 改进VPI和PyTorch之间的互操作性
改进VPI和PyTorch之间的互操作性
NVIDIA Vision Programming Interface ( VPI )是 NVIDIA 的一个计算机视觉和图像处理软件库,使您能够在 NVIDIA Jetson 嵌入式设备和离散 GPU 上提供的不同硬件后端上实现加速算法。
库中的一些算法包括滤波方法、透视扭曲、时间降噪、直方图均衡化、立体视差和镜头畸变校正。 VPI 提供了易于使用的 Python 绑定,以及一个 C ++ API 。
除了 与 OpenCV 接口 , VPI 还能够与 PyTorch 和其他基于 Python 的库进行互操作。在本文中,我们将通过一个基于 PyTorch 的对象检测和跟踪示例向您展示这种互操作性是如何工作的。有关更多信息,请参阅 视觉编程接口( VPI ) 页和 Vision 编程接口 文档。
与 PyTorch 和其他库的互操作性
根据您在计算机视觉和深度学习管道中实现的应用程序,您可能必须使用多个库。开发此类管道的挑战之一是这些库之间交互的效率。例如,当在内存拷贝之间交换图像数据时,可能会由于内存拷贝而出现性能问题。
使用 VPI ,您现在可以与 PyTorch 或任何其他支持__cuda_array_interace__的库进行互操作。__cuda_array_interface__( CUDA Array Interface )是 Python 中的一个属性,它支持各种项目(如库)中类似 GPU Array 对象的不同实现之间的互操作性。
阵列对象(如图像)可以在一个库中创建,在另一个库中修改,而无需复制 GPU 中的数据或将其传递给 CPU 。
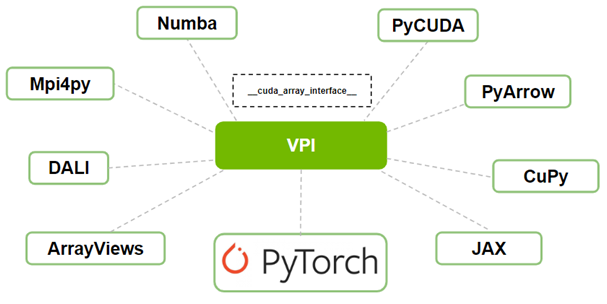
图 1 VPI 和其他库之间的互操作性使用 __cuda_array_interface__
时间噪声抑制以改进目标检测和跟踪
噪声是视频中跨帧的常见特征。这种时间噪声会对视频中目标检测和跟踪算法的性能产生负面影响。
VPI 库提供了一种时间降噪( TNR )算法,这是计算机视觉应用中用于降低视频数据中噪声的常用方法。
在本演练中,您将在嘈杂的视频上使用基于 PyTorch 的对象检测和跟踪示例。然后应用 VPI 中的 TNR 算法来减少噪声,从而改进目标检测和跟踪。
我们表明,在执行 VPI 和 PyTorch 算法的过程中, VPI 和 PyTorch 都可以无缝工作,没有任何内存拷贝。
该示例包括以下内容:
PyTorch 基于原始输入视频的目标检测与跟踪
PyTorch 基于 VPI TNR 的干净输入视频目标检测与跟踪
使用 CUDA 阵列接口实现 VPI 和 PyTorch 之间的互操作性
PyTorch 基于原始输入视频的目标检测与跟踪
首先,首先定义一个基于 PyTorch 的应用程序来检测图像中的对象。此示例应用程序基于 具有 MobileNetV3 主干的 SSDLite ,用于使用 PyTorch 和 Torchvision 进行目标检测 Example.
