 AUTO插件和自动批处理的最佳实践
AUTO插件和自动批处理的最佳实践
1.1 概述
OpenVINO 2022.1是自OpenVINO工具套件2018年首次发布以来最大的更新之一,参见《OpenVINO 迎来迄今为止最重大更新,2022.1新特性抢先看!》。在众多新特性中,AUTO插件和自动批处理(Automatic-Batching)是最重要的新特性之一,它帮助开发者无需复杂的编程即可提高推理计算的性能和效率。
1.1.1 什么是AUTO插件?
AUTO插件1 ,全称叫自动设备选择(Automatic device selection),它是一个构建在CPU/GPU插件之上的虚拟插件,如图1-1所示。在OpenVINO 文档中,“设备(device)”是指用于推理计算的 Intel 处理器,它可以是受支持的CPU、GPU、VPU(视觉处理单元)或 GNA(高斯神经加速器协处理器)或这些设备的组合3 。
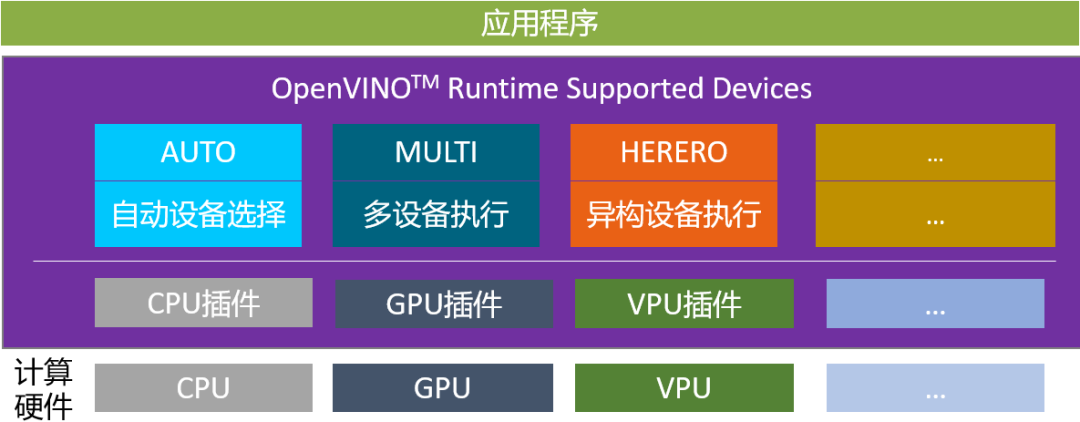
图1-1 OpenVINO Runtime支持的设备插件3
AUTO插件好处有:
■ 首先检测运行时平台上所有可用的计算设备,然后选择最佳的一个计算设备进行推理计算,并根据深度学习模型和所选设备的特性以最佳配置使用它。
■使 GPU 实现更快的首次推理延迟:GPU 插件需要在开始推理之前在运行时进行在线模型编译——可能需要 10 秒左右才能完成,具体取决于平台性能和模型的复杂性。当选择独立或集成GPU时,“AUTO”插件开始会首先利用CPU进行推理,以隐藏此GPU模型编译时间。
■使用简单,开发者只需将compile_model()方法的device_name参数指定为“AUTO”即可,如图1-2所示。

图1-2 指定AUTO插件
1.1.2 什么是自动批处理?
自动批处理(Automatic Batching)2 ,又叫自动批处理执行(Automatic Batching Execution),是OpenVINO Runtime支持的设备之一,如图1-1所示。
一般来说,批尺寸(batch size) 越大的推理计算,推理效率和吞吐量就越好。自动批处理执行将用户程序发出的多个异步推理请求组合起来,将它们视为多批次推理请求,并将批推理结果拆解后,返回给各推理请求。
自动批处理无需开发者手动指定。当compile_model()方法的config参数设置为{“PERFORMANCE_HINT”: ”THROUGHPUT”}时,OpenVINO Runtime会自动启动自动批处理执行,如图1-3所示,让开发人员以最少的编码工作即可享受计算设备利用率和吞吐量的提高。

