 使用VMX设计的能量计实时测量系统
使用VMX设计的能量计实时测量系统
处理器的性能与操作系统允许的一样好。一个计算平台,无论是嵌入式的还是其他的,不仅包括物理资源——内存、CPU 内核、外围设备和总线——通过资源分区(虚拟化)取得了一些成功,还包括性能资源,如 CPU 周期、时钟速度、内存和I/O 带宽和主/高速缓存内存空间。这些资源由诸如优先级或时间片之类的古老方法管理,或者根本不管理。结果,处理器未被充分利用并消耗过多能量,从而剥夺了它们真正的性能潜力。
大多数现有的管理方案都是分散的。CPU 周期由优先级和时间隔离管理,这意味着需要在预设时间内完成的应用程序将保留该时间,无论它们是否真的需要它。由于缓存未命中、未命中推测和 I/O 阻塞导致执行时间无法安全预测,因此保留时间通常比需要的时间长。为了确保智能手机中的调制解调器堆栈接收到足够的 CPU 周期来进行呼叫,可能会限制其他应用程序不能同时运行。这就解释了为什么一些无名品牌手机的用户抱怨当电话响起时,GPS 会掉线。
除此之外,电源管理最近引起了极大的兴趣。注意“分离”的特征。大多数部署的解决方案擅长检测空闲时间、使用系统响应缓慢的模式,或 CPU 可以以较低时钟速度运行从而节省能源的特定应用程序。例如,英特尔提出了 Hurry Up and Get Idle (HUGI)。要理解 HUGI,请考虑这个类比:有人可以使用 Indy 汽车全速到达目的地然后将其停放,但也许使用 Prius 及时到达目的地会更实用。您认为哪个使用较少的气体?基于使用模式的电源管理粒度太粗,无法始终有效地挖掘所有节能机会。
理想情况下,开发人员希望改变时钟速度/电压以匹配瞬时工作负载,但这不能仅通过关注正在运行的应用程序来实现。开发人员可能能够确定应用程序按时完成的最低时钟速度,但他们是否可以在不知道其他等待运行的应用程序如果延迟会受到影响的情况下减慢时钟速度?单独管理任务和时钟速度(功率)并不能带来最佳的能源消耗。获胜的方法将同时管理/优化所有性能资源,但至少管理时钟速度和任务调度。想象一下,任务调度器是旅行计划者,时钟管理器是汽车司机。如果汽车减速,则必须重新计划行程。驱动程序可能由于糟糕的路况(缓存未命中)而不得不减速或在铁路障碍处停下(多线程中的障碍,由于分配的 I/O 带宽不足而导致缓冲区空时阻塞,等等)。表现出依赖于数据的执行时间的应用程序也存在一个问题,因为它们完成的时间直到它们完成才知道。应该提前为这些应用程序分配什么时钟速度?
先进的绩效管理解决方案
管理性能资源的一个示例是 VirtualMetrix 性能管理 (PerfMan),它通过参数驱动算法控制所有性能资源。该软件根据带宽消耗和指令退役等性能数据安排任务、更改时钟速度、确定空闲期并分配 I/O 带宽和缓存空间。这种方法(如图 1 所示)解决了碎片问题,并可以实现最佳资源分配,甚至考虑到现代处理器和数据相关应用程序的执行速度的不可预测性。
图 1: PerfMan 使用参数驱动算法控制所有性能资源,从而实现最佳资源分配。
