 一种新方法GSConv来减轻模型的复杂度并保持准确性
一种新方法GSConv来减轻模型的复杂度并保持准确性
目标检测是计算机视觉中一项艰巨的下游任务。对于车载边缘计算平台,大模型很难达到实时检测的要求。而且,由大量深度可分离卷积层构建的轻量级模型无法达到足够的准确性。因此本文引入了一种新方法 GSConv 来减轻模型的复杂度并保持准确性。GSConv 可以更好地平衡模型的准确性和速度。并且,提供了一种设计范式,Slim-Neck,以实现检测器更高的计算成本效益。在实验中,与原始网络相比,本文方法获得了最先进的结果(例如,SODA10M 在 Tesla T4 上以 ~100FPS 的速度获得了 70.9% mAP0.5)。
1简介
目标检测是无人驾驶汽车所需的基本感知能力。目前,基于深度学习的目标检测算法在该领域占据主导地位。这些算法在检测阶段有两种类型:单阶阶段和两阶段。两阶段检测器在检测小物体方面表现更好,通过稀疏检测的原理可以获得更高的平均精度(mAP),但这些检测器都是以速度为代价的。单阶段检测器在小物体的检测和定位方面不如两阶段检测器有效,但在工作上比后者更快,这对工业来说非常重要。
类脑研究的直观理解是,神经元越多的模型获得的非线性表达能力越强。但不可忽视的是,生物大脑处理信息的强大能力和低能耗远远超出了计算机。无法通过简单地无休止地增加模型参数的数量来构建强大的模型。轻量级设计可以有效缓解现阶段的高计算成本。这个目的主要是通过使用 Depth-wise Separable Convolution (DSC)操作来减少参数和FLOPs的数量来实现的,效果很明显。
