 关于字符串硬核讲解
关于字符串硬核讲解
1 暴力破解法
在主串A中查找模式串B的出现位置,其中如果A的长度是n,B的长度是m,则n > m。当我们暴力匹配时,在主串A中匹配起始位置分别是 0、1、2….n-m 且长度为 m 的 n-m+1 个子串。
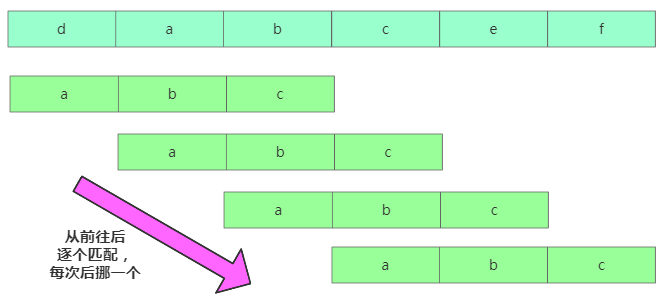 暴力匹配
暴力匹配对应代码是:
#include
如果主串是bbb…bbb,模式串是bbbbc,那每个串都要比较m次,一共是(n-m+1)*m次。时间复杂度很大 = O(n*m),一般简单匹配时候可用此法。
2 Rabin-Karp 算法
算法思路:对主串的 n-m+1 个子串分别求哈希值,然后跟模板串的哈希值对比,如果一样再逐个对比字符串是否一样。
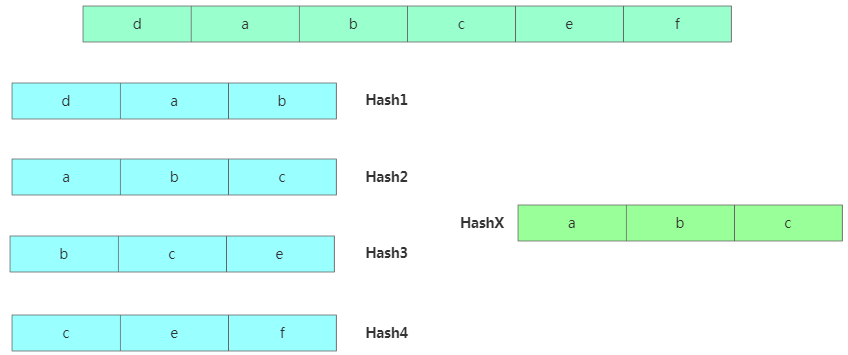 Rabin-Karp算法
Rabin-Karp算法但是中间数据的Hash值计算是可以优化的,我们以简单的字符串匹配举例,把a-z映射到0~25上。然后按照26进制计算一个串的哈希值,比如:
 Hash计算
Hash计算但是你会发现相邻的两个子串数据之间是有重叠的,比如
dab跟abc重叠了ab。这样哈希下一个数据的Hash值其实可以借鉴下上一个数据的值推导得出: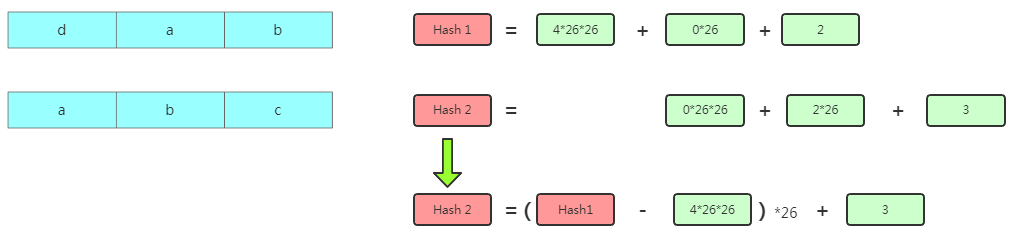 优化计算哈希值
优化计算哈希值RK算法的时间复杂度包含两部分,第一部分是遍历所有子串计算Hash值,时间复杂度是O(n)。第二部分是比较哈希值,这部分时间复杂度也是O(n)。
这个算法的核心就是尽量减少哈希值相等的情况下数据不一样从而进行的比较,所以哈希算法要尽可能的好,如果你感觉用123对应字母abc容易碰撞,那用素数去匹配也是OK的,反正目的是一样的, 你可以认为这是一种取巧的办法来处理字符串匹配问题。
3 Boyer-Moore 算法。
Boyer Moore算法是一种非常高效的字符串匹配算法,它的性能是著名的 KMP 算法的 3 到 4 倍。它不太好理解,但确是工程中使用最多的字符串匹配算法。以前我们匹配字符串的时候是一个个从前往后挪动来逐次比较,BM 算法核心思想是在模式串中某个字符与主串不能匹配时,将模式串往后多滑动几位,来减少不必要的字符比较。
 移动比较对比
移动比较对比整体而言BM算法还是挺复杂的相比前面两种,主要包含
坏字符规则跟好后缀规则。
3.1 坏字符规则
坏字符规则意思是根据模式串从后往前匹配,当我们发现某个字符没法匹配的时候。我们把这个没有匹配的主串中的字符叫作坏字符。
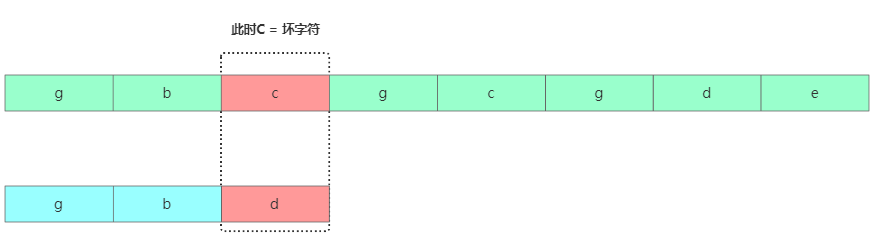 坏字符
坏字符找到坏字符c后,在模式串中继续查找发现c跟模式串任何字符无法匹配,则可以直接将模式串往后移动3位。继续从模式串尾部对比。
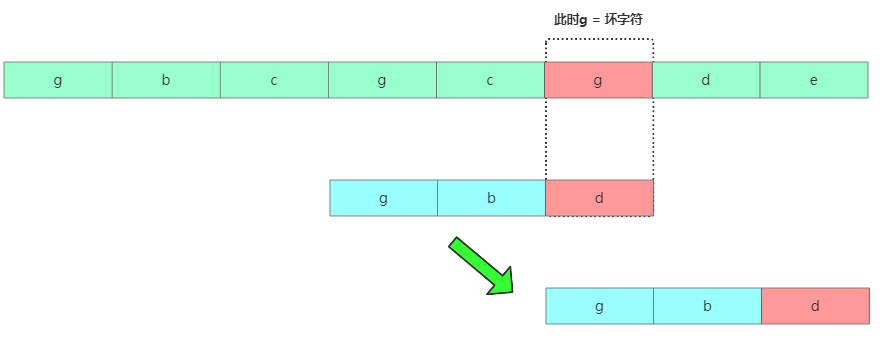 移动2格
移动2格此时发现坏字符是g,但在模式串中有个g存在,不能再往后移动3个了,移动的位置是2个。再继续匹配。那有啥规律呢?