图1-3 自动启动自动批处理执行
1.2 动手学AUTO插件的特性
读书是学习,实践也是学习,而且是更有效的学习。本文提供了完整的实验代码,供读者一边动手实践,一边学习总结。
Github地址: https://github.com/yas-sim/openvino-auto-feature-visualization
1.2.1 搭建实验环境
第一步,克隆代码仓到本地。
git clone https://github.com/yas-sim/openvino-auto-feature-visualization.git
第二步,在openvino-auto-feature-visualization路径执行:
python -m pip install --upgrade pip
pip install -r requirements.txt
第三步,下载模型并完成转换
omz_downloader --list models.txt
omz_converter --list models.txt
到此,实验环境搭建完毕。实验程序的所有配置和设置参数都硬编码在源代码中,您需要手动修改源代码以更改测试配置,如图1-4所示。
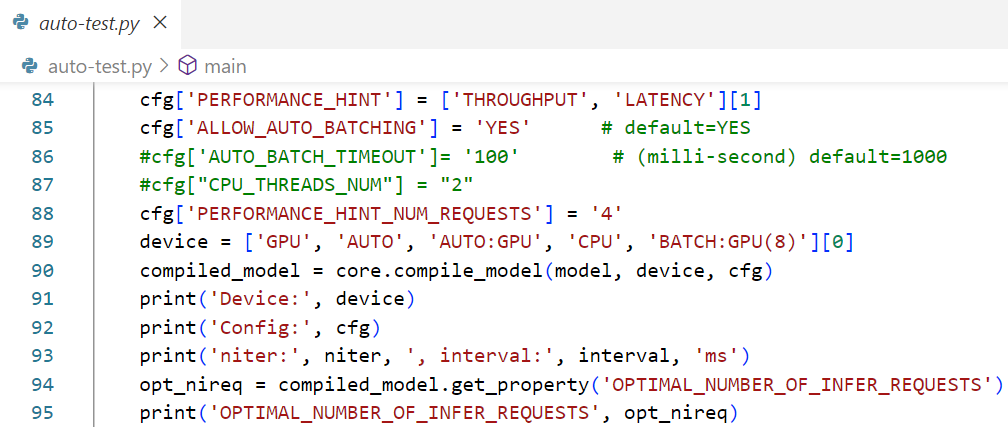
图1-4 手动修改源代码中的配置
1.2.2 AUTO插件自动切换计算设备
GPU插件需要在 GPU 上开始推理之前将IR模型编译为 OpenCL 模型。这个模型编译过程可能需要很长时间,例如 10 秒,会延迟应用程序开始推理,使得应用程序启动时的用户体验不好。
为了隐藏这种 GPU 模型编译延迟,AUTO插件将在 GPU 模型编译进行时使用CPU执行推理任务;当GPU模型编译完成后,AUTO插件会自动将推理计算设备从CPU切换到GPU,如图1-5所示。
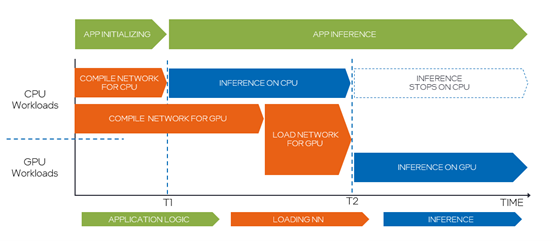
图1-5 AUTO插件自动切换计算设备
1.2.3 动手观察自动切换计算设备的行为
AUTO插件会依据设备优先级1 : dGPU > iGPU > VPU > CPU, 来选择最佳计算设备。当自动插件选择 GPU 作为最佳设备时,会发生推理设备切换,以隐藏首次推理延迟。
请注意,设备切换前后的推理延迟不同;此外,推理延迟故障可能发生在设备切换的那一刻,如图1-6所示。
请如图1-6所示,设置auto-test-latency-graph.py配置参数为:
cfg['PERFORMANCE_HINT'] = ['THROUGHPUT', 'LATENCY'][0]
并运行命令:
python auto-test-latency-graph.py
同时打开Windows任务管理器,观察CPU和iGPU的利用率。
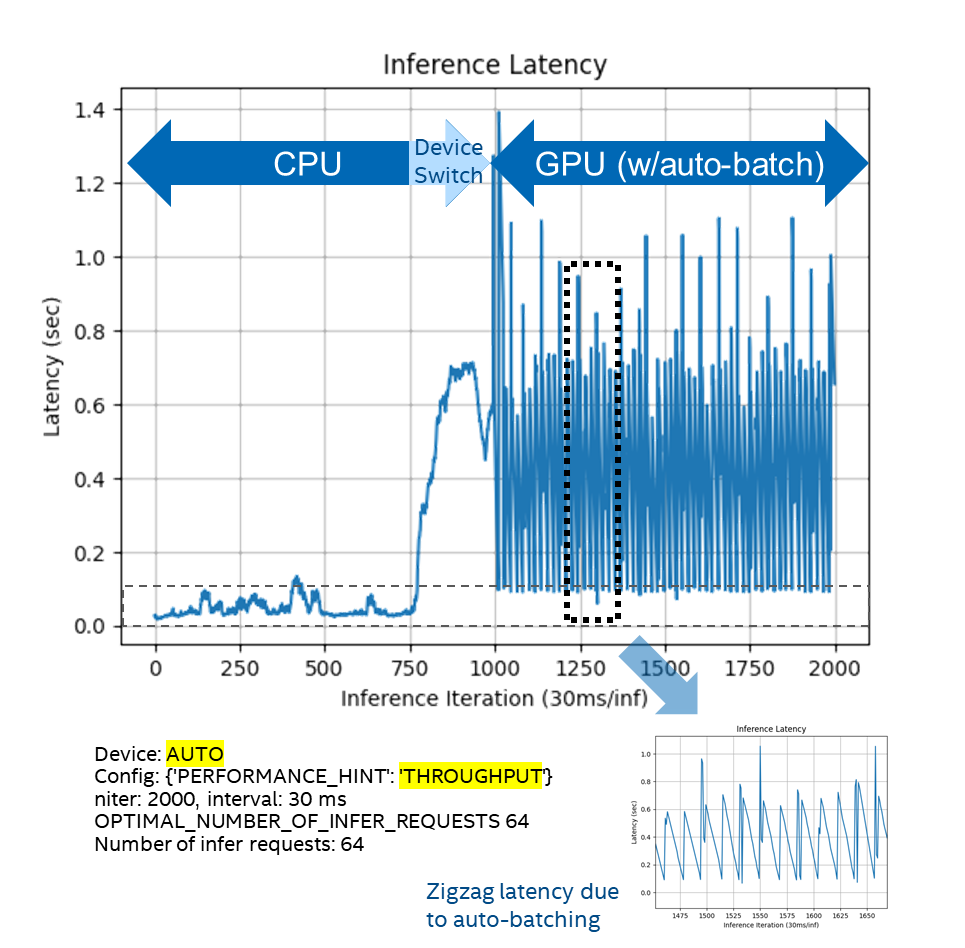
图1-6 config={“PERFORMANE_HINT”:”THROUGPUT”}的执行行为
1.2.4 PERFORMANCE_HINT设置
如1.1.2节所述,AUTO插件的执行行为取决于compile_model()方法的config参数的PERFORMANCE_HINT设置,如表1-1所示:
表1-1 PERFORMANCE_HINT设置