但是,DSC 的缺点也很明显:输入图像的通道信息在计算过程中是分离的。
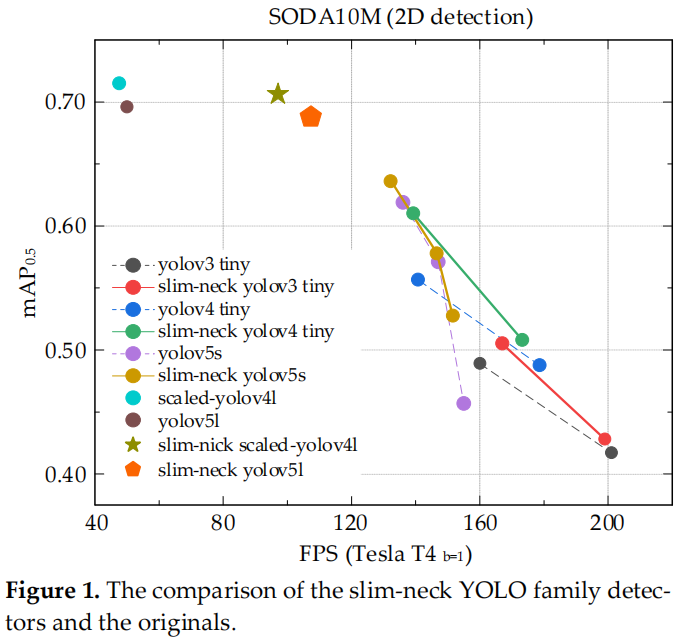
图 1
对于自动驾驶汽车,速度与准确性同样重要。通过 GSConv 引入了 Slim-Neck 方法,以减轻模型的复杂度同时可以保持精度。GSConv 更好地平衡了模型的准确性和速度。在图 1 中,在 SODA10M 的无人驾驶数据集上比较了最先进的 Slim-Neck 检测器和原始检测器的速度和准确度。结果证实了该方法的有效性。
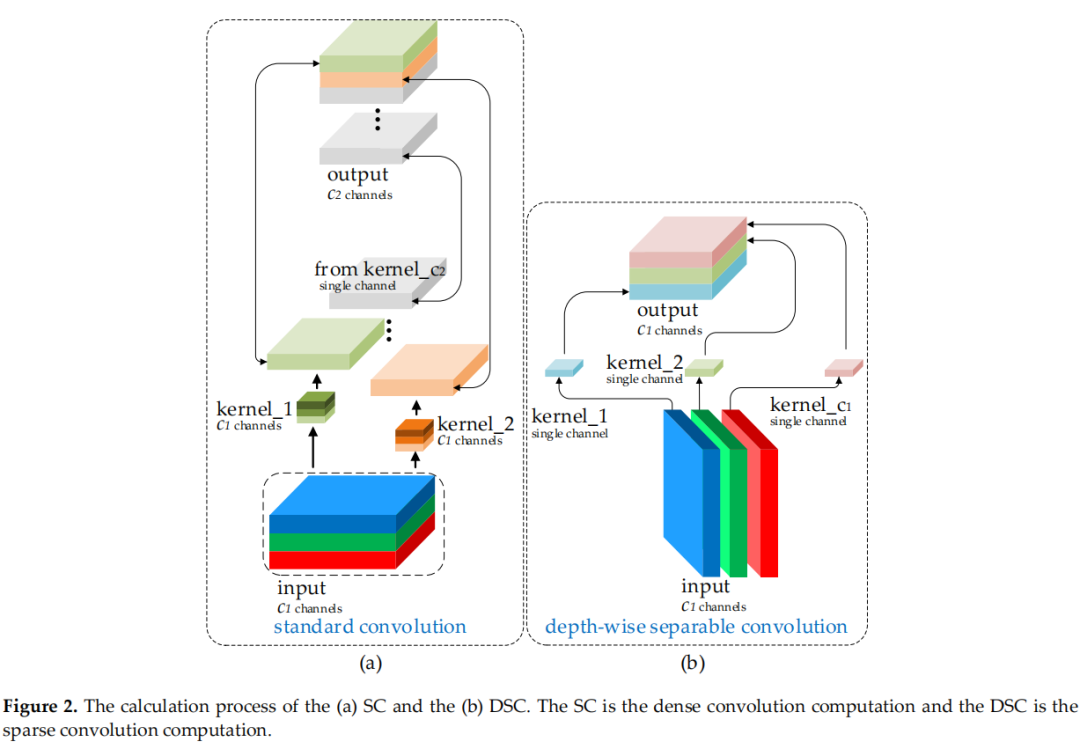
图2
图2(a)和(b)显示了 DSC 和标准卷积(SC)的计算过程。这种缺陷导致 DSC 的特征提取和融合能力比 SC 低得多。优秀的轻量级作品,如 Xception、MobileNets 和 ShuffleNets,通过 DSC 操作大大提高了检测器的速度。但是当这些模型应用于自动驾驶汽车时,这些模型的较低准确性令人担忧。事实上,这些工作提出了一些方法来缓解 DSC 的这个固有缺陷(这也是一个特性):MobileNets 使用大量的 1×1 密集卷积来融合独立计算的通道信息;ShuffleNets 使用channel shuffle来实现通道信息的交互,而 GhostNet 使用 halved SC 操作来保留通道之间的交互信息。但是,1×1的密集卷积反而占用了更多的计算资源,使用channel shuffle效果仍然没有触及 SC 的结果,而 GhostNet 或多或少又回到了 SC 的路上,影响可能会来从很多方面。