创建一个名为PyTorchDetection的类来处理所有 PyTorch 对象和调用。创建此类对象时,应用程序正在将用于对象检测的预训练深度学习模型加载到 GPU ,仅用于推理。以下代码示例显示了所需的导入和类构造函数定义:
import torch
import torchvision class PyTorchDetection: def __init__(self): assert torch.cuda.is_available() self.cuda_device = torch.device('cuda') self.convert = torchvision.transforms.Compose([ torchvision.transforms.ConvertImageDtype(torch.float32), torchvision.transforms.Lambda(lambda x: x.permute(2, 0, 1)), torchvision.transforms.Lambda(lambda x: x.unsqueeze(0)), ]) model = torchvision.models.detection.ssdlite320_mobilenet_v3_large(
pretrained=True) self.torch_model = model.eval().to(self.cuda_device)
PyTorchDetection类还负责从阵列创建 CUDA 图像帧,有效地将其上载到 GPU 。稍后,您将使用 OpenCV 从文件中读取输入视频,其中每个视频帧都是一个 NumPy 数组,用作该类创建函数的输入。
此外,PyTorchDetection类可以将 CUDA 图像帧转换为 CUDA 张量对象,为模型推断做好准备,并将基于 VPI 的 CUDA 帧转换为张量。最后一次转换使用 VPI 的__cuda_array_interface__互操作性来避免复制帧。
def CreateCUDAFrame(self, np_frame): return torch.from_numpy(np_frame).to(self.cuda_device) def ConvertToTensor(self, cuda_frame): return self.convert(cuda_frame) def ConvertFromVPIFrame(self, vpi_cuda_frame): return torch.as_tensor(vpi_cuda_frame, device=self.cuda_device)
除了前面定义的函数外,PyTorchDetection类还定义了一个函数,在给定scores_threshold值的情况下,可以在当前 OpenCV 帧中检测和绘制对象:
def DetectAndDraw(self, cv_frame, torch_tensor, title, scores_threshold=0.2): with torch.no_grad(): pred = self.torch_model(torch_tensor) (...)
在这篇文章中,我们省略了代码,以提请大家注意 PyTorch 模型的预测结果。此处下载或使用本规范即表示您接受本规范的条款和条件。 您可以下载并查看代码 。
下一节介绍如何使用 VPI 降低输入视频中的噪声,将 VPI 与 PyTorch 耦合以改进其目标检测。
PyTorch 基于 VPI TNR 的干净输入视频目标检测与跟踪
在本节中,定义一个基于 VPI 的实用程序类VPITemporalNoiseReduction,以清除视频帧中的噪声。
创建此类对象时,应用程序加载主 VPI TNR 对象和基于 VPI 的 CUDA 帧以存储清理后的输出。以下代码示例显示了所需的导入和类构造函数定义:
import vpi class VPITemporalNoiseReduction: def __init__(self, shape, image_format): if (image_format == 'BGR8'): self.vpi_image_format = vpi.Format.BGR8 else: self.vpi_image_format = vpi.Format.INVALID self.vpi_output_frame = vpi.Image(shape, format=self.vpi_image_format) self.tnr = vpi.TemporalNoiseReduction(shape, vpi.Format.NV12_ER, version=vpi.TNRVersion.V3, backend=vpi.Backend.CUDA)
类的构造函数需要每个输入图像帧的形状(图像宽度和高度)和格式。为简单起见,您只接受BGR8图像格式,因为这是OpenCV在读取输入视频时使用的格式。
此外,您正在创建 VPI 图像,以使用提供的形状和格式存储输出帧。然后使用 TNR code 版本 3 和 CUDA 后端为该形状构造 TNR 对象。 TNR 的输入格式为 NV12 \ u ER ,与输入图像帧中的格式不同。接下来将在Denoise实用程序函数中处理帧转换。
def Denoise(self, torch_cuda_frame, tnr_strength=1.0): vpi_input_frame = vpi.asimage(torch_cuda_frame, format=self.vpi_image_format) with vpi.Backend.CUDA: vpi_input_frame = vpi_input_frame.convert(vpi.Format.NV12_ER) vpi_input_frame = self.tnr(vpi_input_frame, preset=vpi.TNRPreset.OUTDOOR_LOW_LIGHT, strength=tnr_strength) vpi_input_frame.convert(out=self.vpi_output_frame) return self.vpi_output_frame