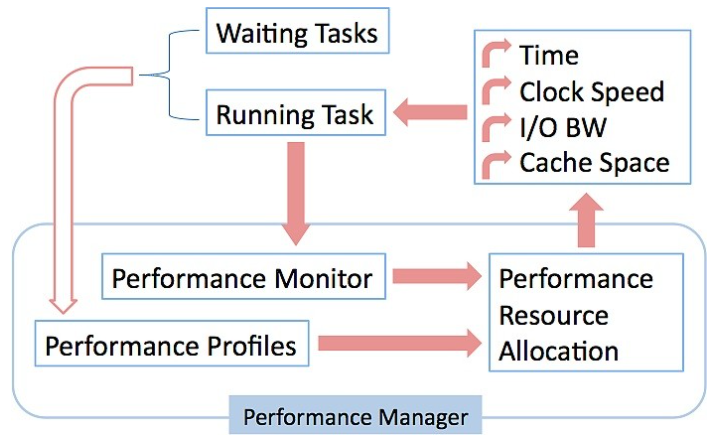
正在申请专利的已完成工作分配算法使用闭环方法,通过比较已完成的工作与仍需完成的工作来做出分配决策,以系统提供的任何可测量的性能量表示。例如,如果应用程序是填充缓冲区的视频播放器或通信协议,PerfMan 可以跟踪缓冲区填充级别并确定时钟速度和运行时间,以便及时填充缓冲区。完成的时间不可避免地会有所不同,因此决策会周期性更新。在许多情况下,缓冲区被过度填充以防止缓冲区空时阻塞,这可能导致时序违规。PerfMan 能够进行精确的性能分配,将缓冲保持在最低限度并减少内存占用。该算法可以处理硬、软、
如果应用程序执行图被量化为简单的性能参数,并且在重要时知道截止日期,那么算法将动态调度以及时满足截止日期。即使是非实时应用程序也需要一些性能分配以避免无限期延迟。分配应用程序所需的最少处理器资源会提高系统利用率,从而可能产生更高的工作负载。该方法不依赖于严格的优先级,尽管可以使用它们。执行的优先级或顺序是应用程序在等待轮到运行时表现出的紧迫性的直接结果,这是要执行的基本工作/已完成工作范式的函数。
扩展到更多维度
如果任务已准备好在现有操作系统中运行,它们将运行,但它们需要吗?如果操作系统知道它不会影响它们的操作,它们可以被延迟(强制空闲)吗?
了解每个任务的时间以及它是否正在运行或等待运行相对于其完成进度,允许软件自动确定最小时钟速度和运行时间。因此,在所有负载条件下,一切都按时完成。将时钟速度与瞬时工作负载相匹配并不意味着时钟速度总是最小化。低能耗的目标有时需要在空闲之后出现高速爆发,例如英特尔的 HUGI。但即便如此,运行速度超过最佳利用率(每单位时间执行的操作)所表明的速度并没有任何好处。等待内存操作完成时的快速时钟不会节省能源。
该算法“以最低能耗实现最高利用率/工作负载”的口号在很大程度上是通过管理所有性能资源的闭环算法来实现的。
在多核系统中,不能同时实现负载均衡、多线程屏障延迟低和总能耗最低。为了解决这个问题,可以将 PerfMan 配置为优化一个或多个性能属性。如果以最低能耗为目标,一个不平衡的系统,其中一些内核负载高,而其他内核为空并因此关闭,可能会以更长的执行延迟和整体较低的性能为代价提供最低的能耗。
加速线程以减少屏障延迟也会导致更高的能耗。但是,满足最后期限(硬的或软的)优先于所有其他考虑。精确的基于闭环的性能资源分配算法可以安全地保持更高的工作负载水平,这反过来又可以比现有方法更进一步地推动核心整合,从而实现更高的能耗降低。
在 VMX Linux 上实现
PerfMan 已实现为独立于驻留操作系统运行的瘦内核 (sdKernel)。它已被移植到 Linux 2.6.29 (VMX Linux),如图 2 所示。Android 移植即将完成。该软件接管了 Linux 任务调度并与现有的电源管理基础架构互通。sdKernel 的一个单独版本提供虚拟化并支持在符合 POSIX 的环境中的硬实时任务。调度/上下文切换在许多平台上处于亚微秒级,但由于大多数 Linux 系统调用对于硬实时应用程序来说太慢了,因此 sdKernel 为基本外围设备、定时器和其他资源提供了 API。