许多轻量级模型使用类似的思维来设计基本架构:从深度神经网络的开始到结束只使用 DSC。但 DSC 的缺陷直接在主干中放大,无论是用于图像分类还是检测。作者相信 SC 和 DSC 可以结合在一起使用。仅通过channel shuffle DSC 的输出通道生成的特征图仍然是“深度分离的”。
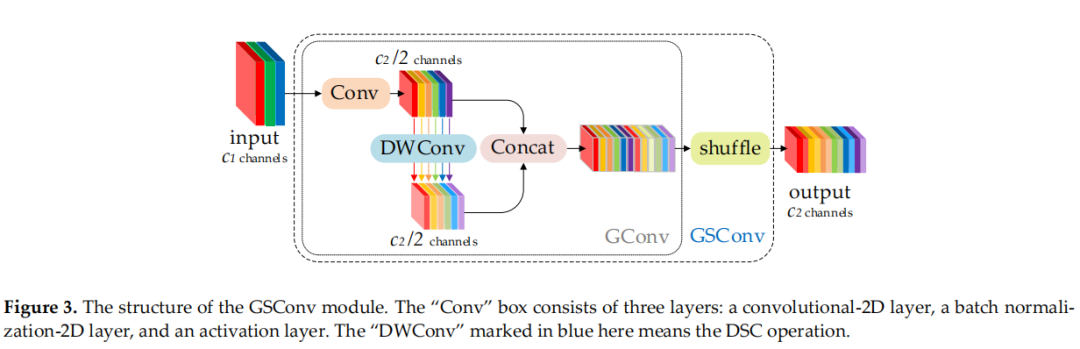
图 3
为了使 DSC 的输出尽可能接近 SC,引入了一种新方法——GSConv。如图 3 所示,使用 shuffle 将 SC 生成的信息(密集卷积操作)渗透到 DSC 生成的信息的每个部分。这种方法允许来自 SC 的信息完全混合到 DSC 的输出中,没有花里胡哨的东西。

图 4
图 4 显示了 SC、DSC 和 GSConv 的可视化结果。GSConv 的特征图与 SC 的相似性明显高于 DSC 与 SC 的相似。当在 Backbone 使用 SC,在Neck使用 GSConv(slim-neck)时,模型的准确率非常接近原始;如果添加一些技巧,模型的准确性和速度就会超过原始模型。采用 GSConv 方法的Slim-Neck可最大限度地减少 DSC 缺陷对模型的负面影响,并有效利用 DSC 的优势。
主要贡献可以总结如下:
引入了一种新方法 GSConv 来代替 SC 操作。该方法使卷积计算的输出尽可能接近 SC,同时降低计算成本;
为自动驾驶汽车的检测器架构提供了一种新的设计范式,即带有标准 Backbone 的 Slim-Neck 设计;
验证了不同 Trick 的有效性,可以作为该领域研究的参考。
2本文方法
2.1 为什么要在Neck中使用GSConv