发送不匹配时,坏字符对应的模式串字符下标位置Si,如果坏字符在模式串中存在,取从后往前最先出现的坏字符下标记为Xi(取第一个是怕挪动太大咯),如果坏字符在模式串中不存在则Xi = -1。此时模式串往后移动位数= Si - Xi。
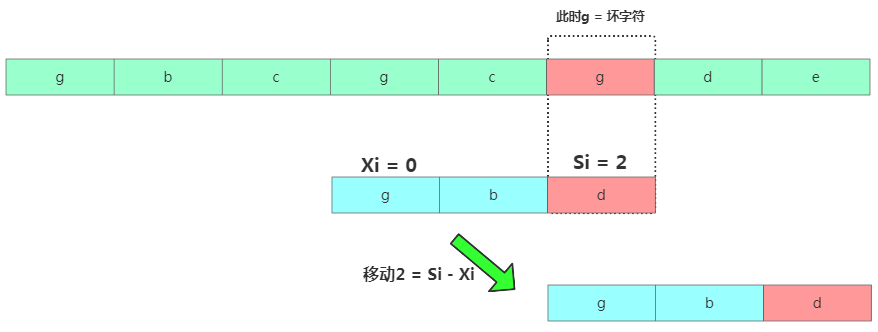 坏字符移动规则
坏字符移动规则如果碰到极致的主串=cccdcccdcccd,模式串=cccc,那此时时间复杂度是O(n/m)。
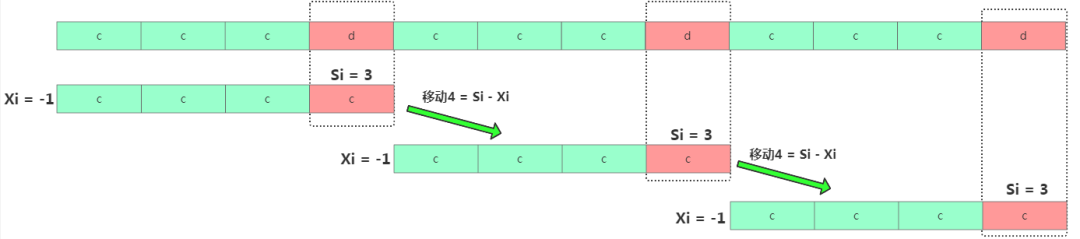 最优解
最优解但是不要高兴太早!下面这种情况可能导致模式串不往后移动,反而往前移动哦!
 往前移动?
