 利用axi_master接口指令端的几个静态参数的优化技巧
利用axi_master接口指令端的几个静态参数的优化技巧
Vitis HLS 在从Vivaido HLS的升级换代中,以axi_master接口为起点的设计正在变得更易上手,其中很重要的一点就是更多的MAXI端口设计参数可以让用户通过指令传达到。这些参数可以分为两类:
静态参数指标:这些参数会影响内存性能,可以在 C 综合期间的编译时从编译的结果中很清楚地知道,突发读写地长度、数据端口宽度加宽、对齐等。
动态参数指标:这些参数本质上是动态的,取决于系统。例如,与 DDR/HBM 的通信效率在C综合编译时是未知的。 本文给大家提供利用axi_master接口指令端的几个静态参数的优化技巧,从扩展总线接口数量,扩展总线位宽,循环展开等角度入手。最核心的优化思想就是以资源面积换取高带宽的以便并行计算。
熟记这本文几个关键的设计点,让你的HLS内核接口效率不再成为设计的瓶颈! 以上代码在进行了c综合后,我们所有的指针变量都会依据指令的设置映射到axi-master上,但是因为根据指令中所有的端口都绑定到了一条总线gmem上。所以在综合的警告里面会提示:
以上代码在进行了c综合后,我们所有的指针变量都会依据指令的设置映射到axi-master上,但是因为根据指令中所有的端口都绑定到了一条总线gmem上。所以在综合的警告里面会提示:
 当总线数量满足了我们并行读入的要求后,读取数据的位宽就成为了我们优化的方向:
因为读取的数据格式是int类型,所以这里的数据位宽就是32bit。
当总线数量满足了我们并行读入的要求后,读取数据的位宽就成为了我们优化的方向:
因为读取的数据格式是int类型,所以这里的数据位宽就是32bit。
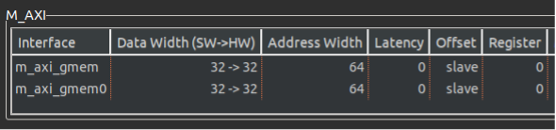 为了能够转移数据传输瓶颈,在Vitis kernel target flow中,数据位宽在512bit的时候能够达到最高的数据吞吐效率。在Vitis HLS 中的新增了 max_widen_bitwidth 选项来自动将较短的数据位宽拼接到设定的较长的数据位宽选项。在这里我们可以将位宽设置到512bit的位宽,但是同时要向编译器说明,原数据位宽和指定的扩展位宽成整数倍关系。这个操作很简单,在数据读取的循环边界上,用(size/16)*16示意编译器即可。
为了能够转移数据传输瓶颈,在Vitis kernel target flow中,数据位宽在512bit的时候能够达到最高的数据吞吐效率。在Vitis HLS 中的新增了 max_widen_bitwidth 选项来自动将较短的数据位宽拼接到设定的较长的数据位宽选项。在这里我们可以将位宽设置到512bit的位宽,但是同时要向编译器说明,原数据位宽和指定的扩展位宽成整数倍关系。这个操作很简单,在数据读取的循环边界上,用(size/16)*16示意编译器即可。
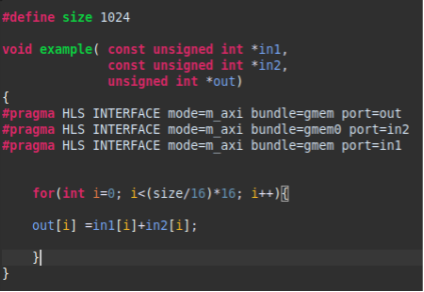 扩展位宽后的结果可以在综合报告的接口部分看到数据位宽已经从32位扩展到512位。
扩展位宽后的结果可以在综合报告的接口部分看到数据位宽已经从32位扩展到512位。