为了加速预测的计算,CNN 中的馈送图像几乎必须在 Backbone 中经历类似的转换过程:空间信息逐步向通道传输。并且每次特征图的空间(宽度和高度)压缩和通道扩展都会导致语义信息的部分丢失。密集卷积计算最大限度地保留了每个通道之间的隐藏连接,而稀疏卷积则完全切断了这些连接。
GSConv 尽可能地保留这些连接。但是如果在模型的所有阶段都使用它,模型的网络层会更深,深层会加剧对数据流的阻力,显著增加推理时间。当这些特征图走到 Neck 时,它们已经变得细长(通道维度达到最大,宽高维度达到最小),不再需要进行变换。因此,更好的选择是仅在 Neck 使用 GSConv(Slim-Neck + 标准Backbone)。在这个阶段,使用 GSConv 处理 concatenated feature maps 刚刚好:冗余重复信息少,不需要压缩,注意力模块效果更好,例如 SPP 和 CA。
2.2 Slim-Neck
作者研究了增强 CNN 学习能力的通用方法,例如 DensNet、VoVNet 和 CSPNet,然后根据这些方法的理论设计了 Slim-Neck 结构。
1、Slim-Neck中的模块
首先,使用轻量级卷积方法 GSConv 来代替 SC。其计算成本约为 SC 的60%~70%,但其对模型学习能力的贡献与后者不相上下。然后,在 GSConv 的基础上继续引入 GSbottleneck,图5(a)展示了 GSbottleneck 模块的结构。
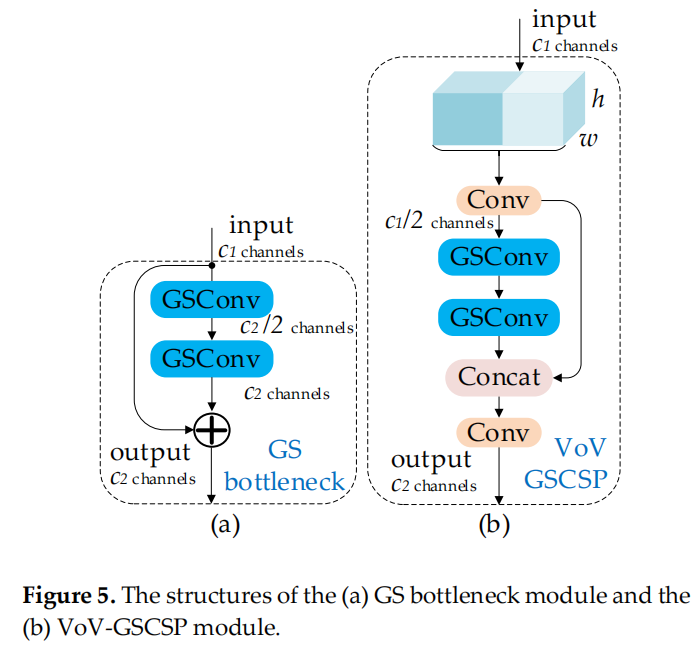
图5