设置auto-test-latency-graph.py配置参数为:
cfg['PERFORMANCE_HINT'] = ['THROUGHPUT', 'LATENCY'][1]
并运行命令:
python auto-test-latency-graph.py
同时打开Windows任务管理器,观察CPU和iGPU的利用率,运行结果如图1-7所示。
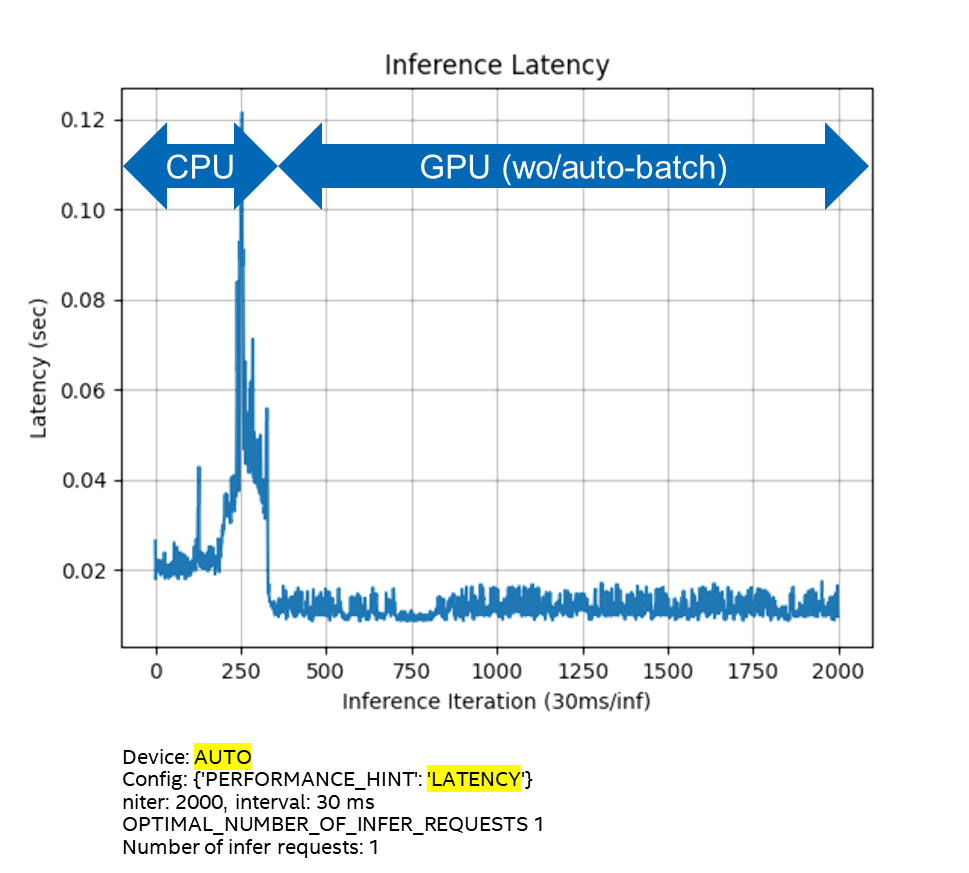
图1-7 config={“PERFORMANE_HINT”:”LATENCY”}的执行行为
通过实验,我们可以发现,根据不同的config参数设置,使得AUTO插件可以工作在不同的模式下:
■ 在Latency模式,不会自动启动Auto Batching,执行设备切换后,GPU上的推理延迟很小,且不会抖动。
■在THROUGHPUT模式,自动启动Auto Batching,执行设备切换后,GPU上的推理延迟较大,而且会抖动。
接下来,本文将讨论Auto Batching对推理计算行为的影响。
1.3 动手学Auto Batching的特性
如1.1.2节所述,自动批处理执行将用户程序发出的多个异步推理请求组合起来,将它们视为多批次推理请求,并将批推理结果拆解后,返回给各推理请求,如图1-8所示。

