 计算机视觉的网络结构又要迎来革新了?
计算机视觉的网络结构又要迎来革新了?
【导读】最近,中科院软件所等四个机构的研究团队将CV与图神经网络结合起来,提出全新模型ViG,在等量参数情况下,性能超越ViT,可解释性也有所提升。
从卷积神经网络到带注意力机制的视觉Transformer,神经网络模型都是把输入图像视为一个网格或是patch序列,但这种方式无法捕捉到变化的或是复杂的物体。
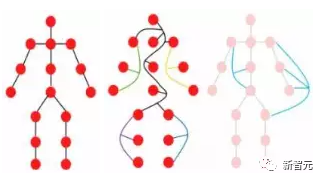
比如人在观察图片的时候,就会很自然地就将整个图片分为多个物体,并在物体间建立空间等位置关系,也就是说整张图片对于人脑来说实际上是一张graph,物体则是graph上的节点。
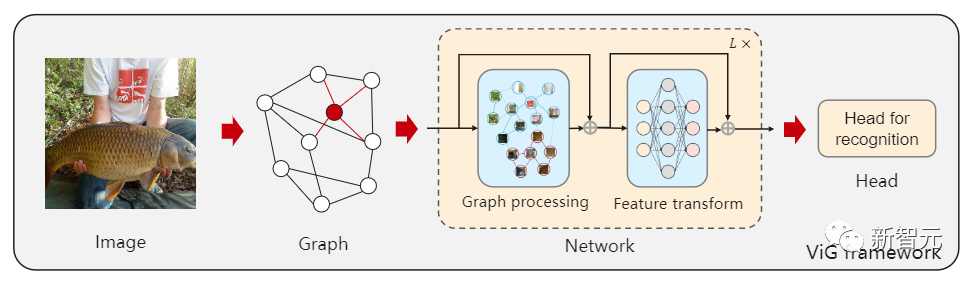
最近中科院软件研究所、华为诺亚方舟实验室、北京大学、澳门大学的研究人员联合提出了一个全新的模型架构Vision GNN (ViG),能够从图像中抽取graph-level的特征用于视觉任务。

论文链接:https://arxiv.org/pdf/2206.00272.pdf
首先需要将图像分割成若干个patch作为图中的节点,并通过连接最近的邻居patch构建一个graph,然后使用ViG模型对整个图中所有节点的信息进行变换(transform)和交换(exchange)。
ViG 由两个基本模块组成,Grapher模块用graph卷积来聚合和更新图形信息,FFN模块用两个线性层来变换节点特征。
在图像识别和物体检测任务上进行的实验也证明了ViG架构的优越性,GNN在一般视觉任务上的开创性研究将为未来的研究提供有益的启发和经验。
论文作者为吴恩华教授,中国科学院软件研究所博士生导师、澳门大学名誉教授,1970年本科毕业于清华大学工程力学数学系,1980年博士毕业于英国曼彻斯特大学计算机科学系。主要研究领域为计算机图形学与虚拟现实, 包括:虚拟现实 、真实感图形生成、基于物理的仿真与实时计算、基于物理的建模与绘制、图像与视频的处理与建模、视觉计算与机器学习。
