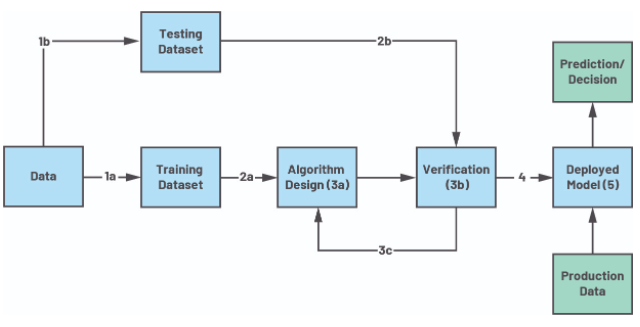
图 8. 机器学习模型开发流程。
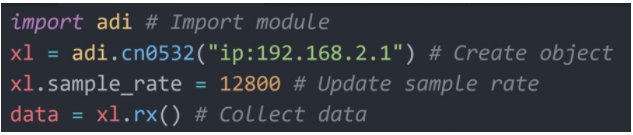
图 9. PyADI-IIO 示例。
MATLAB 集成 - 连接到 MATLAB
在 MATLAB 方面,通过 Analog Devices 传感器工具箱提供对 CN0549 及其组件的支持。该工具箱与 PyADI-IIO 一样,具有针对不同部件的设备特定类,并将它们实现为 MATLAB 系统对象 (MSO)。MSO 是 MathWorks 作者可以与硬件和不同软件组件接口的标准化方式,并提供高级功能来协助代码生成、Simulink 支持和一般状态管理。许多 MATLAB 用户可能会在不知情的情况下利用作为 MSO 实现的 MATLAB 功能,例如示波器或信号发生器。在图 10 中,我们使用 CN0532 接口和 DSP 频谱分析仪示波器,两者均作为 MSO 实现。同样,像 PyADI-IIO 一样,有一个对传统 MATLAB 用户友好的界面。
除了硬件连接之外,传感器工具箱还集成了用于 HDL 和 C/C++ 的代码生成工具。这些是用于开发、仿真和部署 IP 的绝佳工具,即使对于那些不熟悉 HDL 设计或工具但了解 MATLAB 和 Simulink 的人来说也是如此。
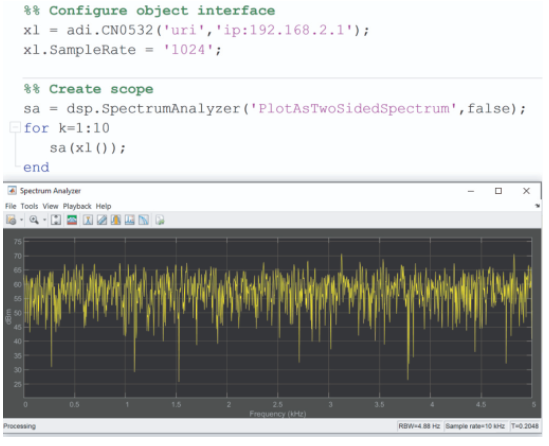
图 10. 带有示波器的 Sensor Toolbox 流式传输示例。
使用 TensorFlow 的分类示例
CN0549 套件提供了几个示例,从基本数据流到机器学习分类示例。时间序列数据的机器学习,例如来自CN0532的振动数据,可以从几个不同的角度进行处理。这可以包括支持向量机 (SVM)、长短期记忆 (LSTM) 模型,如果数据被直接解释为时间序列,甚至可以包括自动编码器。但是,在许多情况下,将时间序列问题转换为图像处理问题并利用在该应用领域开发的丰富知识和工具会更方便。
让我们看看 Python 中的这种方法。在 PyADI-IIO 提供的一个示例中,通过将 CN0532 安装到摆动风扇上进行了多次测量。这是在风扇的不同设置(睡眠、常规、过敏原)下完成的,在每种模式下,捕获了 409,600 个样本。在检查图 11 中的数据时,很容易识别过敏原病例的时域,但其他两种情况更难区分。这些可能可以通过检查来识别,但是让算法识别这些情况可能在时域中容易出错。
为了帮助更好地区分用例,将数据转换为频域,并使用频谱图绘制不同频率随时间的浓度。与图 11 相比,图 12 中显示的频谱图在数据上的差异更加明显,并且在时间维度上保持一致。这些频谱图是有效的图像,现在可以使用传统的图像分类技术进行处理。
将数据集拆分为训练集和测试集,将频谱图输入到具有三个密集层的仅中性网络 (NN) 模型和较小的卷积神经网络 (CNN) 模型中。两者都是在 TensorFlow 中实现的,并且能够在不到 100 个 epoch 内轻松收敛到接近 100% 的测试验证。CNN 在大约一半的时间内以大约 1% 的可调参数收敛,使其成为迄今为止更高效的设计。图 13 中提供了精度与 epoch 的训练收敛图,以概述 CNN 的快速收敛。
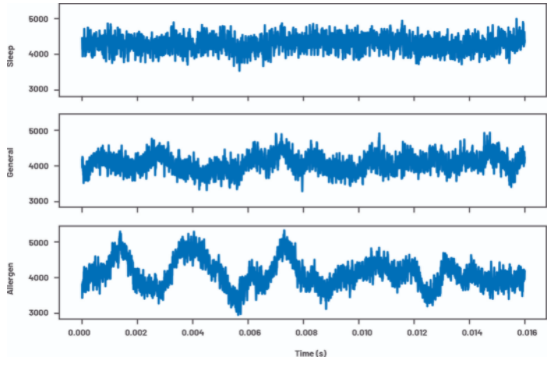
图 11. 时间序列中的风扇振动数据。
