 回顾历史,从串行计算到并行计算
回顾历史,从串行计算到并行计算
小编说:回顾计算机的发展历史,从串行到并行,从同构到异构,接下来会持续进化到超异构:第一阶段,串行计算。单核CPU和ASIC等都属于串行计算。 第二阶段,同构并行计算。CPU多核并行和GPU数以千计众核并行均属于同构并行计算。 第三阶段,异构并行计算。CPU+GPU、CPU+FPGA、CPU+DSA以及SOC都属于异构并行计算。(SOC属于异构的原因是,其他所有引擎的处理都是在CPU的控制之下,其他引擎难以直接数据通信。) 未来,将走向第四阶段,超异构并行阶段。把众多的CPU+xPU“有机”集成起来,形成超异构。
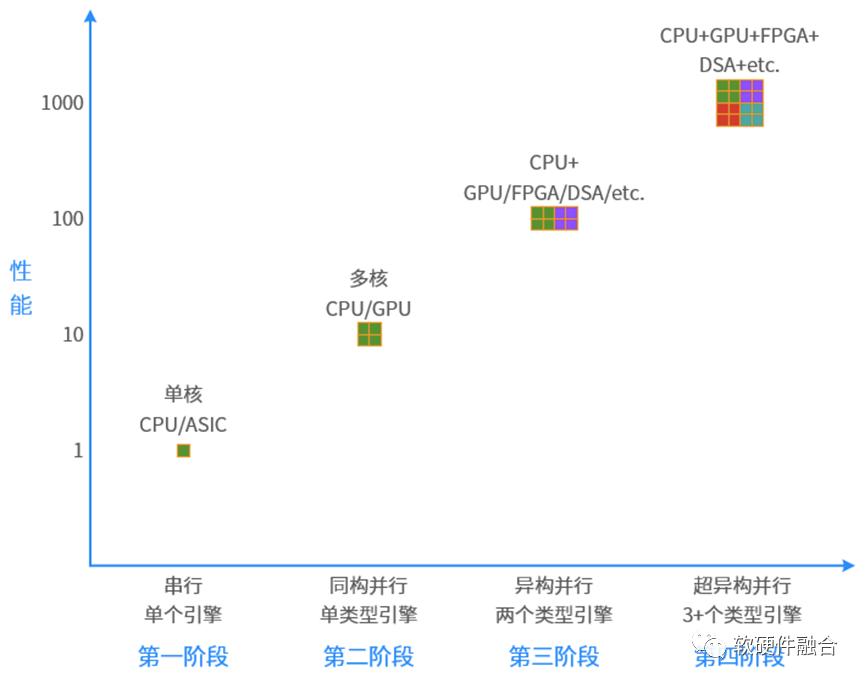
图源:软硬件融合 
回顾历史,从串行计算到并行计算
① 串行计算和并行计算
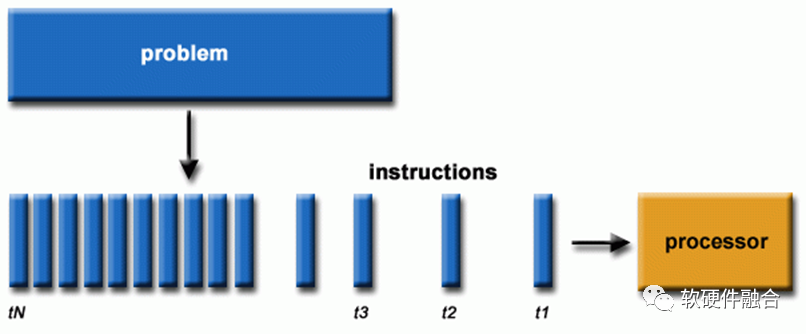
图源:软硬件融合软件一般是为串行计算编写的:① 一个问题被分解成一组指令流; ② 在单个处理器上执行; ③ 指令是依次执行的(处理器内部可能存在非依赖指令乱序,但宏观效果上依然是串行指令流的执行)。
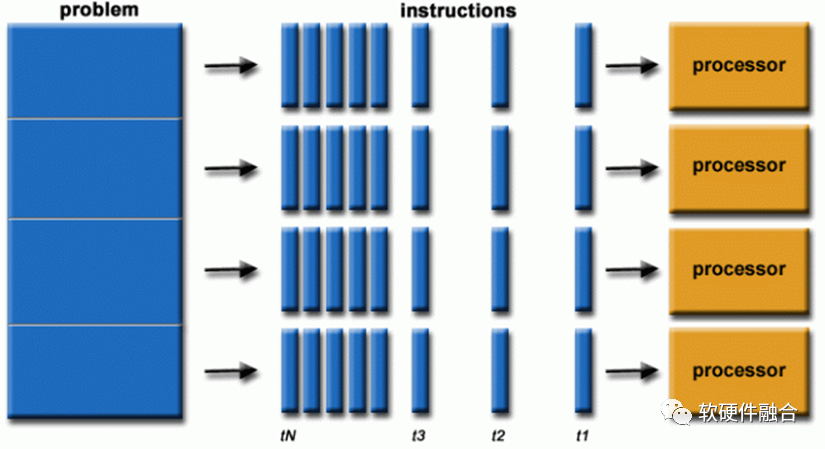
图源:软硬件融合
并行计算就是同时使用多个计算资源来解决一个计算问题:①一个问题被分解成可以同时解决的部分; ②每个部分进一步分解为一系列指令; ③每个部分的指令在不同的处理器上同时执行; ④需要采用整体控制/协调机制。 计算的问题应该能够:分解成可以同时解决的离散工作;随时执行多条程序指令;使用多个计算资源比使用单个计算资源在更短的时间内解决问题。 计算的资源通常是:具有多个处理器/内核的单台计算机;通过网络(或总线)连接的任意数量的此类计算机。
