 基于扬声器的深度神经网络方案
基于扬声器的深度神经网络方案
完整的扬声器会包括几个部份:喇叭单体、分频网络、音箱这三大区块,我们就分门别类来讨论。首先就是喇叭单体,基本上来说就是将麦克风的工作原理倒过来,以电气讯号输入在磁力系统里音圈上的线圈,线圈会随着讯号产生磁性变化,而带动音圈在磁力系统中以声音的波形运动。音圈再推动喇叭单体的振膜或音盆,以推动空气产生音波,声音就这样发出来了。
说来确实并不困难,不过要将电气讯号尽可能地依原来应有的波形、响应等低失真的情况发出声音就是另外一回事了。音频范围由低频(20Hz)到高频(18kHz)超过了十个八度音程,单一喇叭单体要能涵盖这个音频范围,在音量方面就会受到结构的限制。不过现在全音域单体技术成熟发达,市面上已经有不少性能还不错的全音域单体供货销售了。
当然要建构能发出大音量高带宽的扬声系统,就需要将不同音域配置给不同特性的单体,诸如低频域(300Hz以下)配置给低音单体、中频域(300Hz-2500Hz)给中音单体,高频域(2500Hz以上)给高音单体分别发音,整合成完整的音域。低频因为需要推动大量的空气,所以需要最大的振膜/音盆;中音域需要推动的空气量较少,因此音盆口径与单体尺寸也更小更轻;而高音域只需要推动最少的空气,因此高音单体也是振膜与体型最轻小的。
基本上来说,单体音盆/振膜口径愈大,质量就愈重能推动愈多空气,但也具备更大的惯性所以反应的速度会降低,因此适合更低的频率;反之单体的振膜口径愈小质量愈轻的,就具备更快的反应速度,能发出更高的频率,但相对能推动的空气量就有限。这也是为何市面上稍有体积的扬声器,都会配置多音路与多个单体整合发音。
当然这样的话就要将扩大机的电气讯号分出高低音路甚或中音路,也就是所谓的「分频」。一般说来扬声系统的分频方式有两种做法,最主流的方式就是以被动分频网络,将扩大机的讯号分出频率范围不同的音路出来。而被动分频网络说穿了就是被动的电感、电容与电阻所构成的「滤波器」,将该音路的音域范围以外的频段予以滤除,而只剩下所需的频段能够通过。所以扬声器统设有几个音路,也就会有几组滤波网络来构成分频网络,分别驱动负责不同音域的单体。
另外一种做法是「电子分音」,是由讯号还在前级输出的阶段,就输送至电子分音器,分出所需频段的各音域,不过采用的是主动式的电子分音电路,一般说来分频效果会比起被动分频网络要来得更好。但分频出来的不同音路就需要个别不同的扩大机去推动各音路的单体,因此会大幅提升扬声系统的成本;通常电子分音都是由比较大型的扬声系统所采用(还有会另文介绍的专业鉴听扬声器)。
最后这些不同音路的单体当然要装置起来成为一组完整的扬声系统,不过还需要进一步考虑的,是单体前后往复震动推动空气发出声音,其前后的声音是「反相」的,如果不进一步处理的话,会在聆听空间中产生彼此抵消的效应,因此需要「装箱」将单体后方发出的「背波」做进一步的处理。一般说来每只单体都会有独立的空间来处理背波,中高音若是单体的体积较小,单体出厂时就会建置密封的背腔预先处理。
所以扬声器音箱最主要还是针对某些口径较大的中音与低音单体设计。目前扬声器音箱设计有两种主流方式:密闭式与开放式,开放式的主流是低音反射式,也就是让音箱的低音腔室容量与反射导管的口径与长度经过计算,与单体的低频特性调谐以产生更大量(适量)的低频表现。但密闭式的音箱容积依然要经过考虑单体特性的计算,让低频可以得到最低频率的延伸。
不过开放式的音箱并不只有低音反射的设计方式,还有诸如双单体多气室的Isobarik形式或是传输线(将音箱内部隔成长导管的形态以延伸低频频率)等诸多方式。音箱的材质与结构上也有诸多设计以强化其结构避免产生共振影响音质,最主流的材质就是所谓的「中密度纤维板」(MDF),此种材料有价格合宜、加工容易以及效果理想的的诸多特性。当然也有扬声器厂家采用金属或特殊材料设计/建构音箱,以取得更佳的特性与效果。