 优化到这一步我们的设计可以进行大位宽的同步读写,但是发现循环的trip count还是执行了1024次, 也就是说虽然位宽拓展到512后,还是一个循环周期计算一次32bit的累加。实际上512bit的数据位宽可以允许16个累加计算并行执行。
优化到这一步我们的设计可以进行大位宽的同步读写,但是发现循环的trip count还是执行了1024次, 也就是说虽然位宽拓展到512后,还是一个循环周期计算一次32bit的累加。实际上512bit的数据位宽可以允许16个累加计算并行执行。
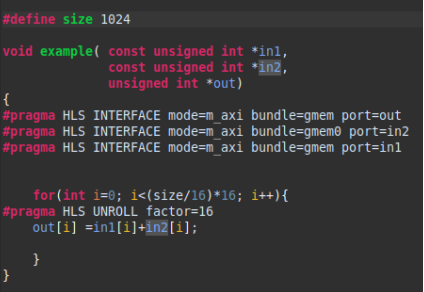
 为了完成并行度的优化,我们需要在循环中添加系数为16的unroll 指令,这样就可以生成16个并行执行累加计算的硬件模块以及线程。
为了完成并行度的优化,我们需要在循环中添加系数为16的unroll 指令,这样就可以生成16个并行执行累加计算的硬件模块以及线程。
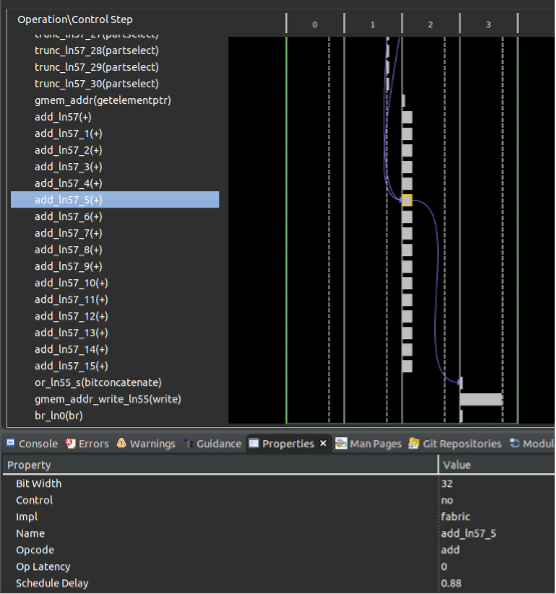
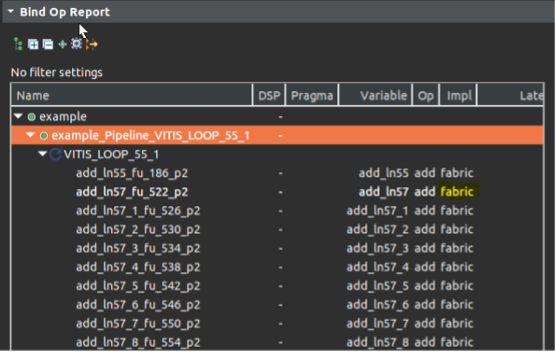
 在循环中并行执行的累加操作,我们可以从schedule viewer中观察到并行度,可以从bind_op窗口中观察到operation实现所使用的硬件资源,可以从循环的trip_count 降低到了1024/16=64个周期,以及大大缩小的模块的整个latency中得以证明。
在循环中并行执行的累加操作,我们可以从schedule viewer中观察到并行度,可以从bind_op窗口中观察到operation实现所使用的硬件资源,可以从循环的trip_count 降低到了1024/16=64个周期,以及大大缩小的模块的整个latency中得以证明。
 最后我们比较了一下并行执行16个累加计算前后的综合结果,可以发现由于有数据的按位读写拆分拼接等操作,整个模块的延迟虽然没有缩短为16分之一,但是缩短为5分之一也是性能的极大提升了。
最后我们比较了一下并行执行16个累加计算前后的综合结果,可以发现由于有数据的按位读写拆分拼接等操作,整个模块的延迟虽然没有缩短为16分之一,但是缩短为5分之一也是性能的极大提升了。
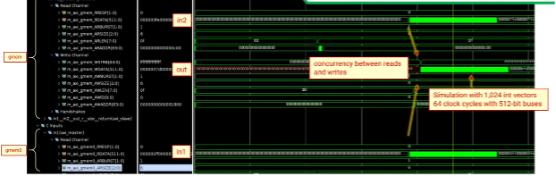
 最后的最后,RTL级别的co-sim仿真才让我们更加确信了数据的从两个并行读写,循环执行的周期减小至了64个时钟周期。
最后的最后,RTL级别的co-sim仿真才让我们更加确信了数据的从两个并行读写,循环执行的周期减小至了64个时钟周期。
 以上内容是设计者在AXI总线接口中使用传统的数据类型时,提升数据传输效率和带宽的一揽子有效方法:
第一,扩展总线接口数量,以便并行读写。第二,扩展总线位宽,增加读写带宽。第三,循环展开,例化更多计算资源以便并行计算。
本文的优化方式还是基于内核设计本身的,下一篇文章,我们将使用Alveo板卡做一些突发传输的实验,深度定制传输需求,以真实仿真波形和测得的传输速度,从系统级别强化我们对于突发读写效率的认知。
审核编辑 :李倩
以上内容是设计者在AXI总线接口中使用传统的数据类型时,提升数据传输效率和带宽的一揽子有效方法:
第一,扩展总线接口数量,以便并行读写。第二,扩展总线位宽,增加读写带宽。第三,循环展开,例化更多计算资源以便并行计算。
本文的优化方式还是基于内核设计本身的,下一篇文章,我们将使用Alveo板卡做一些突发传输的实验,深度定制传输需求,以真实仿真波形和测得的传输速度,从系统级别强化我们对于突发读写效率的认知。
审核编辑 :李倩
动态参数指标:这些参数本质上是动态的,取决于系统。例如,与 DDR/HBM 的通信效率在C综合编译时是未知的。 本文给大家提供利用axi_master接口指令端的几个静态参数的优化技巧,从扩展总线接口数量,扩展总线位宽,循环展开等角度入手。最核心的优化思想就是以资源面积换取高带宽的以便并行计算。
熟记这本文几个关键的设计点,让你的HLS内核接口效率不再成为设计的瓶颈!
以上代码在进行了c综合后,我们所有的指针变量都会依据指令的设置映射到axi-master上,但是因为根据指令中所有的端口都绑定到了一条总线gmem上。所以在综合的警告里面会提示:
WARNING: [HLS 200-885] The II Violation in module 'example_Pipeline_VITIS_LOOP_55_1' (loop 'VITIS_LOOP_55_1'):Unable to schedule bus request operation ('gmem_load_1_req', example.cpp:56) on port 'gmem' (example.cpp:56) due to limited memory ports(II = 1). Please consider using a memory core with more ports or partitioning the array.
因为在axi-master总线上最高只能支持一个读入和一个写出同时进行,如果绑定到一条总线则无法同时从总线读入两个数据,所以最终的循环的II=2。解决这个问题的方法就是用面积换速度,我们实例化两条axi总线gmem和gmem0,最终达到II=1。
当总线数量满足了我们并行读入的要求后,读取数据的位宽就成为了我们优化的方向:
因为读取的数据格式是int类型,所以这里的数据位宽就是32bit。
为了能够转移数据传输瓶颈,在Vitis kernel target flow中,数据位宽在512bit的时候能够达到最高的数据吞吐效率。在Vitis HLS 中的新增了 max_widen_bitwidth 选项来自动将较短的数据位宽拼接到设定的较长的数据位宽选项。在这里我们可以将位宽设置到512bit的位宽,但是同时要向编译器说明,原数据位宽和指定的扩展位宽成整数倍关系。这个操作很简单,在数据读取的循环边界上,用(size/16)*16示意编译器即可。
扩展位宽后的结果可以在综合报告的接口部分看到数据位宽已经从32位扩展到512位。
优化到这一步我们的设计可以进行大位宽的同步读写,但是发现循环的trip count还是执行了1024次, 也就是说虽然位宽拓展到512后,还是一个循环周期计算一次32bit的累加。实际上512bit的数据位宽可以允许16个累加计算并行执行。
