 使用TensorBoard进行机器学习模型分析
使用TensorBoard进行机器学习模型分析
这些模型针对特定数据集进行了训练,并在准确性和处理速度方面得到了证明。开发人员需要在部署之前评估 ML 模型并确保其符合预期的特定阈值和功能。有很多实验可以提高模型性能,在设计和训练模型时,可视化差异变得至关重要。TensorBoard 有助于可视化模型,使分析变得不那么复杂,因为当人们可以看到问题所在时,调试变得更容易。
训练 ML 模型的一般做法
一般的做法是使用预训练的模型并执行迁移学习以针对相似的数据集重新训练模型。在迁移学习期间,首先针对与正在解决的问题相似的问题对神经网络模型进行训练。然后将训练模型中的一个或多个层用于针对感兴趣问题训练的新模型。
大多数情况下,预训练模型采用二进制格式,这使得很难获取内部信息并立即开始处理。从组织的业务角度来看,拥有一些工具来深入了解模型以缩短项目交付时间是有意义的。
有几个可用的选项可以获取模型信息,例如层数和相关参数。模型摘要和模型图是基本选项。这些选项非常简单,考虑到几行实现,并提供了非常基本的细节,如层数、层类型和每层的输入/输出。
但是,模型摘要和模型图对于理解协议缓冲区形式的任何大型复杂模型的每一个细节并不是那么有效。在这样的场景下,使用TensorFlow提供的可视化工具TensorBoard就更有意义了。考虑到它提供的各种可视化选项,例如模型、标量和度量(训练和验证数据)、图像(来自数据集)、超参数调整等,它非常强大。
模型图以可视化自定义模型
当以协议缓冲区的形式接收自定义模型时,此选项特别有用,并且需要在对其进行任何修改或训练之前对其进行理解。如下图所示,在板上可视化了顺序 CNN 的概述。每个块代表一个单独的层,选择其中一个将在右上角打开一个窗口,其中包含输入和输出信息。
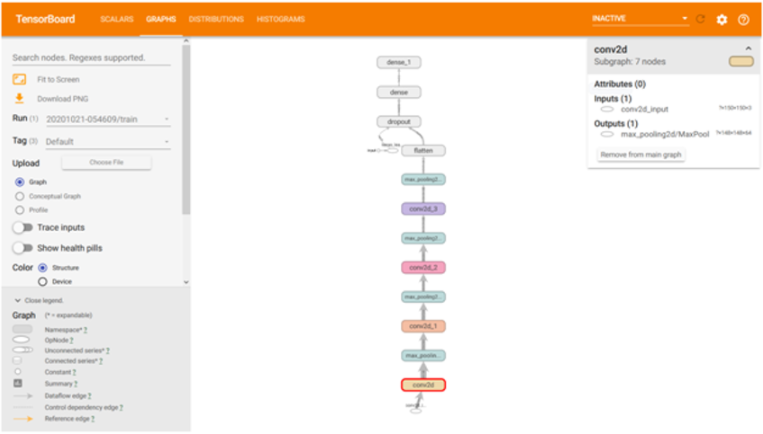
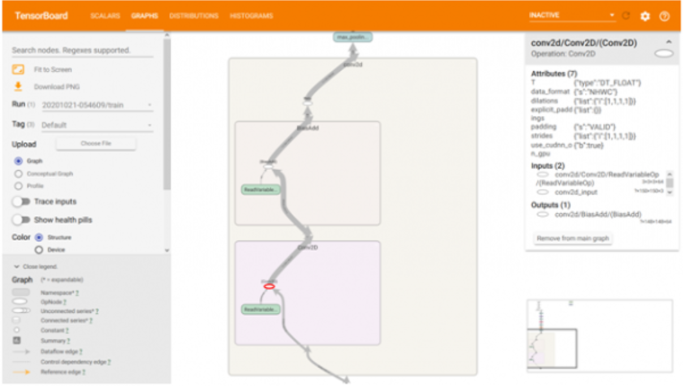
如果需要进一步的信息,关于各个块中的内容,可以简单地双击块,这将展开块并提供更多详细信息。请注意,一个块可以包含一个或多个可以逐层扩展的块。在选择任何特定操作后,它还将提供有关相关处理参数的更多信息。
用于分析模型训练和验证的标量和指标
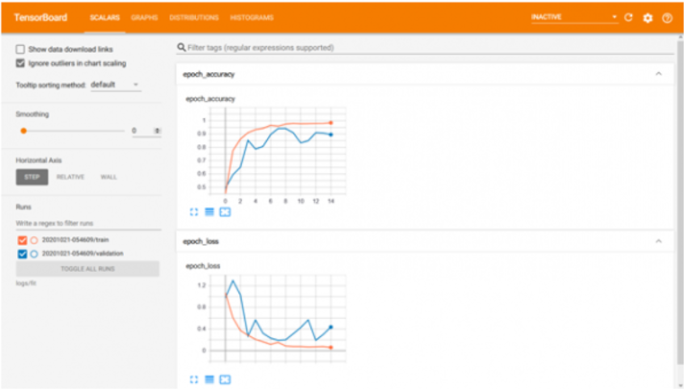
机器学习的第二个重要方面是分析给定模型的训练和验证。从准确性和速度的角度来看,性能对于使其适用于现实生活中的实际应用非常重要。在下图中,可以看出模型的准确性随着 epochs/迭代次数的增加而提高。如果训练和测试验证不达标,则表明某些事情不正确。这可能是欠拟合或过拟合的情况,可以通过修改层/参数或改进数据集或两者兼而有之来纠正。