往前移动?所以此时BM算法还需要用到
好后缀规则。
3.2 坏字符代码
为避免每次都拿怀字符从模式串中遍历查找,此时用到散列表将模式串中每个字符及其下标存起来,方便迅速查找。
接下来说下散列表规则,比如一个字符是一个字节,用大小为256的数组记录每个字符在模式串出现位置,数组中存储的是模式串出现的位置,数组下表是字符对应的ASCII值。
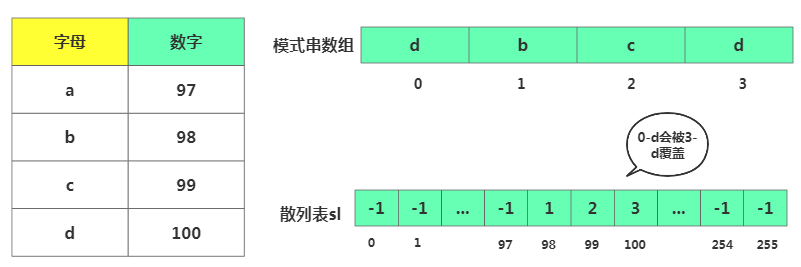 哈希规则
坏字符规则:
哈希规则
坏字符规则:
//全局变量 SIZE
privatestaticfinalintSIZE=256;
//b=模式串数组,m是模式串数组长度,sl是哈希表,默认-1
privatevoidgenerateBC(char[]b,intm,int[]sl){
for(inti=0;i< SIZE; i++) {
sl[i] = -1;//初始化sl
}
for(inti=0;i< m; ++i) {
intascii=(int)b[i];
sl[ascii]=i;
}
}
接下来先不考虑好后缀规则跟坏字符的负数情况,先大致写出 BM 算法代码。
 坏字符BM
坏字符BM
publicintbm(char[]a,intn,char[]b,intm){
//记录模式串中每个字符最后出现的位置
int[]sl=newint[SIZE];
//构建坏字符哈希表
generateBC(b,m,sl);
//i表示主串与模式串对齐的第一个字符
inti=0;
while(i<= n - m) {
intj;
for(j=m-1;j>=0;j--){
if(a[i+j]!=b[j])break;
}
if(j< 0){
//匹配成功,返回主串与模式串第一个匹配的字符的位置
returni;
}
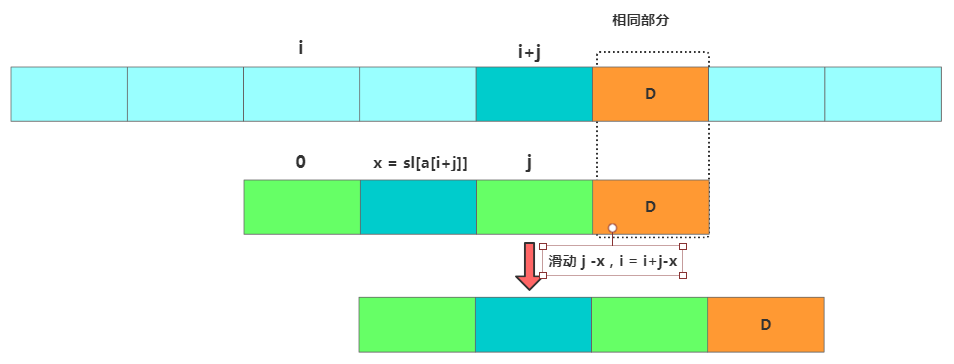
//将模式串往后滑动j-bc[(int)a[i+j]]位
i=i+(j-sl[(int)a[i+j]]);
}
return-1;
}
3.3 好后缀规则
好后缀跟坏后缀道理类似,从后往前匹配,直到遇到不匹配的字符x,那主串x之前的就叫好后缀。
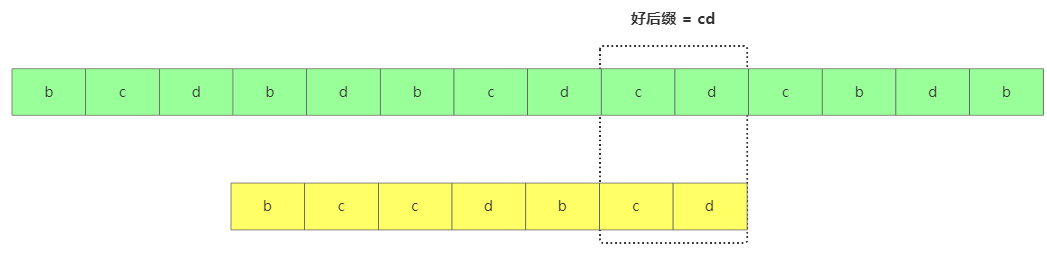 好后缀定义
好后缀定义此时移动的规则如下:
-
如果好后缀在模式串中找到了,用x框起来,然后将x框跟好后缀对齐继续匹配。
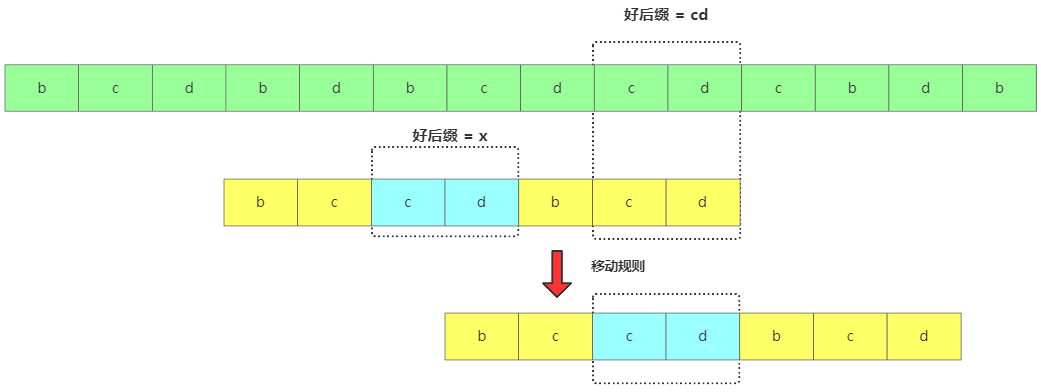 找到了移动规则
找到了移动规则 -
找不到的时候,如果直接移动长度是模式串m位,那极有可能过度了!而过度移动存在的原因就是,比如你找了好后缀u,u在模式串中整体没找到,但是u的子串d是可以跟模式串匹配上的啊。
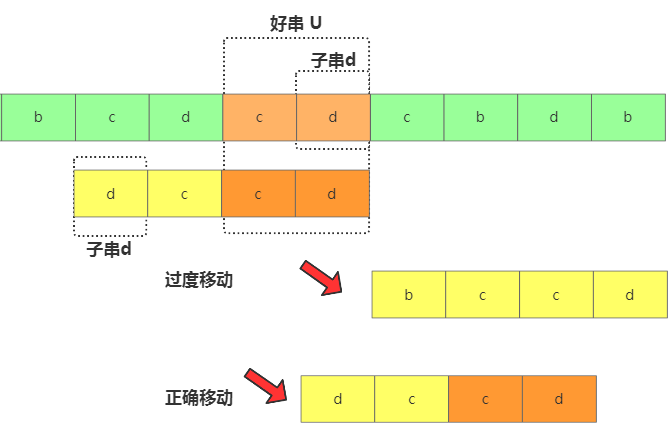 过度移动
过度移动
所以此时还要看好后缀的后缀子串是否跟模式串中的前缀子串匹配,从好后缀串的后后缀子串中找个最长能跟模式串的前缀子串匹配的然后滑动到一起,比如上面的d。
然后分别计算坏字符往后滑动位数跟好后缀往后滑动此时,两者取其大作为模式串往后滑动位数,这种情况下还可以避免坏字符的负数情况。
3.4 好后缀代码
好后缀的核心其实就在于两点:
-
在模式串中,查找跟好后缀匹配的另一个子串。
-
在好后缀的后缀子串中,查找最长的、能跟模式串前缀子串匹配的后缀子串。
3.4.1 预处理工作