② 多核CPU和众核GPU
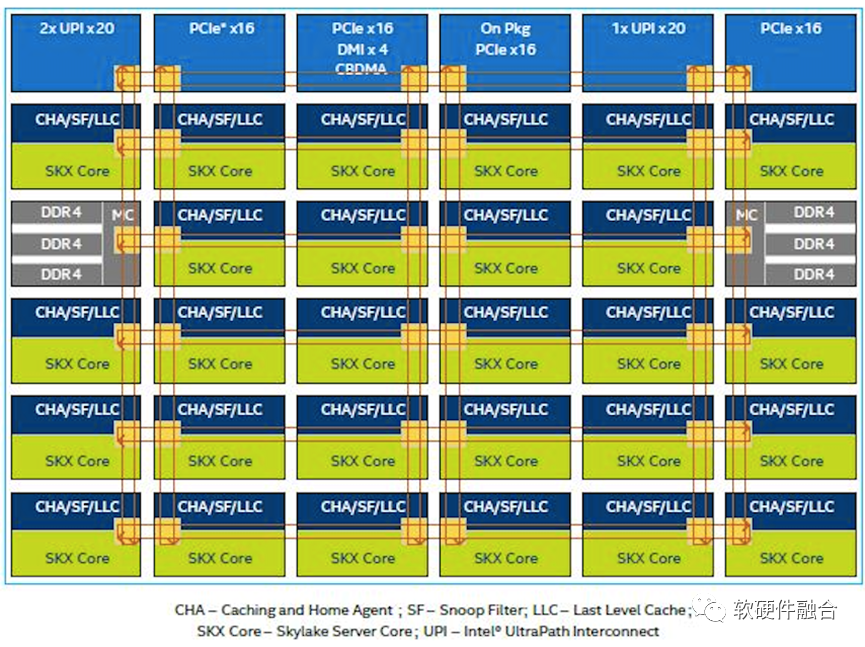
图源:软硬件融合
如上图,是Intel Xeon Skylake的内部架构。可以看到,此CPU是由28个CPU核组成的同构并行。
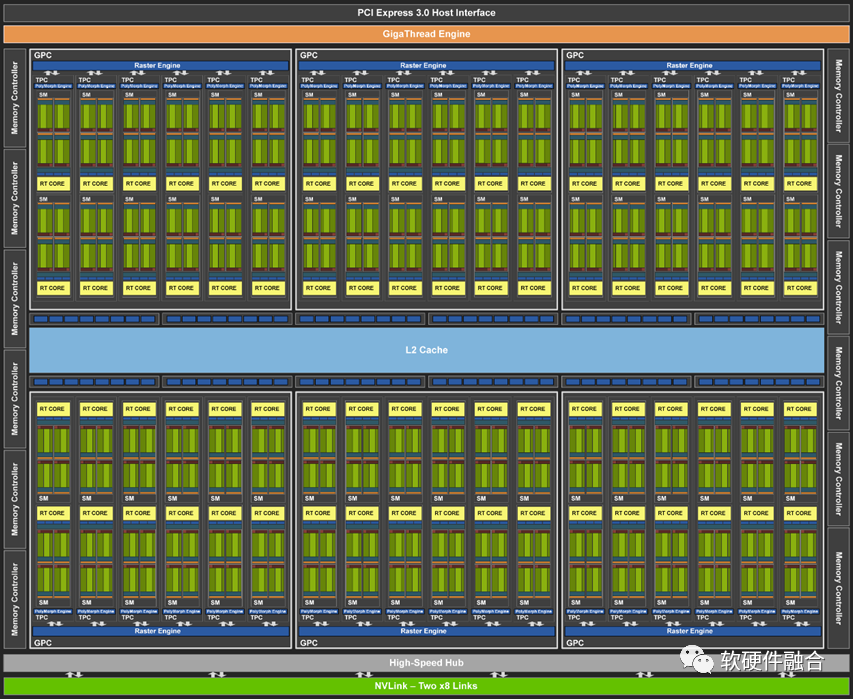
图源:软硬件融合 上图是NVIDIA发布的图灵架构GPU,此架构GPU的核心处理引擎由如下部分组成:6个图形处理簇(GPC);每个GPC有6个纹理处理簇(TPC),共计36个TPC;每个TPC有2个流式多核处理器(SM),总共72个SM。每个SM由64个CUDA核、8个Tensor核、1个RT核、4个纹理单元。 因此,图灵架构GPU总计有4608个CUDA核、576个Tensor核、72个RT核、288个纹理单元。 需要注意的是:GPU非图灵完备,无法单独运行,需要和CPU一起,通过CPU+GPU的异构方式才能工作。因为CPU是图灵完备的,可以自主运行,因此,存在基于多核CPU组成的CPU芯片是同构并行的。
从同构并行到异构并行,异构计算蓬勃发展
① 同构并行和异构并行

图源:软硬件融合
但是,不存在除CPU外其他处理器引擎单独存在的并行计算系统,如GPU、FPGA、DSA、ASIC等引擎同构并行的系统。因为这些处理引擎/芯片是非图灵完备的,它们都是作为CPU的加速器而存在。因此,其他处理引擎的并行计算系统即为CPU+xPU的异构并行,大体分为三类: ①CPU+GPU。CPU+GPU是目前流行的异构计算系统,在HPC、图形图像处理以及AI训练/推理等场景得到广泛应用。 ②CPU+FPGA。