图像数据以可视化数据集中的图像
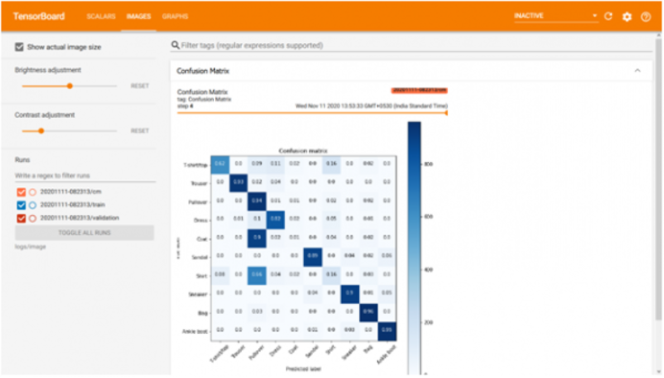
顾名思义,它有助于可视化图像。它不仅限于可视化数据集中的图像,它还以图像的形式显示混淆矩阵。该矩阵表示检测各个类别的对象的准确性。如下图所示,模特将大衣与套头衫混淆了。为了克服这种情况,建议改进特定类别的数据集,以将可区分的特征提供给模型,以便更好地学习并提高准确性。
超参数调整以实现所需的模型精度
模型的准确性取决于输入数据集、层数和相关参数。在大多数情况下,在初始训练期间,准确度永远不会达到预期的准确度,除了数据集之外,还需要考虑层数、层类型、相关参数。此过程称为超参数调整。
在这个过程中,提供了一系列超参数供模型选择,并结合这些参数运行模型。每个组合的准确性都记录在板上并可视化。它纠正了为超参数的每个可能组合手动训练模型所消耗的精力和时间。
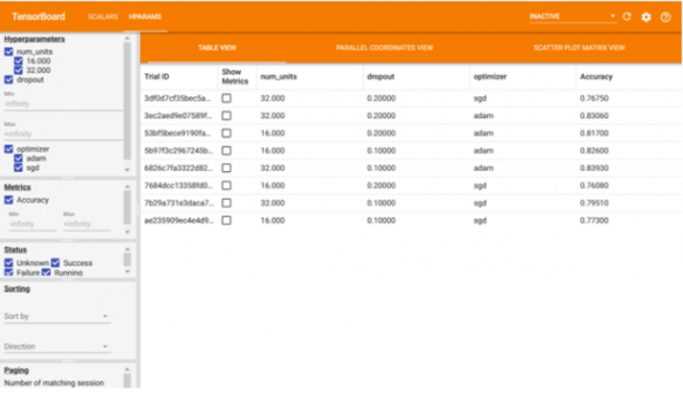
分析模型处理速度的分析工具
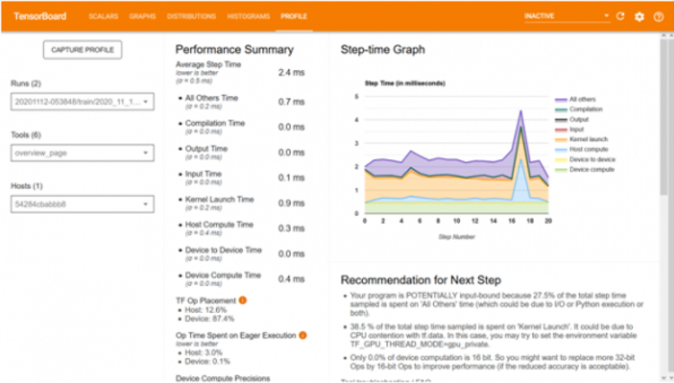
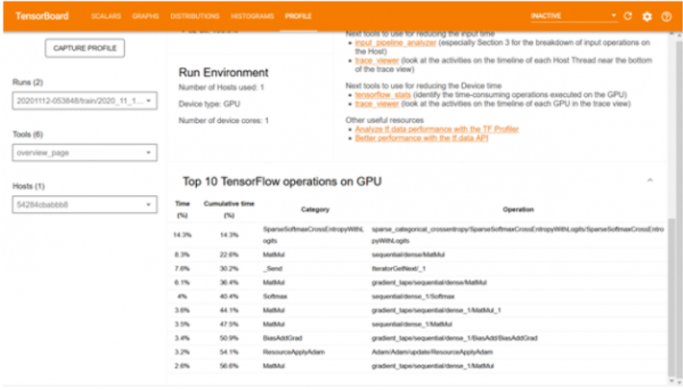
除了准确性之外,处理速度对于任何模型来说都是同样重要的方面。有必要分析各个块消耗的处理时间,以及是否可以通过一些修改来减少它。Profiling Tool 提供了每个操作在不同时期的时间消耗的图形表示。通过这种可视化,人们可以很容易地查明需要更多时间的操作。一些已知的开销可能是调整输入的大小、从 Python 转换模型代码或在 CPU 而非 GPU 中运行代码。照顾好这些事情将有助于实现最佳性能。
总体而言,TensorBoard 是帮助开发和培训过程的绝佳工具。Scalar and Metrics、Image Data 和 Hyperparameter 调优的数据有助于提高准确性,而 profiling 工具有助于提高处理速度。TensorBoard 还有助于减少所涉及的调试时间,否则这肯定是一个很大的时间框架。
审核编辑:郭婷
-
cpu
+关注
关注
68文章
10874浏览量
212108 -
gpu
+关注
关注
28文章
4747浏览量
129020 -
机器学习
+关注
关注
66文章
8423浏览量
132753
发布评论请先 登录
相关推荐
什么是机器学习?通过机器学习方法能解决哪些问题?

AI大模型与深度学习的关系
使用AI大模型进行数据分析的技巧
AI大模型与传统机器学习的区别

构建语音控制机器人 - 线性模型和机器学习






 工商网监
工商网监
评论