视觉GNN
网络结构往往是提升性能最关键的要素,只要能保证数据量的数量和质量,把模型从CNN换到ViT,就能得到一个性能更佳的模型。
但不同的网络对待输入图像的处理方式也不同,CNN在图像上滑动窗口,引入平移不变性和局部特征。
而ViT和多层感知机(MLP)则是将图像转换为一个patch序列,比如把224×224的图像分成若干个16×16的patch,最后形成一个长度为196的输入序列。
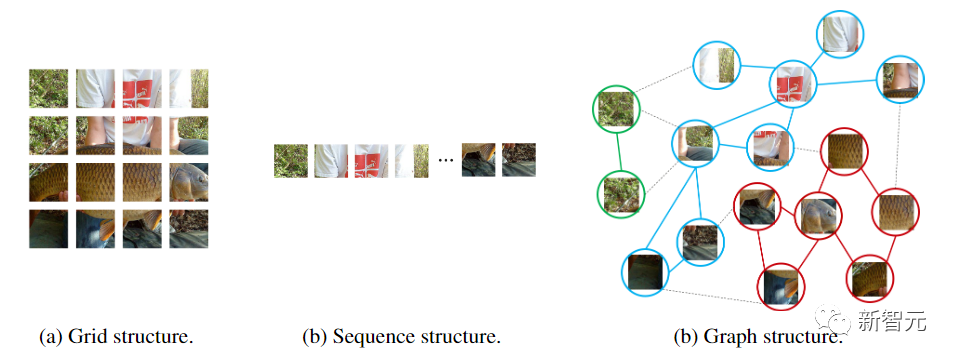
图神经网络则更加灵活,比如在计算机视觉中,一个基本任务是识别图像中的物体。由于物体通常不是四边形的,可能是不规则的形状,所以之前的网络如ResNet和ViT中常用的网格或序列结构是多余的,处理起来不灵活。
一个物体可以被看作是由多个部分组成的,例如,一个人可以大致分为头部、上半身、胳膊和腿。
这些由关节连接的部分很自然地形成了一个图形结构,通过分析图,我们最后才能够识别出这个物体可能是个人类。
此外,图是一种通用的数据结构,网格和序列可以被看作是图的一个特例。将图像看作是一个图,对于视觉感知来说更加灵活和有效。
使用图结构需要将输入的图像划分为若干个patch,并将每个patch视为一个节点,如果将每个像素视为一个节点的话就会导致图中节点数量过多(>10K)。
建立graph后,首先通过一个图卷积神经网络(GCN)聚合相邻节点间的特征,并抽取图像的表征。
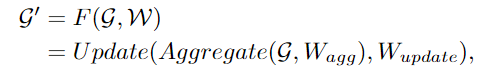
为了让GCN获取更多样性的特征,作者将图卷积应用multi-head操作,聚合的特征由不同权重的head进行更新,最后级联为图像表征。
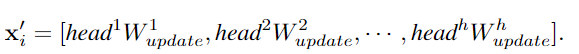
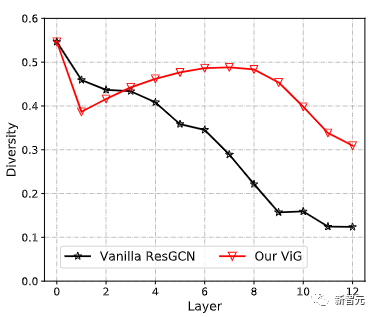
以前的GCN通常重复使用几个图卷积层来提取图数据的聚合特征,而深度GCN中的过度平滑现象则会降低节点特征的独特性,导致视觉识别的性能下降。