同样,使用一次性聚合方法来设计跨级部分网络 (GSCSP) 模块 VoV-GSCSP。VoV-GSCSP 模块降低了计算和网络结构的复杂性,但保持了足够的精度。图 5 (b) 显示了 VoV-GSCSP 的结构。值得注意的是,如果我们使用 VoV-GSCSP 代替 Neck 的 CSP,其中 CSP 层由标准卷积组成,FLOPs 将平均比后者减少 15.72%。
最后,需要灵活地使用3个模块,GSConv、GSbottleneck 和 VoV-GSCSP。
2、Slim-Neck针对YOLO系列的设计
YOLO 系列检测器由于检测效率高,在行业中应用更为广泛。这里使用 slim-neck 的模块来改造 Scaled-YOLOv4 和 YOLOv5 的 Neck 层。图 6 和图 7 显示了2种 slim-neck 架构。
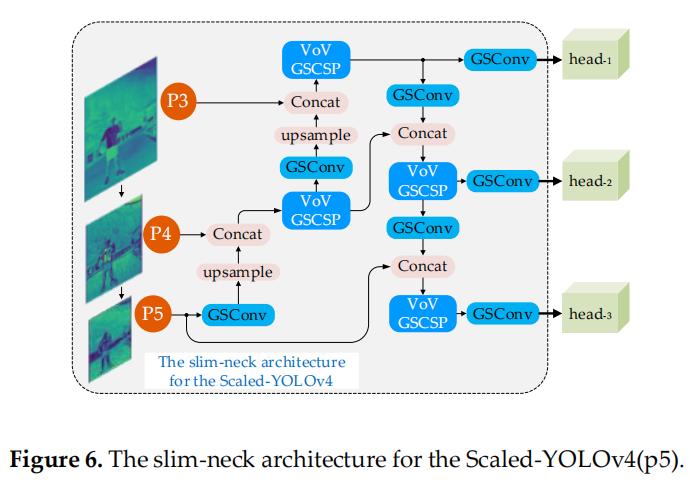
图 6
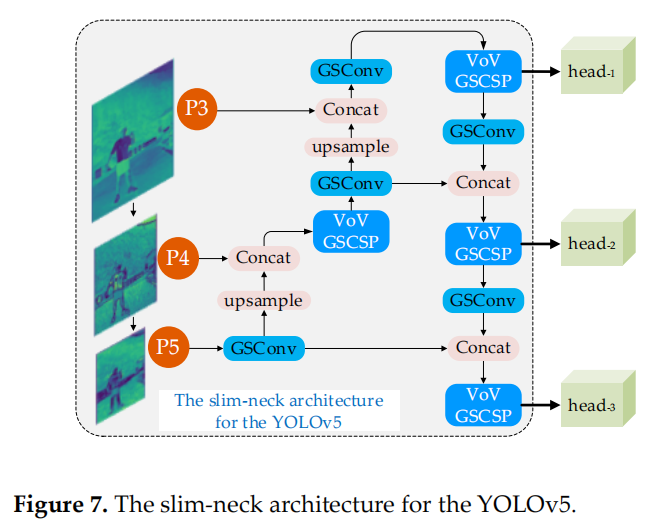
图 7
3、免费的改进Tricks
可以在基于 CNNs 的检测器中使用一些局部特征增强方法,结构简单,计算成本低。这些增强方法,注意力机制,可以显著提高模型精度,而且比Neck 简单得多。这些方法包括作用于通道信息或空间信息。SPP 专注于空间信息,它由4个并行分支连接:3个最大池操作(kernel-size为 5×5、9×9 和 13×13)和输入的 shortcut 方式。它用于通过合并输入的局部和全局特征来解决对象尺度变化过大的问题。YOLOv5 作者的 SPP 改进模块 SPPF 提高了计算效率。该效率 增加了近 277.8%。通式为:
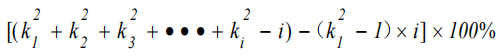