最后一个函数执行输入图像帧的实际清理。此函数用于从基于 PyTorch 的输入 CUDA 帧中移除噪声,返回基于 VPI 的输出 CUDA 帧。
首先使用 PyTorch 函数将 PyTorch vpi.asimage帧转换为 VPI 。torch_cuda_frame与vpi_input_frame共享相同的内存空间:即不涉及内存拷贝。
接下来,将输入帧从给定的输入格式( BGR8 )转换为 CUDA 中的 NV12 \ u ER 进行处理。
使用 TNR 预设OUTDOOR_LOW_LIGHT和给定的 TNR 强度,在转换后的输入帧上执行 TNR 算法。
清理后的输入帧( TNR 算法的输出)被转换回原始格式( BGR8 ),并存储在基于 VPI 的 CUDA 输出帧中。
生成的输出帧将返回,以供 PyTorch 稍后使用。
使用 CUDA 阵列接口实现 VPI 和 PyTorch 之间的互操作性
最后,在主模块中定义一个MainWindow类。此类基于 PySide2 ,并为本例提供了图形用户界面。
窗口界面显示两个输出图像帧,一个仅使用 PyTorch 进行检测,另一个在 VPI TNR 后使用 PyTorch 。此外,窗口界面包含两个滑块,用于控制用于 PyTorch 检测的分数阈值和用于去除 VPI 时间噪声的 TNR 强度。
import cv2
import numpy as np
(...)
from PySide2 import QtWidgets, QtGui, QtCore
(...)
from vpitnr import VPITemporalNoiseReduction
from torchdetection import PyTorchDetection class MainWindow(QMainWindow): def __init__(self, input_path): super().__init__() #-------- OpenCV part -------- self.video_capture = cv2.VideoCapture(input_path) if not self.video_capture.isOpened(): self.Quit() self.input_width = int(self.video_capture.get(cv2.CAP_PROP_FRAME_WIDTH)) self.input_height = int(self.video_capture.get(cv2.CAP_PROP_FRAME_HEIGHT)) self.output_video_shape = (self.input_height * 2, self.input_width, 3) self.output_frame_shape = (self.input_height, self.input_width, 3) self.cv_output_video = np.zeros(self.output_video_shape, dtype=np.uint8) #-------- Main objects of this example -------- self.torch_detection = PyTorchDetection() self.vpi_tnr = VPITemporalNoiseReduction((self.input_width, self.input_height), 'BGR8') (...) def UpdateDetection(self): in_frame = self.cv_input_frame if in_frame is None: return cuda_input_frame = self.torch_detection.CreateCUDAFrame(in_frame) # -------- Top Frame: No VPI --------- cuda_tensor = self.torch_detection.ConvertToTensor(cuda_input_frame) self.torch_detection.DetectAndDraw(self.TopFrame(), cuda_tensor, 'Pytorch only (no VPI)', self.scores_threshold) # -------- Bottom Frame: With VPI --------- vpi_output_frame = self.vpi_tnr.Denoise(cuda_input_frame, self.tnr_strength) with vpi_output_frame.rlock_cuda() as cuda_frame: cuda_output_frame=self.torch_detection.ConvertFromVPIFrame(cuda_frame) cuda_tensor = self.torch_detection.ConvertToTensor(cuda_output_frame) self.torch_detection.DetectAndDraw(self.BottomFrame(), cuda_tensor, 'Pytorch + VPI TNR', self.scores_threshold) (...)