为了完成并行度的优化,我们需要在循环中添加系数为16的unroll 指令,这样就可以生成16个并行执行累加计算的硬件模块以及线程。
在循环中并行执行的累加操作,我们可以从schedule viewer中观察到并行度,可以从bind_op窗口中观察到operation实现所使用的硬件资源,可以从循环的trip_count 降低到了1024/16=64个周期,以及大大缩小的模块的整个latency中得以证明。
最后我们比较了一下并行执行16个累加计算前后的综合结果,可以发现由于有数据的按位读写拆分拼接等操作,整个模块的延迟虽然没有缩短为16分之一,但是缩短为5分之一也是性能的极大提升了。
最后的最后,RTL级别的co-sim仿真才让我们更加确信了数据的从两个并行读写,循环执行的周期减小至了64个时钟周期。
以上内容是设计者在AXI总线接口中使用传统的数据类型时,提升数据传输效率和带宽的一揽子有效方法:
第一,扩展总线接口数量,以便并行读写。第二,扩展总线位宽,增加读写带宽。第三,循环展开,例化更多计算资源以便并行计算。
本文的优化方式还是基于内核设计本身的,下一篇文章,我们将使用Alveo板卡做一些突发传输的实验,深度定制传输需求,以真实仿真波形和测得的传输速度,从系统级别强化我们对于突发读写效率的认知。
审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
接口
+关注
关注
33文章
8770浏览量
152365 -
静态
+关注
关注
1文章
29浏览量
14601 -
代码
+关注
关注
30文章
4857浏览量
69480
原文标题:开发者分享 | HLS, 巧用AXI_master总线接口指令的定制并提升数据带宽-面积换速度
文章出处:【微信号:Open_FPGA,微信公众号:OpenFPGA】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
VirtualLab Fusion应用:参数优化文档介绍
摘要
VirtualLab Fusion的参数优化文档使用户能够为其光学装置应用非线性优化算法。该文档指导您完成优化配置并最终输出结果。这个用例解释了
发表于 02-28 08:44
ZYNQ基础---AXI DMA使用
Xilinx官方也提供有一些DMA的IP,通过调用API函数能够更加灵活地使用DMA。 1. AXI DMA的基本接口 axi dma IP的基本结构如下,主要分为三个部分,分别是控制axi
hdmi是什么电平?hdmi信号里有几对差分还有几个单端的,差分的信号是不是cml电平?
出来的cml信号在还原成hdmi信号,接到显示器上。现在有几个问题:
1,hdmi是什么电平?第一次接触,hdmi信号里有几对差分还有几个单端的,差分的信号是不是cml电平?
2,如果差分的是cml电平
发表于 12-24 06:34
如何优化SSR渲染性能
服务器端渲染(SSR)是一种将前端页面在服务器端生成的技术,它可以提高首屏加载速度,改善SEO,并提供更好的用户体验。然而,SSR也可能带来性能挑战,尤其是在处理大量请求时。以下是一些优化SSR渲染
spi master接口的fpga实现