目前数据中心流行的FaaS服务,利用FPGA的局部可编程能力,基于FPGA开发运行框架,以及借助第三方ISV支持或自研的方式,构建面向各种应用场景的FPGA加速解决方案。 ③CPU+DSA。谷歌TPU是DSA架构处理器,TPUv1采取独立加速器的方式,实现CPU+DSA(TPU)的方式实现异构并行。 此外,需要说明的是,由于ASIC功能固定,缺乏一定的灵活适应能力,因此不存在CPU+单个ASIC的异构计算。CPU+ASIC形态通常是CPU+多个ASIC组,或在SOC中,作为一个逻辑上独立的异构子系统存在的,需要与其他子系统协同工作。

图源:软硬件融合
SOC本质上也是异构并行,SOC可以看做是CPU+GPU、CPU+ISP、CPU+Modem等多个异构并行子系统组成的系统。
超异构也可以看做是由多个逻辑上独立的异构子系统有机组成的,但SOC和超异构不同:SOC的不同模块通常无法直接高层次数据通信,而是通过CPU调度才能间接通信。SOC和超异构的区别会在超异构部分详细介绍。
② 基于CPU+GPU的异构并行
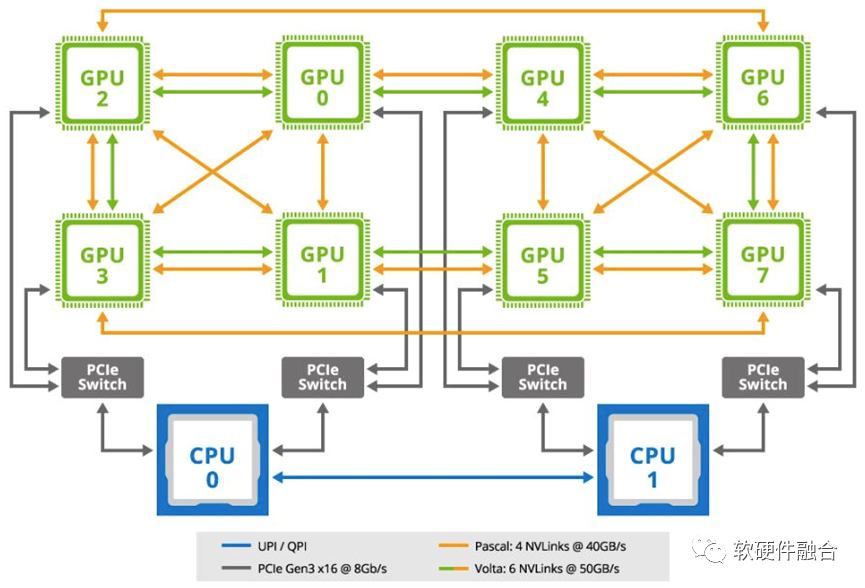
图源:软硬件融合
如图所示,是典型的用于机器学习场景的GPU服务器主板拓扑结构,是一个典型的SOB(System on Board,板级系统)。在此GPU服务器的架构里,通过主板,连接了两个通用CPU和8个GPU加速卡。两个CPU通过UPI/QPI相连;每个CPU通过两条PCIe总线,分别连接1个PCIe交换机;每个PCIe交换机再连接到两个GPU;另外,GPU间还通过NVLink总线相互连接。
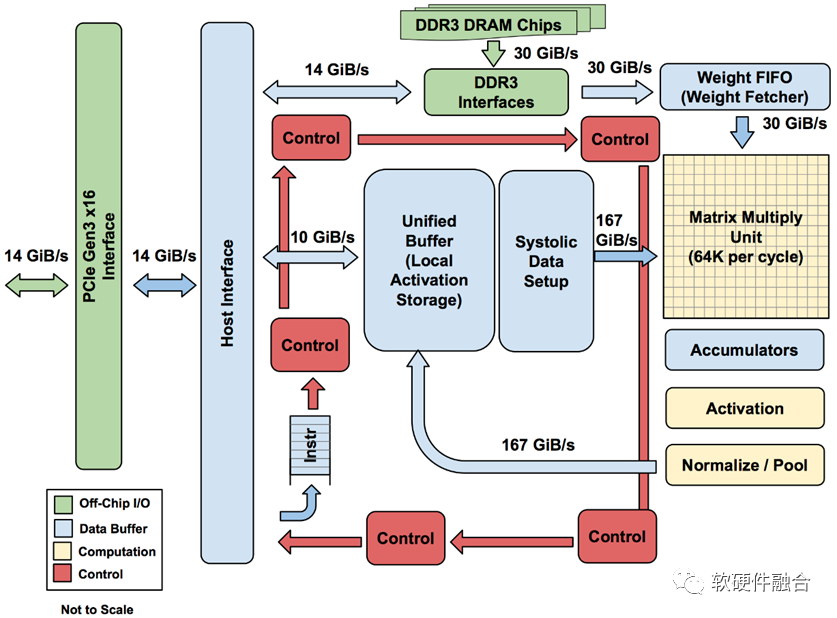
图源:软硬件融合