为了缓解这个问题,研究人员在ViG块中引入了更多的特征转换和非线性激活函数。
首先在图卷积的前后应用一个线性层,将节点特征投射到同一域中,增加特征多样性。在图形卷积之后插入一个非线性激活函数以避免层崩溃。
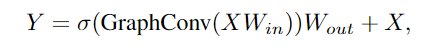
为了进一步提高特征转换能力,缓解过度平滑现象,还需要在每个节点上利用前馈网络(FFN)。FFN模块是一个简单的多层感知机,有两个全连接的层。
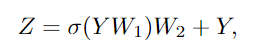
在Grapher和FFN模块中,每一个全连接层或图卷积层之后都要进行batch normalization,Grapher模块和FFN模块的堆叠构成了一个ViG块,也是构建大网络的基本单元。
与原始的ResGCN相比,新提出的ViG可以保持特征的多样性,随着加入更多的层,网络也可以学习到更强的表征。
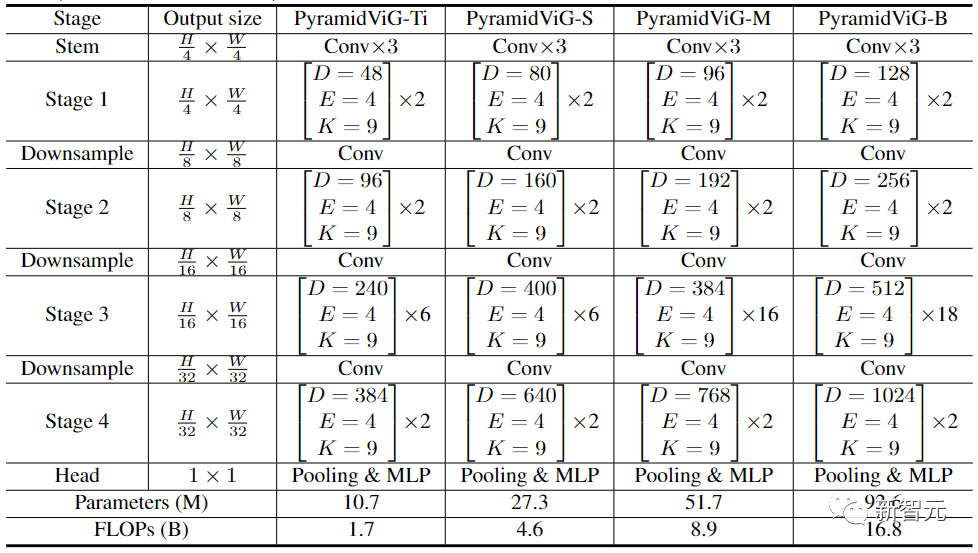
在计算机视觉的网络架构中,常用的Transformer模型通常有一个等向性(Isotropic)的结构(如ViT),而CNN更倾向于使用金字塔结构(如ResNet)。
为了与其他类型的神经网络进行比较,研究人员为ViG同时建立了等向性和金字塔的两种网络架构。
在实验对比阶段,研究人员选择了图像分类任务中的ImageNet ILSVRC 2012数据集,包含1000个类别,120M的训练图像和50K的验证图像。
目标检测任务中,选择了有80个目标类别的COCO 2017数据集,包含118k个训练图片和5000个验证集图片。

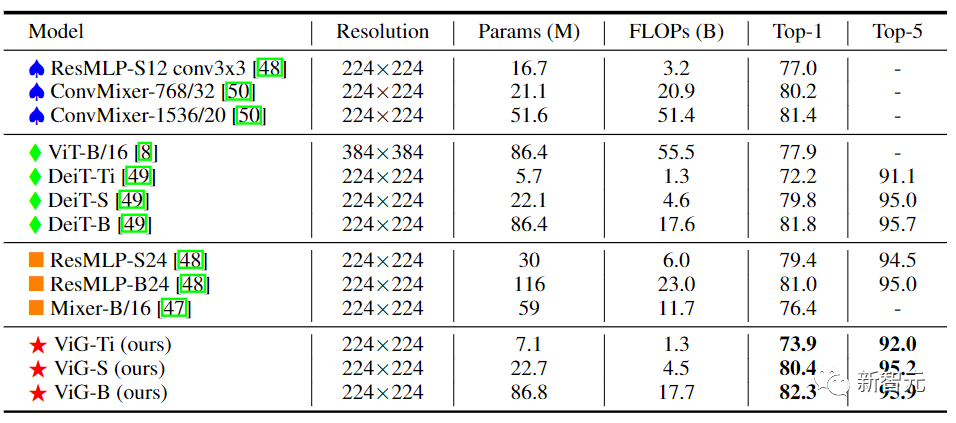
在等向性的ViG架构中,其主要计算过程中可以保持特征大小不变,易于扩展,对硬件加速友好。在将其与现有的等向性的CNN、Transformer和MLP进行比较后可以看到,ViG比其他类型的网络表现得更好。其中ViG-Ti实现了73.9%的top-1准确率,比DeiT-Ti模型高1.7%,而计算成本相似。