以上就是典型扬声器的构成要素,当然在技术上还有其他不同的设计会脱离上述的范畴,例如「电浆/离子高音」式采用放电的方式驱动空气;「静电扬声器」是采用电极/电场驱动薄膜来推动空气发音,根本没有音箱结构。要将电能转为声能确实还有诸多其他方式,不过目前技术最成熟也是最主流的做法,依然是以电磁系统为原理的传统单体、再与音箱结构整合的传统扬声器。
01 物理神经网络
看到最近在 Nature 杂志上发表的一篇文章 Deep Physical Neural Networks Trained with Backpropogation[1] 介绍了利用多层非线性物理系统构建深度学习网络,并通过反向随机梯度下降完成系统训练方法的确令人惊讶、毁人三观。
你敢想象利用几只扬声器,或者几只场效应管就可以组成深度物理神经网络(Physical Neural Networks),完成图像分类?分类效果比起传统的数字神经网络也不逊色。对于MNIST手写体数字识别也可达到97%以上。(见下面基于四通道双谐波信号发生器(SHG)方案)
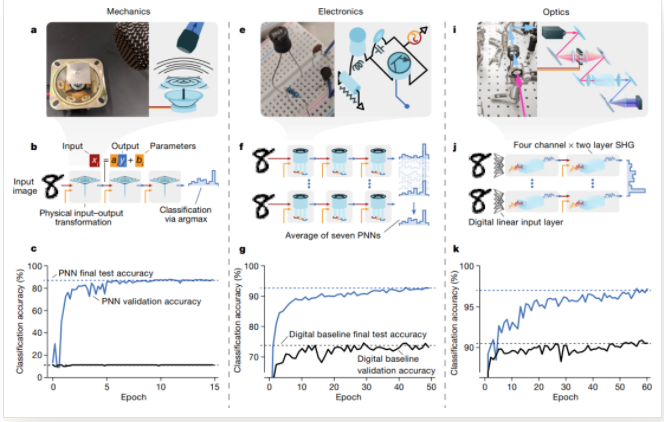
▲ 图1 分别基于机械系统、电子线路、光学系统构建的P物理神经网络
这类建构在物理系统而非数字处理器之上的神经网络目标是在推理速度和能效方面超过传统数字计算机,构建智能传感器和高效网络推理。
猜测大多数人和我一样,第一看到这个文章都会有疑问:这类常见到的扬声器、三极管、光学透镜怎么就能够像深度学习网络那样完成学习训练和推理的呢?特别是这其中都是一些常见到的物理系统,这里面并没有包含什么量子计算机、神经计算机之类结构。
文章包含的工作很多(原文PDF有60多页),我还没有看完,不过文章一开始把为什么物理神经网络能够实现人工神经网络算法的原理还是讲的比较明白。传统的深度学习可以分解若干网络层的级联计算,每一层的计算包括输入数据(Input)、网络参数(Parameters),它们经过融合后经过神经元非线性传递函数形成网络的输出(Output)。
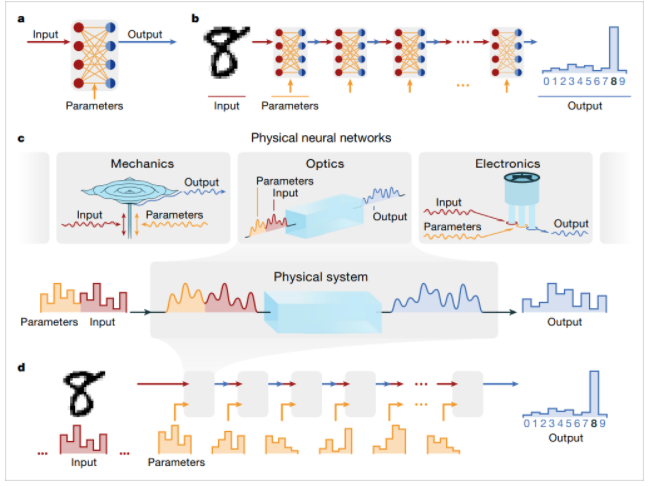
▲ 图2 人工神经网络(ANN)与物理神经网络(PNN) 之间的联系
物理神经网络也是分成若干层的级联,比如若干个扬声器,每个扬声器是一层神经网络。输入信号是扬声器的输入电压;网络参数则是一组可以控制的电压信号,比如持续时间,幅值可以改变的信号,它们与输入信号通过(叠加、串联等)合并后送入扬声器,扬声器的输出声音再经过麦克风采集形成网络的输出。
▲ 图1.3 由扬声器组成的一层神经网络结构图
在由晶体管组成的放大电路、光学倍频器(SHG)组成的系中,对于输入信号,网络参数以及它们的融合方法根据各子系统特点有所不同。
比如在下图中,网络参数实际上就是一段长度和幅值不同的直流信号,嵌入在输入变化的信号中(A),经过三极管电路之后形成输出(B),输入信号和网络参数融合部分进行展开与归一化(C)形成网络输出信号。
▲ 图3 在三极管电路中输入信号网络参数信号(幅值可控一段直流电平)的串联,以及对应的电路输出信号
尽管现在对于网络如何进行训练,如何进行工作的细节还有待进一步的了解,但文章所展示关于深度神经网络算法的本质令人耳目一新。利用了系统输入输出之间的非线性把输入信号与网络信号进行融合完成信息的处理,所以文章所举例的三个系统(扬声器、三极管电路、二次倍频光学系统)都应该不是线性时不变系统。
下面,我们抛开物理神经网络算法,先看看论文中的这三个系统的特点。
02 非线性系统
在大学本科阶段所学习的“信号与系统”、“自动控制理论”中所讨论的原理和方法基本上都是针对于线性时不变系统,因此判断一个系统是否是线性时不变是应用这些理论第一步需要做的事情。
在前面Nature 论文中所提到的三个物理系统(机械、电子、光学)是否都满足线性时不变呢?