TPU是业界第一款DSA架构芯片,上图是TPU v1的结构框图。TPU v1通过PCIe Gen3 x16总线和CPU相连,从CPU发送指令到TPU的指令缓冲区,由CPU控制TPU的运行;数据交互在两者的内存之间进行,由CPU发起控制,TPU的DMA执行具体的数据搬运。
从异构持续进化到超异构
① CPU、GPU、DPU、AI等大算力芯片面临的共同挑战
在云计算、边缘计算、终端超级计算机(如自动驾驶)等复杂计算场景,对芯片的可编程能力要求非常高,甚至高过对性能的要求。如果不是基于CPU的摩尔定律失效,数据中心依然会是CPU的天下(虽然CPU的性能效率是低的)。
性能和灵活可编程性,是影响大算力芯片大规模落地非常重要的两个因素。两者如何均衡,甚至兼顾,是大芯片设计永恒的话题。
CPU、GPU、DPU、AI等大算力芯片,面临着共同的挑战,包括:
①单类型引擎性能和灵活性的矛盾。CPU灵活性好,但性能不够;ASIC性能优质,但灵活性不够。
②不同用户的业务差异以及用户的业务迭代。针对这一问题,目前主要做法是针对场景定制。通过FPGA定制,规模太小,成本和功耗太高;通过芯片定制,导致场景碎片化,芯片难以大规模落地,难以摊薄成本。
③宏观算力要求芯片能够支撑大规模部署。宏观算力与单位芯片算力,以及芯片的落地规模成正比。但各类性能提升的方案会损失可编程灵活性,使得芯片难以实现大规模部署,从而进一步影响宏观算力的增长。典型的例子就是目前AI芯片的大规模落地困难。
④芯片的一次性成本过高。数以亿计的NRE成本,需要芯片的大规模落地,才能够摊薄一次性成本。这就需要芯片足够“通用”,在很多场景可以落地。
⑤生态建设的门槛。大芯片需要框架和生态,门槛高且需要长期积累,小公司难以长期大量投入。
⑥计算平台的融合。云网边端融合,需要构建统一的硬件平台和系统堆栈。
⑦等等......