图1-8 Auto Batching的执行过程
Auto Batching在收集到指定数量的异步推理请求或计时器超时(默认超时=1,000 毫秒)时启动批推理计算(batch-inference),如图1-9所示。

图1-9 启动批推理计算
1.3.1 Auto Batching被禁止时
Auto Batching被禁止时,所有推理请求都是单独被处理的。
请配置并运行auto-test.py。
Device: AUTO
Config: {'PERFORMANCE_HINT': 'LATENCY'}
niter: 20 , interval: 30 ms
OPTIMAL_NUMBER_OF_INFER_REQUESTS 1
Number of infer requests: 1
运行结果如图1-10所示,可见每一个推理请求是被单独处理的。

图1-10 Auto Batching被禁止时的运行结果
1.3.2 Auto Batching被使能时
Auto Batching被使能时,异步推理请求将作为多批次推理请求进行绑定和处理。推理完成后,结果将分发给各个异步推理请求并返回。需要注意的是:批推理计算不保证异步推理请求的推理顺序。
请配置并运行auto-test.py。
Device: GPU
Config: {'CACHE_DIR': './cache', 'PERFORMANCE_HINT': 'THROUGHPUT', 'ALLOW_AUTO_BATCHING': 'YES'}
niter: 200 , interval: 30 ms
OPTIMAL_NUMBER_OF_INFER_REQUESTS 64
Number of infer requests: 16
运行结果如图1-11所示,可见每16个推理请求被组合成一个批次进行批推理计算,推理计算顺序不被保证。