图 2:在 Linux 实施中,PerfMan 接管 Linux 任务调度并与现有的电源管理基础架构互通。
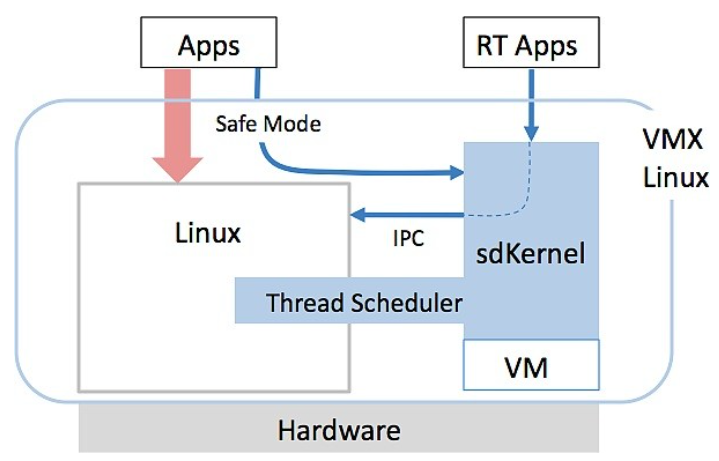
通过监控性能,该软件可以检测异常的执行模式,从而预测即将到来的操作系统恐慌和崩溃。在这种情况下,sdKernel 将通知关键任务应用程序停止使用 Linux 系统调用,并在 Linux 重新启动时临时切换到 sdKernel API(安全模式)。
VMX Linux 支持实时和非实时应用程序的混合,具有高效的性能隔离,同时将能耗降至最低。它还可以提供硬件隔离/安全和安全迫降。
基准测试显示结果
使用 VMX 设计的能量计实时测量的能量消耗为系统累积并与各个应用程序相关联。媒体播放器应用程序(视频和音频)首先使用标准 Linux 2.6.29(图 3 红色图表)和 VMX Linux(图 3 蓝色图表)在 OMAP35xx BeagleBoard 上运行。
图 3:在 OMAP35xx BeagleBoard 上使用 VMX Linux 可实现 95% 的平均负载并及时完成。
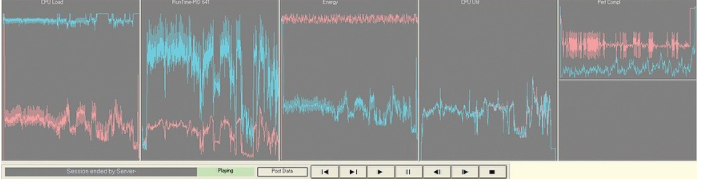
性能合规性(Perf Compl 图)显示应用程序任务按时完成的距离(中心线)。线下方表示违反截止日期。请注意,使用 VMX Linux,可以实现 95% 的平均负载,而无需预缓冲,也不会违反最后期限,但它已经接近了。使用 VMX Linux 时,46 秒视频的总电路板能耗从 68.7 W*sec 下降到 27.6 W*sec。显示的数据代表预设时间间隔内的平均值。作为额外的奖励,当 Linux 被故意崩溃时,视频会消失,但音乐会在安全模式下播放,不会出现任何可听见的故障。
简而言之,该实施创造了一种新的绩效管理方法,并取得了令人兴奋的结果。
审核编辑:郭婷
-
播放器
+关注
关注
5文章
398浏览量
37410 -
Linux
+关注
关注
87文章
11302浏览量
209431 -
操作系统
+关注
关注
37文章
6818浏览量
123320
发布评论请先 登录
相关推荐
焊接能量实时监测仪:精准控制,高效焊接

电磁流量计不能测量什么介质,进来了解
靶式流量计的传感器类型 靶式流量计的校准方法
紫外能量计的技术原理和应用场景
物联网智能家居行业节能方案分享_电量计量芯片剖析
Coherent激光功率和能量计

储能中的“监察官”——能量计量芯片
多普勒流量计 高精度非接触式测量,管道流量监测无障碍
速度式流量计的测量原理是什么
如何利用实时示波器测量线缆长度
如何利用实时示波器测量差分阻抗
多端口能量路由实时控制仿真系统解决方案
能量管理系统是什么意思
光学雨量计:高精度测量降水量的理想解决方案

从入门到精通的孔板流量计测量原理





 工商网监
工商网监
评论