其中,是 SPPF 模块中第i个分支的最大池化的kernel-size。
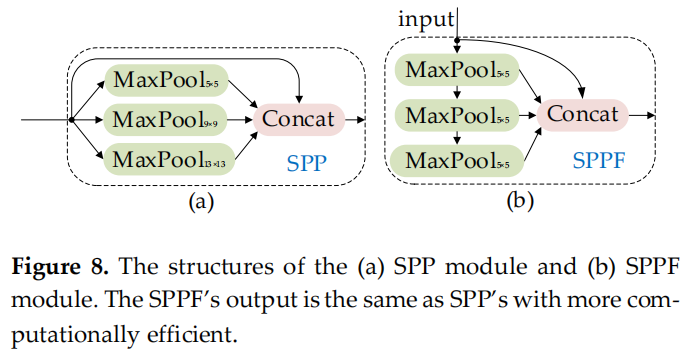
图 8
图 8 (a) 和 (b) 显示了 SPP 和 SPPF 的结构。SE是一个通道注意力模块,包括两个操作过程:squeeze和excitation。该模块允许网络更多地关注信息量更大的特征通道,而否定信息量较少的特征通道。CBAM 是一个空间通道注意力机制模块。CA 模块是一种新的解决方案,可以避免全局池化操作导致的位置信息丢失:将注意力分别放在宽度和高度两个维度上,以有效利用输入特征图的空间坐标信息。图9(a)、(b)和(c) 显示了 SE、CBAM 和 CA 模块的结构。
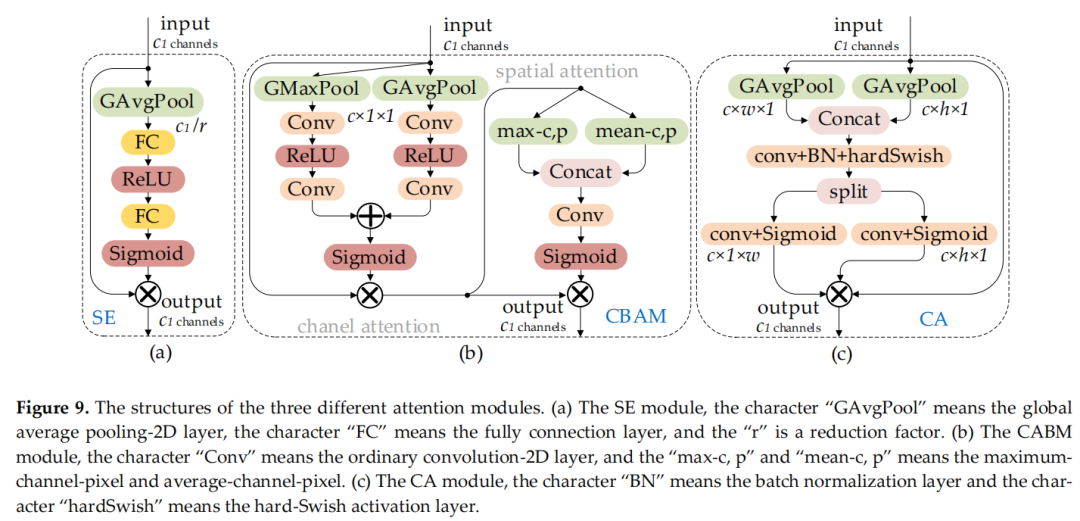
图 9
4、损失和激活函数
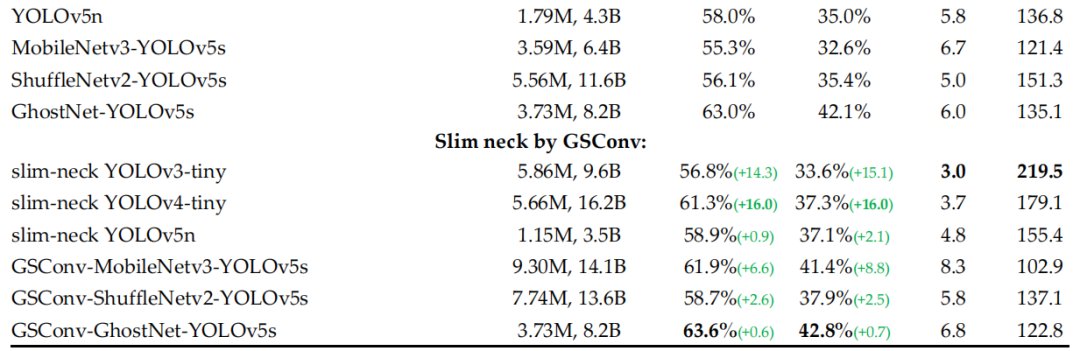
IoU 损失对于基于深度学习的检测器具有很大的价值。它使预测边界框回归的位置更加准确。随着研究的不断发展,许多研究人员已经提出了更高级的 IoU 损失函数,例如 GIoU、DIoU、CIoU 和最新的 EIoU。5个损失函数定义如下:
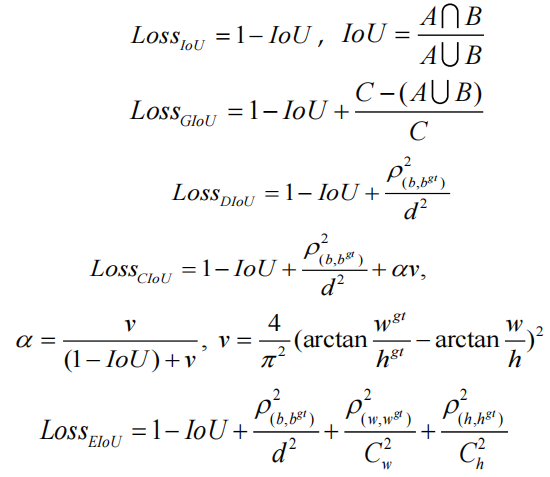
其中参数“A”和“B”表示Ground truth边界框的面积和预测边界框的面积;参数“C”表示Ground truth边界框和预测边界框的最小包围框的面积;参数“d”表示封闭框的对角线顶点的欧式距离;参数“ρ”表示Ground truth边界框和预测边界框质心的欧式距离;参数“α”是权衡的指标,参数“v”是评价Ground truth边界框和预测边界框长宽比一致性的指标。