类的构造函数需要输入视频的路径。它使用OpenCV读取输入视频,并创建一个高度为输入视频两倍的输出视频帧。这用于存储两个输出帧,一个仅用于PyTorch输出,另一个用于VPI+ PyTorch 输出。
构造函数还为 PyTorch 检测和 VPI TNR 创建对象。在本文中,我们省略了创建图形用户界面小部件和处理其回调的代码。我们还省略了创建主窗口和启动应用程序的代码。有关 TNR code 这一部分的更多信息,请下载示例。
当有新的输入视频帧可用时,调用UpdateDetection函数,从 NumPy OpenCV 输入帧创建基于 PyTorch 的 CUDA 输入帧。然后将其转换为张量,以检测并绘制PyTorchDetection类。顶部帧的管道直接在输入视频帧中运行 PyTorch 检测。
底部帧的下一条管道首先对基于 PyTorch CUDA 的输入帧进行去噪。去噪后的输出是一个名为vpi_output_frame的基于 VPI 的 CUDA 帧,使用rlock_cuda函数在 CUDA 中锁定读取。此函数为cuda_frame对象中的 VPI CUDA 互操作性提供__cuda_array_interface__。该对象将转换为 PyTorch CUDA 帧,然后转换为张量。再次,对管道的结果调用 detect and draw 函数。第二条管道在 VPI 去噪功能之后运行PyTorchDetection。
结果
图 3 显示了在公共场所行人噪声输入视频上,无 VPI TNR 和有 VPI TNR 的 PyTorch 目标检测和跟踪的结果。正如您可以从带有注释的输出视频中看到的那样,在检测之前应用去噪可以改善检测和跟踪结果(右)。

图 3 PyTorch 无 VPI TNR 和(右)有 VPI TNR 的目标检测和跟踪(左)
视频帧右下角显示的每秒帧数( FPS )( 32.8 仅适用于 PyTorch , 32.1 适用于 VPI + PyTorch )表明,将 VPI 添加到 PyTorch 检测管道不会增加太多开销。这在一定程度上是由于避免了从 CUDA 内存到 CPU 内存的每帧超过 20Mb 的拷贝,这是通过使用__cuda_array_interface__启用的。
总结
在这篇文章中,我们以 PyTorch 对象检测和跟踪为例,展示了 VPI 和其他支持__cuda_array_interface__的库之间的互操作性。在目标检测和跟踪之前,您应用了 VPI 的时间噪声抑制来改进它。我们还证明了在 PyTorch 管道中添加 VPI 不会导致性能损失。
关于作者
Sandeep Hiremath 是NVIDIA 计算机视觉的首席技术产品经理。他是一位经验丰富的产品领导者,专长于计算机视觉、机器学习和嵌入式系统领域。在NVIDIA ,他负责为汽车、医疗保健、机器人和研究领域的开发人员提供一组计算机视觉和图像处理解决方案的产品愿景和战略。
André de Almeida Maximo 是 NVIDIA 的系统工程师,专注于嵌入式平台的软件。他曾在多家工业公司的研究中心工作,帮助塑造不同行业的人工智能。在空闲时间,安德烈喜欢跑步和阅读小说。
审核编辑:郭婷
-
嵌入式
+关注
关注
5086文章
19142浏览量
306016 -
gpu
+关注
关注
28文章
4749浏览量
129031 -
计算机
+关注
关注
19文章
7513浏览量
88172 -
pytorch
+关注
关注
2文章
808浏览量
13248
发布评论请先 登录
相关推荐
PCIe 6.0 互操作性PHY验证测试方案
利用Arm Kleidi技术实现PyTorch优化

TI ADS42JB69系列JESD204B ADC与Altera FPGA的互操作性


互操作性对智能家居的重要性

是德科技携手高通突破5G高频段FR3互操作性
PyTorch深度学习开发环境搭建指南
ZigBee多网关之间如何通讯?

基于PyTorch的卷积核实例应用
tensorflow和pytorch哪个更简单?
LitePoint宣布其IQgig-UWB和IQgig-UWB+测试平台通过FiRa联盟验证
深入浅出Matter创建设计的挑战以及实践的重要步骤
Matter 1.3 SVE测试活动在DEKRA德凯成功举办,推动智能家居行业持续发展
区块链互操作标准化应用及经验,华为云 BCS 获评团体标准示范项目






 工商网监
工商网监
评论