② 解决方案,把异构计算的孤岛连接在一起,形成超异构
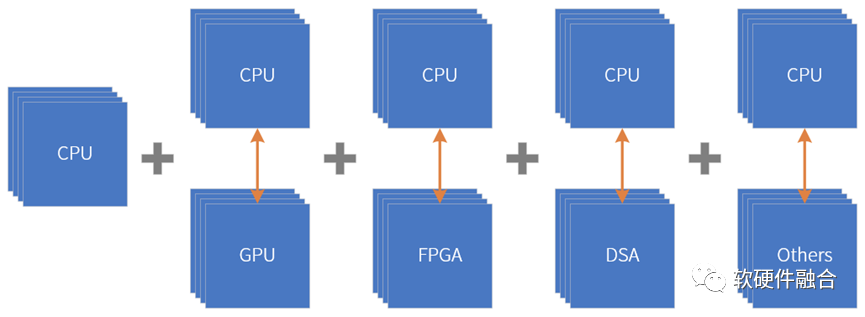
图源:软硬件融合
超异构可以看做是CPU+CPU的同构并行和CPU+其他xPU的异构并行“有机”组合到一起,形成的一个新的超大系统。
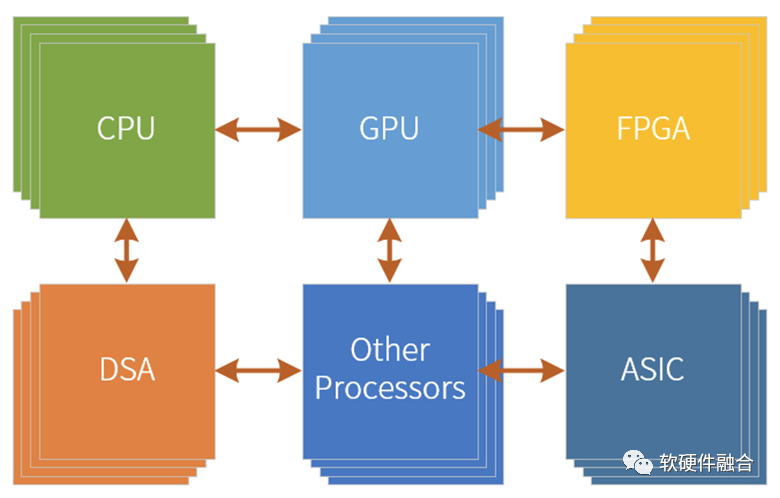
图源:软硬件融合
超异构是由CPU、GPU、FPGA、DSA、ASIC以及其他各种加速引擎“有机”组成的新的宏系统。
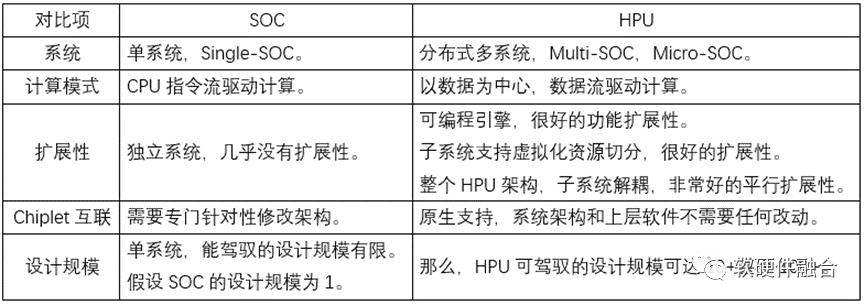
③ 超异构和SOC的不同之处超异构处理器HPU,可以算是SOC,但又跟传统的SOC有很大的不同。如果无法认识到这些不同,就无法理解到HPU的本质。下表是一些典型的差异性对比。
图源:软硬件融合
为什么是现在(才兴起超异构计算)?