CIoU loss是目前Anchor-based检测器中使用最广泛的损失函数,但CIoU loss仍然存在缺陷:
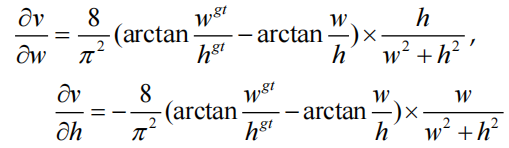
其中“δv /δw”是“v”相对于“w”的梯度,“δv/δh”是“v”相对于“h”的梯度。
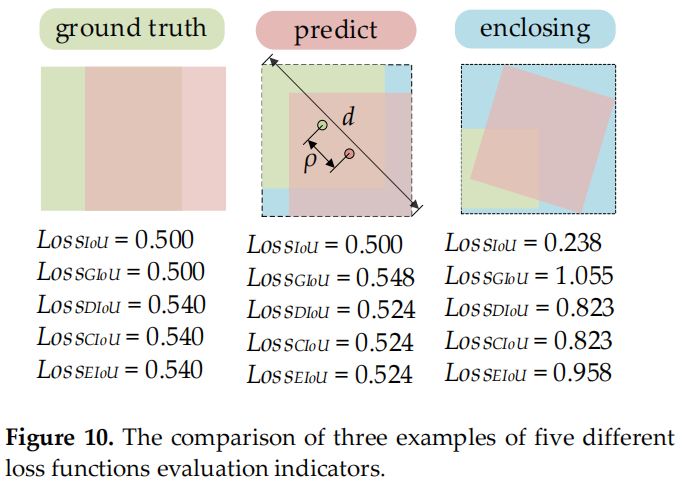
图 10
根据 CIoU 损失的定义,如果,CIoU 损失将退化为DIoU损失,即CIoU损失中添加的惩罚项的相对比例(αv)将不起作用。此外,w和h的梯度符号相反。
因此,这两个变量(w或h)只能在同一方向上更新,同时增加或减少。这不符合实际应用场景,尤其是当 且 $hw^{gt}h>h^{gt}$ 时。EIoU loss没有遇到这样的问题,它直接使用预测边界框的w和h独立作为惩罚项,而不是w和h的比值。图10是这些损失函数的不同评估指标的3个示例。
在深度网络上,使用 Swish 和 Mish 的模型的准确性和训练稳定性通常比 ReLU 差。Swish 和 Mish 都具有无上界和下界、平滑和非单调的特性。它们定义如下:
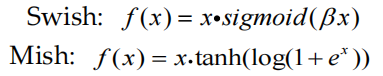
在更深的网络上,Mish 的模型准确度略好于 Swish,尽管实际上2条激活函数曲线非常接近。与 Swish 相比,Mish 由于计算成本的增加而消耗更多的训练时间。
3实验
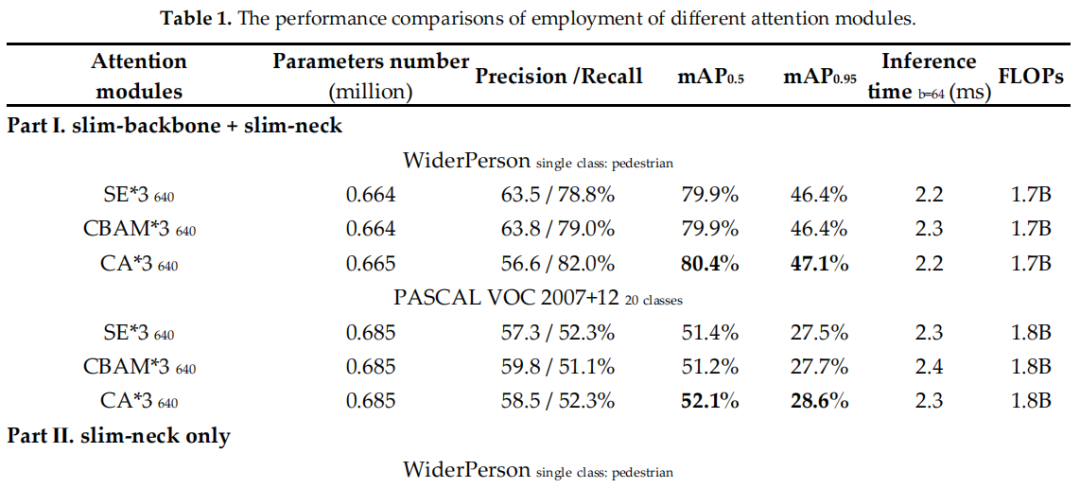