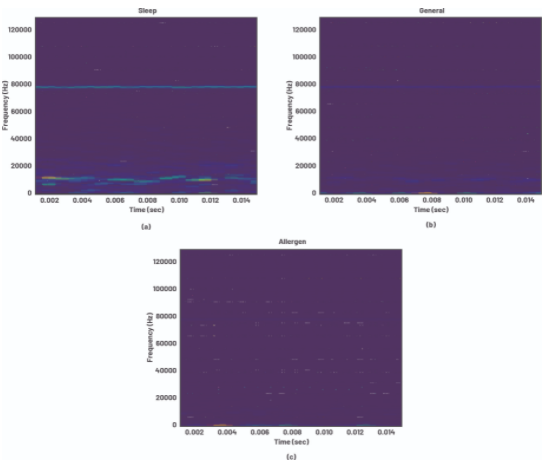
图 12. 捕获的振动数据的频谱图。
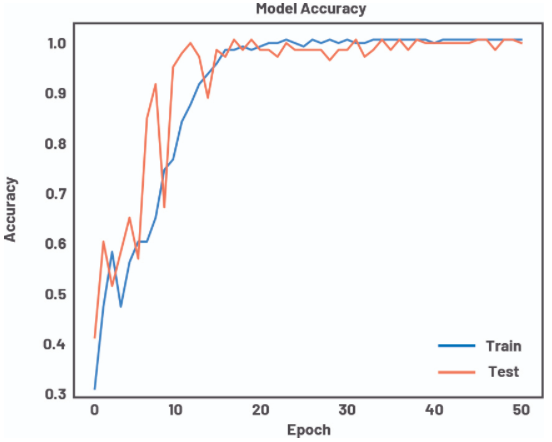
图 13. CNN 训练精度随时间变化的振动频谱图。
GitHub 上 PyADI-IIO 源代码树下的所有 Python 脚本、笔记本和数据集都可用于此示例。由于提供了数据集,TensorFlow 的示例演示甚至可以在没有 CN0549 硬件的情况下使用。然而,通过硬件,训练后的模型可以用于实时推理。
边缘到云:转向嵌入式解决方案
创建模型后,可以将其部署用于推理目的或决策制定。使用 CN0549,它可以放置在远程 PC 上,数据从 CN0540 流式传输或直接在嵌入式处理器上运行。根据实现的不同,将模型放置在处理器中需要更多的工程设计工作,但可以提高一个数量级的功率效率,并且能够实时运行。幸运的是,在过去几年中,用于部署机器学习模型的工具和软件取得了巨大的发展增长。
利用 FPGA
Xilinx 和 Intel 都拥有高级综合 (HLS) 工具,可将高级语言转换为在 FPGA 上运行的 HDL 代码。这些通常会与 TensorFlow、PyTorch 或 Caffe 等 Python 框架集成,以帮助将模型转换为 IP 内核——允许工程师将 IP 部署到 DE10-Nano、Cora Z7-07S 或自定义系统。然后将这些 IP 内核拼接到 ADI 提供的开放式 HDL 参考设计中。图 14 显示了 Vivado 的 Cora Z7-07S CN0540 的带注释屏幕截图,重点关注数据路径。在设计中,来自 CN0540 的数据通过 SPI 引脚读取,24 位样本由 SPI 引擎解释并传递到 DMA 控制器到内存中。任何 DSP 或机器学习模型都可以直接在数据路径中插入到此管道中。
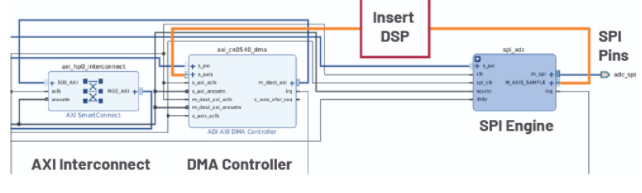
图 14. Vivado 2019.1 中显示的 Cora Z7-07S HDL 参考设计数据路径。
利用微处理器
与其将算法转换为 HDL 层,不如直接在 Arm 内核中运行。根据算法的数据速率和复杂性,这是一条合理的开发路径,通常更直接。为 Arm 内核开发 C 代码甚至可能是 Python 将比 HDL 花费更少的开发资源和时间,并且通常更易于维护。
MATLAB Embedded Coder 等工具甚至可以简化这一过程,并自动将 MATLAB 转换为针对 Arm 内核的可嵌入和优化的 C 代码。或者,TensorFlow 拥有诸如 TensorFlow Lite 之类的工具,它们是其 Python 库的可嵌入 C 版本,以允许更简单地过渡到嵌入式目标。
智能决策拓扑
基于状态的监控并不是一刀切的适用于硬件和软件的所有空间,这就是 CN0549 设计灵活的原因。当我们考虑诸如 CbM 异常检测之类的问题时,通常可以从两个时间尺度来处理:一个是我们需要立即做出反应,例如在与安全相关的场景中,或者在与维护或维护更相关的长期时间尺度上。设备更换。两者都需要不同的算法、处理能力和方法。
作为理想情况下的机器操作员,我们将拥有一个大型数据湖来训练我们的模型,并且既可以处理没有干扰事件的短期检测,又可以从正在运行的设备连续传输数据以用于未来的维护预测。然而,对于大多数运营商而言,情况可能并非如此,数据湖更像是干涸的河床。考虑到安全问题、物理位置、网络或拓扑要求,一些现成的解决方案也可能难以执行数据收集。这些困难推动了对更多定制解决方案的需求。