串行外围接口 大致了解: spi是个同步协议,数据在master和slaver间交换通过时钟sck,由于它是同步协议,时钟速率就可以各种变换。 sck:主机提供,从机不能操控,从器件由主机产生的时钟控制。数据只有在sck来了的上升沿或者下降沿才传输。 高级一点的spi芯

AMBA AXI4接口协议概述
AMBA AXI4(高级可扩展接口 4)是 ARM 推出的第四代 AMBA 接口规范。AMD Vivado Design Suite 2014 和 ISE Design Suite 14 凭借半导体产业首个符合
PGA309温漂是否可以通过设置参数软件方式优化,如何优化?
1.PGA309温漂是否可以通过设置参数软件方式优化,如何优化?
2.针对可编程放大器,是否有数字输出的PGA系列产品?
发表于 08-09 07:04
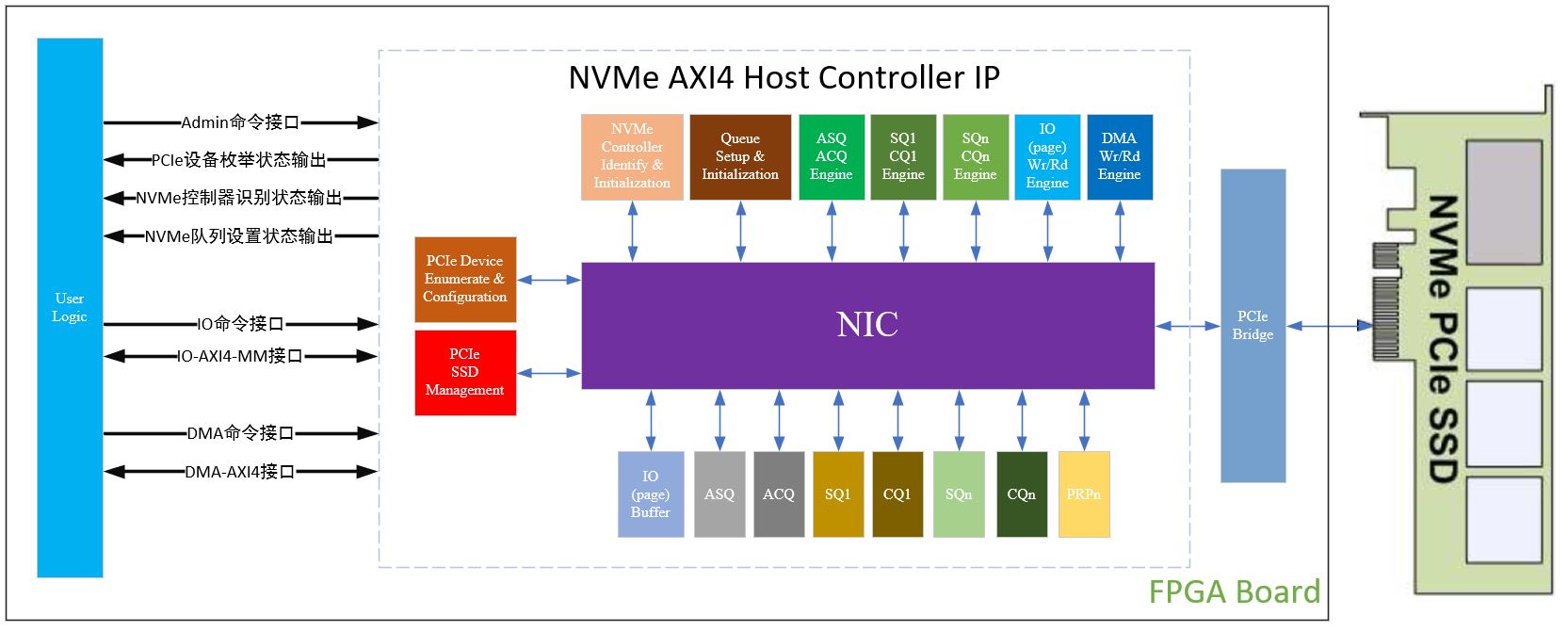
Xilinx NVMe AXI4主机控制器,AXI4接口高性能版本介绍
NVMe AXI4 Host Controller IP可以连接高速存储PCIe SSD,无需CPU,自动加速处理所有的NVMe协议命令,具备独立的数据写入和读取AXI4接口,不但适用高性能、顺序
FPGA的SRIO接口使用应注意的事项
,并使用正确的连接线将它们连接起来。
按照规格书的要求进行连接,确保连接的稳固性和可靠性。
在FPGA和通信设备上配置SRIO接口的软件驱动程序和相关设置,确保两端的通信协议和参数设置一致
发表于 06-27 08:33
有关PL端利用AXI总线控制PS端DDR进行读写(从机wready信号一直不拉高)
怎么判断他到底采用了这三种握手里面的哪种握手,这实在令人费解。还是PS端的DDR的机制的问题。
5.31 update:
问题找到部分:
情形一:接口的设置上,如果是设置为AXI4,如图所示,
那么
发表于 05-31 12:04
SoC设计中总线协议AXI4与AXI3的主要区别详解
AXI4和AXI3是高级扩展接口(Advanced eXtensible Interface)的两个不同版本,它们都是用于SoC(System on Chip)设计中的总线协议,用于处理器和其它外设之间的高速数据传输。
FPGA设计中,对SPI进行参数化结构设计
今天给大侠带来FPGA设计中,对SPI进行参数化结构设计,话不多说,上货。
为了避免每次SPI驱动重写,直接参数化,尽量一劳永逸。SPI master有啥用呢,你发现各种外围芯片的配置一般
发表于 05-07 16:09
FPGA开发如何降低成本,比如利用免费的IP内核
的参数、改进接口设计或优化布局布线等。通过迭代和优化,可以进一步提高设计的性能和效率。
需要注意的是,虽然这些IP内核是免费的,但在使用时仍需遵守相关的许可协议和条款。此外,对于某些复
发表于 04-28 09:41
FPGA设计中,对SPI进行参数化结构设计
今天给大侠带来FPGA设计中,对SPI进行参数化结构设计,话不多说,上货。
为了避免每次SPI驱动重写,直接参数化,尽量一劳永逸。SPI master有啥用呢,你发现各种外围芯片的配置一般
发表于 04-11 18:29





 工商网监
工商网监
评论