 使用RISC-V和内存结构的开放式计算
使用RISC-V和内存结构的开放式计算
在过去几年中,我们目睹了数据生成、处理和进一步利用以获取额外价值和智能的方式发生了巨大变化,所有这些都受到基于深度学习和神经网络应用的新计算模型出现的影响。这种深刻的变化始于数据中心,深度学习技术被用于提供对海量数据的洞察,主要用于分类和/或识别图像,启用自然语言或语音处理,或者理解、生成或成功学习如何玩复杂的游戏。策略游戏。这一变化还带来了一波更节能的计算设备(基于 GP-GPU 和 FPGA),专门针对这类问题创建,后来包括完全定制的 ASIC,
大数据和快速数据
大数据应用程序使用专业的 GP-GPU、FPGA 和 ASIC 处理器通过深度学习技术分析大型数据集,并揭示趋势、模式和关联,从而实现图像识别、语音识别等。因此,大数据主要基于过去的信息,或通常驻留在云中的剩余数据。大数据分析的一个常见结果是“训练有素”的神经网络能够执行特定任务,例如识别和标记图像或视频序列中的所有面部。语音识别也展示了神经网络的力量。
该任务最好由专门的引擎(或推理引擎)执行,这些引擎直接驻留在边缘设备上并由快速数据应用程序领导(图 1)。通过处理在边缘本地捕获的数据,Fast Data 利用源自大数据的算法来提供实时决策和结果。由于大数据提供了从“发生了什么”到“可能发生什么”(预测分析)得出的见解,Fast Data 提供了可以改进业务决策、运营和减少低效率的实时行动,这些行动总是会影响底线结果。这些方法可能适用于各种边缘和存储设备,例如相机、智能手机和 SSD。
计算数据
新的工作负载基于两个场景:(1)在特定工作负载上训练大型神经网络,例如图像或语音识别;(2) 在边缘设备上应用经过训练(或“拟合”)的神经网络。这两种工作负载都需要大量并行数据处理,包括大型矩阵的乘法和卷积。这些计算函数的最佳实现需要对大型向量或数据数组进行操作的向量指令。RISC-V是一个非常适合此类应用程序的架构和生态系统,因为它提供了一个由开源软件支持的标准化流程,使开发人员能够完全自由地采用、修改甚至添加专有矢量指令。图 1 概述了突出的 RISC-V 计算架构机会。
移动数据
边缘快速数据和计算的出现产生了一个事实结果,即将所有数据来回移动到云端进行计算分析效率不高。首先,它涉及通过移动网络和以太网长距离传输相对较大的数据延迟,这对于必须实时运行的图像或语音识别应用程序来说并不是最佳选择。其次,边缘计算允许更多可扩展的架构,其中图像和语音处理或 SSD 上的内存计算操作可以以可扩展的方式执行。因此,每个添加的边缘设备都会带来所需计算能力的增量增加。数据移动方式和时间的优化是新架构可扩展性的关键因素。
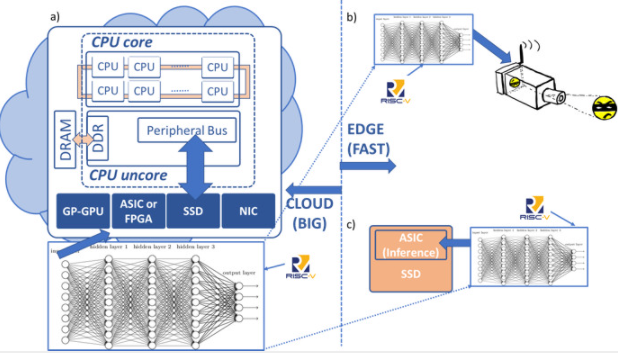
【图1 | 大数据、快速数据和 RISC-V 机会]
在图 1a 中,云数据中心服务器使用深度学习神经网络对大型大数据集进行训练来执行机器学习。在图 1b 中,边缘的安全摄像头使用经过大数据训练的推理引擎,并实时识别图像(快速数据)。在图 1c 中,智能 SSD 设备使用推理引擎进行数据识别和分类,有效利用了设备的带宽。由于图 1 显示了 RISC-V 内核的潜在机会,它可以自由添加专有和未来标准化矢量指令,这些指令有助于处理深度学习和推理技术。
数据移动和访问方式的另一个类似且重要的趋势存在于大数据端和云中(图 2)。传统的计算机架构(图 2a)利用连接到许多其他设备(例如专用机器学习加速器、显卡、快速 SSD、智能网络控制器等)的慢速外围总线。慢速总线通过限制它们自身、主 CPU 和主要的、潜在的持久内存之间的通信能力来影响设备利用率。这类新的计算设备也不可能在它们之间或与主 CPU 共享内存,这会导致通过慢速总线的浪费和有限的数据移动。
