 NVIDIA AI平台在MLPerf基准测试实现飞跃
NVIDIA AI平台在MLPerf基准测试实现飞跃
NVIDIA AI 仍是唯一能够运行 MLPerf 行业基准测试中所有测试的平台, A100 GPU 自发布以来连续两年一直保持着获胜次数最多的纪录。
根据今天发布的 MLPerf 基准测试结果, NVIDIA 及其合作伙伴占了所有参赛生态伙伴的 90%,并且继续提供了最佳的整体 AI 训练性能和提交了最多的测试项。
NVIDIA AI 平台覆盖了 MLPerf 训练 2.0 版本中的所有八项基准测试,突显了其领先的通用性。
除 NVIDIA 之外,无其它加速器运行过所有基准测试,这些基准测试代表了流行的 AI 用例,包括语音识别、自然语言处理、推荐系统、目标检测、图像分类等,而 NVIDIA 自 2018 年 12 月向作为行业标准 AI 基准测试的 MLPerf 提交首轮测试结果以来就一直如此。
领先的基准测试结果与可用性
在连续第四次 MLPerf 训练提交结果中,基于 NVIDIA Ampere 架构的 NVIDIA A100 Tensor Core GPU 依然表现出色。
各个提交者平台在每个网络的“最快训练时间”
Selene 是 NVIDIA 内部的一台 AI 超级计算机,它基于模块化的 NVIDIA DGX SuperPOD,并由 NVIDIA A100 GPU、软件堆栈和 NVIDIA InfiniBand 网络驱动,在八项大规模工作负载测试的四项中获得 “最快训练时间” 。
为了计算单芯片性能,该图表将每份提交结果归一化到每个提交者最常见的尺度,检测分数归一化到速度最快的竞争者,最快竞争者显示为 1 倍。
NVIDIA A100 还保持了单芯片性能上的领导地位,在八项测试中的六项测试中呈现了最快的速度。
共有 16 家合作伙伴使用 NVIDIA AI 平台提交了本轮结果,包括华硕、百度、中国科学院自动化研究所、戴尔科技、富士通、技嘉、新华三、慧与、浪潮、联想、宁畅和超微。
NVIDIA 的大多数 OEM 合作伙伴提交了使用 NVIDIA 认证系统得到的结果,这些服务器经过 NVIDIA 验证,能够为企业部署提供出色的性能、可管理性、安全性和可扩展性。
多种模型驱动实际 AI 应用
AI 应用可能需要理解用户说出的要求,对图像进行分类、提出建议并以语音信息的形式作出回应。
即使是上图简单的用例也需要将近 10个模型,这突出了运行每个基准的重要性
这些任务需要多种类型的 AI 模型按顺序工作,用户需要能够快速且灵活地设计、训练、部署和优化这些模型。
这也是为什么通用性(能够在 MLPerf 及其他版本中运行每个模型)以及领先的性能都是将现实世界的 AI 引入入生产的关键。
通过 AI 实现投资回报
对于客户而言,数据科学和工程团队是最宝贵的资源,他们的生产力决定了 AI 基础设施的投资回报。客户必须考虑昂贵的数据科学团队的成本,这通常在部署 AI 的总成本中占比很重,而部署 AI 基础设施本身的成本相对较少。
AI 研究人员的生产力取决于能否快速测试新的想法,这需要通用性来训练任何模型,以及大规模训练模型所能提供的速度。这就是为什么企业关注单位成本的整体生产力,以确定最佳的 AI 平台——更全面的视角,更准确地代表了部署 AI 的真实成本。
此外, AI 基础设施的利用率取决于可替换性,或在单一平台上加速从数据准备到训练再到推理的整个 AI 工作流程的能力。
凭借 NVIDIA AI,客户可以在整个 AI 流程中使用相同的基础设施,重新利用它来适配数据准备、训练和推理之间的不同需求,这极大地提高了利用率,实现了非常高的投资回报率。
随着研究人员发现新的 AI 突破口,支持最新模型创新是最大程度地延长 AI 基础设施使用寿命的关键。
NVIDIA AI 兼容并适用于每个模型、可以扩展到任何规模,并加速从数据准备到训练再到推理的端到端 AI 流程,能够实现最高的单位成本生产力。
今天的结果再次证明了 NVIDIA 在迄今为止所有 MLPerf 训练、推理和 HPC 评测中所展示的丰富而深厚的 AI 专业性。