2.1 三极管电路
文章中三极管电路最简单,同样它的非线性也最为明显。
电路包含有四个元器件:电阻、电感、电容以及场效应三极管。其中电阻、电感、电容都是线性元器件,只有场效应三极管是一个非线性器件。它的漏极饱和电流与栅极电压之间呈现平方关系。所以该电子系统是一个非线性系统。
▲ 图2.1.1 三极管电路
2.2 二次谐波产生系统(SHG)
二次谐波产生系统 是一个光学系统,也是文章举例中最复杂的系统。
对于SHG(Second-Harmonic Generation)光学系统我不是很熟悉,通过 检索相应文献[2] 可以了解到它的基本原理。它利用了 一些特殊的分子物理状态可以将输入光学信号的频率进行倍频,产生对应的二次谐波信号。
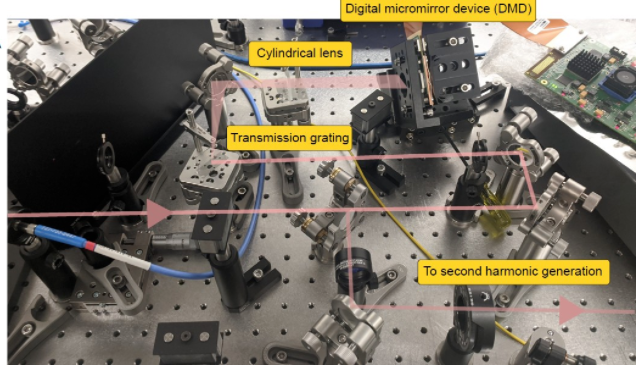
▲ 图2.2.1 二次谐波产生系统
对于这类你不熟悉的物理系统,那么该如何判断它 是否属于线性时不变系统呢?
在这里我们需要利用线性时不变系统的一个特性:线性时不变系统不会产生新的频率信号。
虽然它可以改变输入信号中不同频率分量的幅度和相位,但不会有新的频率分量产生。SHG光学系统是将输入光谱中所有频率分量都进行倍频,产生了新的倍频分量,因此它不属于线性时不变系统。
因此,倍频是该系统能够用于完成物理神经系统的关键,一个线性时不变光学系统是无法构建物理神经网络的。
2.3 扬声器
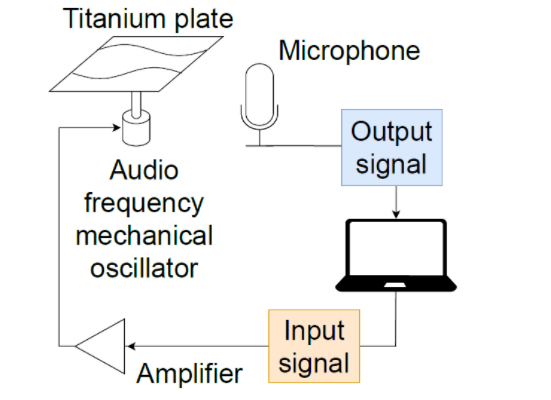
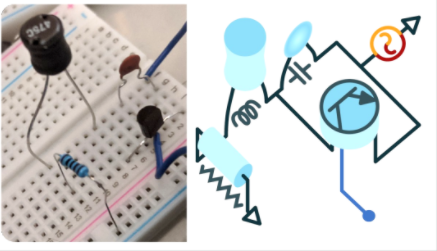
文章举例的三个系统中,就数扬声器机械振动系统最令人感到扑朔迷离。系统分为扬声器、音频功放、麦克风组成。其中扬声器需要进行改装。
他们把动圈式喇叭的振动膜和防尘罩拆除,露出音频线圈,在上面使用胶水粘上一个金属螺钉,再固定一个3.2cm×3.2cm见方,1mm厚的金属钽制作的金属片。读到此,你会觉得他们这通骚操作属于脱了裤子放屁,故弄玄虚。

▲ 图2.3.1 利用扬声器制作的机械振荡系统
原以为他们这么改装应该是想在喇叭机械系统中融入非线性环节,但在音圈(Sound Coil)上增加的金属螺钉和钽片好像仅仅是增加了喇叭线圈惯性质量,对于其中高频振荡进行压制,起到一个低频滤波的作用。因此该系统仍然属于一个线性时不变系统。
下面是论文补充材料中给出的扬声器输入电压信号,麦克风录音信号以及信号降采样的数字信号。可以看到麦克风录制的音频信号的确是对输入信号的低通平滑滤波。