① 基于CPU的摩尔定律失效,引发连锁反应
系统越来越复杂,需要选择越来越灵活的处理器;而性能挑战越来越大,需要我们选择定制加速的处理器。这是一对矛盾,拉扯着我们的各类算力芯片设计。本质矛盾是:单一处理器无法兼顾性能和灵活性,即使我们拼尽全力平衡,也只“治标不治本”。
CPU灵活性很好,在符合性能要求的情况下,在云计算、边缘计算等复杂计算场景,CPU是优质的处理器。但受限于CPU的性能瓶颈,以及对算力需求的持续不断上升,(站在算力视角)CPU逐渐成为了非主流的算力芯片。
CPU+xPU的异构计算,由于主要算力是由xPU完成,因此,xPU的性能/灵活性特征,决定了整个异构计算的性能、灵活性特征:
①CPU+GPU的异构计算。虽然在足够灵活的基础上,能够满足(相对CPU的)数量级的性能提升,但算力效率仍然无法做到更优质。
②CPU+DSA的异构计算。由于DSA的灵活性较低,因此不适合应用层加速。典型案例是AI,目前主要是由基于CPU+GPU完成训练和部分推理,DSA架构的AI芯片目前还没有大范围落地。
② Chiplet技术成熟,量变引起质变:需要架构创新,而不是简单集成
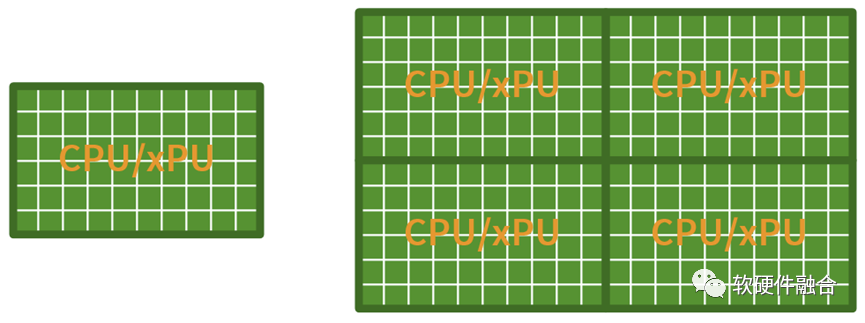
图源:软硬件融合
假设,在没有Chiplet的时候,我们的CPU或xPU可以集成50个核,有了Chiplet互联,把4个DIE拼起来,我们就可以单芯片集成200个核心。 但是,上图的平行扩展方式,真的就是Chiplet的价值吗? 结论是,这样的Chiplet集成,暴殄天物!

图源:软硬件融合
Chiplet使得我们在单个芯片的层次,可以构建规模数量级提升的超大系统。这样,我们可以利用大系统的一些“特点”,来进一步优化。这些特点是:
①复杂系统是由分层分块的任务组成;
②基础设施层的任务,相对确定,适合放在DSA/ASIC。可以在满足任务基本灵活性的基础上,极限的提升性能;
③应用不可加速部分的任务,不确定,适合CPU。系统符合二八定律,用户关心的应用只占整个系统的20%,而不可加速部分,占比通常会少于10%。为了提供用户优质的体验,这部分任务建议放在CPU上。
④应用可加速部分的任务,由于应用的算法差异化和迭代较大,适合放在GPU、FPGA等弹性加速引擎。可以提供足够灵活可编程的同时,可以提供尽可能好的性能。
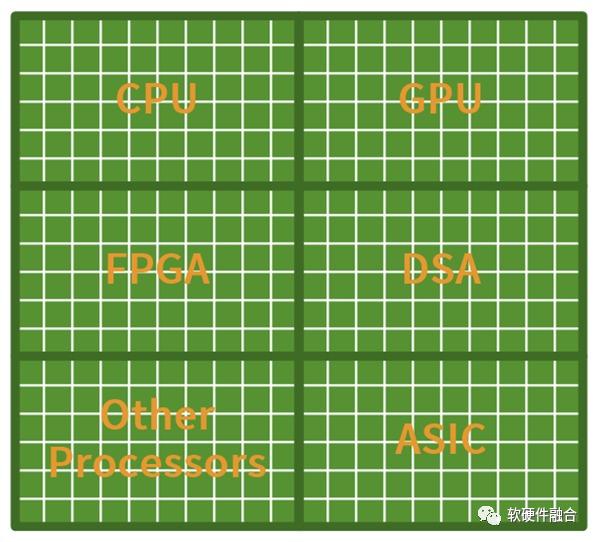
图源:软硬件融合
这样,基于超异构实现的整个系统:
①从宏观视角看,80%甚至90%以上的计算,都是在DSA中完成。这样,整个系统是接近于DSA/ASIC的优质性能;
②用户关心的应用不可加速部分,只占10%以内,依然运行在CPU上。也即用户看到的仍然是100%的CPU级别的灵活可编程性。
也即,通过超异构架构,可以在实现灵活性的同时,实现优质的性能。
③ 超异构更难驾驭,需要创新的理念和技术