上面两个核心点可以在代码层面用暴力解决,但太耗时!我们可以在匹配前通过预处理模式串,预先计算好模式串的每个后缀子串,对应的另一个可匹配子串的位置。
先看如何表示模式串中不同的后缀子串,因为后缀子串的最后个字符下标为m-1,我们只需记录后缀子串长度即可,通过长度可以确定一个唯一的后缀子串。
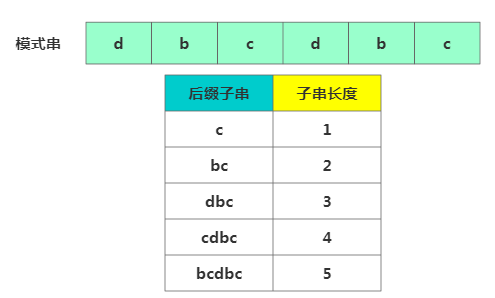 子串表示
子串表示再引入关键的变量
suffix数组。suffix 数组的index表示后缀子串的长度。下标对应的数组值存储的是好后缀在模式串中匹配的起始下标值:
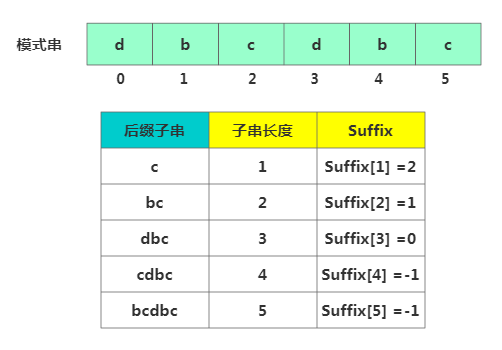 suffix数组定义
suffix数组定义比如此处后缀子串c在模式串中另一个匹配开始位置为2, 后缀子串bc在模式串中另一个匹配开始位置为1 后缀子串dbc在模式串中另一个匹配开始位置为0, 后缀子串cdbc在模式串中只出现了一次,所以为-1。
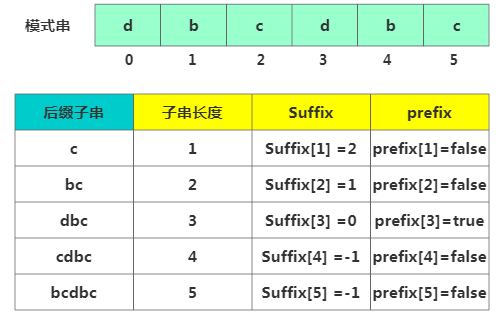 prefix 数组
prefix 数组这里需注意,我们不仅要在模式串中查找跟好后缀匹配的另一个子串,还要在好后缀的后缀子串中查找最长的能跟模式串前缀子串匹配的后缀子串。比如下面:
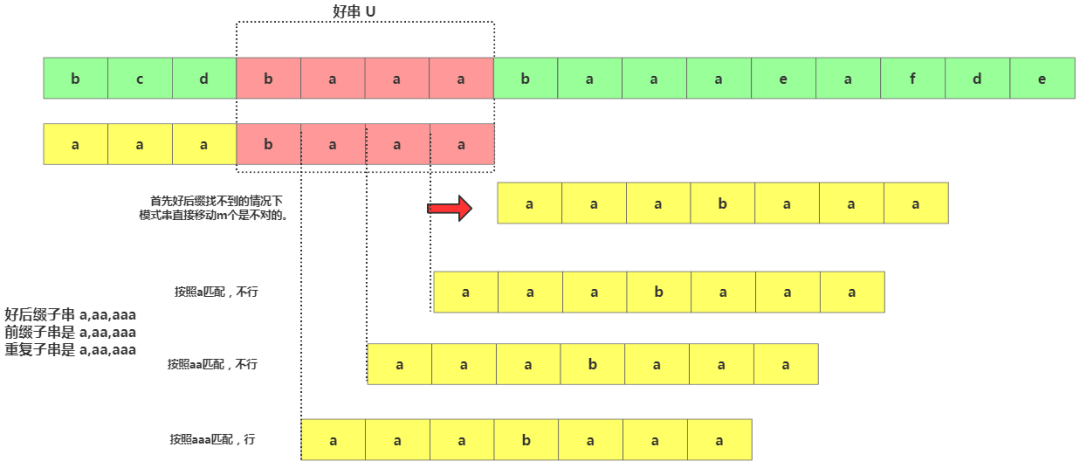 最长模式匹配
最长模式匹配
用suffix只能查找跟好后缀匹配的另一个子串。但还需要个 boolean 类型的prefix数组来记录模式串的后缀子串是否能匹配模式串的前缀子串。
接下来重点看下如何填充suffix跟prefix数组,拿下标从 0 到 i 的子串与整个模式串,求公共后缀子串,其中i=[0,m-2]。如果公共后缀子串的长度是 k,就suffix[k]=j,其中 j 表示公共后缀子串的起始下标。如果 j = 0,说明公共后缀子串也是模式串的前缀子串,此时 prefix[k]=true。
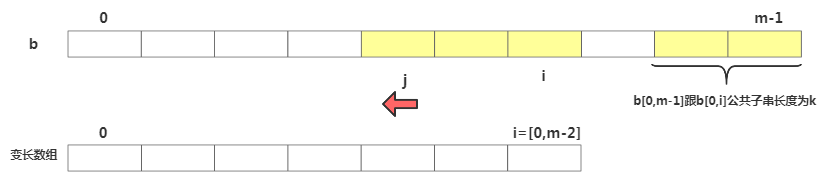 suffix跟prefix数组
suffix跟prefix数组
//b=模式串,m=模式串长度,suffix,prefix数组如上定义
privatevoidgenerateGS(char[]b,intm,int[]suffix,boolean[]prefix){
//初始化
for(inti=0;i< m; i++){
suffix[i]=-1;
prefix[i]=false;
}
//b[0,i]
for(inti=0;i< m - 1;i++){
intj=i;
//公共后缀子串长度
intk=0;
//与b[0, m-1]求公共后缀子串,并且会有覆盖现象产生。
while(j>=0&&b[j]==b[m-1-k]){
--j;
++k;
//j+1表示公共后缀子串在b[0,i]中的起始下标
suffix[k]=j+1;
}
//如果公共后缀子串也是模式串的前缀子串
if(j==-1)prefix[k]=true;
}
}
3.4.2 正式代码
有了suffix跟prefix数组后,看下移动规则。假设好后缀串长度=k,如果k != 0,说明有好后缀,接下来通过suffix[k]的值来判断如何移动。
-
suffix[k] != -1,不等于时说明匹配上了,模式串后移 j-suffix[k]+1 位,其中 j 表示坏字符对应的模式串中的字符下标。
-