关于如何改善不同计算设备(例如 CPU 和计算和网络加速器)之间的数据移动,以及如何在内存或快速存储中访问数据,出现了几个重要的行业趋势。这些新趋势专注于开放标准化工作,以提供更快、更低延迟的串行结构和更智能的逻辑协议,从而实现对共享内存的一致访问。
下一代以数据为中心的计算
未来的架构将需要为连接到计算加速器的持久内存和支持缓存一致性的快速总线(例如TileLink、RapidIO、OpenCAPI和Gen-Z)部署开放接口,不仅可以显着提高性能,还可以使所有设备能够共享内存并减少不必要的数据移动。

【图2 | 计算架构中的数据移动和访问]
在图 2a 中,由于用于快速存储和计算加速设备的外围总线速度较慢,传统计算架构已达到其极限。在图 2b 中,未来的计算架构部署开放接口,提供平台中所有计算资源对共享持久内存的统一缓存一致访问(称为以数据为中心的架构)。在图 2c 中,部署的设备能够利用相同的共享内存,从而减少不必要的数据复制。
CPU 非核心和网络接口控制器的作用将成为移动数据的关键推动力。CPU 非核心组件必须支持关键内存和持久内存接口(例如 NVDIMM-P),以及靠近 CPU 的内存。还需要实施用于计算加速器、智能网络和远程持久内存的智能和快速总线。总线上的任何设备(例如 CPU、通用或专用计算加速器、网络适配器、存储或内存)都可以包含自己的计算资源,并能够访问共享内存(图 2b 和 2c)。
为了优化数据移动,RISC-V 技术可以成为关键推动因素,因为它将在所有计算加速器设备上为新的机器学习工作负载实施矢量指令。它启用了支持开放内存和智能总线接口的开源 CPU 技术,并实现了具有连贯共享内存的新的以数据为中心的架构。
用 RISC-V 解决挑战
大数据和快速数据带来了未来的数据移动挑战,为 RISC-V 指令集架构 (ISA) 及其开放的模块化方法铺平了道路,非常适合作为以数据为中心的计算架构的基础。它提供了以下能力:
扩展边缘计算设备的计算资源
添加新指令,例如用于关键机器学习工作负载的向量指令
将小型计算核心定位在非常靠近存储和内存介质的位置
启用新的计算范式和模块化芯片设计
启用以数据为中心的新架构,其中所有处理元素都可以连贯地访问共享持久内存,优化数据移动
RISC-V由超过一百个组织的成员开发,包括一个软件和硬件创新者的协作社区,他们可以使 ISA 适应特定目的或项目。加入该组织的任何人都可以根据伯克利软件分发 (BSD) 许可设计、制造和/或销售 RISC-V 芯片和软件。
最后的想法
为了实现其价值和可能性,需要捕获、保存、访问和转换数据以充分发挥其潜力。具有大数据和快速数据应用程序的环境已经超过了通用计算架构的处理能力。未来以数据为中心的极端应用程序需要专门构建的处理,以开放的方式支持数据资源的独立扩展。
拥有一个以存储在持久内存中的数据为中心的通用开放计算机架构,同时允许所有设备发挥计算作用,是这些新的可扩展架构的关键推动因素,这些架构由一类新的机器学习计算工作负载驱动。跨所有云和边缘部分的下一代应用程序将需要这种新型的低能耗处理,因为专业计算加速处理器专注于手头的任务,减少移动数据的浪费时间,或执行与数据。人、社区和我们的星球通过数据的力量、潜力和可能性而蓬勃发展。
审核编辑:郭婷
-
处理器
+关注
关注
68文章
19523浏览量
231768 -
芯片
+关注
关注
458文章
51526浏览量
429490 -
机器学习
+关注
关注
66文章
8459浏览量
133370
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论