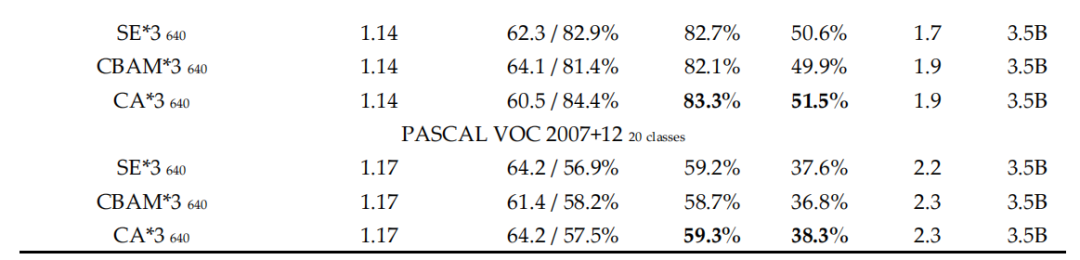
3.1 Trick消融实验
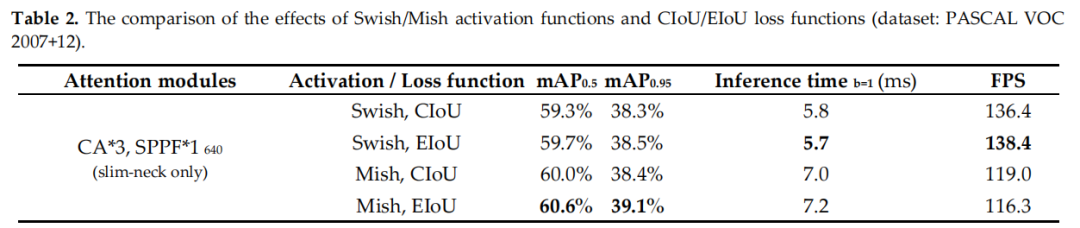
3.2 损失函数对比
3.3 Yolo改进


3.4 可视化结果对比

4参考
[1].Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles
审核编辑 :李倩
-
目标检测
+关注
关注
0文章
204浏览量
15589 -
无人驾驶汽车
+关注
关注
17文章
150浏览量
37332 -
深度学习
+关注
关注
73文章
5491浏览量
120958
原文标题:改进Yolov5 | 用 GSConv+Slim Neck 一步步把 Yolov5 提升到极致!!!
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何提升ASR模型的准确性
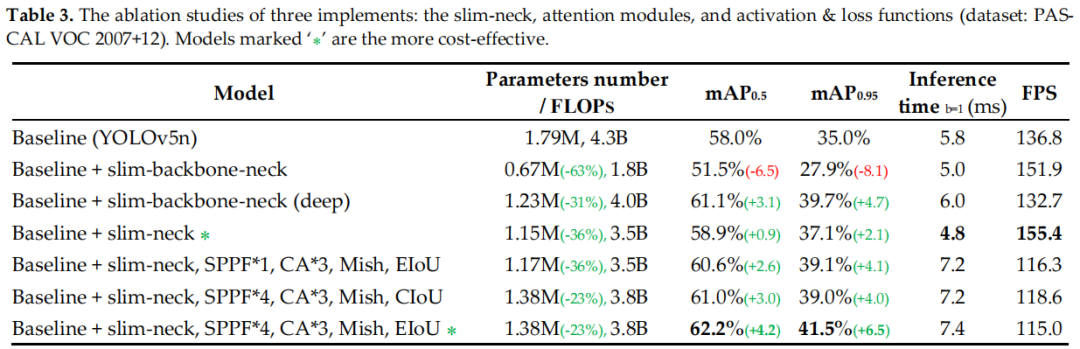
一种创新的动态轨迹预测方法
如何评估 ChatGPT 输出内容的准确性
如何保证测长机测量的准确性?

业务复杂度治理方法论--十年系统设计经验总结
一种无透镜成像的新方法

一种利用光电容积描记(PPG)信号和深度学习模型对高血压分类的新方法
【大语言模型:原理与工程实践】大语言模型的评测
怎样测试电流探头的准确性以及保证其精准性

一种产生激光脉冲新方法

降低Transformer复杂度O(N^2)的方法汇总






 工商网监
工商网监
评论