图1-11 Auto Batching被使能时的运行结果
1.3.3 Auto Batching会导致推理延迟变长
由于较长的默认超时设置(默认timeout = 1,000ms),在低推理请求频率情况下可能会引入较长的推理延迟。
由于Auto Batching将等待指定数量的推理请求进入或超时计时器超时,在低推理频率的情况下,它无法在指定的超时时间内收集足够的推理请求来启动批推理计算,因此,提交的推理请求将被推迟,直到计时器超时,这将引入大于timeout设置的推理延迟。
为解决上述问题,用户可以通过 AUTO_BATCH_TIMEOUT 配置参数指定超时时间,以尽量减少此影响。
请使用AutoBatching的默认timeout,运行auto-test.py。
Device: GPU
Config: {'CACHE_DIR': './cache', 'PERFORMANCE_HINT': 'THROUGHPUT'}
niter: 20, interval: 300 ms
OPTIMAL_NUMBER_OF_INFER_REQUESTS 64
Number of infer requests: 64
运行结果如图1-12所示,由于每次都无法在timeout时间内收集到指定数量的推理请求,由此导致推理请求的延迟很高。

图1-12 timeout=1000ms运行结果
请配置AutoBatching的timeout=100ms,然后运行auto-test.py。
Device: GPU
Config: {'CACHE_DIR': './cache', 'PERFORMANCE_HINT': 'THROUGHPUT', 'AUTO_BATCH_TIMEOUT': '100'}
niter: 20 , interval: 300 ms
OPTIMAL_NUMBER_OF_INFER_REQUESTS 64
Number of infer requests: 16

图1-13 timeout=100ms运行结果
运行结果如图1-13所示, timeout=100ms时间内,仅能收集到一个推理请求。
1.3.4 Auto Batching最佳实践
综上所述,Auto Batching的最佳编程实践:
■ 要记住,默认情况下Auto Batching不会启用。
■只有在以下情况时,Auto Batching才启用:
{'PERFORMANCE_HINT': 'THROUGHPUT', 'ALLOW_AUTO_BATCHING': 'YES'}
■如果您的应用程序能够以高频率连续提交推理请求,请使用自动批处理。
■警告:如果您的应用间歇性地提交推理请求,则最后一个推理请求可能会出现意外的长延迟。
■如果推理节奏或频率较低,即推理频率远低于AUTO_BATCH_TIMEOUT(默认为 1,000 毫秒),请勿开启自动批处理。
■您可以使用AUTO_BATCH_TIMEOUT 参数更改自动批处理的超时设置,以最大限度地减少不需要的长延迟,参数值的单位是“ms”。
■如果您知道工作负载的最佳批处理大小,请使用PERFORMANCE_HINT_NUM_REQUESTS 指定适当的批处理数量,即 {'PERFORMANCE_HINT_NUM_REQUESTS':'4'}。同时,以GPU为例,AUTO插件会在后台根据可以使用的内存,模型精度等计算出最佳批处理大小。
1.4 总结
本节给出AUTO 插件和Auto Batching的快速小结,如表1-2所示。
表1-2 AUTO插件和自动批处理执行快速小结表

本文GitHub源代码链接:https://github.com/yas-sim/openvino-auto-feature-visualization
审核编辑 :李倩
-
Auto
+关注
关注
0文章
42浏览量
15279 -
深度学习
+关注
关注
73文章
5503浏览量
121152
原文标题:OpenVINO™ 2022.1中AUTO插件和自动批处理的最佳实践 | 开发者实战
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
立讯精密入选2024可持续发展最佳实践案例

MES系统的最佳实践案例
边缘计算架构设计最佳实践
云计算平台的最佳实践

RTOS开发最佳实践
工业自动化:PROFINET网络技术解析与Auto Pro工业交换机应用实践

LOTO示波器动作编程功能(命令批处理)
热烈恭贺|开盛晖腾入围APEC•ESCI最佳实践奖候选






 工商网监
工商网监
评论