异构编程很难,NVIDIA经过数年的努力,才让CUDA的编程对开发者足够友好,形成了健康的生态。超异构就更是难上加难:超异构的难,不仅仅体现在编程上,也体现在处理引擎的设计和实现上,还体现在整个系统的软硬件能力整合上。那么,该如何更好的驾驭超异构?经过慎重思考,我们从以下几个方面入手:
①性能和灵活性。从系统的角度,系统的任务从CPU往硬件加速下沉,如何选择合适的处理引擎,达到优质性能的同时,有优越的灵活性。并且不仅仅是平衡,更是兼顾。
②编程及易用性。系统逐渐从硬件定义软件,转向了软件定义硬件。如何利用这些特征,如何利用已有软件资源,以及如何融入云服务。
③产品。用户的需求,除了需求本身之外,还需要考虑不同用户需求的差异性,和单个用户需求的长期迭代。该如何提供给用户更好的产品,满足不同用户短期和长期的需求。授人以鱼不如授人以渔,该如何提供用户没有特定的具体功能的、性能优质的、完全可编程的硬件平台。
④等等。
软硬件融合,为解决上述问题,提供了成体系化的理念、方法、技术和解决方案,为轻松驾驭超异构提供了切实可行的路径。
关于软硬件融合,请看文章:软硬件融合:超异构算力革命。
未来,所有的大算力芯片都是超异构芯片
图源:软硬件融合
Intel高级副总裁兼加速计算系统和图形部门负责人Raja Koduri表示:要想实现《雪崩》和《头号玩家》中天马行空的体验,需将现在的算力至少再提升1000倍。应用不断发展,软硬件根本的矛盾仍然是“硬件的性能提升,永远赶不上软件对性能的需求”。可以说,对算力的需求,永无止境!
要保证宏观算力的精准,一方面是要持续不断的提升性能,另一方面还要保证芯片的灵活可编程性。唯有通过超异构的方式,分门别类,针对每个任务的特征采用优质的引擎方案,才能在确保灵活可编程的同时,实现优质的性能。从而,真正实现性能和灵活性的既要又要。
单兵作战,顾此失彼;团队协作,互补共赢。
未来,唯有超异构计算,才能保证算力数量级提升的同时,不损失灵活可编程性。才能够真正实现宏观算力的数量级提升,才能够更好的支撑数字经济社会发展。
审核编辑 :李倩
-
处理器
+关注
关注
68文章
19535浏览量
231860 -
cpu
+关注
关注
68文章
10947浏览量
213900 -
串行
+关注
关注
0文章
237浏览量
34066
原文标题:超异构计算:大算力芯片的未来
文章出处:【微信号:electronicaChina,微信公众号:e星球】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
GPU加速计算平台的优势
云 GPU 加速计算:突破传统算力瓶颈的利刃
解析DeepSeek MoE并行计算优化策略
xgboost的并行计算原理
直播预告|RISC-V 并行计算技术沙龙,邀您与国内外专家共探 AI 时代无限可能

GPU加速计算平台是什么
scsi接口是串行还是并行
串行接口与并行接口的区别
图像处理器的发展历史
【《计算》阅读体验】量子计算
【《计算》阅读体验】+徜徉于历史人物事件中-跑跑计算实例感叹于前人的智慧
云计算与企业IT成本治理
串行传输和并行传输的区别,各用于什么场合
高性能计算集群的能耗优化






 工商网监
工商网监
评论