suffix[k] = -1,等于时说明好后缀没匹配上,那就看下子串的匹配情况,好后缀的后缀子串长度是 b[r, m-1],其中 r = [j+2,m-1],后缀子串长度 k=m-r,如果 prefix[k] = true,说明长度为 k 的后缀子串有可匹配的前缀子串,这样我们可以把模式串后移 r 位。
-
如果都没匹配上,那就直接将模式串后移m位。
// a跟n 分别表示主串跟主串长度。 // b跟m 分别表示模式串跟模式串长度。 publicintbm(char[]a,intn,char[]b,intm){ //用来记录模式串中每个字符最后出现的位置 int[]sl=newint[SIZE]; //构建坏字符哈希表 generateBC(b,m,sl); int[]suffix=newint[m]; boolean[]prefix=newboolean[m]; //构建suffix跟prefix数组 generateGS(b,m,suffix,prefix); inti=0;//j表示主串与模式串匹配的第一个字符 while(i<= n - m) { intj; //模式串从后往前匹配 for(j=m-1;j>=0;--j){ //坏字符对应模式串中的下标是j if(a[i+j]!=b[j])break; } if(j< 0){ //匹配OK,返回主串与模式串第一个匹配的字符的位置 returni; } //坏字符计算所得需移动长度 intx=j-sl[(int)a[i+j]]; inty=0; //j< m-1 说明有好的匹配上了 if(j< m-1){ y=moveByGS(j,m,suffix,prefix); } i=i+Math.max(x,y); } return-1; } //j=坏字符对应的模式串中的字符下标 //m=模式串长度 privateintmoveByGS(intj,intm,int[]suffix,boolean[]prefix){ //好后缀长度 intk=m-1-j; if(suffix[k]!=-1){ //好后缀可以匹配上,返回需移动长度 returnj-suffix[k]+1; } //有匹配到好后缀子串的模式串前缀子串 for(intr=j+2;r<= m-1;++r){ if(prefix[m-r]==true){ returnr; } } //没找到直接移动最大值 returnm; }
3.5 复杂度分析
整个BM算法用到了额外的 sl、suffix、prefix三个数组,其中sl数组大小跟字符集大小有关,suffix 数组和 prefix 数组的大小跟模式串长度 m 有关。如果处理字符集很大的字符串匹配问题,bc 数组对内存的消耗就会比较多。
因为好后缀和坏字符规则是独立的,如果我们运行的环境对内存要求苛刻,可以只使用好后缀规则,不使用坏字符规则,这样就可以避免 bc 数组过多的内存消耗。不过,单纯使用好后缀规则的 BM 算法效率就会下降一些了。
BM 算法的时间复杂度分析起来是非常复杂,一般在3n~5n之间。
4 KMP 算法
KMP算法跟BM算法类似,从前往后匹配,把能匹配上的叫好前缀,不能匹配上的叫坏字符。
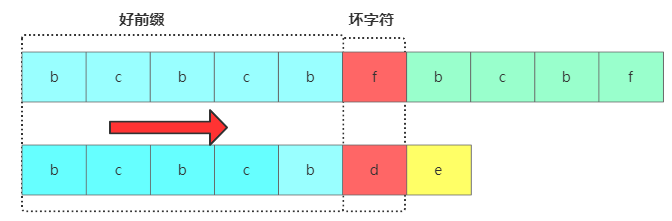 KMP匹配定义
KMP匹配定义遇到坏字符后就要进行主串好前缀后缀子串跟模式串的前缀子串进行对比,问题是对于已经比对过的好前缀,能否找到一种规律,将模式串一次性滑动很多位?