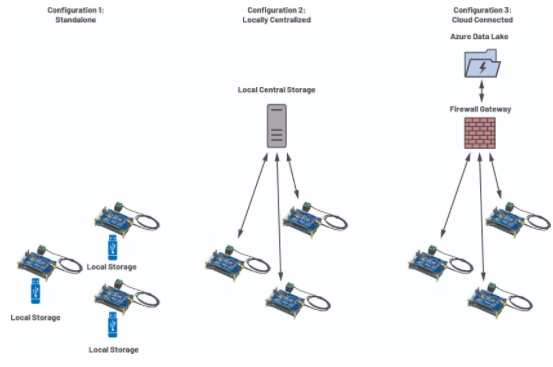
图 15. CbM 网络拓扑。
CN0549 是具有多种连接选项的独立系统。由于它运行标准 Linux,以太网和 Wi-Fi 等传统网络堆栈开箱即用,如果需要,甚至可以连接蜂窝调制解调器。在实际应用中,有几个典型的拓扑比较突出,如图 15 所示。
图 15 中显示的最左侧配置是离线收集案例,它可能发生在远程站点或无法连接到 Internet 的地方。在这种情况下,大型存储介质将与平台共存,并按计划手动收集。或者,其他两个选项将数据流式传输到公共端点。图 15 的中间配置是一个孤立的网络,它可能仅位于组织内部,也可能只是位于远程位置的一组平台,用于集中收集数据。这可能是出于安全考虑或只是缺乏连接性而需要的。CN0549 的设置对于任何这些配置都很容易,并且可以针对最终部署的特定需求进行定制。
最终配置是直接云选项,每个平台直接访问互联网并将测量推送到云端。由于 CN0549 在 Linux 上运行,因此该平台可以通过 Python 等语言轻松利用 Microsoft Azure IoT 或 Amazon IoT Greengrass 等不同云供应商的 API,从而为开始为新连接的设备构建数据湖创造了一条简单的途径。
当云和本地进程之间存在一致的连接时,可以将不同的算法拆分为我们已经讨论过的需要或可以在本地运行的内容以及可以在云中运行的内容。这将在算法复杂性的处理能力要求、事件延迟以及可以发送到云的带宽限制之间进行自然权衡。但是,由于它非常灵活,因此可以轻松探索这些因素。
结论
CN0549 CbM 平台在开发应用程序时为设计人员提供系统灵活性和大量软件资源。围绕如何利用不同的组件进行 CbM 和预测性维护 (PdM) 开发进行了对软件堆栈的深入探讨。由于软件、HDL、原理图的开放性以及与数据科学工具的集成,设计人员可以在整个堆栈中利用其终端系统所需的组件。总而言之,这种状态监测设计提供了一种易于使用的开箱即用解决方案,并配有开源软件和硬件,以提供灵活性并允许设计人员在更短的时间内实现更好的定制结果。
审核编辑:郭婷
-
互联网
+关注
关注
54文章
11113浏览量
103022 -
调制解调器
+关注
关注
3文章
850浏览量
38783 -
Linux
+关注
关注
87文章
11232浏览量
208939
发布评论请先 登录
相关推荐
AWTK-WEB 快速入门(1) - C 语言应用程序

使用Redis和Spring Ai构建rag应用程序

HarmonyOS开发实例:【状态管理】
【从0开始创建AWTK应用程序】编译应用到RTOS平台
什么是云平台?软件被云平台拦截了怎么办
在ModuStoolBox环境之外开发应用程序时应该考虑哪些因素?
Harmony 鸿蒙应用级变量的状态管理

10kV配电所柜内运行状态及环境指标监测管理平台分析
如何构建linux开发环境和编译软件工程、应用程序
【从0开始创建AWTK应用程序】编译应用到嵌入式Linux平台运行
LabVIEW发开发电状态监测系统
LabVIEW开发工业设备远程在线状态监测

【从0开始创建AWTK应用程序】创建应用程序并在模拟器运行





 工商网监
工商网监
评论