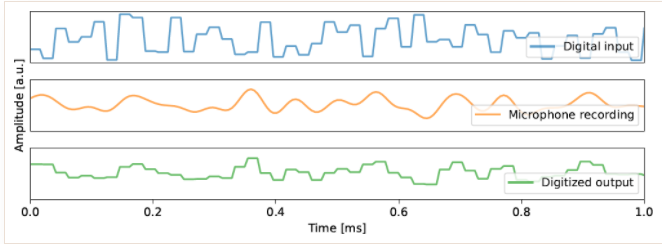
▲ 图2.3.2 扬声器的输入信号、麦克风录音信号以及降采样数字信号
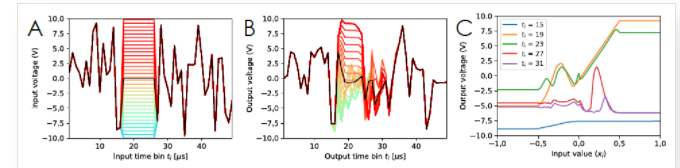
下图是文章中给出的输入随机信号中嵌入了幅度可控一段直流信号(相当于网络参数),施加在扬声器上之后,麦克风采集到的音频信号。最后一张图上可以看到在不同时刻对应的输出信号与输入信号之间呈现线性关系。
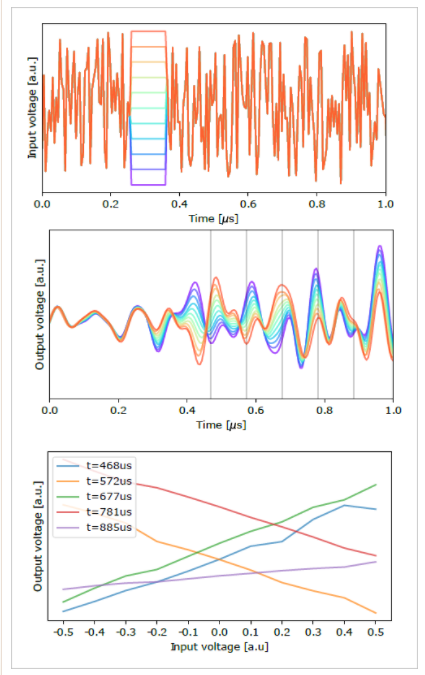
▲ 图2.3.3 输入随机噪声加上可控直流信号片段噪声的输出信号
那么问题来了:这个系统中的非线性环节到底在哪儿呢?
现在能够想到的就是其中麦克风信号进行降采样可能会改变系统的线性时不变特性,类似于卷积神经网中的 Pooling 层的作用。
※ 总 结 ※
来自于康纳尔大学的这篇研究论文给出了 一个利用物理系统实现深层网络学习和推理的框架。本文对于文章举例的三个系统不属于线性时不变系统进行分析。除了其中SHG系统比较复杂之外,其它两个系统(三极管、扬声器)是如此的简便,吸引人去进行搭建系统,测试一下相应的性能性能。
[1]Deep Physical Neural Networks Trained with Backpropogation: https://www.nature.com/articles/s41586-021-04223-6.pdf[2]检索相应文献: https://www.sciencedirect.com/topics/chemistry/second-harmonic-generation
-
三极管
+关注
关注
142文章
3611浏览量
121905 -
麦克风
+关注
关注
15文章
636浏览量
54821 -
扬声器
+关注
关注
29文章
1302浏览量
63016
发布评论请先 登录
相关推荐
FPGA在深度神经网络中的应用
残差网络是深度神经网络吗
简单认识深度神经网络
深度神经网络概述及其应用
循环神经网络和卷积神经网络的区别
深度神经网络与基本神经网络的区别
深度神经网络的设计方法
卷积神经网络与循环神经网络的区别
bp神经网络是深度神经网络吗
深度学习与卷积神经网络的应用
深度神经网络有哪些主要模型?各自的优势和功能是什么?
深度神经网络模型有哪些
利用深度循环神经网络对心电图降噪
详解深度学习、神经网络与卷积神经网络的应用






 工商网监
工商网监
评论