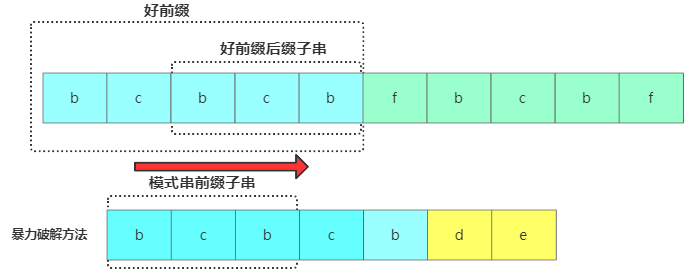 暴力破解
暴力破解
思路是将主串中好前缀的后缀子串和模式串中好前缀的前缀子串进行对比,获取模式串中最大可以匹配的前缀子串。一般把好前缀的所有后缀子串中,最长的可匹配前缀子串的那个后缀子串,叫作最长可匹配后缀子串。对应的前缀子串,叫作最长可匹配前缀子串。假如现在最长可匹配后缀子串 = u,最长可匹配前缀子串 = v,获得u跟v的长度为k,此时在主串中坏字符位置为i,模式串中为j,接下来将模式串后移j-k位,然后将待比较的模式串位置j = j-k进行比较。
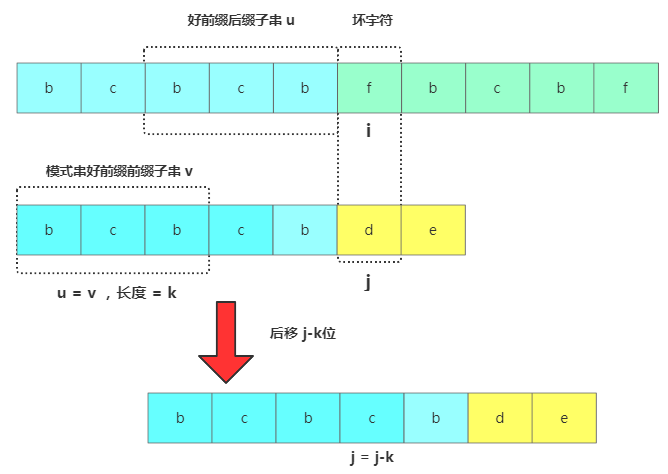 KMP算法移动
KMP算法移动4.1 Next 数组存在意义
那最长可匹配前缀跟后缀我们用模式串就可以求解了。仿照BM算法,预先计算好就行。在KMP算法中提前构造个next数组。其中next数组的下标用来存储前缀子串最后一个数据的index,对应的value保存的是这个字符串的后缀子串集合跟前缀子串集合的交集。
干说可能不太好理解,我们以"abababca"为例。它的部分匹配表(Partial Match Table)数组如下:
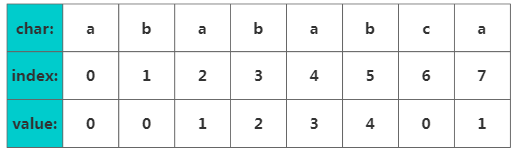 Next数组
Next数组接下来对value值的获取进行解释,如果字符串A和B,存在A=BS,其中S是任意的非空字符串,那就称B为A的前缀。例如”what”的前缀包括{"w","wh","wha"},我们把所有前缀组成的字符串的前缀集合。同样可以定义后缀A=SB, 其中S是任意的非空字符串,那就称B为A的后缀,例如"Potter"的后缀包括{"otter", "tter", "ter", "er", "r"},然后把所有后缀组成字符串的后缀集合。要注意字符串本身并不是自己的后缀。