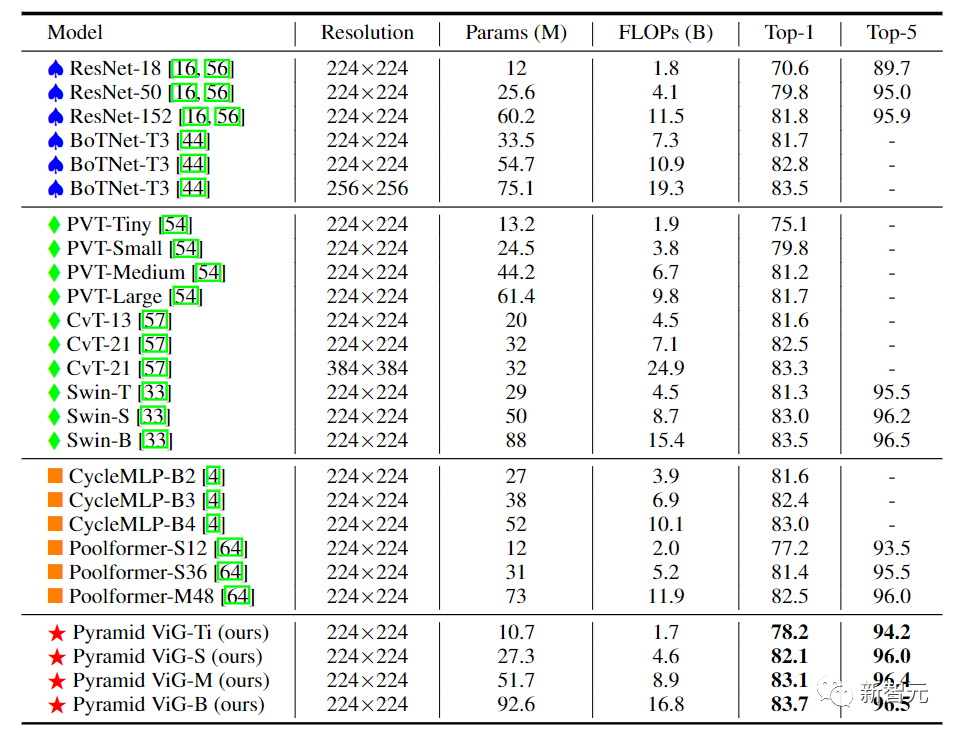
金字塔结构的ViG中,随着网络的加深逐渐缩小了特征图的空间大小,利用图像的尺度不变量特性,同时产生多尺度的特征。
高性能的网络大多采用金字塔结构,如ResNet、Swin Transformer和CycleMLP。在将Pyramid ViG与这些有代表性的金字塔网络进行比较后,可以看到Pyramid ViG系列可以超越或媲美最先进的金字塔网络包括CNN、MLP和Transfomer。
结果表明,图神经网络可以很好地完成视觉任务,并有可能成为计算机视觉系统中的一个基本组成部分。
为了更好地理解ViG模型的工作流程,研究人员将ViG-S中构建的图结构可视化。在两个不同深度的样本(第1和第12块)的图。五角星是中心节点,具有相同颜色的节点是其邻居。只有两个中心节点是可视化的,因为如果绘制所有的边会显得很乱。

可以观察到,ViG模型可以选择与内容相关的节点作为第一阶邻居。在浅层,邻居节点往往是根据低层次和局部特征来选择的,如颜色和纹理。在深层,中心节点的邻居更具语义性,属于同一类别。 ViG网络可以通过其内容和语义表征逐渐将节点联系起来,帮助更好地识别物体。
审核编辑 :李倩
-
神经网络
+关注
关注
42文章
4769浏览量
100687 -
模型
+关注
关注
1文章
3218浏览量
48801 -
计算机视觉
+关注
关注
8文章
1698浏览量
45965
原文标题:CV的未来是图神经网络?中科院软件所发布全新CV模型ViG,性能超越ViT
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
计算机视觉有哪些优缺点
计算机视觉技术的AI算法模型
计算机视觉的五大技术
计算机视觉的工作原理和应用
计算机视觉与人工智能的关系是什么
计算机视觉与智能感知是干嘛的
深度学习在计算机视觉领域的应用
机器视觉与计算机视觉的区别
计算机视觉的主要研究方向
计算机视觉的十大算法






 工商网监
工商网监
评论