3 年半内将性能提高 23 倍
自首次基于 A100 提交 MLPerf 基准测试以来的两年时间里,在 NVIDIA 软件堆栈持续优化的推动下, NVIDIA 平台的性能已提高了 6 倍。
自 MLPerf 问世以来,归功于跨 GPU、软件和大规模改进的全栈式创新, NVIDIA AI 平台在 3 年半时间里,在基准测试中实现了 23 倍的性能提升。正是这种对创新的持续追求,让客户确信他们现今投资的 AI 平台将持续服务 3 至 5 年,并将继续推进以适配最先进的技术。
此外, NVIDIA 于 3 月发布的 NVIDIA Hopper架构有望在未来的 MLPerf 基准测评中实现性能的另一巨大飞跃。
NVIDIA 如何做到这一点
软件创新持续释放 NVIDIA Ampere架构的更多性能。
例如,在提交结果中大量使用的 CUDA Graphs,该软件可以最大限度地减少跨多个加速器上运行作业的启动开销。NVIDIA 不同库的内核优化,如 cuDNN 和预处理库 DALI,解锁了额外的加速。NVIDIA 还实现了跨硬件、软件和网络的全栈改进,如 NVIDIA Magnum IO 和 SHARP,将部分 AI 功能卸载到网络中,以获得更好的性能,特别是在大规模的情况中。
NVIDIA 所使用的所有软件均可从 MLPerf 资源库中获取,所有人都可以获得 NVIDIA 的世界级领先成果。NVIDIA 不断地将这些优化集成到 NVIDIA 的 GPU 应用软件中心—— NGC 上提供的容器中,并通过 NVIDIA AI Enterprise 提供完全由 NVIDIA 支持,并经过优化的软件。
从 A100 GPU 两年前首次提交以来, NVIDIA AI 平台继续在 MLPerf 2.0 中提供最高的性能,仍是唯一能够提交所有基准测试的平台。NVIDIA 的下一代 Hopper 架构有望在未来的 MLPerf 评测中实现另一巨大飞跃。
NVIDIA 平台适用于任何规模的模型和框架,并具有可替代性以处理 AI 工作负载的每个部分。它可以在所有云端和主要的服务器制造商上使用。
原文标题:NVIDIA 与合作伙伴在 MLPerf 中展示领先的 AI 性能和通用性
文章出处:【微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
-
NVIDIA
+关注
关注
14文章
5094浏览量
104071 -
gpu
+关注
关注
28文章
4807浏览量
129605 -
AI
+关注
关注
87文章
32069浏览量
270959 -
基准测试
+关注
关注
0文章
21浏览量
7626 -
MLPerf
+关注
关注
0文章
35浏览量
659
原文标题:NVIDIA 与合作伙伴在 MLPerf 中展示领先的 AI 性能和通用性
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

NVIDIA发布Cosmos平台,加速物理AI开发
交通运输领先企业率先采用NVIDIA Cosmos平台
NVIDIA发布Cosmos™平台,助力物理AI系统发展
MLCommons推出AI基准测试0.5版
使用NVIDIA AI平台确保医疗数据安全
赖耶科技通过NVIDIA AI Enterprise平台打造超级AI工厂
NVIDIA与思科合作打造企业级生成式AI基础设施
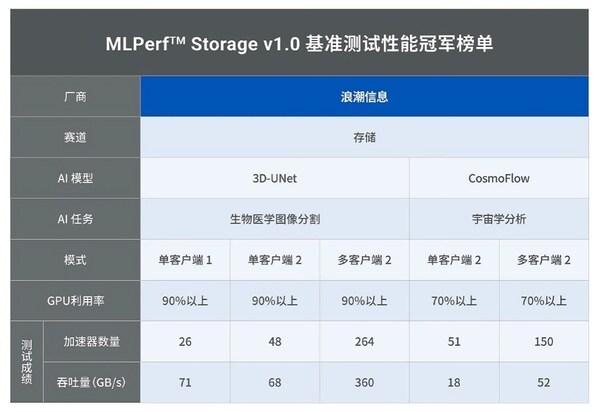
浪潮信息AS13000G7荣获MLPerf™ AI存储基准测试五项性能全球第一
NVIDIA在加速计算和生成式AI领域的创新
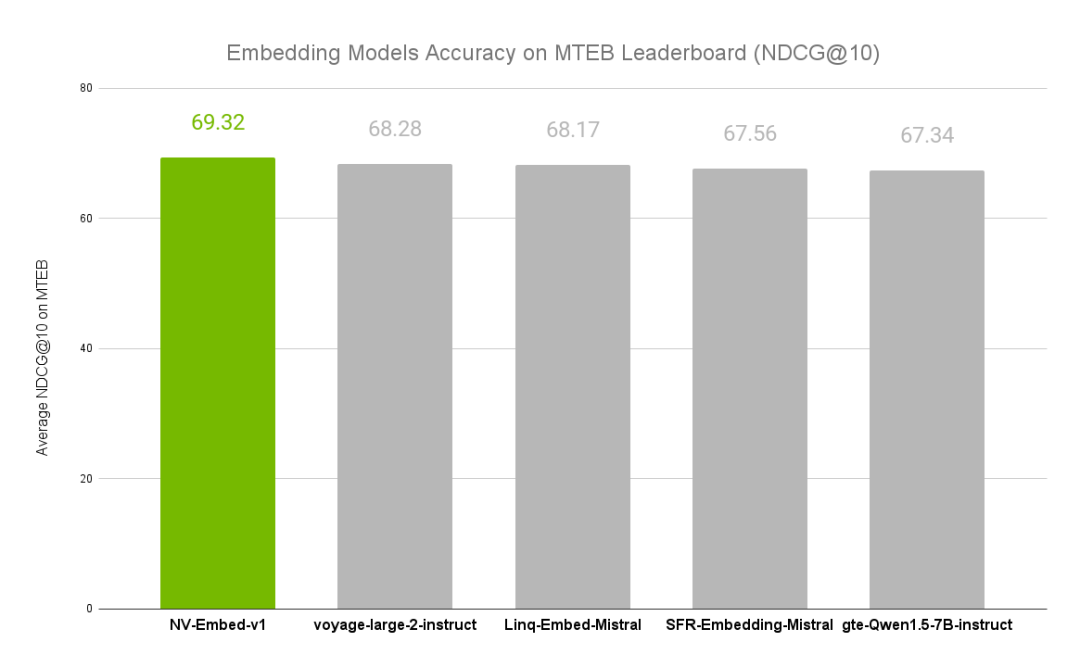
NVIDIA文本嵌入模型NV-Embed的精度基准
NVIDIA推出用于支持在全新GeForce RTX AI笔记本电脑上运行的AI助手及数字人
NVIDIA 通过 Holoscan 为 NVIDIA IGX 提供企业软件支持,实现边缘实时医疗、工业和科学 AI 应用






 工商网监
工商网监
评论