PMT数组中的值是字符串的前缀集合与后缀集合的交集中最长元素的长度。例如,对于"aba",它的前缀集合为{"a", "ab"},后缀集合为{"ba", "a"}。两个集合的交集为{"a"},那么长度最长的元素就是字符串"a"了,长度为1,所以"aba"的Next数组value = 1,同理对于"ababa",它的前缀集合为{"a", "ab", "aba", "abab"},它的后缀集合为{"baba", "aba", "ba", "a"}, 两个集合的交集为{"a", "aba"},其中最长的元素为"aba",长度为3。
我们以主串"ababababca"中查找模式串"abababca"为例,如果在j处字符不匹配了,那在模式串[0,j-1]的数据串"ababab"中,前缀集合跟后缀集合的交集最大值就是长度为4的"abab"。
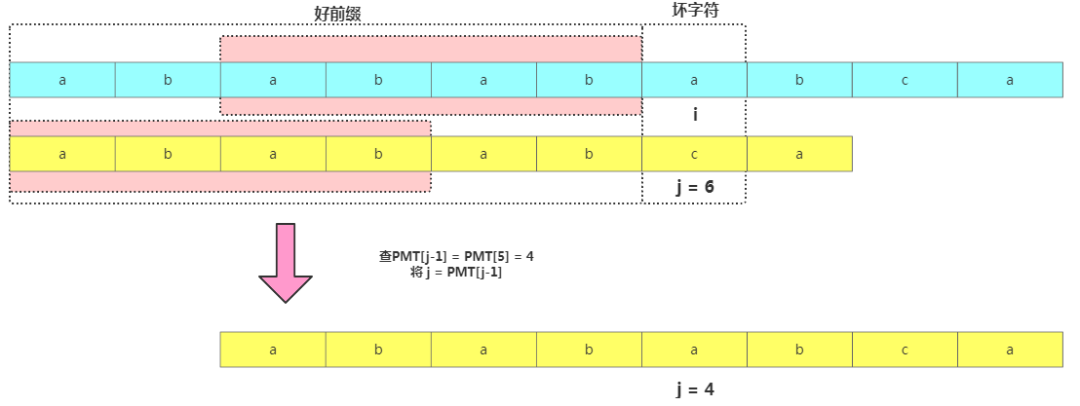 PMT数组使用方法
PMT数组使用方法基于此就可以使用PMT加速字符串的查找了。我们看到如果是在
j位失配,那么影响j 指针回溯的位置的其实是第 j−1 位的 PMT 值,但是编程中为了方便一般不直接使用PMT数组而是使用Next数组,Next数组的value其实就是存储的这个前缀的最长可以匹配前缀子串的结尾字符下标,其中如果匹配不到用-1代替。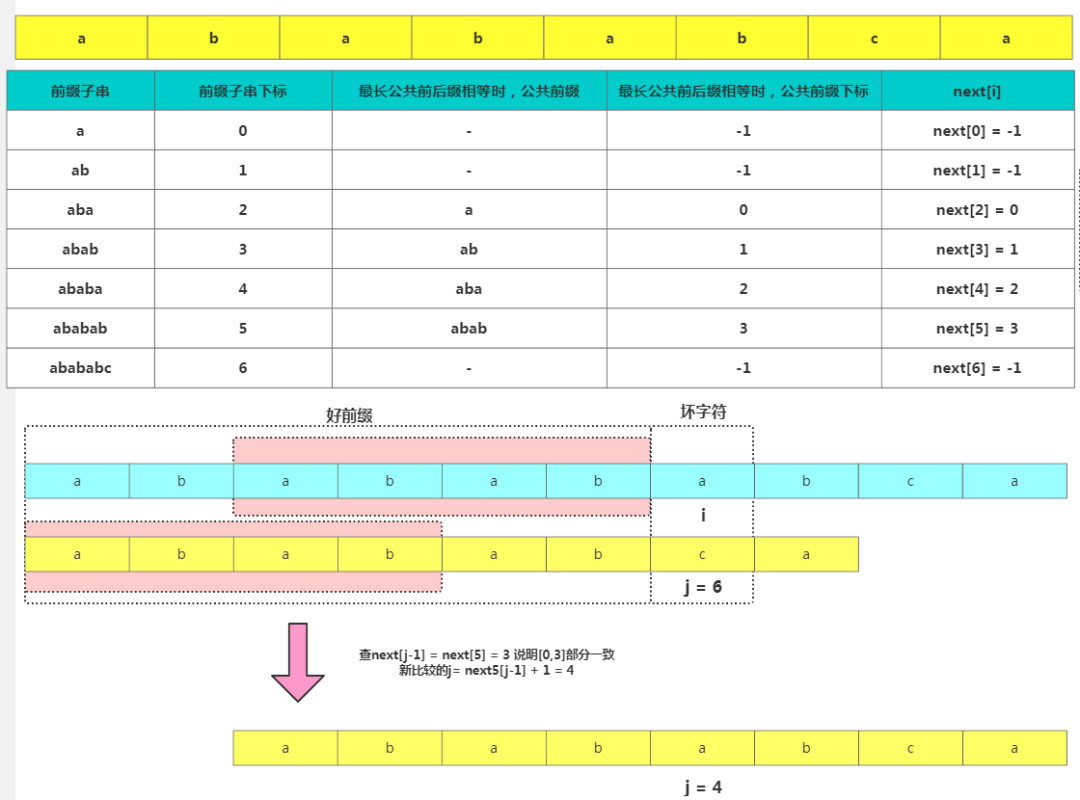 Next数组使用
Next数组使用4.2 KMP 匹配代码
// a =主串,n=主串长度。b =模式串,m =模式串长度
publicstaticintkmp(char[]a,intn,char[]b,intm){
int[]next=getNexts(b,m);
intj=0;
for(inti=0;i< n; ++i) {
while(j>0&&a[i]!=b[j]){
j=next[j-1]+1;//发现不一样则保持i不变j进行移动
}
if(a[i]==b[j]){
++j;
}
if(j==m){//找到匹配模式串的了
returni-m+1;
}
}
return-1;
}
至此你会发现只要搞明白了PMT存在的意义,然后顺着思路推Next数组即可。
4.3 Next 数组求解
当要计算next[i]时,前面计算过的next[0~i-1]是否可以被用来快速推导出next[i]呢?
情况一:如果next[i-1] = k-1,那此时b[0,i-1]的最长可匹配前缀子串是b[0,k-1],如果b[0,i-1]的下个字符b[i]跟b[0,k-1]的下个字符b[k]相等,那next[i] = k。

情况二:假设b[0,i]最长可用后缀子串是b[r,i],那b[r,i-1]肯定是b[0,i-1]的可匹配后缀子串,但不一定是最长可匹配后缀子串。比如字符串b = "dexdecdexdex",此时最长可匹配后缀子串是"dex",b去掉最后的'x'成为B,此时虽然"de"是B的可匹配后缀子串,但"dexde"才是最长后缀子串!也就是说b[0, i-1]最长可匹配后缀子串对应的模式串的前缀子串的下一个字符并不等于 b[i]。
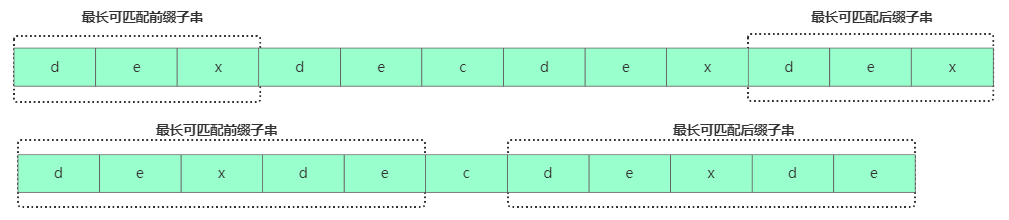
那此时看下b[0,i-1]的
次长可匹配后缀子串b[x,i-1]对应的可匹配前缀子串b[0,i-1-x] 的下个字符b[i-x] 是否等于b[i],相等那b[0,i]的最长可匹配后缀子串是b[x,i]。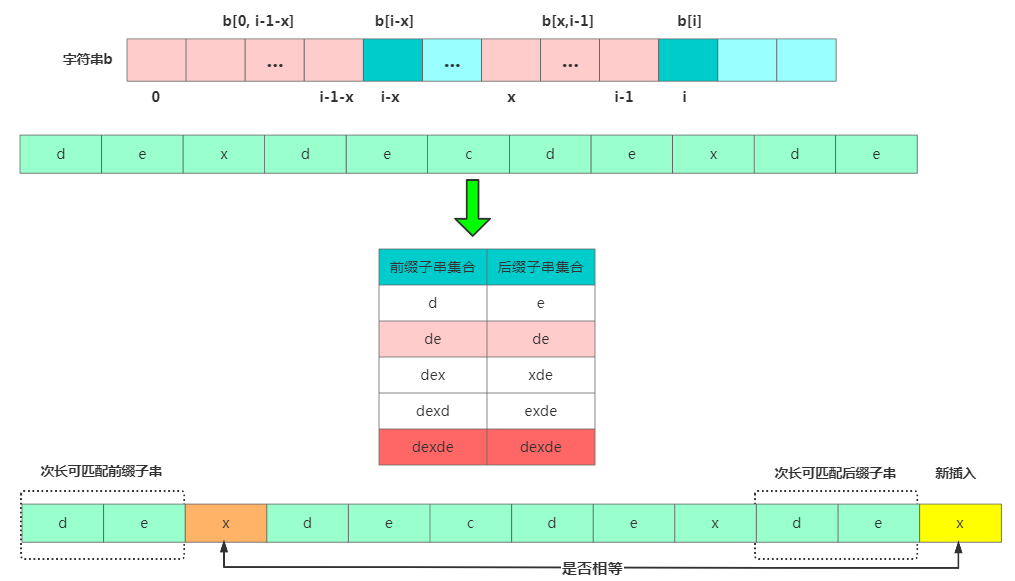
那我们来求 b[0, i-1]的次长可匹配后缀子串呢?次长可匹配后缀子串一定被包含在最长可匹配后缀子串中,而最长可匹配后缀子串又对应最长可匹配前缀子串 b[0, y]。此时查找 b[0, i-1]的次长可匹配后缀子串变成了查找b[0, y]的最长匹配后缀子串的问题。
按此思路考察完所有的 b[0, i-1]的可匹配后缀子串 b[y, i-1],直到找到一个可匹配的后缀子串,它对应的前缀子串的下一个字符等于 b[i],那这个 b[y, i]就是 b[0, i]的最长可匹配后缀子串。
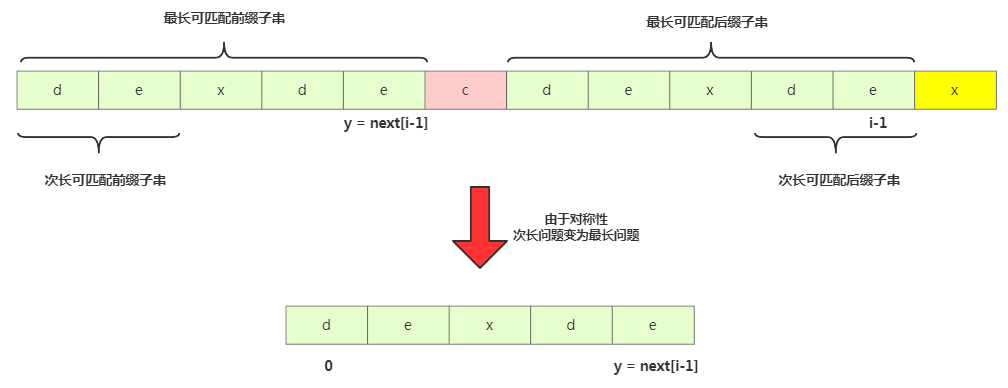
//b=模式串,m=模式串的长度
privatestaticint[]getNexts(char[]b,intm){
int[]next=newint[m];
next[0]=-1;
intk=-1;
for(inti=1;i< m; ++i) {
while(k!=-1&&b[k+1]!=b[i]){
k=next[k];
//因为前一个的最长串的下一个字符不与最后一个相等,需要找前一个的次长串,
//问题就变成了求0到next(k)的最长串,如果下个字符与最后一个不等,
//继续求次长串,也就是下一个next(k),直到找到,或者完全没有
//最好结合前面的图来看
}
if(b[k+1]==b[i]){
++k;//字符串相等则看下一个
}
next[i]=k;//数组赋值
}
returnnext;
}
KMP空间复杂度:该算法只需要一个额外的 next 数组,数组的大小跟模式串相同。所以空间复杂度是 O(m),m 表示模式串的长度。
KMP时间复杂度:next 数组计算的时间复杂度是 O(m) + 匹配时候时间复杂度是 O(n) = O(m+n)
至此,常见的字符串匹配算法正式讲解完毕,其实前面说的都是一个主串,一个模式串。
审核编辑 :李倩
-
字符串
+关注
关注
1文章
579浏览量
20528
原文标题:字符串硬核讲解
文章出处:【微信号:zhuyandz,微信公众号:FPGA之家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐








 工商网监
工商网监
评论